

机器学习实用代码汇总(你想要的这里都有)
文章目录
- 机器学习实用代码汇总(你想要的这里都有)
- 前言
- 一、数据导入
* - 1.数据文件读取
- 2.提取特征和标签
- 3.数据分布及关系图(ProfileReport)
- 二、数据预处理
* - 1.数据的查看、去重、异常值删除
- 2.数据的无量纲化
- 3.缺失值处理
- 4.处理分类型特征:编码与哑变量
- 5.处理连续型特征:二值化与分段
- 6.数据集制造
- 7.样本不均衡处理
- 8.训练集、测试集划分
- 三、特征选择
* - 1.Filter过滤法
- 2.Embedded嵌入法
- 3. Wrapper包装法
- 4.PCA与LDA降维
- 5.特征选择经验技巧
- 四、模型搭建及优化
* - 1.模型评估
– - 2.机器学习常用回归模型
– - 3.机器学习常用分类模型
– - 4.机器学习常用聚类模型
– - 四、参数调整
* - 1.通用学习曲线
- 2.网格调参
- 3.随机搜索
- 4.贝叶斯搜索
- 五、常用绘图
- 六、参考文章
前言
这里记录了自己在学习和实践中, 记录下来的常用代码块。非常适合小白来学习和实践,在实践过程中找到你想要的某些功能,不断的复制粘贴就可以,有助于你早日成为CV工程师。
(后面会慢慢完善BP、CNN、RNN、LSTM、GRU、Transorformer、BERT、GAN、YOLOV、Q-learning、QMIX、MAPPO等网络结构结合任务场景的快速使用)
一、数据导入
1.数据文件读取
代码如下(示例):
#读取CSV文件
import pandas as pd
str="文件路径"#您可以右键您的文件来复制路径
data = pd.read_csv(str,header=None)#str:要打开的文件路径,header=:布尔类型,等于None时,可以自己给特征和标签取名字。names=:列表类型,传入你想给特征和标签取的名字。
#读取TXT文件
#按行读取,放入列表即可
data = []
for line in open("文件路径","r"): #设置文件对象并读取每一行文件
data.append(line) #将每一行文件加入到list中
2.提取特征和标签
代码如下(示例):
#X为你要取的特征,y为你要取的标签
X=data.iloc[a:b,m:n]#a,b为你要取a-1行到b-1行的数据。m,n为你要取第m-1列到n-1列的数据。
y=data.iloc[:,-1]#一般标签在最后一列
3.数据分布及关系图(ProfileReport)
用于数据分析报告,可以查看相关性,样本分布关系等
代码如下(示例):
import seaborn as sns
import pandas as pd
import pandas_profiling as pp
import matplotlib.pyplot as plt
data=pd.read_csv("data.csv")
report = pp.ProfileReport(data)
report
二、数据预处理
1.数据的查看、去重、异常值删除
代码如下(示例):
#查看部分数据
print(data.head(m))#m为多少条数据
#描述性统计
print(data.describe([0.01,0.1,0.25,.5,.75,.9,.99]).T)#查看数据大致分布
#查看数据基本信息
print(data.info())
#查看数据数量统计信息
for cate in sample.columns:#sample为你导入的数据样本
print(sample[cate].value_counts())
#查看每个特征与标签的分布关系
m,n=sample.shape()#这里查看所有样本和每一个特征,如果想查看个别特征修改循环值就行,想查看部分样本,直接修改m。
for i in range(0,n-1):
X_=np.arange(m)
y_=pd.DataFrame(sample.iloc[0:m,i])
z_=sample.iloc[0:m,0]
plt.scatter(X_,y_,c=z_)
plt.xlabel("sample")
plt.ylabel("feature")
plt.show()
数据去重
#按某些列去重、raw_data为你的数据集
reviews=raw_data.copy()
reviews=reviews[['content', 'content_type']]#选取你要去重的列
reviews=reviews.drop_duplicates()
#数据整体去除重复值
data.drop_duplicates(inplace=True)#inplace=True表示替换原数据
#删除之后千万不要忘记,恢复索引
data.index = range(data.shape[0])
#按照索引为subset列去重
data=data.drop_duplicates(subset=1, ignore_index=True, inplace=True)
箱线图公式处理异常值:删除需谨慎,除非是根据先验知道数据确实异常,否则随意删除很容易改变数据分布。并且只能对训练集删除,测试集不能删。
def outliers_proc(data, col_name, scale=1.5):
"""
用于清洗异常值,默认用 box_plot(scale=1.5)进行清洗(scale=1.5表示异常值,scale=3表示极端值)
:param scale: 尺度
"""
def box_plot_outliers(data_ser, box_scale):
"""
利用箱线图去除异常值
:param data_ser: 接收 pandas.Series 数据格式
:param box_scale: 箱线图尺度,
:return:
"""
iqr = box_scale * (data_ser.quantile(0.75) - data_ser.quantile(0.25))
val_low = data_ser.quantile(0.25) - iqr
print('val_low:',val_low)
val_up = data_ser.quantile(0.75) + iqr
print('val_up:',val_up)
rule_low = (data_ser < val_low) # 下离群点
rule_up = (data_ser > val_up) # 上离群点
return (rule_low, rule_up), (val_low, val_up)
data_n = data.copy()
data_series = data_n[col_name]
rule, value = box_plot_outliers(data_series, box_scale=scale)
index = np.arange(data_series.shape[0])[rule[0] | rule[1]]
print("Delete number is: {}".format(len(index)))
