

- Elasticsearch 是一个分布式的开源搜索和分析引擎,在 _Apache Lucene_的基础上开发而成。Lucene 是开源的搜索引擎工具包,Elasticsearch 充分利用Lucene,并对其进行了扩展,使存储、索引、搜索都变得更快、更容易, 而最重要的是, 正如名字中的” elastic “所示, 一切都是灵活、有弹性的。而且,应用代码也不是必须用Java 书写才可以和Elasticsearc兼容,完全可以通过JSON 格式的HTTP 请求来进行索引、搜索和管理Elasticsearch 集群。
-
官方文档:
-
Index(索引):
- 动词:相当于数据库中的insert
- 名词:相当于数据库中的DataBase
- Type(类型):
- 在index索引中可以定义一个或多个类型,类似于Mysql中的table,每种类型的数据放在一起。
- Document(文档):
-
保存在某个索引(index)下,某种类型(type)的一个数据(Document),文档是JSON格式的,Document就像是Mysql中某个Table里面的内容。
-
倒排索引:
- ElasticSearch为什么能快速检索出我们所搜索得到内容,主要得益于其内部维护的倒排索引表:
- 当保存第一条索引时,先对这条索引进行分词(定义见图片中,词也可以是单个字),在倒排索引表中记录每一个拆分出来的词的出现位置。保存完这五个索引就能维护出这样的一张倒排索引表。
-
当我们想要检索红海特工行动时,一样先对检索的数据进行分词,在倒排索引表中发现红海出现在已保存的索引中的1,2,3,4,5.特工出现在5,行动出现在1,2,3.由于红海出现在了保存的所有的记录中,所以ElasticSearch会将保存的所有的数据都检索出来。红海和行动以及特工都分别出现了两次,谁排在前面涉及到 相关性得分的高低。红海、行动在保存的记录中的命中率为2/2、2/3。红海和特工的命中率为2/4. 。自然红海和行动的相关性得分高,所以包含红海和行动的索引会排在包含红海和特工的索引的前面。
-
先将虚拟机内存增大至1G;
-
启动vagrant,运行命令:
-
运行命令:
-
sudo docker images查看上面两个是否安装成功。
- 创建配置文件夹及数据文件夹:
- sudo mkdir -p /mydata/elasticsearch/config
- sudo mkdir -p /mydata/elasticsearch/data
- 如果已经是管理员就不用sudo了
- 进入到mydata文件夹下并展示文件夹内容,查看elasticsearch文件夹是否创建成功
- cd /mydata/
- [vagrant@localhost mydata]$ ls 只用输入ls
- 成功则进入到elasticsearch文件夹中并展示文件夹内容
- [vagrant@localhost mydata]$ cd elasticsearch
- [vagrant@localhost elasticsearch]$ ls 效果-》config data
- 进入config文件夹中
- [vagrant@localhost elasticsearch]$ cd config/
- 切换root管理员模式
- [vagrant@localhost config]$ su root 输入密码 默认是vagrant
- 开始配置elasticsearch
–
[root
- 启动elasticsearch
–
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \-e "discovery.type=single-node" \-e ES_JAVA_OPTS="-Xms64m -Xmx512m" \-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml\ -v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \-d elasticsearch:7.4.2
- docker ps 检测elasticsearch有没有启动,没有启动的话修改elasticsearch文件夹的权限,见下
- cd ../返回上一层目录(elasticsearch),ll查看文件夹信息(效果及代码见下)
–
[root
- 关于drwxr-xr-x的一点儿拓展
- 所以对于elasticsearch这个文件夹,文件所有者具有全部权限,文件所属组具有执行和读权限,其他用户具有读权限。
- 修改elasticsearch文件夹权限:
–
[root
- docker ps -a 查看elasticsearch的CONTAINER ID,记录这个ID
- 重启elasticsearch
- [root@localhost elasticsearch]# docker start +你的ID的前几位(能与其他的服务ID区别开就行)
-
docker ps检测elasticsearch是否启动成功,docker logs +你的ID的前几位查看elasticsearch的日志有没有报错,没有报错就继续访问192.168.56.10:9200。能访问成功则表示elasticsearch配置成功!
