

遗传算法(GA)详解
遗传算法主要作用是求解最优解,例如求函数极值,或是飞机巡航问题中的最短巡航路线的求解等,其作用与模拟退火算法的作用较为相似。本文将从GA算法的原理,结构与两个实践应用进行比较详细的讲解(受篇幅限制,本文先对第一个实践进行详细讲解),本文代码采用Python.
- 算法原理:
遗传算法既然有遗传二字,那自然与遗传有关了。首先兔兔在下面列出了所用到的遗传学的一些术语:
染色体chromosome,表现型phenotype,选择selection,适应度fitness,交叉crossover,变异mutation,种群population.
虽然在其它文章中还会出现基因型等其它术语,但是本人觉得这些应该就差不多了,毕竟这是一个算法实现问题,而不是遗传学问题。
通常情况,对于一个种群,里面有很多个个体,我们认为每一个个体就代表了一个解(或是一个染色体,因为遗传算法中每个个体只有一个染色体,可以把染色体与个体等同的),一个种群有n个个体,也就有n个解。种群内部两两个体之间的基因交流,然后发生染色体的交叉,其子代会继承一部分父母的基因(基因在染色体上)。
除了染色体交叉,还会有染色体部分基因片段的变异。两种情况的综合,使得种群含有的n个解随繁衍代数的变化而变化。这里提醒一下,遗传算法中不像生物学中的那样,父母和他们的后代也组成一个种群,这里就是F1代组成一个种群,F2代组成一个种群,种群内部都是一代人。并且每个父母只有两个孩子(这样保证这个有n个父母种群的后代还是n个孩子)。
可是这样的话,我们只是得到一堆没用的解。这个时候自然选择就起到关键作用了。可以这样说,即使没有上面提到的交叉变异,只有选择,最终也可以得到最优解的(后面会详细说明)。通过自然选择,适应度越高(越适应环境,即越接近最优解),越容易保留下来。这样经过数代之后,种群中大部分个体都能够比较接近最优解的。
* 算法实践1:函数极值的求解。
兔兔在这里先随便选一个函数 f(x)=-x(x-10),x范围是[0,10],图像如下图所示:
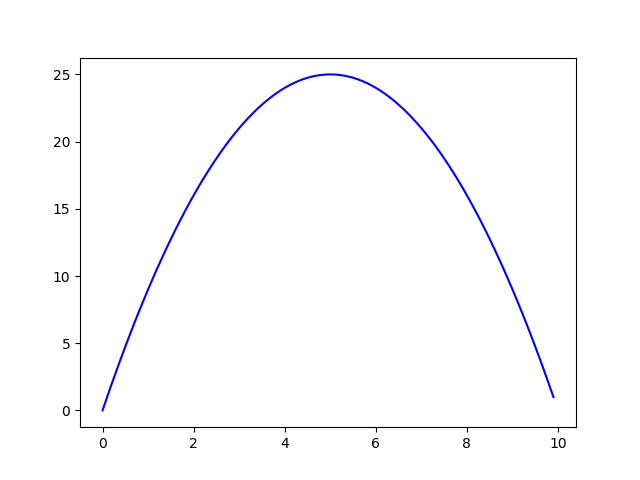

现在我们需要在[0,10]这个区间里面找一个x,使得函数f(x)取得最大值。那根据前面讲的遗传算法,一个解代表一个染色体,可是染色体应该是一个长条串(一维列表)呀,这样才能进行两个染色体的交叉。所以我们应该想一个办法,用一个”串”来表示一个数 ,即x。所以一个好的办法就是 把数转化成二进制,用二进制来表示!而这里最大的数是10,转化成二进制也不过4位,交叉起来感觉不是很好。最好我们可以实现任意一个区间都可以用具有任意长度的二进制表示。
所以我们这样这样做:
比如一个长度为10的二进制列表(如[0,1,1,1,0,0,0,0,1,1]),由于每一位上只取0和1,则它能表示的范围为0~2的9次方再减1,那么这样具有10位的列表,转化成十进制再除以2的10次方,就能把数限制在[0,1)内了。再把它乘上10,那么就得到[0,10)区间的表示方法了。
import numpy as np
def bin():
'''随机生成一个10位的二进制数组'''
a=np.random.randint(0,2,size=10)
return a
def bin_to_dec(a):
'''把二进制数组转化成[0,10)区间内的数'''
s=0
for i in range(len(a)):
s+=2**(len(a)-i-1)
return 10*s/2**(len(a)
print(bin())
print(bin_to_dec(bin()))
对于多个染色体,我们可以把一个个染色体堆叠起来,形成二维矩阵,行数代表染色体个数,列数代表染色体的长度。上面那个代码是一个染色体,染色体长度为10的一个情况。
选择(selection)
选择是这个算法的关键,毕竟我们需要的就是最优解,不对种群选择肯定得不到最优解的。选择时,当然是适应度越大越容易被选择。在我们这个例子中,就是f(x)的值越大,对应的x被选择的概率越大。在这里我先介绍numpy模块中一个比较好用的函数:choice
import numpy as np
a=np.random.choice([1,2,3,4,5],
size=10,p=[0.1,0.1,0.1,0.5,0.2],replace=True)
这里的[1,2,3,4,5]是需要选的5 个数,size=10代表从中选10个数,也就意味着这10个数一定有重复的。p代表选不同数的概率。选1概率为0.1,选2概率0.1,选5概率0.2…所以要保证p里面各个概率之和为1,p里面的个数也要和要选的样本数一致。
