

一、环境准备
1.数据库
创建2个库2个表:
- ybe_shop_order_0
- product_order_0
- product_order_1
- ad_config
- product_order_item_0
- product_order_item_1
- ybe_shop_order_1
- product_order_0
- product_order_1
- ad_config
- product_order_item_0
- product_order_item_1
数据库脚本:
CREATE TABLE product_order_0 (
id bigint NOT NULL AUTO_INCREMENT,
out_trade_no varchar(64) DEFAULT NULL COMMENT '订单唯一标识',
state varchar(11) DEFAULT NULL COMMENT 'NEW 未支付订单,PAY已经支付订单,CANCEL超时取消订单',
create_time datetime DEFAULT NULL COMMENT '订单生成时间',
pay_amount decimal(16,2) DEFAULT NULL COMMENT '订单实际支付价格',
nickname varchar(64) DEFAULT NULL COMMENT '昵称',
user_id bigint DEFAULT NULL COMMENT '用户id',
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
CREATE TABLE ad_config (
id bigint unsigned NOT NULL COMMENT '主键id',
config_key varchar(1024) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '配置key',
config_value varchar(1024) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '配置value',
type varchar(128) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '类型',
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
CREATE TABLE product_order_item_0 (
id bigint unsigned NOT NULL AUTO_INCREMENT,
product_order_id bigint DEFAULT NULL COMMENT '订单号',
product_id bigint DEFAULT NULL COMMENT '产品id',
product_name varchar(128) DEFAULT NULL COMMENT '商品名称',
buy_num int DEFAULT NULL COMMENT '购买数量',
user_id bigint DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
2.代码工程
1.工程创建
- 创建Maven工程,添加相关Maven依赖,
1.8
11
11
2.5.5
3.4.0
1.18.16
4.1.1
4.12
1.1.16
true
org.springframework.boot
spring-boot-starter-web
${spring.boot.version}
org.springframework.boot
spring-boot-starter-test
${spring.boot.version}
test
com.baomidou
mybatis-plus-boot-starter
${mybatisplus.boot.starter.version}
mysql
mysql-connector-java
8.0.27
org.projectlombok
lombok
${lombok.version}
org.apache.shardingsphere
sharding-jdbc-spring-boot-starter
${sharding-jdbc.version}
junit
junit
${junit.version}
org.springframework.boot
spring-boot-maven-plugin
${spring.boot.version}
true
true
- 添加数据库配置文件,根据配置文件可知,配置了两个数据库ds0,ds1;
spring.application.name=yb-sharding-jdbc
server.port=8080
logging.level.root=INFO
打印执行的数据库以及语句
spring.shardingsphere.props.sql.show=true
数据源 ds0 ds1
spring.shardingsphere.datasource.names=ds0,ds1
第一个数据库
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://localhost:3306/ybe_shop_order0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=*****
第二个数据库
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://localhost:3306/ybe_shop_order1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=*****
二、分库分表实战
1.广播表介绍和配置实战
- 指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致
- 适用于数据量不大且需要与海量数据的表进行关联查询的场景
-
例如:字典表、配置表
-
添加AdConfigDO实体类和添加ProductOrderDOMapper类
//数据库实体类
@Data
@EqualsAndHashCode(callSuper = false)
@TableName("ad_config")
public class AdConfigDO {
private Long id;
private String configKey;
private String configValue;
private String type;
}
//数据库实体配置类
public interface AdConfigMapper extends BaseMapper<adconfigdo> {
}
</adconfigdo>