-
运行命令:
–
docker run --name kibana -e ELASTICSEARCH_HOSTS=http:
- docker ps检查kibana有没有成功启动
-
访问http://192.168.56.10:5601检测kibana有没有成功启动,没有启动成功的话就看看日志。
-
运行命令:
–
sudo docker update cdae --restart=alwayssudo docker update 1754 --restart=always其中cdae和1754是你安装的kibana和ElasticSearch所对应的能够区分其他软件的ID。
- GET/ _cat/nodes:查看所有节点_
- GET/ _cat/health: 查看es 健康状况_
- GET/ _cat/master: 查看主节点_
- GET/ _cat/indices: 查看所有索引 相当于sql里的 show databases;
-
postman 发送get请求访问 http://192.168.56.10:9200/_cat/nodes
-
put请求:
- 请求路径: 主机号+端口号+索引+类型+唯一标识。例:http://192.168.56.10:9200/customer/external/1,带上JSON数据。其中customer是索引,external是类型,1是保存的这条数据的唯一标识。
- 注意:put请求必须带唯一标识。两次请求同一URL(唯一标识也相同),第一次为新增数据,第二次为修改数据。
- post请求:
- 请求路径:主机号+端口号+索引+类型。带上JSON数据
- 注意:唯一标识可带可不带,不带唯一标识发送请求后elasticsearch会自动为你创建一个唯一标识,第二次发送同一请求一样为新增操作,再一次为第二次请求创建唯一标识。带唯一标识就和put类似。
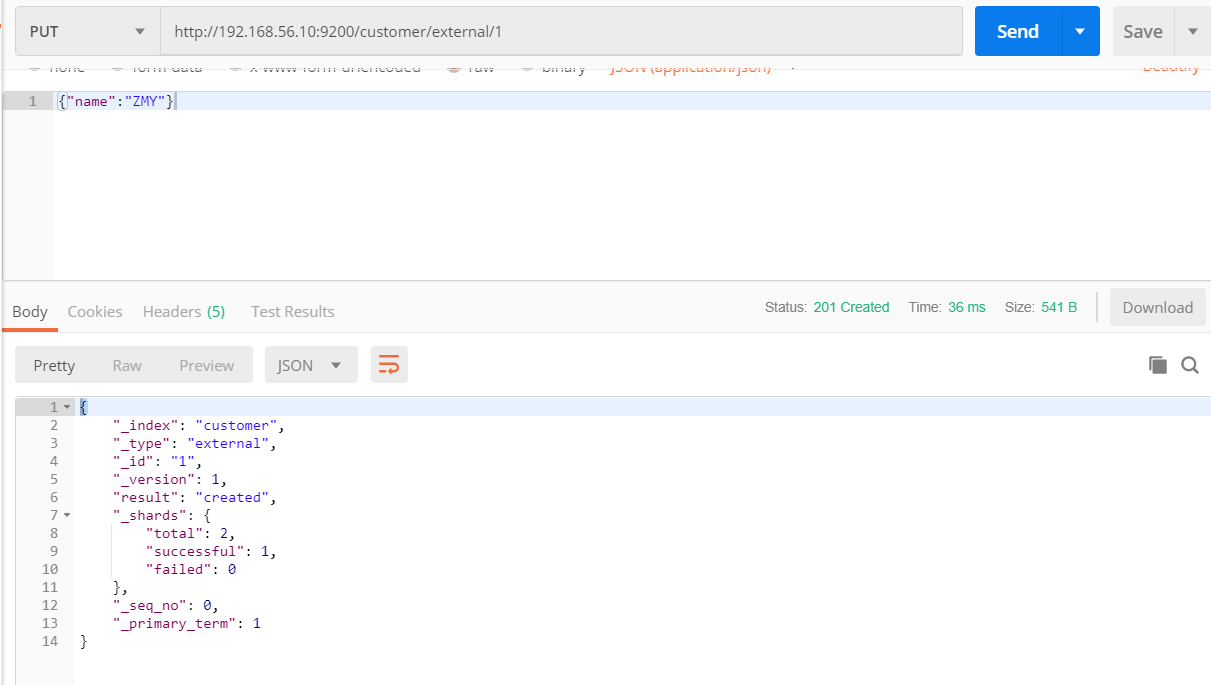

- “_index”:索引
- “_type”:类型
- “_id”:唯一标识
- “_verson”:版本,随着这条记录的更新版本不断递加
- “_shards”:集群知识,目前不懂
- “_seq_no”:并发控制字段,每次更新就会加1,用来做乐观锁
-
“_primary_term”:同上,主分配重新分配,如重启,就会变化。
-
post请求更新:
- 请求路径:主机号+端口号+索引+类型+唯一标识/_update
- 当两次发送同一个post请求更新时,Elasticsearch会与原数据进行对比,没有变化则返回noop(NoOperation的缩写),同时版本号以及序列号(_seq_no)不会改变。
- 注意:请求路径后带update,所带的JSON数据格式必须带doc。即:
+
{ "doc":{ "name":"TX",
+ 请求路径后面不带update,多次重复发送同一请求Elasticsearch不会与原数据进行对比,版本号和序列号会递增。
- put请求更新:
- 请求路径:主机号+端口号+索引+类型+唯一标识
-
put更新操作不能带_update
-
删除数据:
- 语法格式:DELETE customer/external/1 删除一条数据 or DELETE customer 删除整个索引
- 没有对类型的删除
-
请求方式为delete
-
使用REST request URL:查询条件写在url上
–
GET bank/_search?q=*&sort=account_number:asc
- REST request body结构化查询:
–
GET bank/_search{ "query": { "match_all": {} }, "sort": [ { "account_number": "asc" }, { "balance": "desc" } ]}
*
标准语法(按提示)GET bank/_search{ "query": { "match_all": {} }, "sort": [ { "balance": { "order": "desc" } } ], "from": 0, "size": 20, "_source": ["balance","firstname"]}
-
“_source”:用来指定查询到的索引中返回的源数据的返回值,[“balance”,”firstname”]表示在源数据中只显示balance和firstname这两个字段,只想返回一个字段也可以用{“字段名”}。
-
全文检索会对检索条件进行分词匹配,按照评分进行排序。
- match可以做精确检索也可以做模糊检索,字段名对应的检索条件是精确的,这次查询就为精确查询,反之为模糊查询。
–
GET bank/_search{ "query": { "match": { "address": "Mill" } }}
- match是将需要检索的词进行分词(拆词)匹配,而match_phrase则是将需要检索的词当作一个整体来匹配。
