

本人使用训练图片用在目标跟踪上作为数据集扩展,因此只查看了train的json文件。
目录
绪论
COCO的全称是Common Objects in Context,是微软团队提供的一个可以用来进行图像识别的数据集。MS COCO数据集中的图像分为训练、验证和测试集。论文 、数据集官方网址
CoCo2017数据集包括train(118287张)、val(5000张)、test(40670张)
CoCo也有官方的API,我是自己根据自己的想法来提取想要的类别图片来训练。
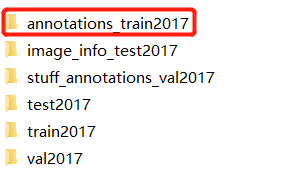
数据集的文件夹及名称


数据集标注json文件所在目录
目标检测/实例分割数据标注文件解析
train图片的标注文件
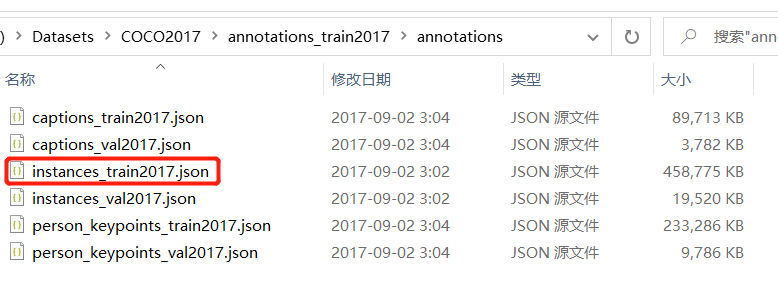
; 标注文件:instances_train2017.json
本文以 COCO2017\annotations_train2017\annotations\instances_train2017.json
为例子。
这个json文件中的信息有以下5个键值所指。
基本结构如下:
{
“info”: {…},
“licenses”: […],
“images”: […],
“categories”: […],
“annotations”: […]
}
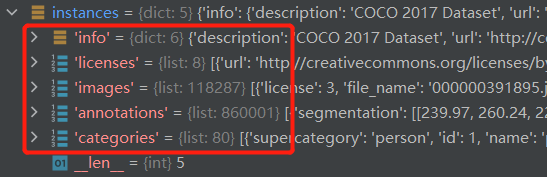
其中info、images、licenses三个key是不同类型标注文件共享的,最后的annotations和categories按照不同的任务有所不同。
info:
该字典包含有关数据集的元数据,对于官方的 COCO 数据集,如下:
{
“description”: “COCO 2017 Dataset”,
“url”: “http://cocodataset.org”,
“version”: “1.0”,
“year”: 2017,
“contributor”: “COCO Consortium”,
“date_created”: “2017/09/01”
}
如我们所见,它仅包含基本信息,”url”值指向数据集官方网站(例如 UCI 存储库页面或在单独域中),这是机器学习数据集中常见的事情,指向他们的网站以获取更多信息,例如获取数据的方式和时间。
licenses:
以下是数据集中图像许可的链接,例如知识共享许可,具有以下结构:
[
{
“url”: “http://creativecommons.org/licenses/by-nc-sa/2.0/”,
“id”: 1,
“name”: “Attribution-NonCommercial-ShareAlike License”
},
{
“url”: “http://creativecommons.org/licenses/by-nc/2.0/”,
“id”: 2,
“name”: “Attribution-NonCommercial License”
},
…
]
这里要注意的重要一点是”id”字段——”images”字典中的每个图像都应该指定其许可证的”id”。