data_n = data_n.drop(index)
data_n.reset_index(drop=True, inplace=True)
print("Now row number is: {}".format(data_n.shape[0]))
index_low = np.arange(data_series.shape[0])[rule[0]]
outliers = data_series.iloc[index_low]
print('\n',"Description of data less than the lower bound is:")
print(pd.Series(outliers).describe())
index_up = np.arange(data_series.shape[0])[rule[1]]
outliers = data_series.iloc[index_up]
print('\n',"Description of data larger than the upper bound is:")
print(pd.Series(outliers).describe())
fig, ax = plt.subplots(1, 2, figsize=(10, 7))
sns.boxplot(y=data[col_name], data=data, palette="Set3", ax=ax[0])
sns.boxplot(y=data_n[col_name], data=data_n, palette="Set3", ax=ax[1])
return data_n
2.数据的无量纲化
无量纲化可以帮我们提升模型精度,避免某一个取值范围特别大的特征对距离计算造成影响。(一个特例是决策树和树的集成算法们,对决策树我们不需要无量纲化,决策树可以把任意数据都处理得很好。)
常用的数据无量纲化代码有 数据归一化和 数据标准化。大多数机器学习算法中,会选择数据标准化来进行特征缩放,因为数据标准化对异常值非常敏感。 在PCA,聚类,逻辑回归,支持向量机,神经网络这些算法中,数据标准化往往是最好的选择。 数据归一化在不涉及距离度量、梯度、协方差计算以及数据需要被压缩到特定区间时使用广泛,比如数字图像处理中量化像素强度时,都会使用数据归一化将数据压缩于[0,1]区间之中。
代码如下(示例):
数据归一化
#数据归一化
from sklearn.preprocessing import MinMaxScaler
#实现归一化
scaler = MinMaxScaler() #实例化
result = scaler.fit_transform(data) #训练和导出结果一步达成
data=scaler.inverse_transform(result) #将归一化后的结果逆转
数据标准化
#数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler() #实例化
x_std =scaler.fit_transform(data) #训练和导出结果一步达成
data=scaler.inverse_transform(x_std) #使用标准化后的结果逆转
数据归一化和标准化接口汇总


3.缺失值处理
代码如下(示例):
用均值、中位数、特定值来填补缺失值
#常用的sklearn内置填补缺失值方法
from sklearn.impute import SimpleImputer
#以特征age为例子
Age=X["age"]#取出你要填补的特征
imp_mean = SimpleImputer() #实例化,默认均值填补
imp_mean = imp_mean.fit_transform(Age) #将缺失值用均值填补
imp_median = SimpleImputer(strategy="median") #用中位数填补
imp_median = imp_median.fit_transform(Age)
imp_0 = SimpleImputer(strategy="constant",fill_value=0) #用0填补
imp_0 = imp_0.fit_transform(Age)
X["age"]=imp_0#别忘记填补完进行特征更新
用随机森林算法来填补缺失值
#用随机森林算法来填补缺失值,仅供参考
from sklearn.ensemble import RandomForestRegressor
def RandomForestImputer(X_missing):#传入你要填补的特征,返回已经填补好的
X_missing_reg = X_missing.copy()
#找出数据集中,缺失值从小到大排列的特征们的顺序,并且有了这些的索引
sortindex = np.argsort(X_missing_reg.isnull().sum(axis=0)).values#np.argsort()返回的是从小到大排序的顺序所对应的索引
for i in sortindex:
#构建我们的新特征矩阵(没有被选中去填充的特征 + 原始的标签)和新标签(被选中去填充的特征)
df = X_missing_reg
fillc = df.iloc[:,i]#新标签
df = pd.concat([df.iloc[:,df.columns != i],pd.DataFrame(y_full)],axis=1)#新特征矩阵
#在新特征矩阵中,对含有缺失值的列,进行0的填补
df_0 =SimpleImputer(missing_values=np.nan,strategy='constant',fill_value=0).fit_transform(df)
#找出我们的训练集和测试集
Ytrain = fillc[fillc.notnull()]# Ytrain是被选中要填充的特征中(现在是我们的标签),存在的那些值:非空值
Ytest = fillc[fillc.isnull()]#Ytest 是被选中要填充的特征中(现在是我们的标签),不存在的那些值:空值。注意我们需要的不是Ytest的值,需要的是Ytest所带的索引
Xtrain = df_0[Ytrain.index,:]#在新特征矩阵上,被选出来的要填充的特征的非空值所对应的记录
Xtest = df_0[Ytest.index,:]#在新特征矩阵上,被选出来的要填充的特征的空值所对应的记录
#用随机森林回归来填补缺失值
rfc = RandomForestRegressor(n_estimators=100)#实例化
rfc = rfc.fit(Xtrain, Ytrain)#导入训练集进行训练
Ypredict = rfc.predict(Xtest)#用predict接口将Xtest导入,得到我们的预测结果(回归结果),就是我们要用来填补空值的这些值
#将填补好的特征返回到我们的原始的特征矩阵中
X_missing_reg.loc[X_missing_reg.iloc[:,i].isnull(),i] = Ypredict
return X_missing_reg
4.处理分类型特征:编码与哑变量