- 设置ad_config为广播表,如果需要配置多个用 逗号 (,) 分开;设置id为生成算法为雪花算法。配置文件中添加如下代码,
#配置广播表
spring.shardingsphere.sharding.broadcast-tables=ad_config
spring.shardingsphere.sharding.tables.ad_config.key-generator.column=id
spring.shardingsphere.sharding.tables.ad_config.key-generator.type=SNOWFLAKE
- 添加测试方法
@Test
public void testSaveAdConfig(){
AdConfigDO adConfigDO = new AdConfigDO();
adConfigDO.setConfigKey("banner");
adConfigDO.setConfigValue("ybe.com");
adConfigDO.setType("ad");
adConfigMapper.insert(adConfigDO);
}
- 执行结果,两个数据库的表都进行了更新。如下图
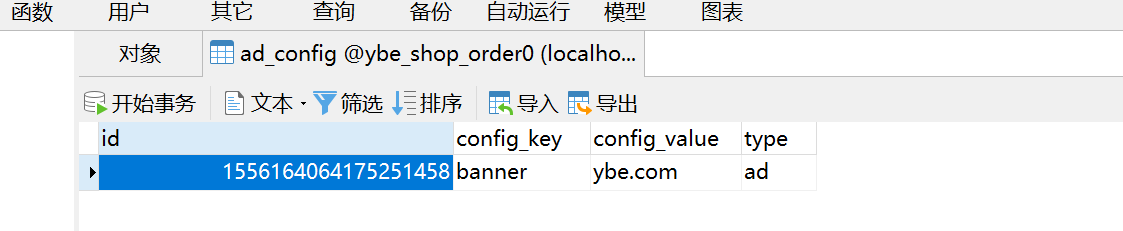


2.行表达式分片策略 InlineShardingStrategy
- 只支持【 单分片键】使用Groovy的表达式,提供对SQL语句中的 =和IN 的分片操作支持
-
可以通过简单的配置使用,无需自定义分片算法,从而避免繁琐的Java代码开发
-
添加ProductOrderDO实体类和添加ProductOrderDOMapper类
//数据库实体类
@Data
@TableName("product_order")
@EqualsAndHashCode(callSuper = false)
public class ProductOrderDO {
// 不设置Mybatis-plus的主键规则,由sharding-jdbc 设置
private Long id;
private String outTradeNo;
private String state;
private Date createTime;
private Double payAmount;
private String nickname;
private Long userId;
}
//数据库实体配置类
public interface ProductOrderMapper extends BaseMapper {
}
- 配置文件添加如下代码,
指定product_order表的数据分布情况,配置数据节点,行表达式标识符使用 ${...} 或 $->{...},但前者与 Spring 本身的文件占位符冲突,所以在 Spring 环境中建议使用 $->{...}
spring.shardingsphere.sharding.tables.product_order.actual-data-nodes=ds$->{0..1}.product_order_$->{0..1}
#id生成策略
spring.shardingsphere.sharding.tables.product_order.key-generator.column=id
spring.shardingsphere.sharding.tables.product_order.key-generator.type=SNOWFLAKE
#work_id 的设置
spring.shardingsphere.sharding.tables.product_order.key-generator.props.worker.id=1
#配置分库规则
spring.shardingsphere.sharding.tables.product_order.database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.product_order.database-strategy.inline.algorithm-expression=ds$->{user_id % 2}
#配置分表规则
#指定product_order表的分片策略,分片策略包括【分片键和分片算法】
spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.algorithm-expression=product_order_$->{id % 2}
由配置文件可知,
设置了product_order为逻辑表,设置了它的真实数据节点为ds$->{0..1}.product_order_$->{0..1},使用了表达式$->{…},它表示实际的物理表为:ds0.product_order_0,ds0.product_order_1,ds1.product_order_0,ds1.product_order_1,总共对应了2个库的2个物理表。
设置了product_order表的id计算方式为雪花算法;
设置了product_order表的分库规则,分库规则为 user_id % 2;也就是说会根据user_id % 2的结果确定是ds0库还是ds1库。
设置了product_order表的分表规则,分表规则为 id % 2;也就是说会根据id % 2的结果确定是product_order_0表还是product_order_1表。
- 添加测试方法
@Test
public void testSaveProductOrder(){
Random random = new Random();
for (int i = 0 ;i < 10 ; i++){
// id是由配置的雪花算法生成
ProductOrderDO productOrderDO = new ProductOrderDO();
productOrderDO.setCreateTime(new Date());
productOrderDO.setNickname("ybe:"+i);
productOrderDO.setOutTradeNo(UUID.randomUUID().toString().substring(0,32));
productOrderDO.setPayAmount(100.00);
productOrderDO.setState("PAY");
// 随机生成UserId
productOrderDO.setUserId(Long.valueOf(random.nextInt(50)));
productOrderMapper.insert(productOrderDO);
}
}
- 执行结果根据不同的user_id 和 id ,生成的表记录插入到了不同的库和表,如下图可以看到数据分散在了两个不同的数据库,以及不同的表中。


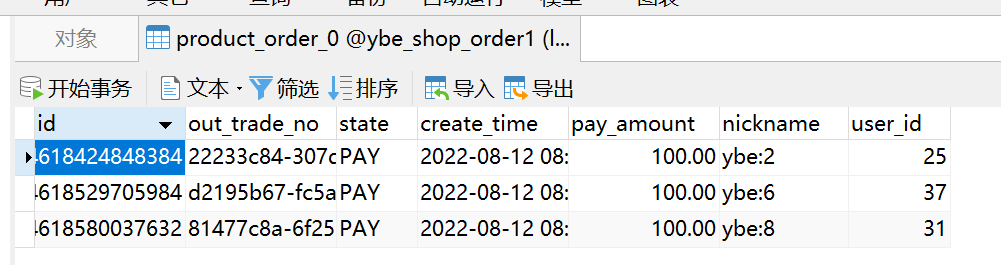
