

记一次HBase进行数据迁移,重建元数据
- 前情提要
- 正文
* - 数据迁移
- 重建元数据
- 测试查询
- 后续的表修复
* - Multiple regions have the same startkey
- Region not listed in hbase:meta or deployed on any region server.
- Region state=FAILED_OPEN
- Region not deployed on any region server
- There is an overlap in the region chain
- Region found in META, but not in HDFS or deployed on any region server
- 拷贝过程的其它问题
* - Distcp失败
- Distcp调优
前情提要
由于早期部署人员和架构上留下的大坑,我们集群的RegionServer组件和其他组件共机严重,服务器负载高时,直接会导致RegionServer断联,出现永久RIT的情况,而且hbck无论怎么修复都不行,虽然业务对hbase的数据需求不是特别的严格,但是有时候应付演示也是要用的,在现有架构难以变动的情况下,想到提供一个小型的同版本集群,进行原始数据拷贝和region重建的工作进行尝试。
正文
数据迁移
首先要将远端Hbase存在HDFS上的数据进行迁移,这里直接使用distcp工具进行拷贝,拷贝前先确认对端的数据和本地要拷贝的数据目录,一般来说都是 /hbase/data/default/{表名}这样的路径:


为了减少对生产环境业务的影响,我的distcp工作都在新集群进行。这样mapreduce是使用新集群的资源运行:
hadoop distcp hdfs://cluster_old/hbase/data/default/tablename /hbase/data/default/

distcp执行期间会产生临时文件,等待任务的最终完成即可:

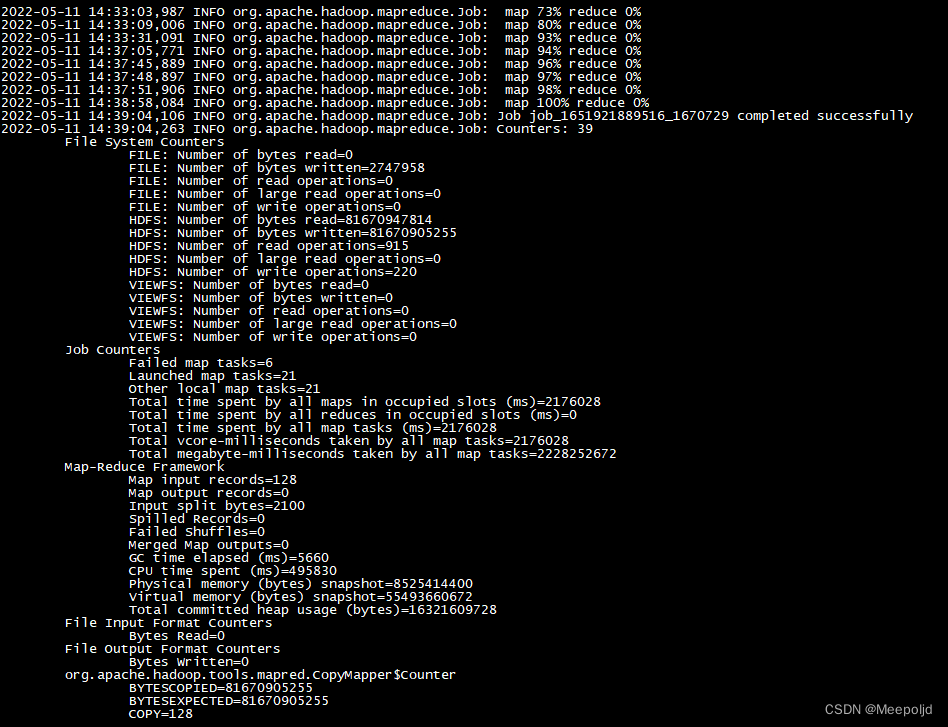
完成需要的表的拷贝后,此时进入hbase执行list命令已经能看到表名了,但是不可以进行查询,因为还没重建表的元数据:
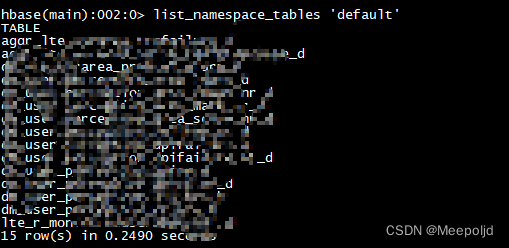
重建元数据
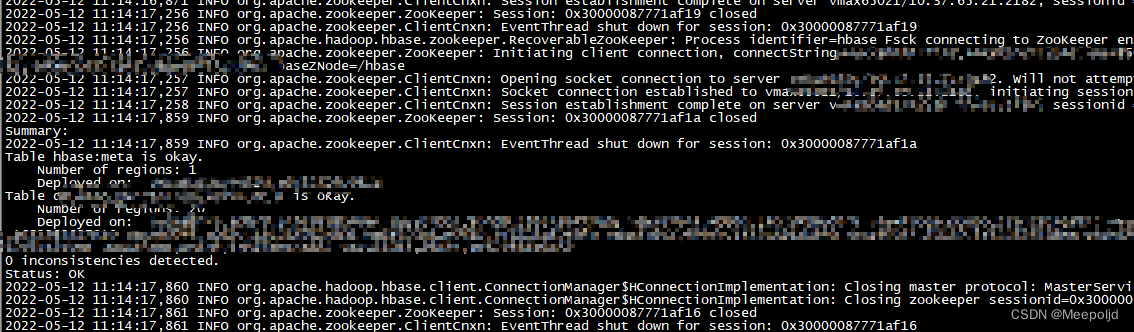
这里也是直接使用hbase hbck工具进行元数据的重建,这里采用的是单个表单个表的进行:
hbase hbck -repair tablename
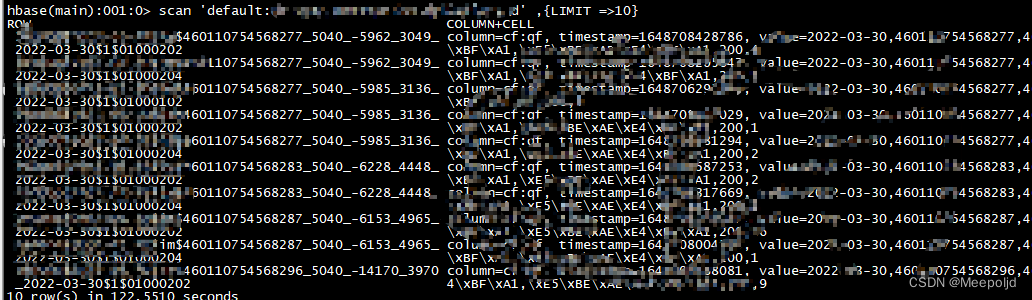
测试查询
随便scan一下,因为现在locality不够,所以可能查询会比较慢,这个会慢慢好的:
; 后续的表修复
Multiple regions have the same startkey
最大的问题就是,原来的数据就已经有问题了,导致我迁移过来以后重建元数据依旧有问题!最恶心的就是 Multiple regions have the same startkey这个,还没发用hbck修复,写了个生成修复命令的脚本:
import os
import commands
def make_json(file):
t = dict()
with open(file) as f:
for item in f:
if "Multiple regions have the same startkey" in item:
item = item.strip('\n')
item = item.split(" ")
region = item[2].strip(')')
startkey = item[-1]
if startkey not in t.keys():
t[startkey]=[]
t[startkey].append(region)
return t
def split_hdfs_result(l):
t = dict()
for i in l:
k = i.split()[1]
v = i.split()[0]
t[k]=v
return t
def check_hdfs_size(t):
allpathsize_map = split_hdfs_result(commands.getoutput("hadoop fs -du /hbase/data/default/dm_user_perception_area_mark_d").split('\n'))
for i in t.keys():
maxregion = ''
maxsize = 0
for region in t[i]:
path = os.path.join("/hbase/data/default/dm_user_perception_area_mark_d", region.split('.')[-2])
try:
if int(allpathsize_map[path]) > int(maxsize):
maxregion = region
maxsize = allpathsize_map[path]
except KeyError as e:
continue
while maxregion in t[i]:
t[i].remove(maxregion)
return t
def make_shell(t):
for k, v in t.items():
li = list(set(v))
for region in li:
for i in ['info:regioninfo', 'info:seqnumDuringOpen', 'info:server', 'info:serverstartcode']:
print("delete 'hbase:meta','{region}','{colum}'".format(region=region, colum=i))
pass
for k, v in t.items():
li = list(set(v))
for region in li:
path = os.path.join("/hbase/data/default/dm_user_perception_area_mark_d", region.split('.')[-2])
print("hadoop fs -rm -r {path}".format(path=path))
if __name__ == "__main__":
a=make_json("hbase.log")
a=check_hdfs_size(a)
make_shell(a)
该脚本会在完成后打印出需要分别在hbase shell和hdfs中执行的命令:

Region not listed in hbase:meta or deployed on any region server.
修复使用fixMeta进行:
hbase hbck -fixMeta
Region state=FAILED_OPEN
如果出现这种问题,最好hbck detail一下,查看具体原因:
hbase hbck -details tablename

比如我这里就出现了一个问题,这个可以直接使用hbck修复:
hbase hbck -fixReferenceFiles tablename

Region not deployed on any region server
hbase hbck -fixAssignments tablename

There is an overlap in the region chain
hbase hbck -fixHdfsOverlaps tablename
Region found in META, but not in HDFS or deployed on any region server
hbase hbck -fixMeta tablename

拷贝过程的其它问题
Distcp失败
有一个表在拷贝的时候,出现异常,任务刚提交没多久就失败,报错是有没法get对应的文件:
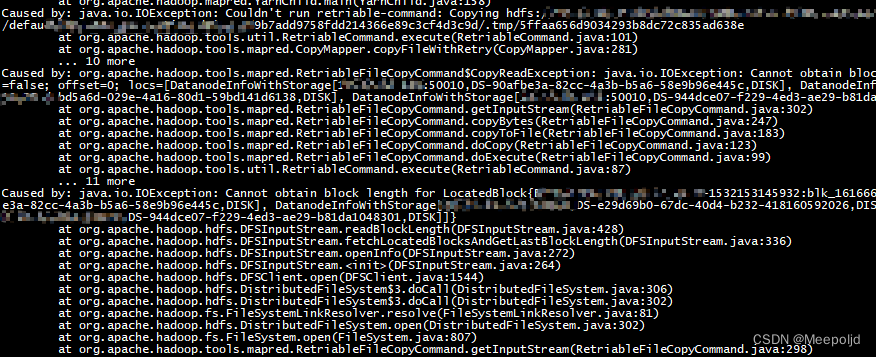
第一个反映是块有问题,然后就去hbck了一下,结果是正常:

这下整蒙了,然后我本地get了一下,文件就是拿不下来。尬了,经过查阅资料,看到一个博客说了这个问题:参考博文
这次检查出来不少文件打印显示都是 openforwrite状态,而且Status为CORRUPT。经测试发现,这些文件无法get和cat。所以这里的” Cannot obtain block length for LocatedBlock “结合字面意思讲应该是当前有文件处于写入状态尚未关闭,无法与对应的datanode通信来成功标识其block长度。
于是我也尝试使用openforwrite检查,发现确实对应的块是CORRUPT状态:
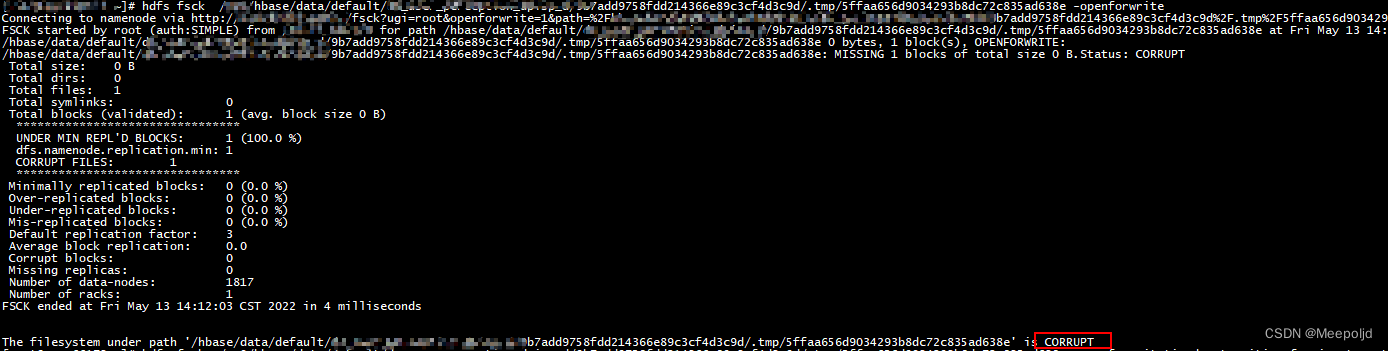
于是我直接对待拷贝数据的全目录再进行了一次扫描,对于异常数据直接delete:
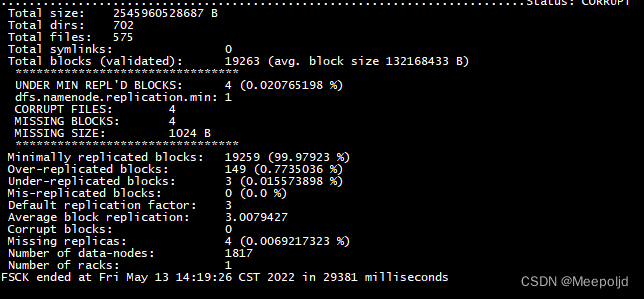
处理以后再次进行同步旧不会报错了:
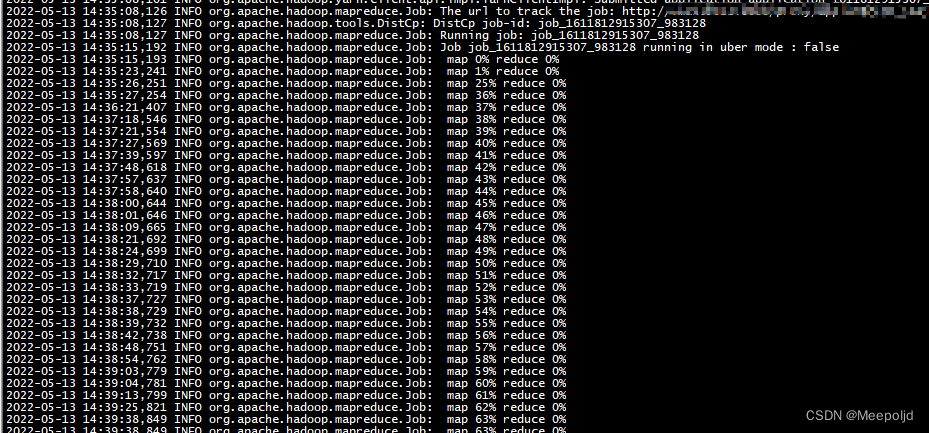
数据删除是敏感操作,笔者是因为集群数据本身异常不能提供服务,经过沟通确认后以最快保证业务恢复为目的而进行的删除操作,作为运维人员一定要对数据安全保有敬畏之心!
; Distcp调优
使用Distcp过程中,遇到数据同步比较慢的情况,尝试了一些参数,直观感受是提高了同步速度,记录一下:
- 增加map数,-m 100,默认会使用20个map,在数据量较大的时候,提速效果明显;
- -Dmapreduce.map.memory.mb=4096 增加map的容器内存,默认是1024M;
- -Dmapreduce.reduce.memory.mb=4096 增加reduce的容器内存,默认是1024M;
最终使用命令:
hadoop distcp -Dmapreduce.map.memory.mb=4096 -Dmapreduce.reduce.memory.mb=4096 -m 100 hdfs://10.1.1.1:9000/hbase/data/default/tablename /hbase/data/default/
Original: https://www.cnblogs.com/Meepoljd/p/16625239.html
Author: 风灵动铭
Title: 【HBASE】记一次HBase进行数据迁移,重建元数据
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/601910/
转载文章受原作者版权保护。转载请注明原作者出处!