在现实中,许多标签和特征在数据收集完毕的时候,都不是以数字来表现的。比如说,学历的取值可以是[“小 学”,”初中”,”高中”,”大学”],付费方式可能包含[“支付宝”,”现金”,”微信”]等等。在这种情况下,为了让数据适应算法和库,我们必须将数据进行编码,即是说, 将文字型数据转换为数值型。
代码如下(示例):
对标签进行编码
#对标签进行编码
from sklearn.preprocessing import LabelEncoder
y = data.iloc[:,-1] #要输入的是标签,不是特征矩阵,所以允许一维
le = LabelEncoder() #实例化
lable=le.fit_transform(y) #也可以直接fit_transform一步到位
data.iloc[:,-1]=lable
le.inverse_transform(label) #使用inverse_transform可以逆转
#如果不需要教学展示的话我会这么写:
from sklearn.preprocessing import LabelEncoder
data.iloc[:,-1] = LabelEncoder().fit_transform(data.iloc[:,-1])
对特征进行编码
#对特征进行编码
from sklearn.preprocessing import OrdinalEncoder
#这个接口可以一次性对多个特征进行编码,如下是对第一行到倒数第二行的所有特征进行编码
data_ = data.copy()#复制一份数据
data_.iloc[:,1:-1] = OrdinalEncoder().fit_transform(data_.iloc[:,1:-1])#进行编码
独热编码(哑变量)
1、能够处理非连续型数值特征。
2、在一定程度上也扩充了特征。
#对特征进行哑变量
from sklearn.preprocessing import OneHotEncoder
X = data.iloc[:,1:-1]#这里取出你想进行哑变量的特征
enc = OneHotEncoder(categories='auto').fit(X)
result = enc.transform(X).toarray()
#依然可以直接一步到位,但为了给大家展示模型属性,所以还是写成了三步
result=OneHotEncoder(categories='auto').fit_transform(X).toarray()
5.处理连续型特征:二值化与分段
代码如下(示例):
二值化
#二值化、根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量
from sklearn.preprocessing import Binarizer
X = data_2.iloc[:,0].values.reshape(-1,1) #选出你想二值化的特征,类为特征专用,所以不能使用一维数组
transformer = Binarizer(threshold=30).fit_transform(X)#进行二值化转化
多值化
#分段、将连续型变量划分为分类变量的类,能够将连续型变量排序后按顺序分箱后编码。
from sklearn.preprocessing import KBinsDiscretizer
X = data.iloc[:,0].values.reshape(-1,1)
est = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='uniform')#分成三段,进行等宽分箱,具体可以看下面参数。
est.fit_transform(X)

6.数据集制造
代码如下(示例):
#用于制造学习来用的分类数据集
def tensorGenCla(num_examples=500, num_inputs=2, num_class=3, deg_dispersion=[4, 2], bias=False):
"""分类数据集创建函数。
:param num_examples: 每个类别的数据数量
:param num_inputs: 数据集特征数量
:param num_class:数据集标签类别总数
:param deg_dispersion:数据分布离散程度参数,需要输入一个列表,其中第一个参数表示每个类别数组均值的参考、第二个参数表示随机数组标准差。
:param bias:建立模型逻辑回归模型时是否带入截距
:return: 生成的特征张量和标签张量,其中特征张量是浮点型二维数组,标签张量是长正型二维数组。
"""
cluster_l = torch.empty(num_examples, 1) # 每一类标签张量的形状
mean_ = deg_dispersion[0] # 每一类特征张量的均值的参考值
std_ = deg_dispersion[1] # 每一类特征张量的方差
lf = [] # 用于存储每一类特征张量的列表容器
ll = [] # 用于存储每一类标签张量的列表容器
k = mean_ * (num_class - 1) / 2 # 每一类特征张量均值的惩罚因子(视频中部分是+1,实际应该是-1)
for i in range(num_class):
data_temp = torch.normal(i * mean_ - k, std_, size=(num_examples, num_inputs)) # 生成每一类张量
lf.append(data_temp) # 将每一类张量添加到lf中
labels_temp = torch.full_like(cluster_l, i) # 生成类一类的标签
ll.append(labels_temp) # 将每一类标签添加到ll中
features = torch.cat(lf).float()
labels = torch.cat(ll).long()
if bias == True:
features = torch.cat((features, torch.ones(len(features), 1)), 1) # 在特征张量中添加一列全是1的列
return features, labels
x,y=tensorGenCla(num_examples=100,num_inputs=19,num_class=3)#制造100个特征为19,有3分类的数据集
7.样本不均衡处理
过采样(over-sampling):通过增加分类中少数类样本的数量来实现样本均衡,比较好的方法有SMOTE算法。
import pandas as pd
from imblearn.over_sampling import SMOTE #过度抽样处理库SMOTE
df=pd.read_table('data.txt')
x=df.iloc[:,:-1]#取出特征
y=df.iloc[:,-1]#取出标签
groupby_data_orginal=df.groupby('label').count() #根据标签label分类汇总
model_smote=SMOTE() #建立smote模型对象
