

决策树回归模型和集合算法
1. 决策树概述
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率 ——百度百科
决策树就是我们通常所说的多叉树
决策树回归模型的核心思想:相似的输入必会产生相似的输出
决策树每层对应一个样本特征
使用树结构,对于海量数据可以提高检索效率
2. 构建决策树回归模型的基本思想
构建决策树的基本步骤:
a、从训练样本矩阵中选择第一个特征进行子表划分,是每个字表中的该特征的值全部相同;
b、在每一个字表中选择下一个特征按照同样的规则继续划分更小的子表;
c、不断重复步骤b直到所有的特征全部使用完毕,此时便得到叶级子表,每个叶级子表种的特征值完全相同
预测样本根据决策树不同层级的特征值进行查找,选择对应的叶级子表,用该叶级子表的输出,通过平均(回归)、或投票(分类)为带预测样本提供输出
随着子表的不断划分,信息熵(信息的混乱程度)越来越小,信息越来越纯净,数据越来越有序
3. 决策树回归模型api
api:sklearn.tree
import sklearn.tree as st
#创建决策树回归器模型,其中max_depth表示树的深度/层数
model = st.DecisionTreeRegressor(max_depth=)
代码示例:
import sklearn.datasets as sd
import sklearn.utils as su
import numpy as np
import sklearn.tree as st
import sklearn.metrics as sm
import sklearn.ensemble as se
import matplotlib.pyplot as plt
boston = sd.load_boston()
"""
print(boston.feature_names) 输入集特征名称
['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO' 'B' 'LSTAT']
[犯罪率 住宅用地比例 商业用地比例 是否靠河 空气质量 房屋数 年限 距中心区距离 路网密度 房产税 师生比 黑人比例 低地位人口比例]
print(boston.data.shape) 输入集大小
print(boston.target.shape) 输出集大小
"""
x, y = su.shuffle(boston.data, boston.target, random_state=7)
train_size = int(len(x)*0.8)
train_x, test_x, train_y, test_y = x[:train_size], x[train_size:], y[:train_size], y[train_size:]
model = st.DecisionTreeRegressor(max_depth=4)
model.fit(train_x, train_y)
res_y = model.predict(test_x)
print("R2得分:", sm.r2_score(test_y, res_y))
print("平均绝对值误差:", sm.mean_absolute_error(test_y, res_y))
输出结果
R2得分: 0.8202560889408635
平均绝对值误差: 2.76709759407969
4. 集合算法
特征工程的优化
不必用尽所有特征,叶级子表种允许混杂不同的特征值,以此降低决策树的层数,在精度牺牲可接受的情况下提高模型的性能
通常情况下可以优先选择使信息熵减少量最大的特征特征作为划分子表的依据
1. 概念
根据多种不同模型的预测结果,利用平均(回归)或投票(分类)的方式得到最终的预测结果
2. 正向激励
首先为样本矩阵中的样本随机分配初始权重,构建一颗带权重的决策树,在由该决策树预测输出时,通过加权平均或加权投票的方式产生预测值。
将训练样本带入模型,预测其输出,对那些预测值和实际值偏差加大的样本,提高其权重,形成第二个决策树。重复以上过程,形成若决策树。
api:sklearn.ensemble.AdaBoostRegressor
代码示例:
model2 = st.DecisionTreeRegressor(max_depth=4)
"""
自适应增长决策树回归模型
n_estimators 指定构建的决策树模型的数量 具体数字根据实际情况设定
random_state 随机数种子
"""
model3 = se.AdaBoostRegressor(model2, n_estimators=400, random_state=7)
model3.fit(train_x, train_y)
res_y3 = model3.predict(test_x)