回到刚才选择的那个问题,用choice 函数就很好解决。我们得到n个解,每个解的值为f(xi)(i从1到n),我们先把这n个解做好对应标记,即[0,1,2…n],取x1概率为f(x1)/(f(x1)+f(x2)+…+f(xn)), 取x2概率为f(x2)/((f(x1)+f(x2)+…+f(xn)),取f(xi)概率就是f(xi)/(f(x1)+f(x2)+…+f(xn)),这样做会使得所有概率相加为1,并且值越大被选概率就越大,从而达到选择的目的。
def f(x):
return -x*(x-10)
x=np.array([1,3,5,7,9])
y=f(x)
s=sum(y)
idx=np.random.choice(np.arange(len(x)),size=5,p=y/s)
print(x[idx],y[idx])
通过以上方法我们学会如何对种群进行选择了。在遗传算法中,通常我们每次选择种群个数时都是n,保持种群个数 不变。
交叉、变异(crossover,mutation)
交叉、变异其实也是遗传算法的重要环节了。如果只是选择的话,倘若初始种群足够大还可以——我们就一直在初始解当中选择,最终肯定也能找到比较好的解。但如果一堆初始解中没有最优解,最终肯定找不到的,所以需要在选择过程中让解也在变化。形象地理解就是,一直选择就相当于无性繁殖,克隆,没有什么变化;而交叉变异则是有性生殖,就是”龙生九子,十子不同”,这样能够保证解的多样性,有可能出现最适的解并在选择当中得以保存下来。并且,交叉这个步骤是可以保留父母双方的优良性状的,之后保留下来的优良性状又会继续交叉从而传递给下一代。
那么在这里就需要两个重要参数:交叉概率pc,突变概率pm。通常pm为0.6左右,保证交叉;pc在0.001左右,突变概率不能太大,否则比较好的解很容易突变掉。pc实现方法就是:种群中每两对染色体交叉之前,都要有一个概率pc来判断是否执行交叉。即:
for i in range(0,x,2):
if np.random.rand()<pm:
crossover(i,i+1)
else:
no crossover
变异(mutation)的操作也是如此。这就很像模拟退火算法中在一定温度下以一定概率去接受一个解。
无论是交叉还是变异,我们都需要找一个位点。对于交叉位点,两个染色体在位点前都保持原来的序列,交叉点后序列互换。变异位点就是把1变成0,0变成1。
a=[0,0,0,0,0,1,1,1,1,1]
b=[1,1,1,1,1,0,0,0,0,0]
a=[0,0,0,0,0,0,0,0,0,0]
b=[1,1,1,1,1,1,1,1,1,1]
c=[0,1,1,1,1,1,1]
c=[1,1,1,1,1,1,1]
至此,所有的部件就都讲述了。不过里面需要注意的东西还是挺多的。比如说前面的选择函数 choice,里面的p是不能为负数的(概率不能为负数)。咱们前面用的函数f(x)=-x*(x-10)在0到10 是非负的,这样用f(xi)除以函数值的和作为选择概率是合理的。一旦在定义域内函数有负数值,那肯定会报错的。比如函数x _sin(x)就是如此,如果我们仅是求极值的话,可以在函数值f(x)做绝对值处理,就是|f(xi)|/(|f(x1)|+|f(x2)|+…+|f(xn)|),这样能保证概率非负,和为1,并且越靠近极值概率越大。
接下来我们以函数f(x)=x_sin(x)为例,用python实现遗传算法。所有算法实现的细节也都在主代码中。
主代码
import numpy as np
def function(x):
'''所需要求解的函数'''
return x*np.sin(x)
class GA:
'''遗传算法'''
def __init__(self,function,domain=50,pc=0.6,pm=0.01,M=50,popsize=50,length=10):
self.pc=pc
self.pm=pm
self.function=function
self.length=length
self.popsize=popsize
self.pop=np.random.randint(0,2,size=(popsize,length))
self.M=M
self.domain=domain
def bio_to_dec(self,pop):
'''把二进制数组转化成在定义域范围内的数'''
new=np.zeros(shape=(self.popsize,self.length))
for i in range(self.length):
new[:,i]=2**(self.length-1-i)*pop[:,i]
new=self.domain*np.sum(new,axis=1)/2**(self.length)