x_smote_resampled,y_smote_resampled=model_smote.fit_resample(x,y)#进行过采样
smote_resampled=pd.concat([pd.DataFrame(x_smote_resampled),pd.DataFrame(y_smote_resampled)],axis=1)#合并,得到过采样的数据集
groupby_data_smote=smote_resampled.groupby('label').count()#再次统计分类汇总
欠采样(under-sampling):通过减少分类中多数类样本的数量来实现样本均衡
import pandas as pd
from imblearn.under_sampling import RandomUnderSampler
model_RandomUnderSampler=RandomUnderSampler() #建立RandomUnderSample模型对象
x_RandomUnderSample_resampled,y_RandomUnderSample_resampled=model_RandomUnderSampler.fit_resample(x,y) #进行欠采样
RandomUnderSampler_resampled=pd.concat([pd.DataFrame(x_RandomUnderSample_resampled),pd.DataFrame(y_RandomUnderSample_resampled)],axis=1)#合并,得到欠采样的数据集
8.训练集、测试集划分
from sklearn.model_selection import train_test_split
#导入你要分的数据特征X,标签Y
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,Y,test_size=0.3,random_state=420)
三、特征选择
特征工程主要包括 特征提取、特征创造和特征选择。 特征提取针对不同的数据有不同的方法,例如,从文字,图像,声音等其他非结构化数据中提取新信息作为特征。比如说,从淘宝宝贝的名称中提取出产品类别、产品颜色,是否是网红产品等等。往往特征提取是科研中的重要一环节,这个后面单独写文章来总结。 特征创造是把现有特征进行组合,或互相计算,得到新的特征。比如说,我们有一列特征是速度,一列特征是距离,我们就可以通过让两列相处,创造新的特征:通过距离所花的时间。特征创造 在机器学习竞赛中用的较多,后面单独写文章来讲解。 特征选择是从所有的特征中,选择出有意义,对模型有帮助的特征,以避免必须将所有特征都导入模型去训练的情况
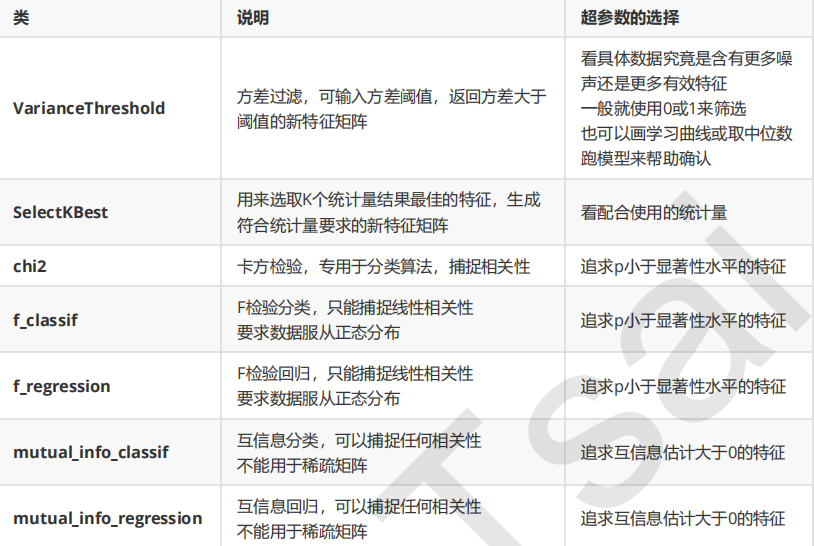
1.Filter过滤法
通常来说,我会建议,先使用方差过滤,然后使用互信息法来捕捉相关性,不过了解各种各样的过滤方式也是必要的。
代码如下(示例):
方差过滤:根据特征的方差大小,设置阈值来过滤
#方差过滤、根据特征的方差大小,设置阈值来过滤
from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold() #实例化,不填参数默认方差为0
X_var0 = selector.fit_transform(X) #获取删除不合格特征之后的新特征矩阵
X = VairanceThreshold().fit_transform(X)#也可以直接写成这样,一步到位
X_fsvar = VarianceThreshold(np.median(X.var().values)).fit_transform(X)#用特征方中位数为阈值过滤
卡方过滤:卡方检验类feature_selection.chi2计算每个非负特征和标签之间的卡方统计量(特征和标签的相关性),并依照卡方统计量由高到低为特征排名
#卡方过滤,卡方检验类feature_selection.chi2计算每个非负特征和标签之间的卡方统计量(特征和标签的相关性),并依照卡方统计量由高到低为特征排名
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
#假设在这里我一直我需要300个特征
X_fschi = SelectKBest(chi2, k=300).fit_transform(X, y)
互信息法:互信息法是用来捕捉每个特征与标签之间的任意关系(包括线性和非线性关系)的过滤方法
#互信息法,互信息法是用来捕捉每个特征与标签之间的任意关系(包括线性和非线性关系)的过滤方法
from sklearn.feature_selection import mutual_info_classif as MIC
result = MIC(X_fsvar,y)
k = result.shape[0] - sum(result 0)
2.Embedded嵌入法
嵌入法是一种让算法自己决定使用哪些特征的方法,即特征选择和算法训练同时进行。在使用嵌入法时,我们先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大到小选择特征。这些权值系数往往代表了特征对于模型的某种贡献或某种重要性.
代码如下(示例):
#通过设置模型重要程度阈值来筛选特征
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier as RFC
RFC_ = RFC(n_estimators =10,random_state=0)#利用随机森林来筛选特征
X_embedded = SelectFromModel(RFC_,threshold=0.05).fit_transform(X,y)
#这里设置贡献度为0.05作为阈值,这个阈值跟你的特征数量有关,正常情况下我们会通过学习曲线来确定阈值。
#RFC_.feature_importances_用来查看特征重要程度
#我们也可以画学习曲线来找最佳阈值
import numpy as np
import matplotlib.pyplot as plt
RFC_.fit(X,y).feature_importances_
threshold = np.linspace(0,(RFC_.fit(X,y).feature_importances_).max(),20)
score = []
for i in threshold:
X_embedded = SelectFromModel(RFC_,threshold=i).fit_transform(X,y)
once = cross_val_score(RFC_,X_embedded,y,cv=5).mean()
score.append(once)
plt.plot(threshold,score)
plt.show()
3. Wrapper包装法
包装法也是一个特征选择和算法训练同时进行的方法,与嵌入法十分相似,它也是依赖于算法自身的选择,比如coef_属性或者特征重要性来完成特征选择。 但不同的是,我们往往使用一个目标函数作为黑盒来帮助我们选取特征,而不是自己输入某个评估指标或统计量的阈值。
