

SimSiam
孪生网络已经成为无监督视觉表征学习的一种常见结构。孪生网络最大化一个图像的两个增广之间的相似性。论文提出了一个简单的孪生网络(SimSiam)在 不需要负样本对、大的批次和动量编码的情况下学习表征。
对比学习的核心思想是吸引正样本对,排斥负样本对。对比学习在无监督(自监督)表征学习中广泛应用。基于孪生网络的简单高效的对比学习实例方法已经被开发出来。实际上,对比学习方法从大量的负样本的获益,InfoDist方法使用一个memory bank存放负样本对;基于孪生网络,MoCo维持一负样本对队列并且将一个分支作为动量编码器来提高队列的一致性;SimCLR直接使用当前批次中共存的负样本,所以它需要一个大的batch size。BYOL不使用负样本对,它从图像的一个视图直接预测另一个视图的输出。BYOL本质上也是一个孪生网络,它的一个分支是一个动量编码器。BYOL的动量编码器防止模型坍塌。
论文发现 stop-gradient操作是防止模型坍塌的关键,SimSiam算法在不使用负样本,也不需要动量编码器的情况下,直接最大化一张图片的两个视图的相似性。而且它不需要一个大的batch size去训练。SimSiam算法可以近似看做”不需要动量编码器的BYOL”。
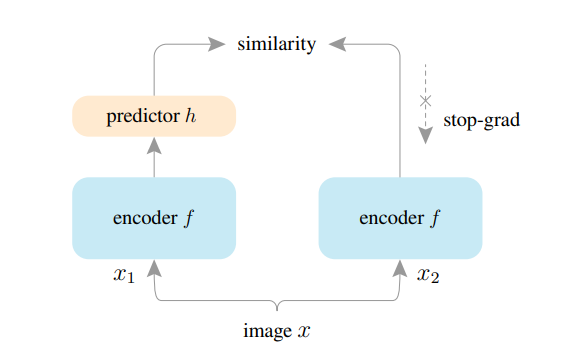

对于一个图像x x x,以它的两个随机增广视图x 1 x_{1}x 1 和x 2 x_{2}x 2 为输入,这两个视图经过一个编码网络f f f,编码网络包含一个backbone和一个projection MLPhead层。编码器f f f在这两个视图之间共享参数。一个预测MLP head,记为h h h,转换其中一个视图的输出并和另一个视图进行匹配。这两个输出向量记为p 1 = h ( f ( x 1 ) ) p_{1} = h\left( f\left( x_{1}\right) \right)p 1 =h (f (x 1 ))和z 2 = f ( x 2 ) z_{2} = f \left( x_{2} \right)z 2 =f (x 2 ),然后最小化它们的余弦相似度的负值。
D ( p 1 , z 2 ) = − p 1 ∥ p 1 ∥ 2 ⋅ z 2 ∥ z 2 ∥ 2 D\left( p_{1}, z_{2} \right) = – \frac{p_{1}}{\| p_{1} \|{2}} \cdot \frac{z{2}}{\|z_{2}\|{2}}D (p 1 ,z 2 )=−∥p 1 ∥2 p 1 ⋅∥z 2 ∥2 z 2
定义一个对称的loss,如下所示:
L = 1 2 D ( p 1 , z 2 ) + 1 2 D ( p 2 , z 1 ) L = \frac{1}{2} D\left( p{1}, z_{2} \right) + \frac{1}{2} D\left( p_{2}, z_{1}\right)L =2 1 D (p 1 ,z 2 )+2 1 D (p 2 ,z 1 )
这是每个图像的对称损失,总的损失函数是所有图像的对称损失的平均值。它的最小值是− 1 -1 −1。SimSiam算法的一个重要实现是stop-gradient操作,那么对称损失函数将变换如下所示。
L = 1 2 D ( p 1 , s t o p g r a d ( z 2 ) ) + 1 2 D ( p 2 , s t o p g r a d ( z 1 ) ) L = \frac{1}{2} D\left( p_{1}, stopgrad\left( z_{2} \right) \right) + \frac{1}{2} D\left( p_{2}, stopgrad\left( z_{1}\right) \right)L =2 1 D (p 1 ,s t o p g r a d (z 2 ))+2 1 D (p 2 ,s t o p g r a d (z 1 ))
其中D ( p 1 , s t o p g r a d ( z 2 ) ) D\left( p_{1}, stopgrad\left( z_{2} \right) \right)D (p 1 ,s t o p g r a d (z 2 ))意味着z 2 z_{2}z 2 是一个常数。simSiam的伪代码如下所示。

