

之前的文章中都是给大家写的变量间线性关系的做法,包括回归和广义线性回归,变量间的非线性关系其实是很常见的,今天给大家写写如何拟合论文中常见的非线性关系。包括多项式回归 Polynomial regression和样条回归 Spline regression。
多项式回归
首先看一个二次项拟合的例子,我现在想探讨苹果内容物apple content和苹果酸度cider acidity的关系,第一步应该是做出apple content和cider acidity关系的散点图,假如是下图:
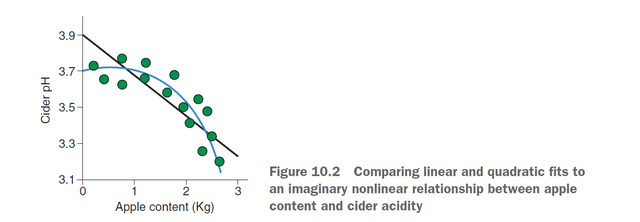

那么我很直观地可以看出来,曲线(二次)对数据的拟合明显是好于线性拟合的。
上面的只是一个2次项拟合的例子,我们其实经常会遇到有可能高次式会把数据拟合的更好,社科论文中其实也常常见到做高次回归的,常见的1次,2次,3次,4次项英文论文中的表达,曲线形状如下:

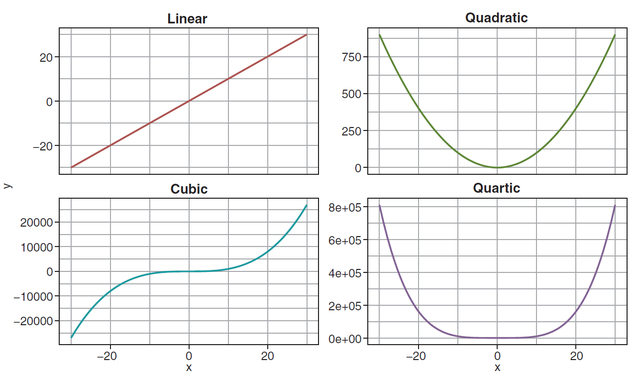
拟合出来的一般模型表达式如下:
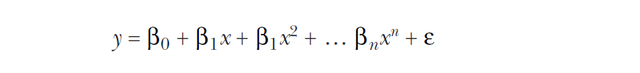
而且通常情况下,模型中所有的低次项都不应该被略去。就是我有了4次项,那么应该3,2,1次项都应该有。
含有二次及以上的模型就叫多项式回归模型。
样条回归
之前在机器学习的文章中有给大家写过拟合,我们做多次项拟合的时候,按道理你可以将项的次数调得很高,总是可以近乎完美的拟合我们的复杂的非线性关系, 但是问题就是外推性就没有了,这也并不是我们想看到的结果:
High-degree polynomials allow us to capture complicated nonlinear relationships in the data but are therefore more likely to overfit the training set.
还有就是自变量和因变量之间的关系在自变量的不同取值范围也并非不变的,比如某个区间是线性的,某个区间是2次曲线,某个区间又成了3次曲线。
上面两个问题处理方法之一就是 样条splines
所谓样条就是成片段的多次式,一个曲线分多段拟合,段与段之间的分割点叫做结knots
A spline is a piecewise polynomial function. This means it splits the predictor variable into regions and fits a separate polynomial within each region, which regions connect to each other via knots.
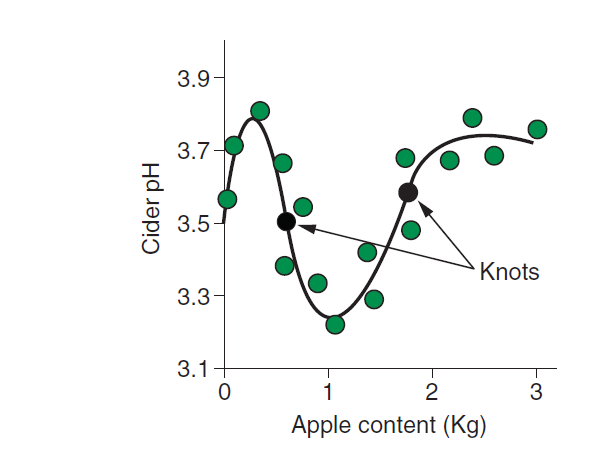
上图便是用两个结将我们的曲线分成了3个样条。
通过对关系曲线的划分,我们可以尽可能达到 既拟合的好,又好解释的目的。
我们在论文中还会有看到说 限制性立方样条(restricted cubic splines),这个又是个啥呢?
就是我们正常做样条,有可能做出来就是这样的:虽然分段但是不连贯:
这样的情况下结点处,不连贯的地方解释起来就会很困难了嘛。
所以,我们更加期望能够得到一个平滑的曲线(增加可解释性),而且首尾都应该是线性的,从而保证预测准确性(减少过拟合的影响),像这样:

为了得到这么样的效果我们就会给样条加上限制,所以叫做限制性立方样条:
restrictions need to be imposed so that the spline is continuous (i.e., there is no gap in the spline curve) and “smooth” at each knot。A restricted cubic spline has the additional property that the curve is linear before the first knot and after the last knot.
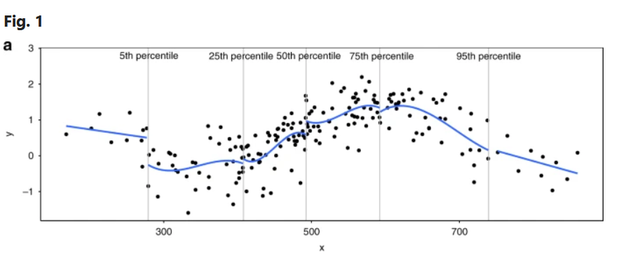
样条数量的确定和结位置的选择也是有讲究的, 结的个数可以自己定,但是一般不超过5个;结的位置需要尽可能在拐弯的地方:
The number of knots used in the spline is determined by the user, but in practice we have found that generally five or fewer knots are sufficient. The location of the knots also needs to be specified by the user, but it is common that the knot with the smallest value is relatively close to the smallest value of the variable being modelled (e.g., the 5th percentile), while the largest knot is in the neighbourhood of the largest value of the variable being modelled (e.g., the 95th percentile).
广义可加模型
上面写的内容,无论是直接拟合,还是分段拟合,我们都是在拟合一个完整的曲线或直线方程,广义可加模型则是将自变量的单独模型相加,下图式子即为一般线性模型和可加模型:

我们看下图,下图中对于x和y关系的拟合是通过x的3个基础函数相加得到的:
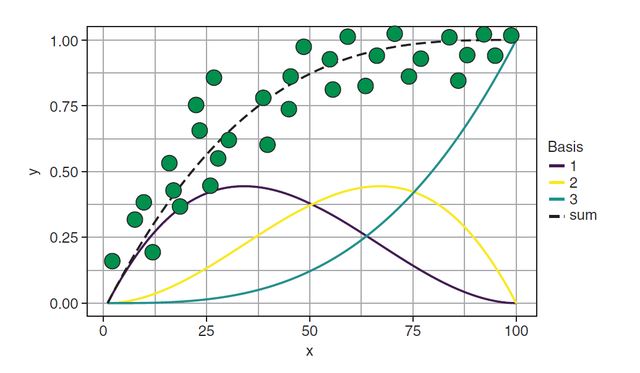
GAMs automatically learn a nonlinear relationship between each predictor variable and the outcome variable, and then add these effects together linearly, along with the intercept.
就是说广义可加的原理就是, 先弄几个好解释的基础函数,这个基础函数可以是一次的,也可以是多次的,然后再将这些基础函数进行线性组合,从而达到更好地拟合数据的目的。
通过广义可加模型可以同时实现模型的可解释性Interpretability,灵活性flexibility和正则化regularization。
怎么理解呢,我们先看可解释性,假如一个可加模型是如下形式的基础函数相加得到的:

x2的作用我们就可以解释为在其它变量不变的情况下,x2和结局之间的关系是线性的,xp对左边的结局在某个点之前也基本是线性增加的,然乎某个点之后xp对结局就无影响了,这个就是将模型相加后才可能实现的解释性。
灵活性在于,可加模型可以将所有自变量单独建模后相加,我们甚至不需要提前知道xy的关系,完全由数据说话的非参数形式,就比整体的多项式和样条更灵活。
正则化则可以避免过拟合,可加模型是有一个超参 _λ_的,这个超参决定了曲线的歪扭程度,英文叫做wiggliness,通过对超参的控制就可以很方便地实现方差偏差折中,见下图:
The level of smoothness is determined by the smoothing parameter, which we denote by λ. The higher the value of λ, the smoother the curve

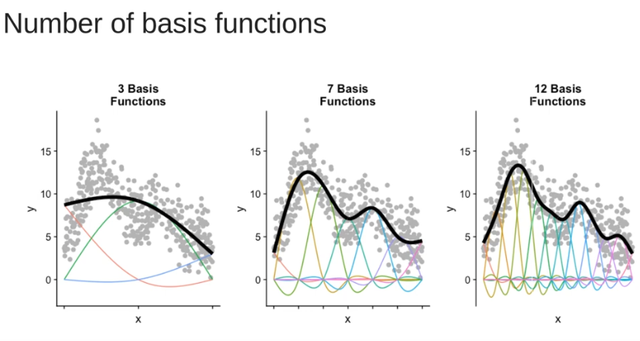
当然还有一个问题就是我到底该用多少个基础函数呢?基础函数越多模型就可以越灵活。见下图,这个大家在具体操作的时候也是可以自己设定的:
实例操练
我现在手上有如下数据