在使用图像时,请确保没有违反其许可——可以在 URL 下找到全文。
如果我们决定创建自己的数据集,请为每个图像分配适当的许可——如果我们不确定,最好不要使用该图像。
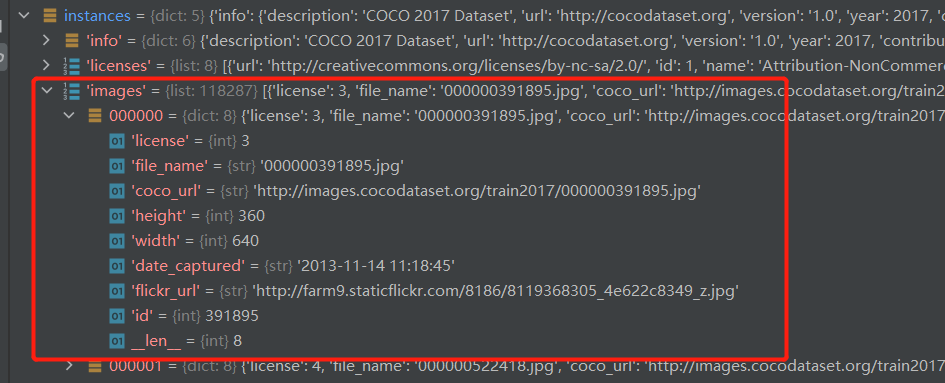
image:
这个字典还包含了所有的图片的名称但是没有图片中目标的信息
包含有关图像的元数据:
{
“license”: 3,
“file_name”: “000000391895.jpg”,
“coco_url”: “http://images.cocodataset.org/train2017/000000391895.jpg”,
“height”: 360,
“width”: 640,
“date_captured”: “2013–11–14 11:18:45”,
“flickr_url”: “http://farm9.staticflickr.com/8186/8119368305_4e622c8349_z.jpg”,
“id”: 391895
}
接下来我们详细看看:
“license”:来自该”licenses” 部分的图像许可证的 ID
“file_name”: 图像目录中的文件名
“coco_url”, “flickr_url”: 在线托管图像副本的 URL
“height”, “width”: 图像的大小,在像 C 这样的低级语言中非常方便,在这种语言中获取矩阵的大小是非常困难的
“date_captured”: 拍照的时间
“id”领域是最重要的领域,这是用于”annotations”识别图像的编号,因此如果我们想识别给定图像文件的注释,则必须在”图像”中检查相应图像文档的”id”,然后在”注释”中交叉引用它。
在官方COCO数据集中”id”与”file_name”相同。需要注意的是,自定义 COCO数据集可能不一定是这种情况!这不是强制的规则,例如由私人照片制成的数据集可能具有与没有共同之处的原始照片名称”id”。
; categories:
类别信息
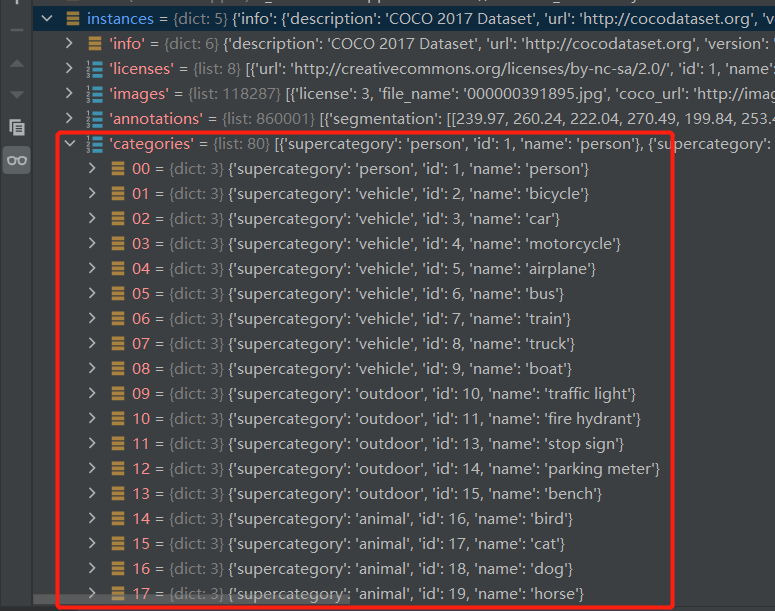
对象检测/对象分割:
[
{“supercategory”: “person”, “id”: 1, “name”: “person”},
{“supercategory”: “vehicle”, “id”: 2, “name”: “bicycle”},
{“supercategory”: “vehicle”, “id”: 3, “name”: “car”},
…
{“supercategory”: “indoor”, “id”: 90, “name”: “toothbrush”}
]
这些是可以在图像上检测到的对象类别(”categories”在 COCO 中是类别的另一个名称,我们可以从监督机器学习中了解到)。
每个类别都有一个唯一的”id”,它们应该在 [1,number of categories] 范围内。类别也分为”超类别”,我们可以在程序中使用它们,例如,当我们不关心是自行车、汽车还是卡车时,一般检测车辆。
annotations:
这是数据集最重要的部分,是对数据集中所有目标信息的介绍。
