

训练神经网络时,最常用的算法就是 反向传播。在该算法中,参数(模型权重)会根据损失函数关于对应参数的梯度进行调整。
为了计算这些梯度,PyTorch内置了名为 torch.autograd 的微分引擎。它支持任意计算图的自动梯度计算。
一个最简单的单层神经网络,输入 x,参数 w 和 b,某个损失函数。它可以用PyTorch这样定义:
import torch
x = torch.ones(5) # input tensor
y = torch.zeros(3) # expected output
w = torch.randn(5, 3, requires_grad=True)
b = torch.randn(3, requires_grad=True)
z = torch.matmul(x, w) + b # 矩阵乘法
loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)
Tensors、Functions and Computational graph
上述代码定义了下面的 computational graph:
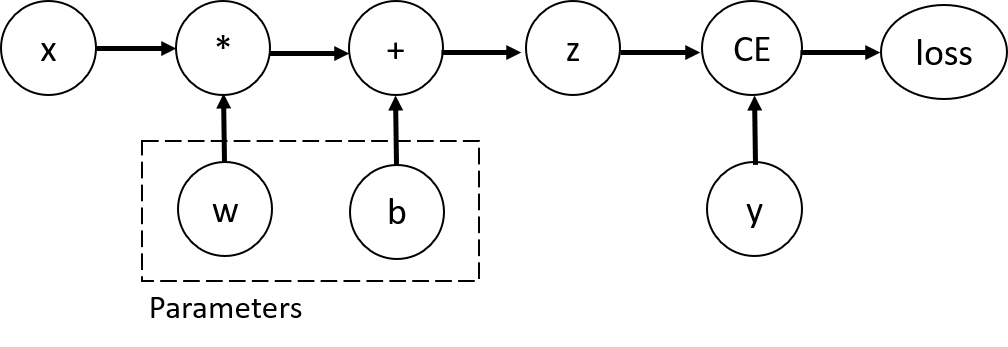

在该网络中, w 和 b 是 parameters,是我们需要优化的。因此,我们需要能够计算损失函数关于这些变量的梯度。因此,我们设置了这些tensor的 requires_grad 属性。
注意:在创建tensor时可以设置 requires_grad 的值,或者创建之后使用 x.requires_grad_(True) 方法。
我们应用到tensor上构成计算图的function实际上是 Function 类的对象。该对象知道如何计算前向的函数,还有怎么计算反向传播步骤中函数的导数。反向传播函数存储在tensor的 grad_fn 属性中。You can find more information of Function in the documentation。
print('Gradient function for z =', z.grad_fn)
print('Gradient function for loss =', loss.grad_fn)
输出:
Gradient function for z = <addbackward0 object at 0x7faea5ef7e10>
Gradient function for loss = <binarycrossentropywithlogitsbackward0 object at 0x7faea5ef7e10>
</binarycrossentropywithlogitsbackward0></addbackward0>
计算梯度
为了优化神经网络的参数权重,我们需要计算损失函数关于参数的导数,即,我们需要利用一些固定的 x 和 y 计算(\frac{\partial loss}{\partial w})和(\frac{\partial loss}{\partial b})。为计算这些导数,可以调用 loss.backward(),然后从 w.grad 和 b.grad:
loss.backward()
print(w.grad)
print(b.grad)
输出:
tensor([[0.0043, 0.2572, 0.3275],
[0.0043, 0.2572, 0.3275],
[0.0043, 0.2572, 0.3275],
[0.0043, 0.2572, 0.3275],
[0.0043, 0.2572, 0.3275]])
tensor([0.0043, 0.2572, 0.3275])
注意:
- 我们只能在计算图中
requires_grad=True的叶节点获得grad属性。对于其它节点,梯度是无效的。 - 出于性能原因,我们只能对给定的graph使用
backward执行梯度计算。如果需要在同一graph调用若干次backward,在调用时,需要传入retain_graph=True。
禁用梯度跟踪
默认情况下,所有 requires_grad=True 的tensor都会跟踪它们的计算历史,并支持梯度计算。但是在一些情况下并不需要,例如,当我们已经训练了一个模型,并将其用在一些输入数据上,即,仅仅经过网络做前向运算。那么可以在我们的计算代码外包围 torch.no_grad() 块停止跟踪计算。
z = torch.matmul(x, w) + b
print(z.requires_grad())
with torch.no_grad():
z = torch.matmul(x, w) + b
print(z.requires_grad)
输出:
True
False
在tensor上使用 detach() 也能达到同样的效果
z = torch.matmul(x, w) + b
z_det = z.detach()
print(z_det.requires_grad)
输出:
False
禁止梯度跟踪的几个原因:
- 将神经网络的一些参数标记为 frozen parameters。这在finetuning a pretrained network中是非常常见的脚本。
- 当你只做前向过程,用于 speed up computations,因为tensor计算而不跟踪梯度将会更有效。
More on Coputational Graphs
概念上,autograd在一个由Function对象组成的有向无环图(DAG)中保留了数据(tensors)记录,还有所有执行的操作(以及由此产生的新的tensors)。在DAG中,叶节点是输入tensor,根节点是输出tensors。通过从根到叶跟踪该图,可以使用链式法则自动地计算梯度。
在前向过程中,autograd同时进行两件事:
- 运行请求的操作计算结果tensor
- 在DAG中保存操作的梯度函数
当在DAG根部调用 .backward()时,后向过程就会开始。 autograd会:
- 由每一个
.grad_fn计算梯度。 - 在对应tensor的 ‘.grad’ 属性累积梯度
- 使用链式法则,一直传播到叶tensor
注意: DAGs在PyTorch是动态的,需要注意的一点是,graph是从头开始创建的;在每次调用 .backward() 之后,autograd开始生成一个新的graph。这允许你在模型中使用控制流语句;如果需要,你可以在每次迭代中改变shape,size,and operations。
选读:Tensor梯度和Jacobian Products
延伸阅读
Original: https://www.cnblogs.com/DeepRS/p/15743698.html
Author: Deep_RS
Title: PyTorch介绍-使用 TORCH.AUTOGRAD 自动微分
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/609932/
转载文章受原作者版权保护。转载请注明原作者出处!