

2021.11.8
【小旭学长-使用python进行城市数据分析】说明篇(开篇 )https://blog.csdn.net/wistonty11/article/details/121347825
【小旭学长-使用python进行城市数据分析】笔记篇(上):https://blog.csdn.net/wistonty11/article/details/121089882
【小旭学长-使用python进行城市数据分析】笔记篇(中):https://blog.csdn.net/wistonty11/article/details/121210664
【小旭学长-使用python进行城市数据分析】笔记篇(下):https://blog.csdn.net/wistonty11/article/details/121308188
文章目录
- 三. Pandas数据处理基础
- 3.1 数据的编码和储存格式
- 3.2 数据表的行列处理
* - 3.2.1 读操作
- 3.2.2 存储
- 3.2.3 写入数据三种形式
- 3.2.4 基本操作
– - 3.3 合并 连接 聚合统计 遍历
*
– - 3.4 练习
* - 3.4.1 表基本操作
- 3.4.2 字符串处理
- 3.4.3 坐标处理
- 四. Pandas 数据处理进阶
- 4.1 Pandas数据处理的起个重要技巧
* - 4.1.1 分组编号
- 4.1.2 去重处理
- 4.1.3 重新编号
- 4.1.4 生成两两之间的表(某时刻)
- 4.1.5 对某一时刻生成两两之间的对应表
- 4.1.6 遍历每一行
- 2.1.7 插值和时空差值
- 4.2 复杂数据处理任务的解决思路
* - 4.2.1 双向的线路只保留单向
- 4.2.2 将站点字符串变为list
- 4.2.3 获取站点对,并标注是否有重复
- 4.2.4 计算全部的站点对数量和重复的站点对数量
三. Pandas数据处理基础
3.1 数据的编码和储存格式
- Pandas中默认读取文件的编码格式为UTF-8,否则会出现乱码
【 CSV】
- CSV是一种纯文本格式,EXCEL和Python都对其支持
- CSV数据中的字段,记录均为
英文逗号,隔开 - CSV每一条记录 都有相同数量的字段

- TSV与CSV区别是:TSV使用制表符(tab,\t)分割数据值
【 json】
- json由数值,字符串,列表,字典等等数据类型资有嵌套在一起构成
{"a":1, "b":[1, 2, 3]}
[1,2,"3", {"a" : 4}]
3.14
- json可以保存成.json后缀的文件,它是一纯文本格式,可以用txt打开
data = {"a":1, "b":[1, 2, 3]}
import json
f = open("data.json",mode = "w")
json.dump(data, f)
f.close()
f = open("data.json",mode = "r")
data1 = json.load(f)
f.close()
data1
【 pickle文件】
- pickle能够将ptrhon中的对象,变量都以本地文件袋形式存储,后缀.pkl
- pickle文件非文本,将文件用于编辑器打开则是乱码,不同python版本打开pickle可能会报错
- 读写效率比CSV文件高
data = {"a":1, "b":[1, 2, 3]}
import pickle
f = open("data.pkl",mode = "wb")
pickle.dump(data, f)