代码如下(示例):
from sklearn.feature_selection import RFE
RFC_ = RFC(n_estimators =10,random_state=0)
selector = RFE(RFC_, n_features_to_select=340, step=50).fit(X, y)
#n_features_to_select是想要选择的特征个数,step表示每次迭代中希望移除的特征个数。
X_wrapper = selector.transform(X)
#包装法学习曲线,来确定最佳参数
score = []
for i in range(1,751,50):
X_wrapper = RFE(RFC_,n_features_to_select=i, step=50).fit_transform(X,y)
once = cross_val_score(RFC_,X_wrapper,y,cv=5).mean()
score.append(once)
plt.figure(figsize=[20,5])
plt.plot(range(1,751,50),score)
plt.xticks(range(1,751,50))
plt.show()
4.PCA与LDA降维
降维算法不能简单的称为特征选择,它能减少特征的数量,又保留大部分有效信息,可以简单理解成一种特征压缩的手段,其本质是对矩阵的分解。
代码如下(示例):
#PCA降维
from sklearn.decomposition import PCA
X_dr = PCA(2).fit_transform(X)#输入你要降到的维度数量,这里为2
#如果你不确定你的超参数,你可以用最大似然估计来选取你要压缩到的维度,当然你也可以绘制学习曲线来确定你的参数
pca_mle = PCA(n_components="mle")
X_mle = pca_mle.fit_transform(X)
#LDA降维
from sklearn.lda import LDA
#参数n_components为降维后的维数
X=LDA(n_components=2).fit_transform(X, y)
5.特征选择经验技巧
1.经验来说,过滤法更快速,但更粗糙。
2.包装法和嵌入法更精确,比较适合具体到算法去调整,但计算量比较大,运行时间长。
3.当数据量很大的时候,优先使用方差过滤和互信息法调整,再上其他特征选择方法。
4.使用逻辑回归时,优先使用嵌入法。使用支持向量机时,优先使用包装法。迷茫的时候,从过滤法走起,看具体数据具体分析。
5.其实特征选择只是特征工程中的第一步。真正的高手,往往使用特征创造或特征提取来寻找高级特征。在Kaggle之类的算法竞赛中,很多高分团队都是在高级特征上做文章,而这是比调参和特征选择更难的,提升算法表现的高深方法。特征工程非常深奥,虽然我们日常可能用到不多,但其实它非常美妙。若大家感兴趣,也可以自己去网上搜一搜,多读多看多试多想,技术逐渐会成为你的囊中之物。
四、模型搭建及优化
1.模型评估
建模的评估一般可以分为回归、分类和聚类的评估。
1.1回归模型评估(平均绝对误差、平均方差、R平方值)
代码如下(示例):
#sklearn的调用,回归常用评估函数,输入测试标签、模型预测标签
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
mean_absolute_error(y_test,y_predict)#平均绝对误差
mean_squared_error(y_test,y_predict)#平均方差
r2_score(y_test,y_predict)#R平方值
1.2分类模型评估(分类报告、混淆矩阵、ROC曲线、交叉验证)
代码如下(示例):
分类报告
#sklearn的调用,分类常用评估函数,输入你的测试集
#分类报告:输出包括了precision/recall/fi-score/均值/分类个数
from sklearn.metrics import classification_report
y_true = y_test #测试集标签
y_pred = model.predict(x_test)#测试集预测值
target_names = ['class 0', 'class 1', 'class 2']#写入你标签的类别名,有几个就写几个
print(classification_report(y_true, y_pred, target_names=target_names))
混淆矩阵
#sklearn的调用,混淆矩阵 输入你的测试集
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
y_true = y_test #测试集标签
y_pred = model.predict(x_test)#测试集预测值
confusion_mat = confusion_matrix(y_true, y_pred)
print(confusion_mat) #看看混淆矩阵长啥样
#sklearn的调用,混淆矩阵可视化
def plot_confusion_matrix(confusion_mat):
'''''将混淆矩阵画图并显示出来'''
plt.imshow(confusion_mat, interpolation='nearest', cmap=plt.cm.gray)
plt.title('Confusion matrix')
plt.colorbar()
tick_marks = np.arange(confusion_mat.shape[0])
plt.xticks(tick_marks, tick_marks)
plt.yticks(tick_marks, tick_marks)
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
plot_confusion_matrix(confusion_mat)
ROC曲线
#sklearn的调用,绘制ROC曲线,AUC就是ROC 曲线下的面积,通常情况下数值介于0.5-1之间,可以评价分类器的好坏,数值越大说明越好。
from sklearn.metrics import roc_curve as ROC
import matplotlib.pyplot as plt
#导入模型,测试集
def roc_auc_score_plot(clf,Xtest,Ytest):
FPR, Recall, thresholds = ROC(Ytest,clf.decision_function(Xtest),pos_label=1)
area = roc_auc_score(Ytest,clf.decision_function(Xtest))#计算auc的值
plt.figure()
plt.plot(FPR, Recall, color='red',
label='ROC curve (area = %0.2f)' % area)
