

Insert优化
优化原因:MYSQL数据库中insert每执行一次都会对数据库进行一次连接,会浪费很大资源。
优化方案:
批量插入
插入数据的时候尽量一次性批量插入多个数据而不是一个数据插入一次。
手动提交事务
在事务中写多个insert语句最后一次性commit提交。
主键顺序插入
插入数据的时候尽量1,2,3,4按照顺序插入从而避免更多的资源浪费。
大批量数据插入
使用load指令直接将本地的大批量数据加载到数据库中。
用法:
- 查看是否打开了本地加载数据的开关
select @@local_infile;
- 进入数据库的时候加上参数
Mysql -local-infile -u 账户 -p 密码
- 开启加载本地文件到数据库的开关
set global local_infile=1;
- 加载数据
load data local infile '本地数据文件路径' into table 表名 fields terminated by '一行内数据的分割符号' , lines terminated by '换行符号';
主键优化
索引组织表(IOT)
在innodb引擎中表数据是根据主键顺序存放的。这种存储关系叫 索引组织表(IOT)
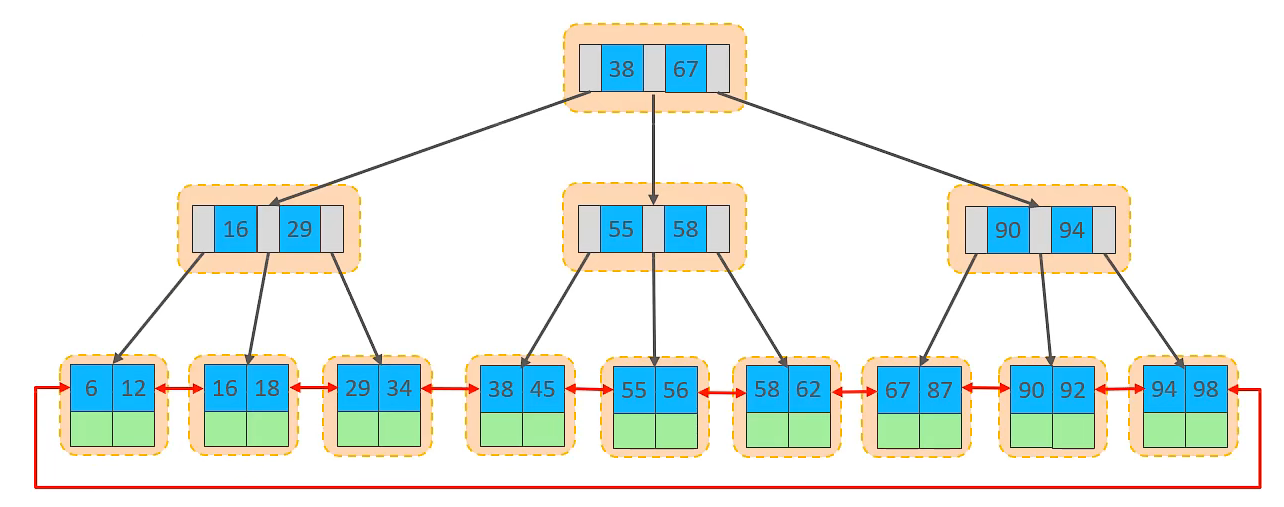

如上图,就是以主键顺序存放的索引组织表。
叶子节点存放数据,非叶子节点起到索引的作用。
这些黄色的块全部是由逻辑层次结构页(page)组成的。
页是innodb磁盘管理的最小单元,最大16k
页内数据根据主键顺序插入
页分裂
页可以为空,可以存一半,可以充满。
每一个页知识包含2行数据,如果某一行数据过大会产生行溢出现象。
主键顺序插入的流程图
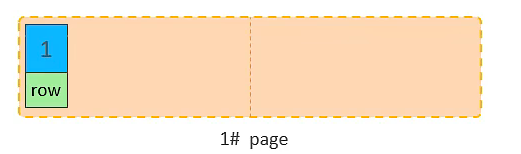
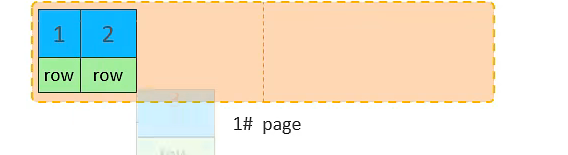
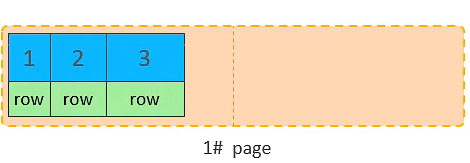
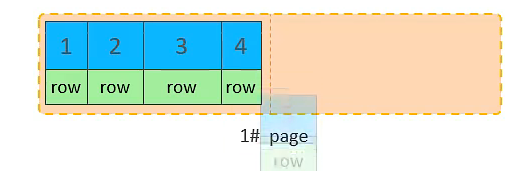
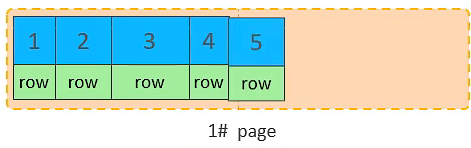
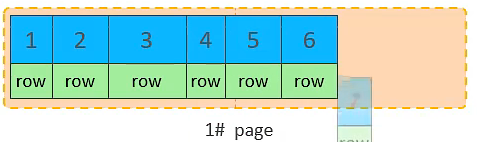
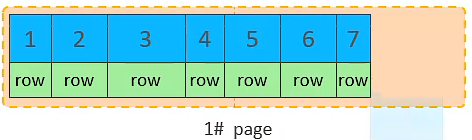