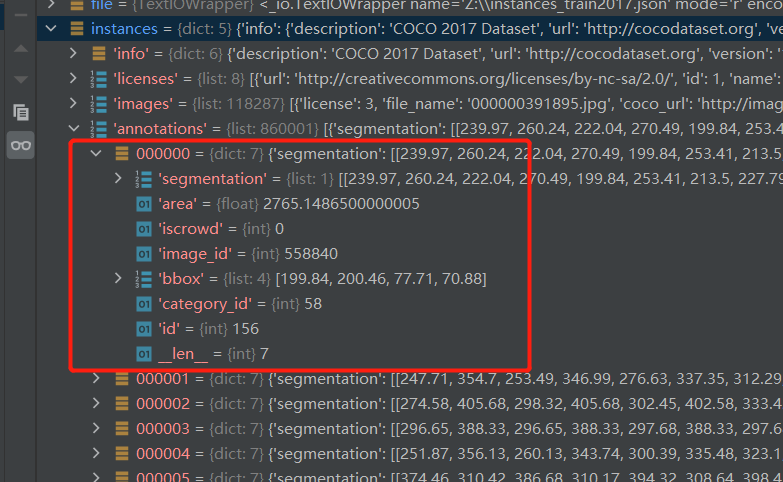
“segmentation”:分割掩码像素列表;这是一个扁平的对列表,因此我们应该采用第一个和第二个值(图片中的 x 和 y),然后是第三个和第四个值,以获取坐标;需要注意的是,这些不是图像索引,因为它们是浮点数——它们是由 COCO-annotator 等工具从原始像素坐标创建和压缩的
“area”:分割掩码内的像素数
“iscrowd”:注释是针对单个对象(值为 0),还是针对彼此靠近的多个对象(值为 1);对于实例分割,此字段始终为 0 并被忽略
“image_id”: ‘images’ 字典中的 ‘id’ 字段;就是图片的名称去除了后缀名
“bbox”:边界框,即对象周围矩形的坐标(左上x,左上y,宽,高);
“category_id”:对象的类,对应”类别”中的”id”字段
“id”: 注释的唯一标识符;警告:这只是注释ID,这并不指向其他词典中的特定图像!
最后使用数据集时,要使用image_id来获取目标所在的图片,使用bbox获得目标的边界框,category_id来获得目标的类别,这是最主要的三个参数
; 代码
import json
import os
from Tools import progressDialog
"""
instances = {
'info':a dict [保存的是数据集的一些元信息,使用中没有用到,可以忽略],
'licenses':a list [一些共享知识,图像的一些许可链接],
'images':a list [保存的是所有训练train图片的信息,比如说是图片的名称,图片的来源网址,图像的宽高等等],
'categories': a list [保存的是所有类别,,每个列表保存一个类别信息,有超类,类别id,类别的名字,这三个信息],
'annotations': a list [保存的是所有目标的信息,列表中每个元素是一个字典,字典中有分割需要的信息,和检测需要的信息,]
}
着重介绍一下images、annotations这两个列表中的信息,都是一个列表,每个列表的元素是一个字典
'images' = [{'license' : 3(a int),
'file_name' : '000000391895.jpg'(a str),
'coco_url' : 网址(a str),
'height' : 360(a int),
'width' : 640(a int),
'date_captured" : 时间(a str),
'flickr_url' : 网址(a str),
'id' : 8(a int)},
{}, ....]
'annotations' = [{'segmentation' : [[float, ....]](a list),
'area' : (a float),
'iscrowd' : 0(a int),
'image_id' : 558840(a int),
'bbox' : [float, float, float, float](a list),
'category_id' : 58(a int),
'id' : 156(a, int)},
{}, ....]