- 语法:
–
GET bank/_search{ "query": { "match_phrase": { "需要进行模糊匹配的字段名": "匹配值" } }}
- 类似于sql里面的username like··· or nickname like···
- 语法:
–
用在上面就相当于 GET bank/_search{ "query": { "multi_match": { "query": "省略号里面的东西", "fields": ["username","nickname"] } }}
-
multi_match 多字段匹配是分词匹配的,假设 省略号里面的东西 为A B,那么elasticsearch会将在username和nickname中包含A或B的索引全部都查出来,而同时包括A和B的相关性得分可能会更高。
-
用bool可以在一次查询中关联多个条件:
- eg:
–
GET bank/_search{ "query": { "bool": { "must": [ {"match": { "FIELD": "TEXT" }} ], "must_not": [ {"match": { "FIELD": "TEXT" }} ], "should": [ {"match": { "FIELD": "TEXT" }} ] } }}
-
其中must条件为某个字段必须是查询的值,must_not条件为某个字段必须不是查询的值,不影响相关性得分。should条件为某个字段可以是查询的值,也可以不是,是查询的值相关性得分更高。
-
filter过滤器可以替代查询,但是filter不会计算相关性得分。
- 语法:
–
GET bank/_search{ "query": { "bool": { "must": [ {"match": { "FIELD": "TEXT" }} ], "filter": { "range": { "FIELD": { "gte": 10, "lte": 20 } } } } }}
- 和match一样。匹配某个属性的值。 全文检索字段用match,其他非text字段匹配用term。
*
GET bank/_search{ "query": { "match": { "address.keyword": "TEXT" } }}GET bank/_search{ "query": { "match_phrase": { "address": "TEXT" } }}
- 这两种写法的不同之处:
- 第一种写法是将address.keyword是将后面的TEXT值完全当作源数据中对应字段的值进行匹配。是一种精确匹配。
-
第二种写法可以进行分词匹配,即源数据字段值中只需要含有这个值就行。
-
聚合的基本使用:
–
GET bank/_search{ "query": { "match": { "address": "mill" } }, "aggs": { "AgeAggs": { "terms": { "field": "age", "size": 10 } } }}
- 聚合结果:
–
"aggregations" : { "AgeAggs" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ { "key" : 38, "doc_count" : 2 }, { "key" : 28, "doc_count" : 1 }, { "key" : 32, "doc_count" : 1 } ] }}
- 类似于sql中的聚合函数。
- 先查询再聚合,上面的聚合的意思是按照年龄的值进行聚合。
- 复杂聚合的使用:
–
GET bank/_search{ "query": { "match_all": {} }, "aggs": { "AgeAggs": { "terms": { "field": "age", "size": 100 }, "aggs": { "genderAgg": { "terms": { "field": "gender.keyword", "size": 10 }, "aggs": { "balanceAvg": { "avg": { "field": "balance" } } } } } } }}
-
聚合中嵌套聚合(子聚合):先查询出所有的索引。先按照年龄聚合-》再在年龄聚合里按照性别聚合-》最后计算完成聚合后的分组的平均薪资。
-
聚合的类型等等参考官网文档:
-
类似于sql里面的数据类型,不过在es里,新建某一条记录后es会为我们自动猜测并存储这条记录的类型
- 使用 ” GET /bank/_mapping “可以查看bank下的属性所对应的类型
- 自定义映射类型(创建映射):
–
PUT /my_index{ "mappings": { "properties": { "name": { "type": "text" }, "age": { "type": "integer" }, "email": { "type": "keyword" } } }}