f.close()
f = open("data.pkl",mode = "rb")
data2 = pickle.load(f)
f.close()
data2
3.2 数据表的行列处理
3.2.1 读操作
用 sep=“符号”来切割字符
import pandas as pd
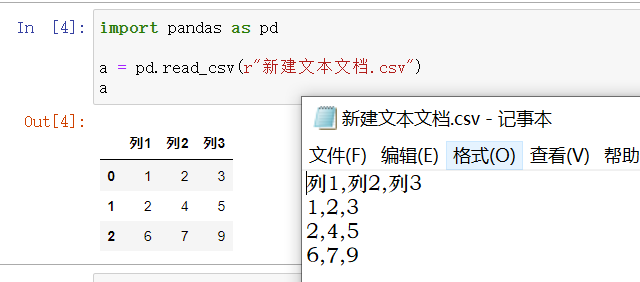
a = pd.read_csv(r"新建文本文档.csv" )
a
列1列2列3012312452679
a1 = pd.read_csv(r"新建文本文档.csv", sep=",")
a1
- 效果一样,因为本身CSV就是以
,切割数据的
【tsv】:以 Tab切割数据
b = pd.read_csv("新建文本文档_1.tsv")
b
列1\t列2\t列301\t2\t312\t4\t526\t7\t9
【tsv】
b1 = pd.read_csv("新建文本文档_1.tsv", sep = "\t")
b1
列1列2列3012312452679
3.2.2 存储
index = None 不存储行号
b1.to_csv(r'新建文本文档_1.csv',index = None,encoding = 'utf-8_sig')
pd.read_csv(r'新建文本文档_1.csv')
列1列2列3012312452679
- 默认存行号
b1.to_csv(r'新建文本文档_2.csv',encoding = 'utf-8_sig')
pd.read_csv(r'新建文本文档_2.csv')
Unnamed: 0列1列2列3001231124522679
【Excel和pickle】
pd.read_excel(r'untitled_1.xlsx')
pd.read_pickle
data.to_pickle
3.2.3 写入数据三种形式
① 方式一:双层list
data = pd.DataFrame([['aa',1],
['bb',2],
['cc',3]])
data.columns = ['name','type']
data
data = pd.DataFrame([['aa',1],
['bb',2],
['cc',3]],columns = ["name","type"])
nametype0aa11bb22cc3
② 方式二:一个list中包含多个字典
pd.DataFrame([{'name':'aa','type':1},
{'name':'bb','type':2},
{'name':'cc','type':3}])
nametype0aa11bb22cc3
- 方式2 如果有个列名不同,空的用NaN补齐
pd.DataFrame([{'name':'aa','type':1},
{'name1':'bb','type':2},
{'name':'cc','type':3}])
nametypename10aa1NaN1NaN2bb2cc3NaN
③ 方式三:一个字典,键值对中的值为list
pd.DataFrame({'name':['aa','bb','cc'],'type':[1,2,3]})
nametype0aa11bb22cc3
【总结】 DataFrame()是个函数,要么双中括号,先给数据再给列名;要么输入一个中括号list,;里面是键值对字典;或者是给个字典,一个键对应多个数据值;
3.2.4 基本操作
3.2.4.1 查看行列名
data.columns
Index(['name', 'type'], dtype='object')