plt.plot([0, 1], [0, 1], color='black', linestyle='--')
plt.xlim([-0.05, 1.05])
plt.ylim([-0.05, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('Recall')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()
交叉验证
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model,X, y,cv=3)#cv:默认是3折交叉验证,可以修改cv=5,变成5折交叉验证
1.3聚类模型评估(ARI、轮廓系数)
代码如下(示例):
ARI:取值范围为[-1,1],负数代表结果不好,值越大意味着聚类结果与真实情况越吻合。ARI可用于聚类算法之间的比较
#ARI接口
from sklearn import metrics
labels_true = [0,0,0,1,1,1]#真实标签
labels_pred = [0,0,1,1,2,2]#预测标签
print(metrics.adjusted_rand_score(labels_true,labels_pred))
轮廓系数:用于没有基准可用时的聚类质量评估,通过考察簇的分离情况和簇的紧凑度进行聚类评估。轮廓系数的值在-1到1之间,轮廓系数越接近于1,聚类效果越好。
#一个求轮廓系数的案例
import numpy as np
from sklearn.cluster import KMeans
from sklearn import metrics
from sklearn.metrics import silhouette_score
from sklearn.datasets import load_iris # 导入数据集iris
X = load_iris().data # 载入数据集
kmeans_model = KMeans(n_clusters=3,random_state=1).fit(X)
labels = kmeans_model.labels_
metrics.silhouette_score(X,labels,metric='euclidean')#得到轮廓系数
2.机器学习常用回归模型
2.1 线性回归
代码如下(示例):
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
lin_reg = LinearRegression(fit_intercept=True, normalize=False, copy_X=True, n_jobs=None)
lin_reg.fit(X_train,y_train)#传入训练数据
print ('线性回归模型的均方误差为:',mean_squared_error(lin_reg.inverse_transform(y_test),lin_reg.inverse_tranform(lr_y_predict)))#均方误差,看模型效果

2.2 决策树回归
代码如下(示例):
%matplotlib inline
from sklearn import tree
clf = tree.DecisionTreeRegressor()
clf = clf.fit(X_train,y_train)
参数说明

1、 criterion:特征选取方法,mse或mae,前者是均方差,后者是和均值的差的绝对值之和,一般用前者,因为前者通常更为精准,且方便计算
2、 splitter: 特征划分点选择方法,可以是best或random,前者是在特征的全部划分点中找到最优的划分点,后者是在随机选择的部分划分点找到局部最优的划分点,一般在样本量不大的时候,选择best,样本量过大,可以用random
3、 max_depth: 树的最大深度,默认可以不输入,那么不会限制子树的深度,一般在样本少特征也少的情况下,可以不做限制,但是样本过多或者特征过多的情况下,可以设定一个上限,一般取10~100
4、 min_samples_split:节点再划分所需最少样本数,如果节点上的样本树已经低于这个值,则不会再寻找最优的划分点进行划分,且以结点作为叶子节点,默认是2,如果样本过多的情况下,可以设定一个阈值,具体可根据业务需求和数据量来定
5、 min_samples_leaf: 叶子节点所需最少样本数,如果达不到这个阈值,则同一父节点的所有叶子节点均被剪枝,这是一个防止过拟合的参数,可以输入一个具体的值,或小于1的数(会根据样本量计算百分比)
6、 min_weight_fraction_leaf: 叶子节点所有样本权重和,如果低于阈值,则会和兄弟节点一起被剪枝,默认是0,就是不考虑权重问题。这个一般在样本类别偏差较大或有较多缺失值的情况下会考虑
7、 max_features: 划分考虑最大特征数,不输入则默认全部特征,可以选 log2N,sqrt(N),auto或者是小于1的浮点数(百分比)或整数(具体数量的特征)。如果特征特别多时如大于50,可以考虑选择auto来控制决策树的生成时间
8、 max_leaf_nodes:最大叶子节点数,防止过拟合,默认不限制,如果设定了阈值,那么会在阈值范围内得到最优的决策树,样本量过多时可以设定
9、min_impurity_decrease/min_impurity_split: 划分最需最小不纯度,前者是特征选择时低于就不考虑这个特征,后者是如果选取的最优特征划分后达不到这个阈值,则不再划分,节点变成叶子节点
10、presort: 是否排序,基本不用管
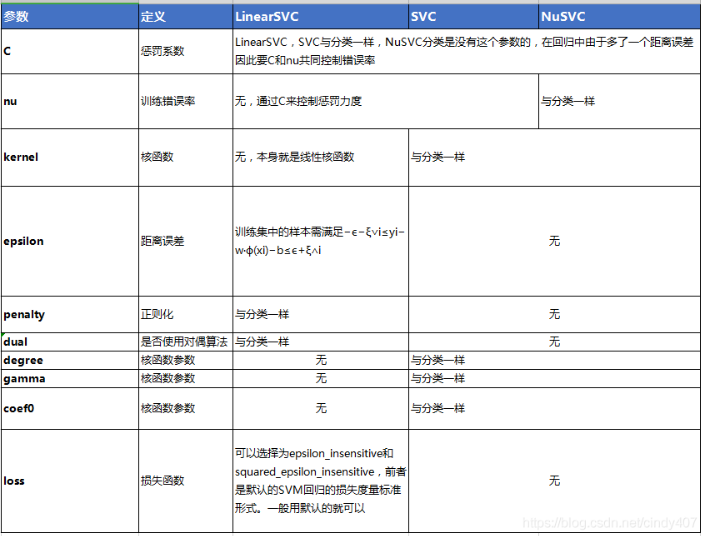
2.3 支持向量机回归
代码如下(示例):
from sklearn.svm import LinearSVC
svm_clf=LinearSVC()
svm_clf.fit(X_train,y_train)
2.4 K近邻回归
代码如下(示例):
from sklearn import neighbors
model_KNeighborsRegressor = neighbors.KNeighborsRegressor()
model_KNeighborsRegressor.fit(X_train,y_train)
2.5 随机森林回归
代码如下(示例):
from sklearn import ensemble
model_RandomForestRegressor = ensemble.RandomForestRegressor(n_estimators=100)
model_RandomForestRegresso.fit(X_train,y_train)
重要参数
n_estimators:森林中基评估器的数量,即树的数量。n_estimators越大模型效果越好,但达到一定程度时,精确性趋于稳定。默认为100。
criterion:衡量标准。gini系数和信息熵2种。
max_depth:树的最大深度