我想探究medv和lstat之间的关系,先做个图:
ggplot(train.data, aes(lstat, medv) ) +
geom_point() +
stat_smooth()
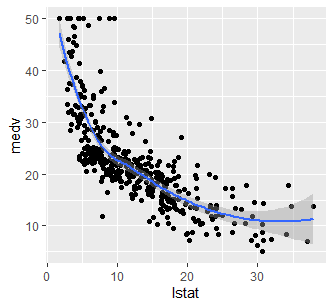
可以看到这两个变量间是非常明显的非线性关系,此时我们需要考虑给自变量加上多次项拟合。
在R语言中我们可以使用 I()来加上变量的高次项,比如我要加二次项,我就可以写出 I(x^2)
lm(medv ~ lstat + I(lstat^2), data = train.data)
模型结果如下:
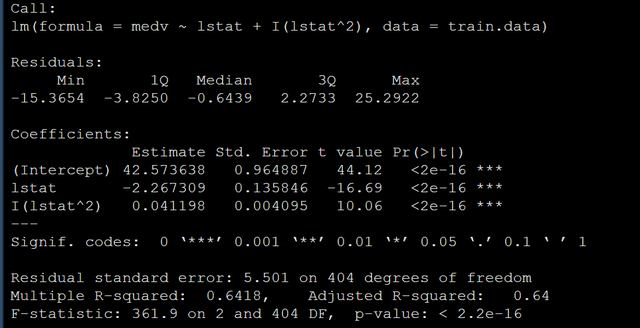
上面就是多次项回归的做法,接下来给大家写写如何做样条回归
刚刚有写我们做样条的时候是需要设定结的,比如我就设定自变量的第25,50,75百分位为结:
knots <- quantile(train.data$lstat, p="c(0.25," 0.5, 0.75))< code></->
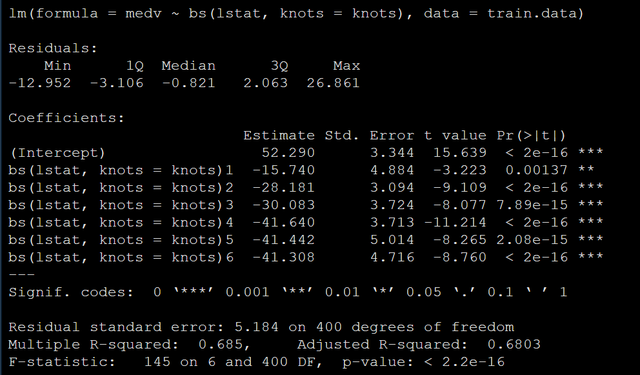
做一个立方样条回归( 默认就是做立方样条),代码如下:
model <- lm (medv ~ bs(lstat, knots="knots)," data="train.data)</code"></->
模型输出结果如下:
我们接着看广义可加模型的R语言做法,我手上有数据如下:
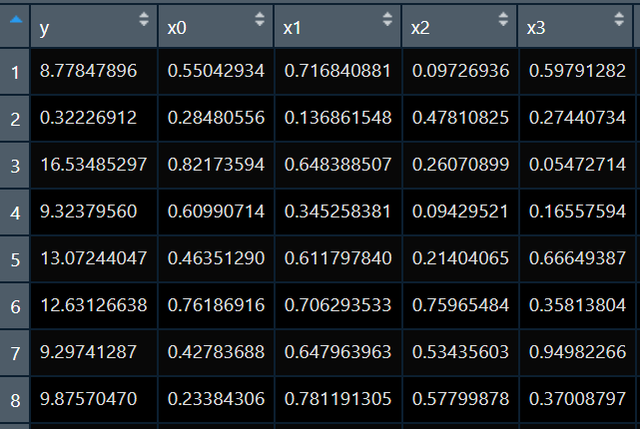
我现在想弄明白x3与y的关系,但是假如我现在已经知道,x1和x2与y的关系为非线性的,我们是不是要把这个非线性关系控制掉来看我们x3和y的关系呀。所以我们跑一个可加模型来瞅瞅:
b1 <- gam(y ~ s(x1, bs="ps" , sp="0.6)" + s(x2, x3, data="dat)" summary(b1)< code></->
上面的代码中bs设定平滑方法,sp设定λ。
运行上面的代码后得到结果如下:
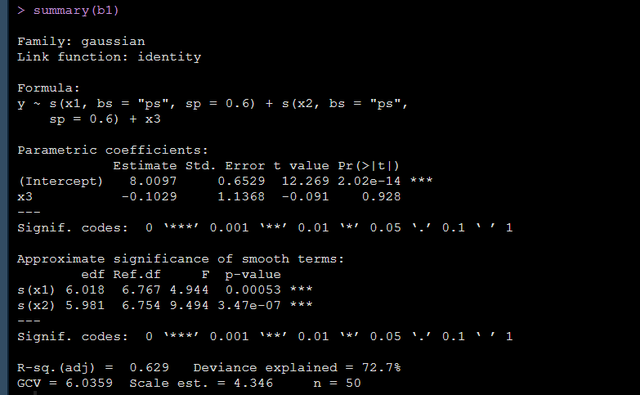
就是说在控制了x1和x2的曲线效应后,我们x3对y其实是没有影响的。
小结
今天给大家写了多项式回归,样条回归和可加模型,希望能给到大家以启发,感谢大家耐心看完,自己的文章都写的很细,重要代码都在原文中,希望大家都可以自己做一做,请转发本文到朋友圈后私信回复”数据链接”获取所有数据和本人收集的学习资料。如果对您有用请先记得收藏,再点赞分享。
也欢迎大家的意见和建议,大家想了解什么统计方法都可以在文章下留言,说不定我看见了就会给你写教程哦,有疑问欢迎私信。
Original: https://blog.csdn.net/tm_ggplot2/article/details/121878789
Author: 公众号Codewar原创作者
Title: R数据分析:变量间的非线性关系,多项式,样条回归和可加模型
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/601488/
转载文章受原作者版权保护。转载请注明原作者出处!