- text类型在检索时会进行全文检索,并且进行分词匹配。
- keyword类型为精确检索。不进行分词匹配。
- 为映射添加新的字段:
–
PUT /my_index/_mapping{ "properties": { "employee_id": { "type": "keyword", "index": false } }}
- 其中index默认值为true,决定这条记录能不能作为索引被检索。
- 更新映射:
- es里面不支持直接更新某个索引的映射,原因很简单。更新某个属性对应的类型后,之前所保存的属性的记录在检索时都会失效。对于已经存在的字段,我们不能更新。更新必须创建新的索引进行数据迁移。
- 数据迁移:
- es6.0之前:
+
PUT /newbank{ "mappings": { "properties": { "account_number": { "type": "long" }, "address": { "type": "text" }, "age": { "type": "integer" }, "balance": { "type": "long" }, "city": { "type": "text" }, "email": { "type": "text" }, "employer": { "type": "text" }, "firstname": { "type": "text" }, "gender": { "type": "text" }, "lastname": { "type": "text" }, "state": { "type": "text" } } }}
- es6.0之后:
- 不需要指定数据类型
+
- 不需要指定数据类型
POST _reindex{ "source": { "index": "bank" }, "dest": { "index": "newbank " }}
- 一个tokenizer(分词器)接收一个字符流,将之分割为独立的tokens(词元,通常是独立的单词),然后输出tokens流。 例如:whitespace tokenizer遇到空白字符时分割文本。它会将文本”Quick brown fox!”分割为[Quick,brown,fox!]。 该tokenizer(分词器)还负责记录各个terms(词条)的顺序或position位置(用于phrase短语和word proximity词近邻查询),以及term(词条)所代表的原始word(单词)的start(起始)和end(结束)的character offsets(字符串偏移量)(用于高亮显示搜索的内容)。 elasticsearch提供了很多内置的分词器,可以用来构建custom analyzers(自定义分词器)。 关于分词器: https://www.elastic.co/guide/en/elasticsearch/reference/7.6/analysis.html
- 安装ik分词器:
- 如果你的虚拟机能够连接外网,那就直接使用wget安装:
- 没有安装wget先安装wget,顺便安装unzip 使用命令 :
+
yum -y install wgetyum -y install unzip
- 安装ik分词器方法一:(推荐)
- 先进入 cd /mydata/elasticsearch/plugins/ik/
- 使用命令:wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip下载ik分词器7.4.2版本 ( 注意:这里的版本要和你所使用的elasticsearch的版本一致)
- 使用命令:unzip elasticsearch-analysis-ik-7.4.2.zip -d ik 解压下载的自拍文件。
- 使用命令:rm -rf elasticsearch-analysis-ik-7.4.2.zip 删除压缩包文件。
- 重启elastic search,去kimaba上测试ik分词器是否生效。
- 安装ik分词器方法二:
- 在github上找自己使用的elasticsearch对应的ik分词器的版本,下载并解压。
- 使用虚拟机可视化操作软件比如MobaXterm在mydata/elasticsearch/plugins 下创建文件夹,取名ik,并利用MobaXterm在ik文件夹下上传你上一步解压的所有文件。
- 测试。。。。。。
- 配置nginx:
- 随便启动一个nginx实例,只是为了复制出配置
docker run -p 8081:80 --name nginx -d nginx:1.10
- 将容器内的配置文件拷贝到/mydata/nginx/conf/ 下
mkdir -p /mydata/nginx/htmlmkdir -p /mydata/nginx/logsmkdir -p /mydata/nginx/confdocker container cp nginx:/etc/nginx .