return new
def selection(self,pop):
'''对种群进行选择'''
value=self.bio_to_dec(pop)
idx=np.random.choice(np.arange(self.popsize),replace=True,size=self.popsize,
p=abs(self.function(value))/abs(self.function(value)).sum())
return pop[idx]
def mutation(self, pop, pm):
'''对种群进行变异'''
x,y= pop.shape
newpop = np.ones((x, y))
for i in range(x):
if np.random.rand() < pm:
mpoint = random.randint(0, y - 1)
newpop[i, :] = pop[i, :]
if newpop[i, mpoint] == 0:
newpop[i, mpoint] = 1
else:
newpop[i, mpoint] = 0
else:
newpop[i, :] = pop[i, :]
return newpop
def crossover(self,pop,pc):
'''对种群进行交叉'''
x,y=pop.shape
newpop=np.ones((x,y))
for i in range(0,x,2):
if np.random.rand()<pc:
cpoint=random.randint(0,y-1)
newpop[i,0:cpoint]=pop[i,0:cpoint]
newpop[i,cpoint:y]=pop[i+1,cpoint:y]
newpop[i+1,0:cpoint]=pop[i+1,0:cpoint]
newpop[i+1,cpoint:y]=pop[i,cpoint:y]
else:
newpop[i,:]=pop[i,:]
newpop[i+1,:]=pop[i,:]
return newpop
def main(self):
'''主函数,把以上三个操作拼接起来'''
for i in range(self.M):
print('the {} epoch'.format(i))
newpop=self.selection(pop=self.pop)
newpop=self.crossover(pop=newpop,pc=self.pc)
newpop=self.mutation(pop=newpop,pm=self.pm)
self.pop=newpop
newpop=self.selection(pop=self.pop)
return self.bio_to_dec(newpop)
g=GA(function=function)
x=np.arange(0,50,0.1)
y=function(x)
plt.plot(x,y,color="green")
xx=g.main()
yy=function(xx)
plt.scatter(xx,yy,color='red')
plt.show()
运行结果:
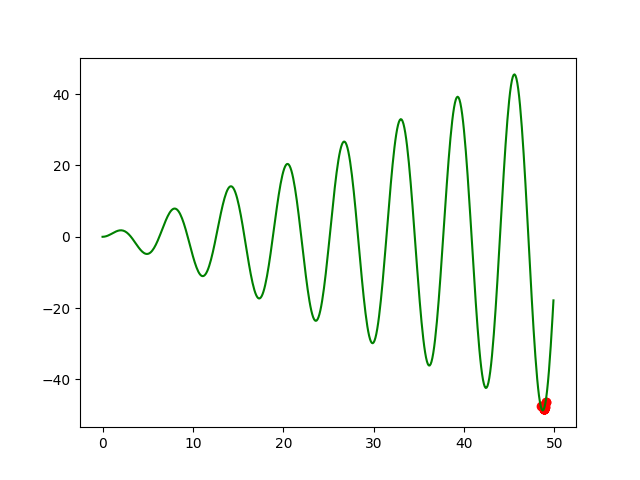
我们发现,结果最终是集中在函数极值附近。如果我们修改代数M这个参数,先赋予M一个比较小的数,比如M=4 时,如图3所示:
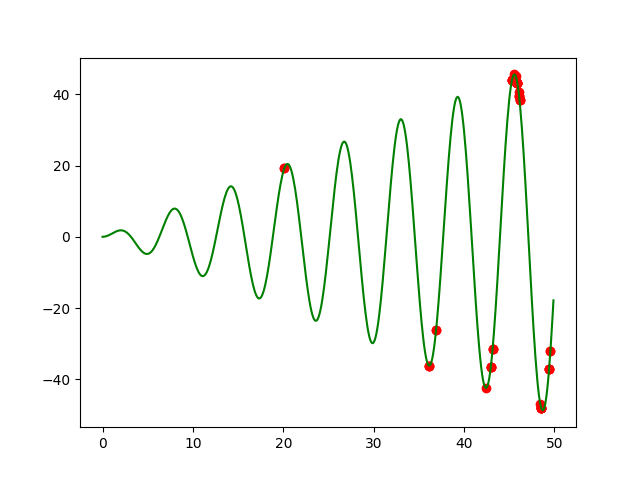
我们发现即使代数是4这么小的代数,结果基本上分别在局部最优解上了。所以遗传算法随着代数的增加,收敛速度是比较快的。至于染色体长度length,种群数popsize,突变概率于交叉概率等参数,感兴趣的小伙伴们也可以尝试一下,会发现有很多有趣的规律的。
同学们甚至可以像我前面提到的那样,把交叉,突变操作去掉,只进行选择操作,也会发现有同样的结果。这是因为种群数量比较大时就有部分初始解在极值点附近,随着筛选就慢慢浮出水面了。但是对于区间长度比较长的函数,或是可能解,就不能这样干啦。
今天先介绍到这里,下一次兔兔将讲解遗传算法在巡航问题中的应用。
Original: https://blog.csdn.net/weixin_60737527/article/details/123740486
Author: 生信小兔
Title: 遗传算法(GA)详解
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/613653/
转载文章受原作者版权保护。转载请注明原作者出处!