10. 将第二页写满

主键乱序插入的流程图



页合并

当删除一行记录时,实际上并没有被物理删除,只是被标记为删除并且他的空间变得运行其他记录声明使用。
当页中删除的记录达到 MERGE_THRESHOLD(默认为页的50%),InnoDB会开始寻找最靠近的页(前或后)看看是否可以将俩个页合并从而优化空间使用。
最终会变成如图

MERGE_THRESHOLD页合并参数的阈值,可以自己设置,在创建表或者索引的时候指定即可。
MERGE_THRESHOLD参数设置过程
创建表的时候设置
create table 表名(
字段1 类型,
...
字段n 类型
)comment='MERGE_THRESHOLD=45';
修改
ALTER TABLE t1 COMMENT='MERGE_THRESHOLD=40';
主键设计原则
- 尽量降低主键的长度 理由:在聚集索引和二级索引中,如果二级索引很多并且,主键索引很长那么会占用很大的空间,搜索的时候会降低大量的磁盘io。
- 插入数据的时候尽量使用顺序插入,auto_increment约束
理由:如果乱序插入会可能出现页分裂现象
- 业务操作的时候避免对主键的修改
Order by优化
explain中的extra会出现俩种情况在order by中
- using filesort
通过表的扫描或者索引,读取满足条件的数据行,然后在 排序缓冲区(sort buffer)中完成排序操作,所有不是通过索引直接返回排序结构的叫using filesort,需要查出来后额外排序,效率低。
- using index
通过有序索引顺序扫描直接返回有序结构,不需要额外排序操作,效率高。
- *将using filesort优化成using index的办法
解决办法:在创建索引的时候规定排序方式
create index 索引名 on 表名(字段1 排序方式,字段2 排序方式...);
注意要点:记得遵循索引规则
- *如果无法避免必须使用using filesort
可以增加sort_buffer_size区的大小(默认256kb)
查询sort_buffer_size的大小
show variables like 'sort_buffer_size';
设置sort_buffer_size的大小
set global sort_buffer_size=大小;
Group by优化
explain中的extra会出现一种情况说明group by的效率较低
- using tempory 代表MYSQL使用了临时表
解决办法:给分组的字段加上索引即可解决。
Limit优化
对于Limit进行大数据量的分页,页越往后效率就越低。
原因:limit 2百万 10 需要对2百万的数据进行排序再返回2百万–2百万零10的记录并丢失其他记录。
解决办法:
一般分页查询的时候,通过创建覆盖索引能提高性能,可以通过 覆盖索引+子查询的方式进行优化。
用法举例
假设我们有一张表student
id name 1 a 2 d 3 d 4 c 5 a
假设这张表有1千万条数据id最大=1千万。
这张表的id为主键索引
select id from a order by id limit 90000,10; ->子查询
select s.* from student s,(select id from a order by id limit 90000,10) a where s.id=a.id;
这样通过子查询+覆盖索引可优化limit
Count优化
- 在MYISM存储引擎
- 在InnoDB存储引擎中他会将表一行行读取并累加,类似与循环+
优化思路:使用触发器在insert或者delete的时候+1或-1并存储在表中某一字段内即可。
count的几种情况
count(*) InnoDB引擎不会把字段全部取出而是专门做了优化,不取值直接在服务层按行进行类型。 count(1) 我们所查询的每一条记录都会放一个1进去,然后在服务器层对数据进行累加(如果是1不是null就+1) count(主键) InnoDB引擎会遍历整张表,然后把每一行的主键id值取出,返回给服务器层,服务器层拿到后直接开始累加(因为主键不可能为null) count(字段) 1. 没有not null约束:innoDB引擎会遍历整张表,然后把每一行的字段值取出返回给服务器层判断是否为null 2. 有not null的约束:InnoDB引擎会遍历整张表,然后把每一行的字段值取出返回给服务器层直接开始累加
从上到小效率依次降低
Update优化(避免行锁升级为表锁)
在InnoDB引擎中开启事务后执行update语句他会将数据行锁住即行锁。
事务没提交前行锁不会释放。
注意一定要对索引数据进行更新才能避免从行锁升级为表锁。
原因:在InnoDB引擎中他不是针对记录加的行锁而是根据索引加的行锁,在更新数据的时候如果索引失效那么就会从行锁升级为表锁。
Original: https://www.cnblogs.com/wdadwa/p/MYSQL_Learning_08.html
Author: wdadwa
Title: MYSQL–>SQL优化
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/611868/
转载文章受原作者版权保护。转载请注明原作者出处!