- 终止原容器:
docker stop nginx
- 执行命令删除原容器:
docker rm nginx
- 创建新的Nginx,执行以下命令
docker run -p 80:80 --name nginx \ -v /mydata/nginx/html:/usr/share/nginx/html \ -v /mydata/nginx/logs:/var/log/nginx \ -v /mydata/nginx/conf/:/etc/nginx \ -d nginx:1.10
- 设置开机启动nginx
docker update nginx --restart=always
- 创建”/mydata/nginx/html/index.html”文件,测试是否能够正常访问
echo 'hello nginx!' >/mydata/nginx/html/index.html
访问:http://ngix所在主机的IP:80/index.html
* 自定义词库:
– 方法一:通过nginx 间接自定义词库:
+ 在 /mydata/nginx/html/es/ 定义一个txt文件作为词库文件
+ 修改 /mydata/elasticsearch/plugins/ik/config/ IKAnalyzer.cfg/xml ,设置远程词库为
+ 重启elastic search,测试效果。
– 方法二:通过ik分词器中的config配置文件定义词库:
+ 在/mydata/elasticsearch/plugins/ik/config/ 目录下新建一个fenci.dic文件。
+ 修改 /mydata/elasticsearch/plugins/ik/config/ IKAnalyzer.cfg.xml ,设置扩展字典为fenci.dic。也就是你刚刚创建词库文件。
+ 重启elastic search,测试效果。
– 这两种方法根本原理都相同,都是在某个文件中添加你想保留的字段,让分词器在分词时根据你的设置来进行分词。
– IKAnalyzer.cfg.xml
+
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置comment>
<entry key="ext_dict">fenci.dicentry>
<entry key="ext_stopwords">entry>
<entry key="remote_ext_dict">http:
- spring-data-elasticsearch:transport-api.jar;
- springboot版本不同,ransport-api.jar不同,不能适配es版本
-
7.x已经不建议使用,8以后就要废弃
-
新建module、开启服务注册发现什么的自己来。
- 依赖版本要和自己的elasticsearch的版本一致。
* - 父依赖中的elasticsearch版本要修改为对应的版本。(不该后面会报错)
-
<elasticsearch.version>7.4.2elasticsearch.version>
@Test public void searchData() throws IOException { GetRequest getRequest = new GetRequest( "users", "_-2vAHIB0nzmLJLkxKWk"); GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT); System.out.println(getResponse); String index = getResponse.getIndex(); System.out.println(index); String id = getResponse.getId(); System.out.println(id); if (getResponse.isExists()) { long version = getResponse.getVersion(); System.out.println(version); String sourceAsString = getResponse.getSourceAsString(); System.out.println(sourceAsString); Map sourceAsMap = getResponse.getSourceAsMap(); System.out.println(sourceAsMap); byte[] sourceAsBytes = getResponse.getSourceAsBytes(); } else { } }
查询state=”AK”的文档:
{ "took": 1, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 22,
搜索address中包含mill的所有人的年龄分布以及平均年龄,平均薪资
GET bank/_search{ "query": { "match": { "address": "Mill" } }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 10 } }, "ageAvg": { "avg": { "field": "age" } }, "balanceAvg": { "avg": { "field": "balance" } } }}
java实现
可以尝试对比打印的条件和执行结果,和前面的ElasticSearch的检索语句和检索结果进行比较;
ctrl+home:回到文档首部;
ctril+end:回到文档尾部。
Original: https://www.cnblogs.com/txzmy/p/16652709.html
Author: 张满月。
Title: ElasticSearch-全文检索
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/607760/
转载文章受原作者版权保护。转载请注明原作者出处!