基础实现:
- 优化器:优化器使用SGD。基础学习率l r = 0.05 lr=0.05 l r =0.05,学习率为l r × B a t c h S i z e / 256 lr \times BatchSize / 256 l r ×B a t c h S i ze /256。学习率遵循余弦衰减时间表。weight decay为0.0001,SGD的动量为0.9,batch size为512。
- projection MLP:projection MLP有3层,每层fc有2048维。每一全连接层都包含BN,包括输出全连接层。输出全连接层中不包含ReLU。
- prediction MLP:prediction MLP有两层,隐含层中有BN操作,输出层中没有BN和ReLU。h h h的输入和输出维度都是2048,h h h的隐藏层维度为512。2048–>512–>2048
- backbone:ResNet-50
class SimSiam(nn.Module):
"""
Build a SimSiam model.
"""
def __init__(self, base_encoder, dim=2048, pred_dim=512):
"""
dim: feature dimension (default: 2048)
pred_dim: hidden dimension of the predictor (default: 512)
"""
super(SimSiam, self).__init__()
self.encoder = base_encoder(num_classes=dim, zero_init_residual=True)
prev_dim = self.encoder.fc.weight.shape[1]
self.encoder.fc = nn.Sequential(nn.Linear(prev_dim, prev_dim, bias=False),
nn.BatchNorm1d(prev_dim),
nn.ReLU(inplace=True),
nn.Linear(prev_dim, prev_dim, bias=False),
nn.BatchNorm1d(prev_dim),
nn.ReLU(inplace=True), 第二层 conv-BN-ReLU
self.encoder.fc,
nn.BatchNorm1d(dim, affine=False))
self.encoder.fc[6].bias.requires_grad = False
self.predictor = nn.Sequential(nn.Linear(dim, pred_dim, bias=False),
nn.BatchNorm1d(pred_dim),
nn.ReLU(inplace=True),
nn.Linear(pred_dim, dim))
def forward(self, x1, x2):
"""
Input:
x1: first views of images
x2: second views of images
Output:
p1, p2, z1, z2: predictors and targets of the network
See Sec. 3 of https://arxiv.org/abs/2011.10566 for detailed notations
"""
z1 = self.encoder(x1)
z2 = self.encoder(x2)
p1 = self.predictor(z1)
p2 = self.predictor(z2)
return p1, p2, z1.detach(), z2.detach()
criterion = nn.CosineSimilarity(dim=1).cuda(args.gpu)
p1, p2, z1, z2 = model(x1=images[0], x2=images[1])
loss = -(criterion(p1, z2).mean() + criterion(p2, z1).mean()) * 0.5
下图是”witd vs witdout stop-gradient”单一变量实验结果比较。左图是训练损失,witdout stop-gradient,优化器快速找到一个退化解,并且达到最小损失值− 1 -1 −1。为了显示这个退化解是由模型坍塌导致的,作者研究了l 2 l_{2}l 2 正则化输出z / ∥ z ∥ 2 z / \| z \|_{2}z /∥z ∥2 的标准差std。如果输出坍塌为一个常数向量,那么它们在所有例子上的std对于每一个通道应当是0,中间图的红色曲线验证了这一点。如果输出z z z具有零均值各向同性高斯分布,那么的标准差为1 d \frac{1}{\sqrt{d}}d 1 ,中间图的蓝色曲线显示在带有stop-gradient的情况下,它的标准差接近于1 d \frac{1}{\sqrt{d}}d 1 。

总结
linear classification protocol的原则是:在1N-1M数据集上预训练之后,冻结特征层,然后训练一个线性分类器,线性分类器由一个全连接层和一个softmax层组成。下面展示各自监督算法的线性分类结果。
metdodarchitecture#params(M)top 1top 5batch size epochesMoCoResNet-5024M60.6-256200SimCLRResNet-5024M69.389.040961000MoCo v2ResNet-50-71.1-256800BYOLResNet-5024M74.391.640961000SimSiamResNet-50-71.3-256800MoCo v3ResNet-50-73.8-4096800MoCo v3ViT-B86M76.7-4096300
Original: https://blog.csdn.net/weixin_42111770/article/details/123723652
Author: 陶将
Title: 对比学习系列(五)—SimSiam
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/613396/
转载文章受原作者版权保护。转载请注明原作者出处!