

这节课是巡安似海PyHacker编写指南的《打造网站Cms识别工具》
喜欢用Python写脚本的小伙伴可以跟着一起写一写呀。
编写环境:Python2.x
00×1:
需要用到的模块如下:
csharp;gutter:true;
import hashlib
import requests</p>
<pre><code>
**00x2:**
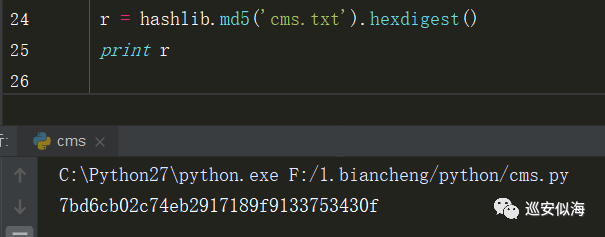
首先利用hashlib.md5().hexdigest()进行获取md5
;gutter:true;
r = hashlib.md5(‘cms.txt’).hexdigest()
print r

获取文件md5:
csharp;gutter:true;
f = open('favicon.png','rb').read()
filemd5 = hashlib.md5(f).hexdigest()
print filemd5</p>
<pre><code>

**00x3:**
获取网站文件的md5:
;gutter:true;
req=requests.get(‘http://www.hackxc.cc/content/templates/Adams/images/favicon.ico’).content
filemd5 = hashlib.md5(req).hexdigest()
print filemd5
00×4:
下面开始整理一下cms.txt
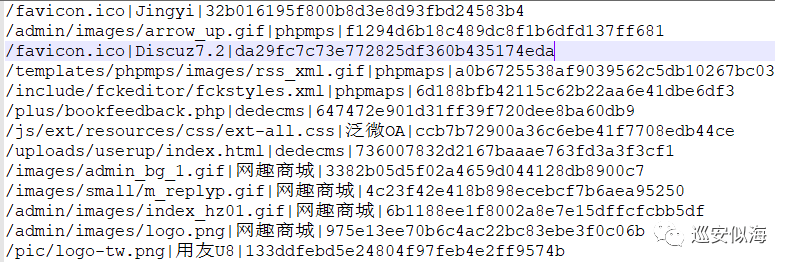
Cms字典处理:
csharp;gutter:true;
data=[]
def cmslist():
file = open("cms.txt")
for line in file:
str = line.strip().split("|")
ls_data={}
if len(str)==3:#判断是否为正确cms格式
ls_data['url']=str[0]
ls_data['name'] = str[1]
ls_data['md5'] = str[2]
data.append(ls_data)
file.close( )
Original: https://www.cnblogs.com/XunanSec/p/pyhacker_cms.html
Author: 巡安似海
Title: 【PyHacker编写指南】网站Cms识别工具
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/603129/
转载文章受原作者版权保护。转载请注明原作者出处!