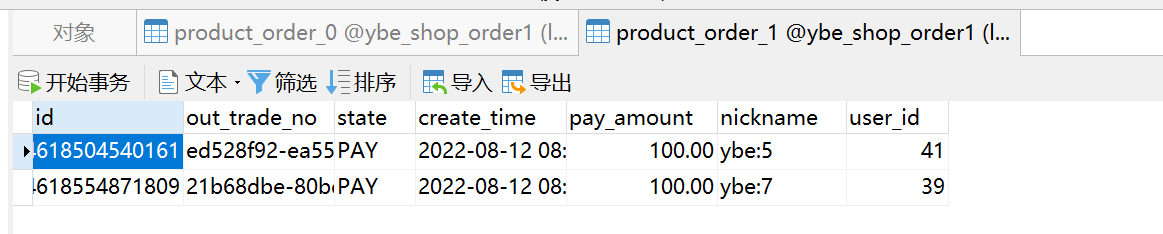
3.标准分片策略StandardShardingStrategy
- 只支持【 单分片键】,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法
- PreciseShardingAlgorithm 精准分片 是必选的,用于处理=和IN的分片
- RangeShardingAlgorithm 范围分片 是可选的,用于处理BETWEEN AND分片
-
如果不配置RangeShardingAlgorithm,如果SQL中用了BETWEEN AND语法,则将按照全库路由处理,性能下降
-
添加分表配置类CustomTablePreciseShardingAlgorithm
public class CustomTablePreciseShardingAlgorithm implements PreciseShardingAlgorithm {
/**
* @param collection 数据源集合
* 在分库时值为所有分片库的集合 databaseNames
* 分表时为对应分片库中所有分片表的集合 tablesNames
* @param preciseShardingValue 分片属性,包括
* logicTableName 为逻辑表,
* columnName 分片健(字段),
* value 为从 SQL 中解析出的分片健的值
* @return
*/
@Override
public String doSharding(Collection collection, PreciseShardingValue preciseShardingValue) {
//循环遍历 数据源,根据算法
for (String databaseName : collection) {
String value = preciseShardingValue.getValue() % collection.size() + "";
//value是0,则进入0库表,1则进入1库表
if (databaseName.endsWith(value)) {
return databaseName;
}
}
throw new IllegalArgumentException();
}
}
- 添加分库配置类CustomDBPreciseShardingAlgorithm
/**
* @param collection 数据源集合
* 在分库时值为所有分片库的集合 databaseNames
* 分表时为对应分片库中所有分片表的集合 tablesNames
* @param preciseShardingValue 分片属性,包括
* logicTableName 为逻辑表,
* columnName 分片健(字段),
* value 为从 SQL 中解析出的分片健的值
* @return
*/
@Override
public String doSharding(Collection collection, PreciseShardingValue preciseShardingValue) {
for (String databaseName : collection) {
String value = preciseShardingValue.getValue() % collection.size() + "";
//value是0,则进入0库表,1则进入1库表
if (databaseName.endsWith(value)) {
return databaseName;
}
}
throw new IllegalArgumentException();
}
- 添加分表范围配置类CustomRangeShardingAlgorithm
public class CustomRangeShardingAlgorithm implements RangeShardingAlgorithm {
/**
* @param collection 数据源集合
* 在分库时值为所有分片库的集合 databaseNames
* 分表时为对应分片库中所有分片表的集合 tablesNames
* @param rangeShardingValue 分片属性,包括
* logicTableName 为逻辑表,
* columnName 分片健(字段),
* value 为从 SQL 中解析出的分片健的值
* @return
*/
@Override
public Collection doSharding(Collection collection, RangeShardingValue rangeShardingValue) {
Set result = new LinkedHashSet<>();
// between 起始值
Long lower = rangeShardingValue.getValueRange().lowerEndpoint();
// between 结束值
Long upper = rangeShardingValue.getValueRange().upperEndpoint();
// 循环范围计算分库逻辑
for (long i = lower; i
- 配置文件添加图下代码,
分库分片算法
spring.shardingsphere.sharding.tables.product_order.database-strategy.standard.sharding-column=user_id
spring.shardingsphere.sharding.tables.product_order.database-strategy.standard.precise-algorithm-class-name=com.ybe.algorithm.CustomDBPreciseShardingAlgorithm
#精准水平分表下,增加一个范围分片
spring.shardingsphere.sharding.tables.product_order.table-strategy.standard.range-algorithm-class-name=com.ybe.algorithm.CustomRangeShardingAlgorithm
分表分片健
spring.shardingsphere.sharding.tables.product_order.table-strategy.standard.sharding-column=id
spring.shardingsphere.sharding.tables.product_order.table-strategy.standard.precise-algorithm-class-name=com.ybe.algorithm.CustomTablePreciseShardingAlgorithm
- 添加测试方法
@Test