print("R2:", sm.r2_score(test_y, res_y3), '\n', sm.mean_absolute_error(test_y, res_y3))
输出结果
R2: 0.9083427831010076
2.163353134343898
结果较之前有一定的优化
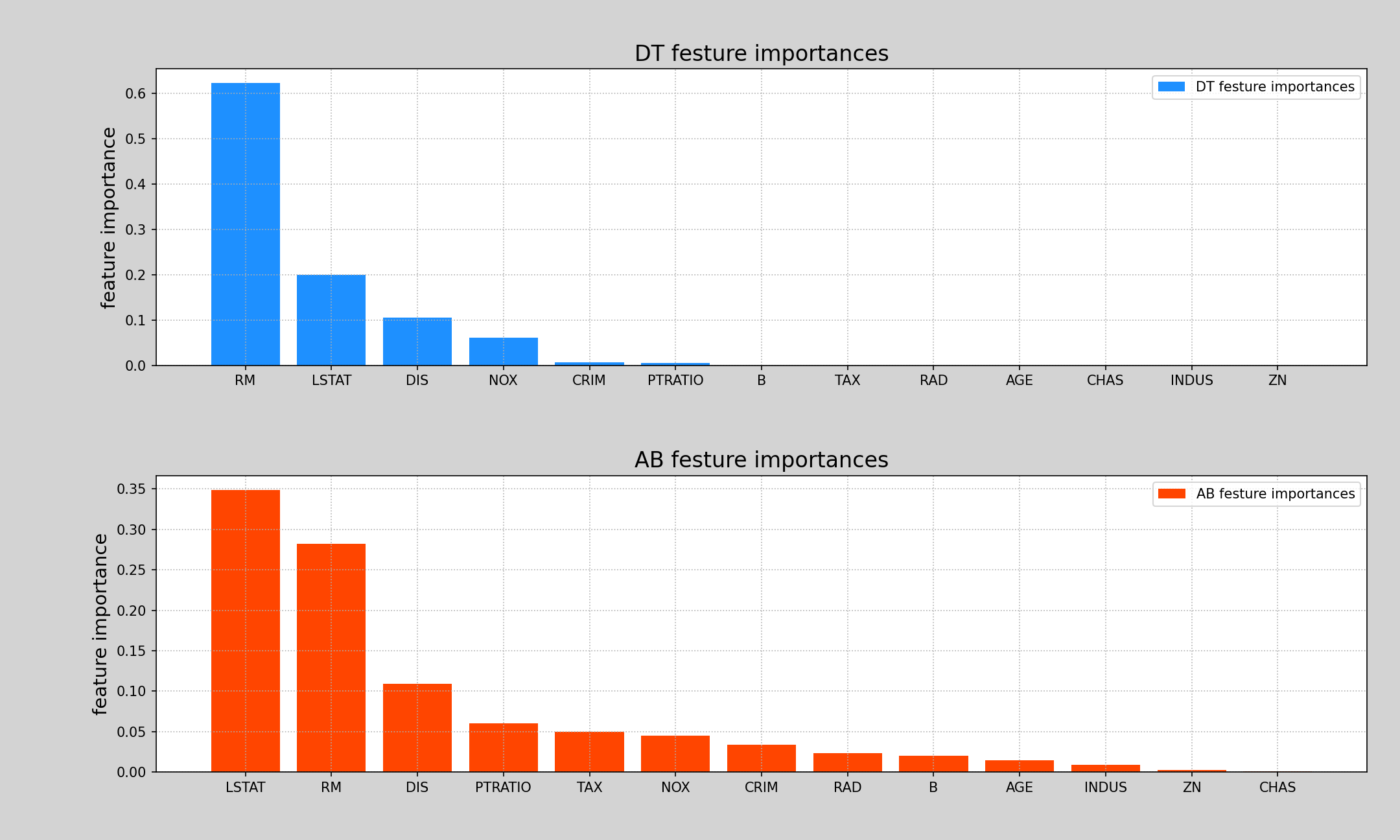
3. 特征重要性
特征重要性是决策树训练过程中的副产品,根据每个特征划分子表前后的信息熵减少量决定了特征的重要程度
每个特征重要性存储在训练得到的模型对象的属性feature_importances_中
api: model.feature_importances_
下边绘制普通决策树和正向激励的特征重要性柱状图
fi = model.feature_importances_
fi3 = model3.feature_importances_
x = np.arange(fi.size)
features = boston.feature_names
plt.figure('Feature Importances', facecolor='lightgray')
plt.subplot(211)
plt.title('DT festure importances', fontsize=16)
plt.ylabel('feature importance', fontsize=14)
plt.grid(linestyle=':', axis='both')
sort_indicts = fi.argsort()[::-1]
fi = fi[sort_indicts]
plt.bar(x, fi, 0.8, color='dodgerblue', label='DT festure importances')
plt.xticks(x, features[sort_indicts])
plt.legend()
plt.tight_layout()
plt.subplot(212)
plt.title('AB festure importances', fontsize=16)
plt.ylabel('feature importance', fontsize=14)
plt.grid(linestyle=':', axis='both')
sort_indicts3 = fi3.argsort()[::-1]
fi3 = fi3[sort_indicts3]
plt.bar(x, fi3, 0.8, color='orangered', label='AB festure importances')
plt.xticks(x, features[sort_indicts3])
plt.legend()
plt.tight_layout()
plt.show()

4. 随机森林
自助聚合
以又放回的随机抽样的方式,从原始样本中又放回的随机抽取部分样本构建决策树,形成多课包含不同样本的决策树,
削弱某些强势样本对模型预测结果的影响,提高模型的泛化特性
没有api,需要自己根据逻辑手写代码
随机森林
随机森林是在以自助聚合为基础,每次构建决策树模型,不仅随机选取部分样本,而且还随机选取部分特征,
这样的集合算法不仅削弱强势样本对预测结果的影响,还削弱了强势特征对预测结果的影响,是模型的预测更加泛化
api:sklearn.ensemble.RandomForestRegressor
代码示例:
"""
RandomForestRegressor:随机森林api
参数:
max_depth 决策树的最大深度
n_estimators 随机森林的决策树的数量
min_samples_split 决策树最小的样本数量
"""
model4 = se.RandomForestRegressor(max_depth=10, n_estimators=10000, min_samples_split=2)
model4.fit(train_x, train_y)
res_y4 = model4.predict(test_x)
print(sm.r2_score(test_y, res_y4), '\n', sm.mean_absolute_error(test_y, res_y4))
输出结果:
0.9269176455289898
1.8766746146314175
与正向激励比较,得分更高,误差更小
Original: https://blog.csdn.net/weixin_49429431/article/details/123393668
Author: 稻城亚丁途
Title: 机器学习(五)—— 决策树回归模型和集合算法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/606146/
转载文章受原作者版权保护。转载请注明原作者出处!