

在人工智能课程中学习线性回归一章时,高阶线性回归需要用到PolynomialFeatures方法构造特征。
先看一下官方文档对于sklearn.preprocessing.PolynomialFeatures方法的解释:
Generate polynomial and interaction features.
Generate a new feature matrix consisting of all polynomial combinations of the features with degree less than or equal to the specified degree. For example, if an input sample is two dimensional and of the form [a, b], the degree-2 polynomial features are [1, a, b, a^2, ab, b^2].
简单翻译一下,意思就是:
生成多项式交互特征。
生成一个新的特征矩阵,包含特定阶数及以下的全部多项式组合。例如,样本特征为二维的,包含[a, b]。其全部二阶多项式特征为[1, a, b, a^2, ab, b^2]。
解释一下,其中包含0阶特征[1],一阶特征为[a, b],二阶特征[a^2, ab, b^2]。也就是说,你只要输入[a, b],自动生成并返回[1, a, b, a^2, ab, b^2]这样一个特征矩阵。(偏置值设为默认值include_bias=True)
在用线性模型LinearRegression拟合时,输入新生成的特征矩阵和标签值矩阵,便可以拟合训练为一个相应高阶的模型。
下面展示一下PolynomialFeatures的使用:
1、首先创建一个数据集。
将其分为训练集和验证集,由于这里用不到所以先不生成测试集了。
import numpy as np
from sklearn.model_selection import train_test_split
生成训练集与验证集,数据带有标准差为0.1的噪声
n = 100
n_train = int(0.8 * n)
n_valid = int(0.2 * n)
x = 6 * np.random.rand(n, 1) - 3
y = 1.2 * x - 3.4 * (x ** 2) + 5.6 * (x ** 3) + 5 + 0.1 * np.random.randn(n, 1)
x_train_set, x_valid_set, y_train_set, y_valid_set = train_test_split(x, y, test_size=0.2, random_state=5)
2、调用PolynomialFeatures方法生成特征矩阵。
由于我们的特征样本只有[x],并且设为三阶(degree=3),所以生成的特征矩阵(include_bias=True)为[1, x, x^2, x^3]。
可以看到矩阵下标为0的这列全部为’1’,这就是偏置值的作用。
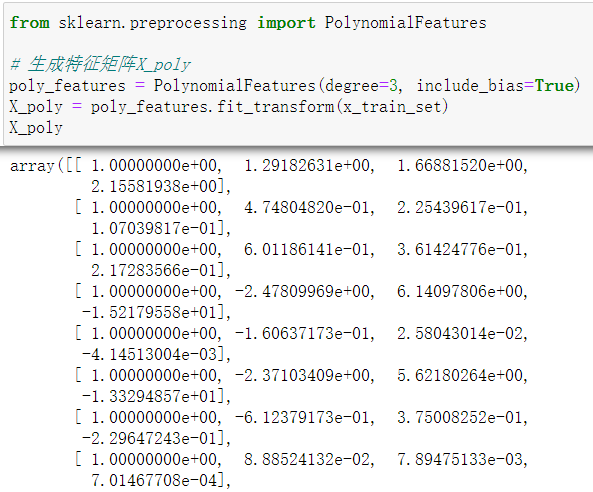

3、设置偏置值include_bias=False
生成的特征矩阵变为[x, x^2, x^3]
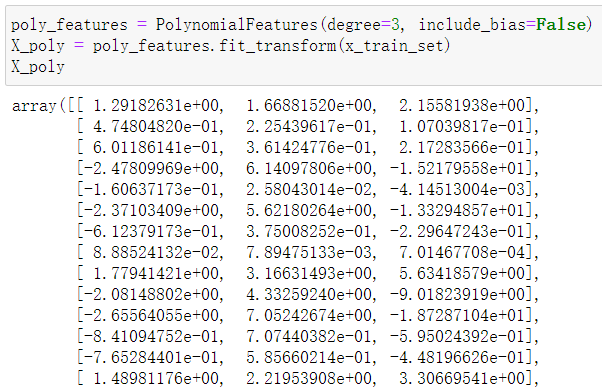
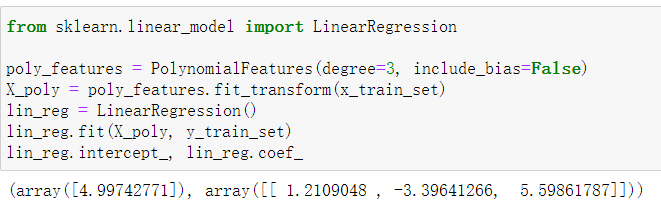
4.1、带入公式计算参数theta
此时的X_poly是include_bias=True时生成的

4.2、或是使用sklearn.linear_model.LinearRegression拟合模型
此时的X_poly是include_bias=False生成的
5、Pipeline中inlude_bias的设置
根据上面的例子,我们可以看到,使用sklearn的LinearRegression方法进行模型拟合时,输入的是不含偏置值的特征矩阵,即include_bias=False。
同理,可以理解,在使用sklearn.pipeline.Pipeline是,如果需要生成多项式特征矩阵,LinearRegression方法的偏置值设置也是include_bias=False。
如下图

Original: https://www.cnblogs.com/mumuxin-gv/p/15393598.html
Author: 木心95
Title: 机器学习学习笔记:sklearn.preprocessing.PolynomialFeatures偏置值inlude_bias设置,以及在Pipeline中的设置
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/604889/
转载文章受原作者版权保护。转载请注明原作者出处!