

ResNet backbone + SVM分类器
对于样本较为均衡小型数据集,SVM作为分类器的效果与MLP的效果相近。
从经验上看,对于样本不均衡的大型数据集,MLP的效果强于SVM。
本博客在自己的小型数据集上进行实验,本来使用MLP已经达到很好的效果,但导师让试一下SVM分类器,可能会对样本量较小的数据集表现稍好。虽然在心里觉得SVM这种方法不太可能有提高,但趁此机会学习一下SVM还是有好处的。
SVM相关知识:
这里仅作简单陈述,详细地可百度或B站,特别多资源
基本理念:最初的SVM是用来作二分类的,目标是在特征空间中找到一个超平面,让任意样本的点到平面的距离大于等于1。
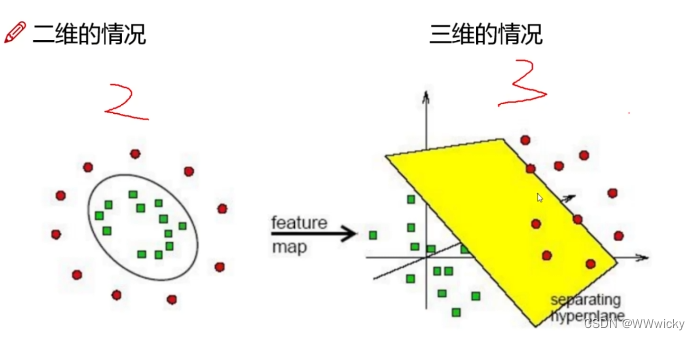
如果样本线性不可分,则需要使用核函数来进行非线性分类,也就是得到非线性超平面。
核函数
SVM可以通过核方法(kernel method)进行非线性分类,是常见的核学习(kernel learning)方法之一。一些线性不可分的问题可能是非线性可分的,即特征空间存在超曲面(hypersurface)将正类和负类分开。使用非线性函数可以将非线性可分问题从原始的特征空间映射至更高维的希尔伯特空间(Hilbert space)H ,从而转化为线性可分问题。

常见的核函数有:多项式核(阶为1时称为线性核)、径向基函数核(又称RBF核、高斯核)、拉普拉斯核、Sigmoid核。
常用线性核和高斯核。
参考自b站:https://www.bilibili.com/video/BV1mP4y137U4?p=2
; 线性核函数
解决问题 从简单的出发,先试一下线性核函数的效果!
公式注意是内积
适用于:特征已经比较丰富了,样本数据量大,即十万、百万这数量级。
多项式核函数(了解即可,不常用):
给定3个参数,Q控制高次项,越高次对应越复杂的边界,计算量也相应越大,具体视任务情况而定

γ和Q就是要调的超参,得在炼丹过程中调整。
高斯核函数——最常用的
公式如下:

高斯核函数能 把低维特征映射为无穷维的特征,比如有m个数据,每个数据是10维,那么根据公式可得到每个数据Xi和任意数据Xk的”距离”Dx,有m个数据,就计算m次,得到m个Xi与Xk的”距离”,然后将Xi里的第k个元素更换为Xi和Xk的”距离”,也就是变成m维了,因此 可用于扩充特征维度,让模型对数据点有更好的认识和区分。
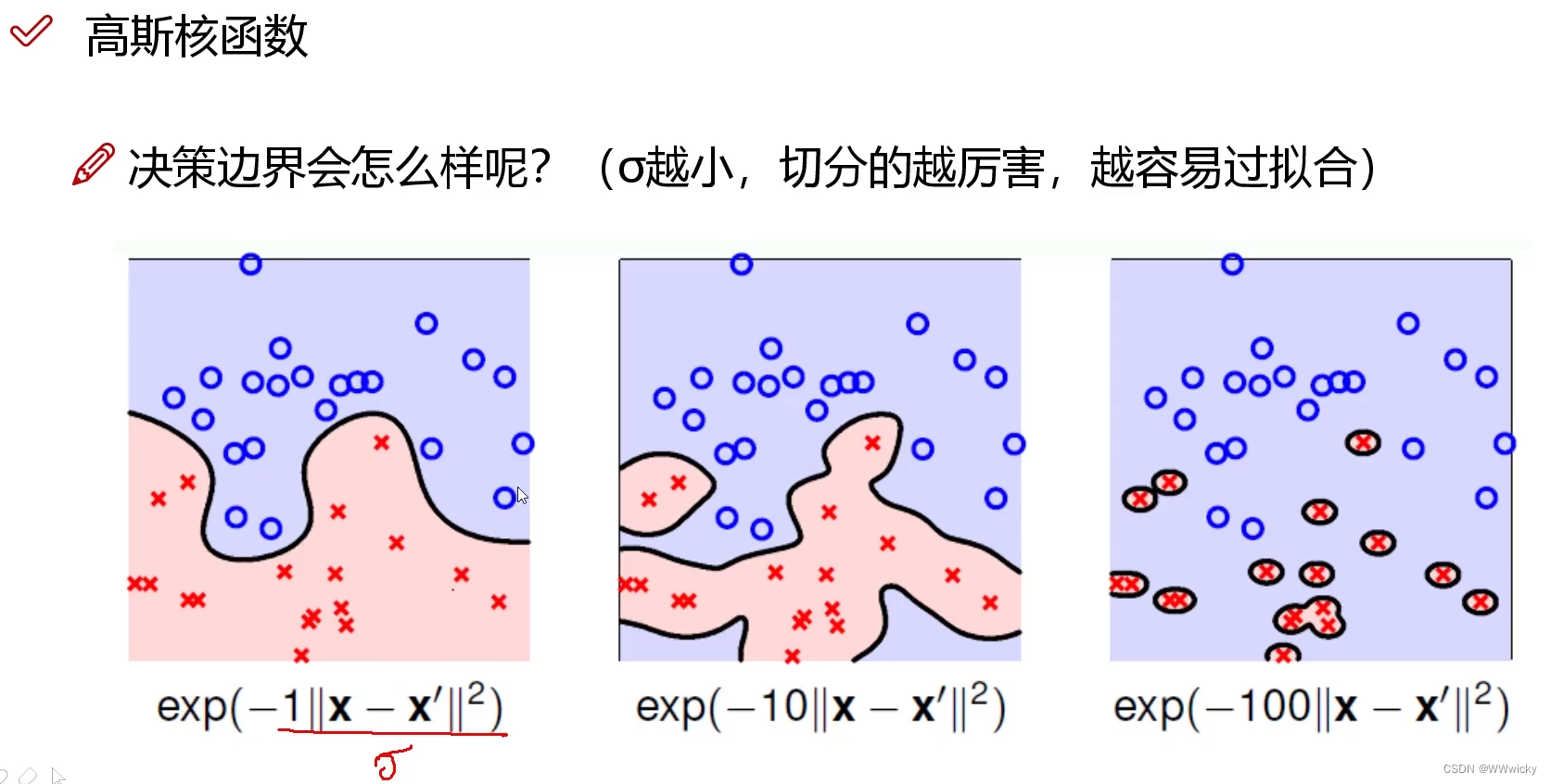
σ越小,越陡,特征越鲜明,可能对分类效果略好,但是风险越大,可以看第二张图。