"""
class AnalysisCoCo:
"""
保存的数据格式
{'000000000025' : {'path' : r'Z:\\Datasets\\COCO2017\\train2017\\000000000025.jpg',
'objects':[{'bbox' : [float, float, float, float],
'category_id':str,
'category_name':str}, {}, ...]},
'000000000026' : {'path' : r'Z:\\Datasets\\COCO2017\\train2017\\000000000026.jpg',
'objects':[{'bbox' : [float, float, float, float],
'category_id':str,
'category_name':str}, {}, ...]},
....
}
"""
def __init__(self, root, save, name="CoCo", is_train=True, bbox_area_thresh=500., cls=()):
"""
:param root: 数据集的根目录
:param save: 保存生成文件的目录
:param name: 数据集名称
:param is_train: 训练数据集还是验证数据集
:param bbox_area_thresh: 选取的边界框的面积阈值
:param cls: 保留下来的类别
"""
self.name = name
self.bbox_area_thresh = float(bbox_area_thresh)
self.cls = cls
self.flag = False if len(cls) == 0 else True
self.root = root
self.save = self._check_dir(os.path.join(save, name))
if is_train:
self.instances_path = 'instances_train2017.json'
self.sub_dir = 'train2017'
else:
self.instances_path = 'instances_val2017.json'
self.sub_dir = 'val2017'
self.analysis_coco()
def analysis_coco(self):
instances = self._read_json(os.path.join(self.root, 'annotations_train2017',
'annotations', self.instances_path))
categories = instances['categories']
classes = {}
for step, category in enumerate(categories):
progressDialog(len(categories), step, information='类别信息提取中...')
name = category['name']
id_ = category['id']
classes[str(id_)] = name
annotations = instances['annotations']
information = {}
image_name = []
for step, annotation in enumerate(annotations):
progressDialog(len(annotations), step, information="目标性信息正在提取中...")
image_id = annotation['image_id']
bbox = annotation['bbox']
category_id = annotation['category_id']
iscrowd = annotation['iscrowd']
if self.flag and classes[str(category_id)] not in self.cls:
continue
if bbox[2] * bbox[3] >= self.bbox_area_thresh:
if image_id not in image_name:
image_name.append(image_id)
information['%012d' % image_id] = {'path': os.path.join(self.root,
self.sub_dir,
'%012d.jpg' % image_id),
'objects': [{'bbox': bbox,
'category_id': str(category_id),
'category_name': classes[str(category_id)],
'iscrowd': iscrowd}]}
else:
information['%012d' % image_id]['objects'].append({'bbox': bbox,
'category_id': str(category_id),
'category_name': classes[str(category_id)],
'iscrowd': iscrowd})
else:
continue
self._save_json(os.path.join(self.save, 'classes.json'), classes)
self._save_json(os.path.join(self.save, 'CoCo.json'), self.sorted_dict(information))
print("Finish...")
@staticmethod
def sorted_dict(_dict: dict):
_tuple = sorted(_dict.items(), key=lambda item: item[0])
_dict = {k: v for k, v in _tuple}
return _dict
@staticmethod
def _read_json(_path):
with open(_path, 'r', encoding='utf-8') as file:
information = json.load(file)
return information
@staticmethod
def _save_json(_path, lines: dict):
print("Saving file to %s" % _path)
with open(_path, 'w', encoding='utf-8') as file:
json.dump(lines, file, indent=4)
@staticmethod
def _check_dir(_path):
if not os.path.exists(_path):
os.makedirs(_path)
return _path
if __name__ == '__main__':
project_path = os.path.dirname(os.getcwd())
print("Analysis CoCo ...")
coco = AnalysisCoCo(root=os.path.join(r'Z:\Datasets', 'COCO2017'),
save=os.path.join(project_path, 'datasets_txt'),
bbox_area_thresh=1314.0,
cls=("person", "car", "airplane", "motorcycle",
"truck", "boat", "cat", "dog", "horse", "sheep",
"cow", "elephant", "bear", "zebra", "giraffe",))
Original: https://blog.csdn.net/weixin_50727642/article/details/122892088
Author: 沐枫8023
Title: CoCo2017数据集使用(简单介绍)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/613348/
转载文章受原作者版权保护。转载请注明原作者出处!