mini_sample_leaf:min_samples_leaf=1,二叉树
mini_samples_split:mini_samples_split=2一个节点分成几类样本
max_features:树的特征个数
random_state :随机种子,选42吧,宇宙终极奥秘。
2.6 Adaboost 回归
代码如下(示例):
from sklearn import ensemble
model_AdaBoostRegressor = ensemble.AdaBoostRegressor(n_estimators=50)
model_AdaBoostRegressor.fit(X_train,y_train)
① criterion: 特征选取方法,分类是gini(基尼系数),entropy(信息增益),通常选择gini,即CART算法,如果选择后者,则是ID3和C4,.5;回归是mse或mae,前者是均方差,后者是和均值的差的绝对值之和,一般用前者,因为前者通常更为精准,且方便计算
② splitter: 特征划分点选择方法,可以是best或random,前者是在特征的全部划分点中找到最优的划分点,后者是在随机选择的部分划分点找到局部最优的划分点,一般在样本量不大的时候,选择best,样本量过大,可以用random
③ max_depth: 树的最大深度,默认可以不输入,那么不会限制子树的深度,一般在样本少特征也少的情况下,可以不做限制,但是样本过多或者特征过多的情况下,可以设定一个上限,一般取10~100
④ min_samples_split:节点再划分所需最少样本数,如果节点上的样本树已经低于这个值,则不会再寻找最优的划分点进行划分,且以结点作为叶子节点,默认是2,如果样本过多的情况下,可以设定一个阈值,具体可根据业务需求和数据量来定
⑤ min_samples_leaf: 叶子节点所需最少样本数,如果达不到这个阈值,则同一父节点的所有叶子节点均被剪枝,这是一个防止过拟合的参数,可以输入一个具体的值,或小于1的数(会根据样本量计算百分比)
⑥ min_weight_fraction_leaf: 叶子节点所有样本权重和,如果低于阈值,则会和兄弟节点一起被剪枝,默认是0,就是不考虑权重问题。这个一般在样本类别偏差较大或有较多缺失值的情况下会考虑
⑦ max_features: 划分考虑最大特征数,不输入则默认全部特征,可以选 log2N,sqrt(N),auto或者是小于1的浮点数(百分比)或整数(具体数量的特征)。如果特征特别多时如大于50,可以考虑选择auto来控制决策树的生成时间
⑧ max_leaf_nodes:最大叶子节点数,防止过拟合,默认不限制,如果设定了阈值,那么会在阈值范围内得到最优的决策树,样本量过多时可以设定
⑨min_impurity_decrease/min_impurity_split: 划分最需最小不纯度,前者是特征选择时低于就不考虑这个特征,后者是如果选取的最优特征划分后达不到这个阈值,则不再划分,节点变成叶子节点
2.7 梯度增强随机森林回归
代码如下(示例):
from sklearn import ensemble
model_GradientBoostingRegressor = ensemble.GradientBoostingRegressor(n_estimators=100)
model_GradientBoostingRegressor.fit(X_train,y_train)
参数参考随机森林
2.8 Bagging 回归
代码如下(示例):
from sklearn.ensemble import BaggingRegressor
model_BaggingRegressor = BaggingRegressor()
model_BaggingRegressor.fit(X_train,y_train)
重要参数
base_estimator:Object or None。None代表默认是DecisionTree,Object可以指定基估计器(base estimator)。
n_estimators:int, optional (default=10) 。 要集成的基估计器的个数。
max_samples: int or float, optional (default=1.0)。决定从x_train抽取去训练基估计器的样本数量。int 代表抽取数量,float代表抽取比例
max_features : int or float, optional (default=1.0)。决定从x_train抽取去训练基估计器的特征数量。int 代表抽取数量,float代表抽取比例
bootstrap : boolean, optional (default=True) 决定样本子集的抽样方式(有放回和不放回)
bootstrap_features : boolean, optional (default=False)决定特征子集的抽样方式(有放回和不放回)
oob_score : bool 决定是否使用包外估计(out of bag estimate)泛化误差
warm_start : bool, optional (default=False) true代表
n_jobs : int, optional (default=1)
random_state : 选42吧,宇宙终极奥秘。
2.9 ExtraTree 回归
代码如下(示例):
from sklearn.tree import ExtraTreeRegressor
model_ExtraTreeRegressor = ExtraTreeRegressor()
model_ExtraTreeRegressor.fit(X_train,y_train)
2.10 Xgboost回归
代码如下(示例):
from xgboost.sklearn import XGBRegressor
gsearch1 = GridSearchCV(estimator=XGBRegressor(scoring='ls',seed=27), param_grid=param_grid, cv=5)
gsearch1.fit(X_train, y_train)
重要参数
n_estimators(基本学习器的数量):要拟合的弱学习器数量,该值越大,模型越复杂,越容易过拟合
max_depth(基本学习器的深度): 树的最大深度,该值越大,模型越复杂,越容易拟合训练数据,越容易过拟合;树生长停止条件之一
learning_rate(学习率):每个基模型的惩罚项,降低单个模型的影响,为了防止过拟合,该值越接近1越容易或拟合,越接近0精度越低
gamma(损失减少阈值):在树的叶节点上进一步划分所需的最小损失减少,在模型训练过程中,只有损失下降的值超过该值,才会继续分裂节点,该值越小模型越复杂,越容易过拟合,树生长停止条件之一
reg_alpha(L1正则化):L1正则化用于对叶子的个数进行惩罚,用于防止过拟合
reg_lambda(L2正则化):L2正则化用于对叶子节点的得分进行惩罚,L1和L2正则化项共同惩罚树的复杂度,值越小模型的鲁棒性越高