; SVM多分类
SVM如何做多分类呢?有直接法和间接法,但直接法不常用,间接法中常用的时一对一(ovo)和一对多(ovr)策略
具体可以来看这篇文章
总结
一对一就是训练 m(m-1)/2 个分类器(m为类别总数),也就是每两个类别之间训练一个分类器,然后用投票法,将预测的变量输入到所有分类器中,预测为label k,则k的得票+1,统计所有的分类器的输出结果,得票最多的类别就是最终预测结果。
优劣:当类别很多时,model的个数是m(m-1)/2,代价很大哦
一对多就是对于第k个类别,将label k的样本设为正类,而其他类别的样本都设为负类,最后训练 m个分类器(m为类别总数)。预测时,将变量输入到所有分类器中,如果只有一个分类器输出正值,则可直接判定结果为该分类器对应的类别,否则选取判别函数值最大的分类器所对应的类别为最终预测结果。
优点:训练m个分类器,个数较少,其分类速度相对较快。
缺点:每个分类器的训练都是讲全部的样本作为训练样本,如果不是线性可分数据,训练速度会随着训练样本的数量增加而急剧减慢;同时由于负类样本的数据要远远大于正类样本的数据,从而出现了样本不对称的情况,且这种情况随着训练数据的增加而趋向严重。解决不对称的问题可以引 入不同的惩罚因子,对样本点来说较少的正类采用较大的惩罚因子。还有就是当有新的类别加进来时,需要对所有的模型进行重新训练。
SVM的优缺点: 引用
1、SVM算法对大规模训练样本难以实施
SVM的空间消耗主要是存储训练样本和核矩阵,由于SVM是借助二次规划来求解支持向量,而求解二次规划将涉及m阶矩阵的计算(m为样本的个数),当m数目很大时该矩阵的存储和计算将耗费大量的机器内存和运算时间。针对以上问题的主要改进有有J.Platt的SMO算法、T.Joachims的SVM、C.J.C.Burges等的PCGC、张学工的CSVM以及O.L.Mangasarian等的SOR算法。如果数据量很大,SVM的训练时间就会比较长,如垃圾邮件的分类检测,没有使用SVM分类器,而是使用了简单的naive bayes分类器,或者是使用逻辑回归模型分类。
2、用SVM解决多分类问题存在困难
经典的支持向量机算法只给出了二类分类的算法,而在数据挖掘的实际应用中,一般要解决多类的分类问题。可以通过多个二类支持向量机的组合来解决。主要有一对多组合模式、一对一组合模式和SVM决策树;再就是通过构造多个分类器的组合来解决。主要原理是克服SVM固有的缺点,结合其他算法的优势,解决多类问题的分类精度。如:与粗集理论结合,形成一种优势互补的多类问题的组合分类器。
3、对缺失数据敏感,对参数和核函数的选择敏感
支持向量机性能的优劣主要取决于 核函数的选取,所以对于一个实际问题而言,如何根据实际的数据模型选择合适的核函数从而构造SVM算法。目前比较成熟的核函数及其参数的选择都是人为的,根据经验来选取的,带有一定的随意性.在不同的问题领域,核函数应当具有不同的形式和参数,所以在选取时候应该将领域知识引入进来,但是目前还没有好的方法来解决核函数的选取问题。
实现
用scikit-learn包(sklearn)中的svm即可:官网地址
SVC
LinearSVC
我的实现是使用ResNet50作为特征提取器(去掉最后一层),先加上MLP预训练35个epoch,然后将特征提取器的输出降维(1024维的特征)输入到SVM中进行训练并得到输出,然后评估结果即可。
在我的小型数据集上实现时, 后续要做添加惩罚因子的实验。
Class Classifer(nn.Module):
def __init__(self):
super(Classifier,self).__init__()
renet50 = torchvision.models.resnet50(pretrained)
modules = list(resnet.children())[:-1]
self.resnet = nn.Sequential(*modules)
self.linear0 = nn.Linear(resnet.fc.in_features, 1024)
def forward(self,images):
features = self.resnet(images)
features = features.reshape(features.size(0), -1)
self.featuremap2048 = copy.deepcopy(features.detach())
features = self.linear0(features)
features = self.relu(features)
self.featuremap1024 = copy.deepcopy(features.detach())
...省略掉MLP的forward
for i, (images, classes, lengths) in enumerate(train_loader):
images = images.to(device)
classes = classes.to(device)
targets = classes
with torch.no_grad():
outputs = classifier(images)
featuremap = classifier.featuremap1024
featuremap_np = featuremap.cpu().numpy()
targets_np = targets.cpu().numpy()
svm_clf.fit(featuremap_np,targets_np)
np_targets_long = []
outputs_label_long_list = []
for m, (images, classes, lengths) in enumerate(test_loader):
images_test = images.to(device)
with torch.no_grad():
outputs_test_tensor = classifier(images_test)
featuremap_np_test = classifier.featuremap1024.cpu().numpy()
np_targets = classes.numpy()
np_outputs = svm_clf.predict(featuremap_np_test)
np_targets_long.extend(np_targets)
outputs_label_long_list.extend(np_outputs)
testset_acc = precision_score(np_targets_long, outputs_label_long_list, average='micro')
Original: https://blog.csdn.net/qq_43679439/article/details/124606380
Author: WWwicky
Title: 使用SVM分类器进行图像多分类
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/613613/
转载文章受原作者版权保护。转载请注明原作者出处!