public void testRand(){
Random random = new Random();
for (int i = 0 ;i < 10 ; i++){
ProductOrderDO productOrderDO = new ProductOrderDO();
productOrderDO.setCreateTime(new Date());
productOrderDO.setNickname("ybe:"+i);
productOrderDO.setOutTradeNo(UUID.randomUUID().toString().substring(0,32));
productOrderDO.setPayAmount(100.00);
productOrderDO.setState("PAY");
productOrderDO.setUserId(Long.valueOf(random.nextInt(50)));
productOrderMapper.insert(productOrderDO);
}
productOrderMapper.selectList(new QueryWrapper().between("id",1L,1L));
}
- 执行结果:1.会根据配置的分库、分表规则进行插入不同的数据库和表;2.范围(between)查询的时候会根据id的范围值查询映射的物理表集合。
4.复合分片算法ComplexShardingStrategy
- 提供对SQL语句中的=, IN和BETWEEN AND的分片操作,支持【多分片键】
- 由于多分片键之间的关系复杂,Sharding-JDBC并未做过多的封装
-
而是直接将分片键值组合以及分片操作符交于算法接口,全部由应用开发者实现,提供最大的灵活度
-
添加分表配置类CustomComplexKeysShardingAlgorithm
public class CustomComplexKeysShardingAlgorithm implements ComplexKeysShardingAlgorithm {
@Override
public Collection doSharding(Collection collection, ComplexKeysShardingValue complexKeysShardingValue) {
// 得到每个分片健对应的值
Collection orderIdValues = this.getShardingValue(complexKeysShardingValue, "id");
Collection userIdValues = this.getShardingValue(complexKeysShardingValue, "user_id");
List shardingSuffix = new ArrayList<>();
// 对两个分片健取模的方式
for (Long userId : userIdValues) {
for (Long orderId : orderIdValues) {
String suffix = userId % 2 + "_" + orderId % 2;
for (String databaseName : collection) {
if (databaseName.endsWith(suffix)) {
shardingSuffix.add(databaseName);
}
}
}
}
return shardingSuffix;
}
/**
* shardingValue 分片属性,包括
* logicTableName 为逻辑表,
* columnNameAndShardingValuesMap 存储多个分片健 包括key-value
* key:分片key,id和user_id
* value:分片value,66和99
*
* @return shardingValues 集合
*/
private Collection getShardingValue(ComplexKeysShardingValue shardingValues, final String key) {
Collection valueSet = new ArrayList<>();
Map> columnNameAndShardingValuesMap = shardingValues.getColumnNameAndShardingValuesMap();
if (columnNameAndShardingValuesMap.containsKey(key)) {
valueSet.addAll(columnNameAndShardingValuesMap.get(key));
}
return valueSet;
}
- 配置文件添加如下代码,多个列的类型必须一样。
复合分片算法,order_id,user_id 同时作为分片健
spring.shardingsphere.sharding.tables.product_order.table-strategy.complex.sharding-columns=user_id,id
spring.shardingsphere.sharding.tables.product_order.table-strategy.complex.algorithm-class-name=com.ybe.algorithm.CustomComplexKeysShardingAlgorithm
- 添加测试方法
@Test
public void testComplex(){
productOrderMapper.selectList(new QueryWrapper().eq("id",66L).eq("user_id",99L));
}
- 执行结果:1.会根据配置的复合分片算法去查找相关的物理表。
5.Hint分片算法HintShardingStrategy
- 这种分片策略无需配置文件进行配置分片健,分片健值也不再从 SQL中解析,外部手动指定分片健或分片库,让 SQL在指定的分库、分表中执行
- 通过Hint代码指定的方式而非SQL解析的方式分片的策略
- Hint策略会绕过SQL解析的,对于这些比较复杂的需要分片的查询,Hint分片策略性能可能会更好
-
可以指定sql去某个库某个表进行执行
-
添加分表配置类CustomTableHintShardingAlgorithm
public class CustomTableHintShardingAlgorithm implements HintShardingAlgorithm {
@Override
public Collection doSharding(Collection collection, HintShardingValue hintShardingValue) {
Collection result = new ArrayList<>();