list(data.index)
[0, 1, 2]
3.2.4.2 改变行列名
data.columns=["a",22]
data
a220aa11bb22cc3
data.reset_index()
indexa2200aa111bb222cc3
drop = True重新算行号
data.reset_index(drop = True)
a220aa11bb22cc3
3.2.4.3 以列名读取数据
- 已列名读取数据时,
[ ]读取的是series格式,[[ ]]读取的DataFrame格式
data["a"]
0 aa
1 bb
2 cc
Name: a, dtype: object
data[["a"]]
a0aa1bb2cc
- 取出多列 双中括号
data[["a",22]]
a220aa11bb22cc3
- 可以取出 重复的列
data[["a",'a']]
aa0aaaa1bbbb2cccc
3.2.4.4 取行
- 取行
.loc用行名取.iloc以行数取
data.index = ["a","b","c"]
data
a22aaa1bbb2ccc3
data.iloc[1]
a bb
22 2
Name: b, dtype: object
data.loc["b"]
a bb
22 2
Name: b, dtype: object
- 用
iloc和loc取出的都是series类 - *取某几行,用切片
data.iloc[0:2]
a22aaa1bbb2
3.2.4.5 输出某一个值
data["a"].iloc[2]
或者
data.iloc[2]["a"]
'cc'
3.2.4.6 支持列运算,支持运算符
data[22] = data[22]*2
data
a22aaa4bbb8ccc12
data[22] = data[22]>7
data
a22aaaFalsebbbTruecccTrue
data[data[22]==True]
a22bbbTruecccTrue
- 反向运算符
data[-data[22]==True]
a22aaaFalse
- *行和列都满足的条件 前面是行
data.loc[-data[22]==True,"a"]
a aa
Name: a, dtype: object
data.loc[-data[22]==True,"a"]=2
data
a22a2FalsebbbTruecccTrue
- 用
astype()转换类型
type(data["a"].loc['a'])
int
type(data["a"].astype(str).loc['a'])
str
3.3 合并 连接 聚合统计 遍历
import pandas as pd
data1 = pd.DataFrame([["aa", 1],
["bb", 2],
["cc", 3]],columns=["name", "type"])
data1
nametype0aa11bb22cc3
data2 = pd.DataFrame([["dd", 1],
["ee", 2],
["ff", 3]])
data2.columns=["name", "type"]
data2
nametype0dd11ee22ff3
3.3.1 合并(concat 和 append)
- 合并
concat ()方法合并
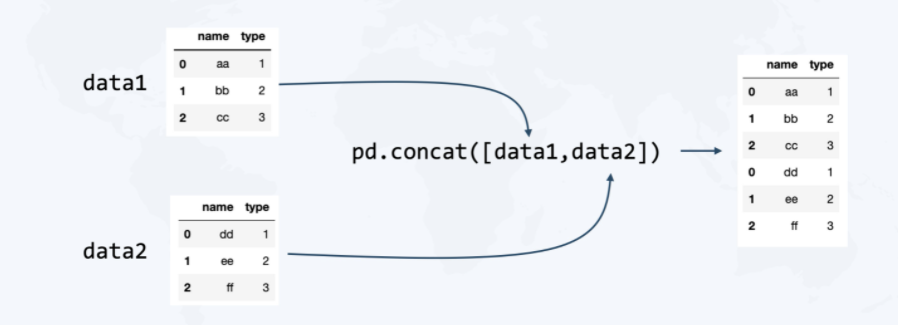
pd.concat([data1, data2])
nametype0aa11bb22cc30dd11ee22ff3