min_child_weight(子集最小权重):最小样本的权重之和,在树的生长过程中,如果样本的权重之和小于该值,将不再分裂;树生长停止条件之一
subsample(样本子采样):训练集对样本实例的采样率,用于防止过拟合
colsample_bytree(列子采样):每棵树对特征的采样率,用于防止过拟合
3.机器学习常用分类模型
3.1 决策树分类
代码如下(示例):
from sklearn.tree import DecisionTreeClassifier as DTC
model=DTC(max_depth=8,random_state=42)
model.fit(X_train, y_train)
重要参数
1、 criterion: 特征选取方法,可以是gini(基尼系数),entropy(信息增益),通常选择gini,即CART算法,如果选择后者,则是ID3和C4,.5
2、 splitter: 特征划分点选择方法,可以是best或random,前者是在特征的全部划分点中找到最优的划分点,后者是在随机选择的部分划分点找到局部最优的划分点,一般在样本量不大的时候,选择best,样本量过大,可以用random
3、 max_depth: 树的最大深度,默认可以不输入,那么不会限制子树的深度,一般在样本少特征也少的情况下,可以不做限制,但是样本过多或者特征过多的情况下,可以设定一个上限,一般取10~100
4、 min_samples_split:节点再划分所需最少样本数,如果节点上的样本树已经低于这个值,则不会再寻找最优的划分点进行划分,且以结点作为叶子节点,默认是2,如果样本过多的情况下,可以设定一个阈值,具体可根据业务需求和数据量来定
5、 min_samples_leaf: 叶子节点所需最少样本数,如果达不到这个阈值,则同一父节点的所有叶子节点均被剪枝,这是一个防止过拟合的参数,可以输入一个具体的值,或小于1的数(会根据样本量计算百分比)
6、 min_weight_fraction_leaf: 叶子节点所有样本权重和,如果低于阈值,则会和兄弟节点一起被剪枝,默认是0,就是不考虑权重问题。这个一般在样本类别偏差较大或有较多缺失值的情况下会考虑
7、 max_features: 划分考虑最大特征数,不输入则默认全部特征,可以选 log2N,sqrt(N),auto或者是小于1的浮点数(百分比)或整数(具体数量的特征)。如果特征特别多时如大于50,可以考虑选择auto来控制决策树的生成时间
8、 max_leaf_nodes:最大叶子节点数,防止过拟合,默认不限制,如果设定了阈值,那么会在阈值范围内得到最优的决策树,样本量过多时可以设定
9、min_impurity_decrease/min_impurity_split: 划分最需最小不纯度,前者是特征选择时低于就不考虑这个特征,后者是如果选取的最优特征划分后达不到这个阈值,则不再划分,节点变成叶子节点
10、class_weight: 类别权重,在样本有较大缺失值或类别偏差较大时可选,防止决策树向类别过大的样本倾斜。可设定或者balanced,后者会自动根据样本的数量分布计算权重,样本数少则权重高,与min_weight_fraction_leaf对应
11、presort: 是否排序,基本不用管
3.2 随机森林分类
代码如下(示例):
from sklearn.ensemble import RandomForestClassifier as RFC
model=RFC(n_estimators=100,random_state=42,n_jobs=8)
model.fit(X_train, y_train)
重要参数
n_estimators:森林中基评估器的数量,即树的数量。n_estimators越大模型效果越好,但达到一定程度时,精确性趋于稳定。默认为100。
criterion:衡量标准。gini系数和信息熵2种。
max_depth:树的最大深度
mini_sample_leaf:min_samples_leaf=1,二叉树
mini_samples_split:mini_samples_split=2一个节点分成几类样本
max_features:树的特征个数
random_state :随机种子
3.3 Adaboost分类
代码如下(示例):
from sklearn.ensemble import AdaBoostClassifier
model=AdaBoostClassifier_()
model.fit(X_train, y_train)
重要参数
base_estimator:基分类器,默认是决策树,在该分类器基础上进行boosting,理论上可以是任意一个分类器,但是如果是其他分类器时需要指明样本权重。
n_estimators:基分类器提升(循环)次数,默认是50次,这个值过大,模型容易过拟合;值过小,模型容易欠拟合。
learning_rate:学习率,表示梯度收敛速度,默认为1,如果过大,容易错过最优值,如果过小,则收敛速度会很慢;该值需要和n_estimators进行一个权衡,当分类器迭代次数较少时,学习率可以小一些,当迭代次数较多时,学习率可以适当放大。
algorithm:boosting算法,也就是模型提升准则,有两种方式SAMME, 和SAMME.R两种,默认是SAMME.R,两者的区别主要是弱学习器权重的度量,前者是对样本集预测错误的概率进行划分的,后者是对样本集的预测错误的比例,即错分率进行划分的,默认是用的SAMME.R。
random_state:随机种子设置。
3.4 GBDT分类
代码如下(示例):
from sklearn.ensemble import GradientBoostingClassifier as GBDT
model=GBDT(n_estimators=100,random_state=1412)
model.fit(X_train, y_train)
重要参数
1) n_estimators: 也就是弱学习器的最大迭代次数,或者说最大的弱学习器的个数。一般来说n_estimators太小,容易欠拟合,n_estimators太大,又容易过拟合,一般选择一个适中的数值。默认是100。在实际调参的过程中,我们常常将n_estimators和下面介绍的参数learning_rate一起考虑。
2) learning_rate: 即每个弱学习器的权重缩减系数𝜈ν,也称作步长,在原理篇的正则化章节我们也讲到了,加上了正则化项,我们的强学习器的迭代公式为𝑓𝑘(𝑥)=𝑓𝑘−1(𝑥)+𝜈ℎ𝑘(𝑥)fk(x)=fk−1(x)+νhk(x)。𝜈ν的取值范围为0
Original: https://blog.csdn.net/weixin_43756027/article/details/124013843
Author: WX_ygg17634504536
Title: 机器学习实用代码汇总(你想要的这里都有)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/606170/
转载文章受原作者版权保护。转载请注明原作者出处!