for (String tableName : collection) {
for (Long shardingValue : hintShardingValue.getValues()) {
if (tableName.endsWith(String.valueOf(shardingValue % collection.size()))) {
result.add(tableName);
}
}
}
return result;
}
}
- 添加分库配置类CustomDBHintShardingAlgorithm
public class CustomDBHintShardingAlgorithm implements HintShardingAlgorithm
{
@Override
public Collection doSharding(Collection collection, HintShardingValue hintShardingValue) {
Collection result = new ArrayList<>();
for (String dbName : collection) {
for (Long shardingValue : hintShardingValue.getValues()) {
if (dbName.endsWith(String.valueOf(shardingValue % collection.size()))) {
result.add(dbName);
}
}
}
return result;
}
}
- 配置文件添加如下代码
Hint分片算法
spring.shardingsphere.sharding.tables.product_order.table-strategy.hint.algorithm-class-name=com.ybe.algorithm.CustomTableHintShardingAlgorithm
spring.shardingsphere.sharding.tables.product_order.database-strategy.hint.algorithm-class-name=com.ybe.algorithm.CustomDBHintShardingAlgorithm
- 添加测试方法
@Test
public void testHint(){
// 清除掉历史的规则
HintManager.clear();
//Hint分片策略必须要使用 HintManager工具类
HintManager hintManager = HintManager.getInstance();
// 设置库的分片健,value用于库分片取模,
hintManager.addDatabaseShardingValue("product_order",4L);
// 设置表的分片健,value用于表分片取模,
hintManager.addTableShardingValue("product_order", 5L);
//对应的value只做查询,不做sql解析
productOrderMapper.selectList(new QueryWrapper().eq("id", 66L));
}
- 执行结果:1.不会解析Sql中的分片键,会把hintManager配置的值作为分片键,在CustomTableHintShardingAlgorithm分片算法的中使用。
6.绑定表介绍和配置实战
- 指分片规则一致的主表和子表
- 比如product_order表和product_order_item表,均按照order_id分片,则此两张表互为绑定表关系
-
绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升
-
添加ProductOrderItemDO实体类和添加ProductOrderDOMapper类
//数据库实体类
@Data
@TableName("product_order_item")
@EqualsAndHashCode(callSuper = false)
public class ProductOrderItemDO {
private Long id;
private Long productOrderId;
private Long productId;
private String productName;
private Integer buyNum;
private Long userId;
}
//数据库实体配置类
public interface ProductOrderItemMapper extends BaseMapper {
}
- 添加配置文件,设置product_order_item的分表逻辑,设置product_order和product_order_item为广播表,如果需要配置多个需要配置多行,binding-tables是个数组。
spring.shardingsphere.sharding.tables.product_order_item.actual-data-nodes=ds$->{0..1}.product_order_item_$->{0..1}
指定product_order表的分片策略,分片策略包括【分片键和分片算法】
spring.shardingsphere.sharding.tables.product_order_item.table-strategy.inline.sharding-column=product_order_id
spring.shardingsphere.sharding.tables.product_order_item.table-strategy.inline.algorithm-expression=product_order_item_$->{product_order_id % 2}
#配置绑定表
spring.shardingsphere.sharding.binding-tables[0]=product_order,product_order_item
- 添加测试方法
@Test
public void testBinding(){
List objects = productOrderMapper.listProductOrderDetail();
System.out.println(objects);
}
- 执行结果:

- 添加绑定表配置之后,可以看到查询的sql语句,主表和子表是一一对应的。如下图,

Original: https://www.cnblogs.com/yuanbeier/p/16584622.html
Author: bei_er
Title: ShardingSphere-JDBC实战
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/608262/
转载文章受原作者版权保护。转载请注明原作者出处!