名字相同的接在一起,没有的用NaN
data3 = pd.DataFrame([["dd", 1],
["ee", 2],
["ff", 3]])
data3.columns=["name1", "type"]
data4 = pd.concat([data1, data3])
data4
nametypename10aa1NaN1bb2NaN2cc3NaN0NaN1dd1NaN2ee2NaN3ff
- 用
.append()方法合并
如果是data1 非常大 data2小,那么用append方法会省时
data1.append(data2)
nametype0aa11bb22cc30dd11ee22ff3
- *取某行数据用切片,因为只是某一行,那么类型是series.
data4.iloc[0:1]
nametypename10aa1NaN
data4.iloc[0]
name aa
type 1
name1 NaN
Name: 0, dtype: object
results = []
for i in range(len(data4)):
result = data4.iloc[i:i+1]
results.append(result)
pd.concat(results)
nametypename10aa1NaN1bb2NaN2cc3NaN0NaN1dd1NaN2ee2NaN3ff
results = pd.DataFrame()
for i in range(len(data4)):
result = data4.iloc[i:i+1]
results = results.append(result)
results
nametypename10aa1NaN1bb2NaN2cc3NaN0NaN1dd1NaN2ee2NaN3ff
data5=data4.reset_index(drop = True)
data5
nametypename10aa1NaN1bb2NaN2cc3NaN3NaN1dd4NaN2ee5NaN3ff
3.3.2 表的连接(merge)

用 pd.merge()连接表,用 how来确定连接方式, on确定以什么为标准连接
pd.merge(data1,data5,on="name")
nametype_xtype_yname10aa11NaN1bb22NaN2cc33NaN
pd.merge(data1,data5,on="name", how= "outer")
nametype_xtype_yname10aa1.01NaN1bb2.02NaN2cc3.03NaN3NaNNaN1dd4NaNNaN2ee5NaNNaN3ff
pd.merge(data1,data5,on="name", how= "left")
nametype_xtype_yname10aa11NaN1bb22NaN2cc33NaN
data6 = pd.merge(data1,data5,on="name", how= "right")
data6
nametype_xtype_yname10aa1.01NaN1bb2.02NaN2cc3.03NaN3NaNNaN1dd4NaNNaN2ee5NaNNaN3ff
- 用
.isnull()查空值对象
data6[data6["name"].isnull()]
nametype_xtype_yname13NaNNaN1dd4NaNNaN2ee5NaNNaN3ff
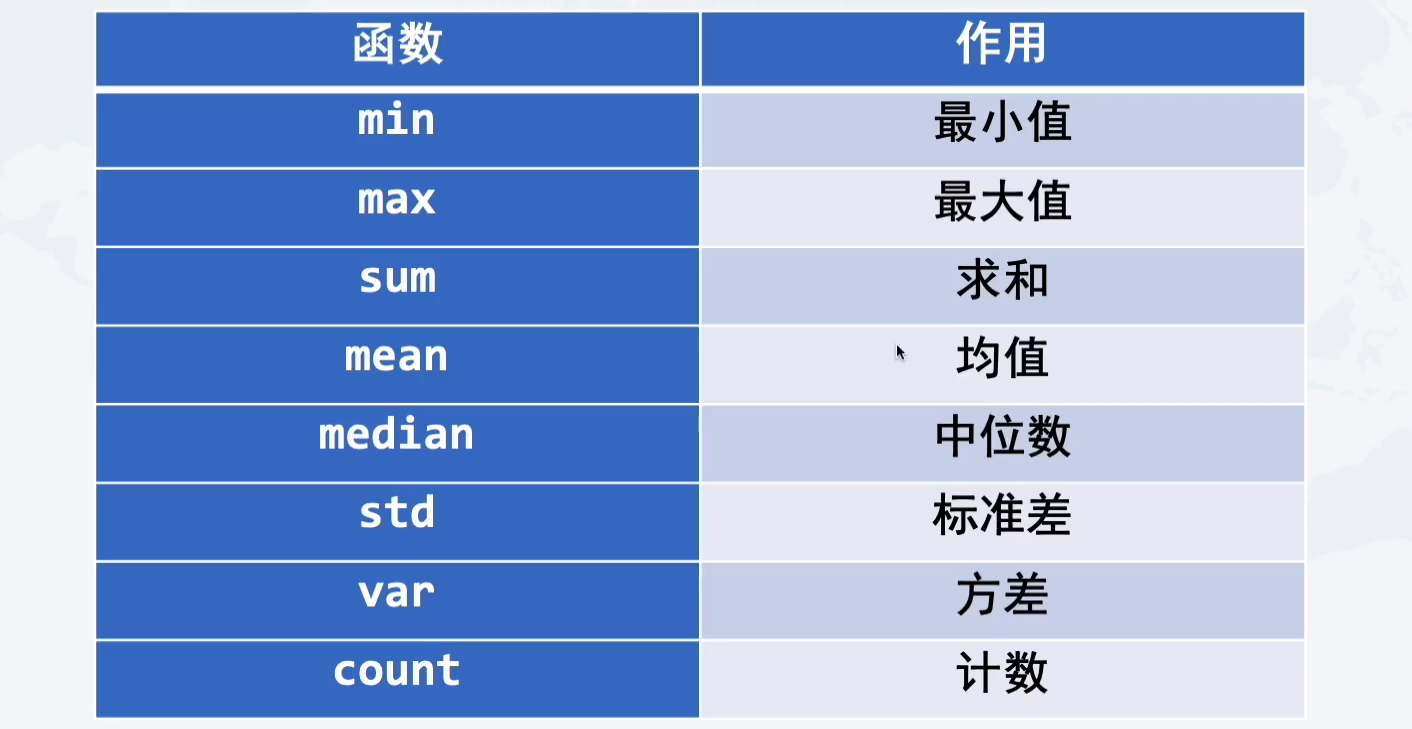
3.3.3 数据表的聚合操作(集计)
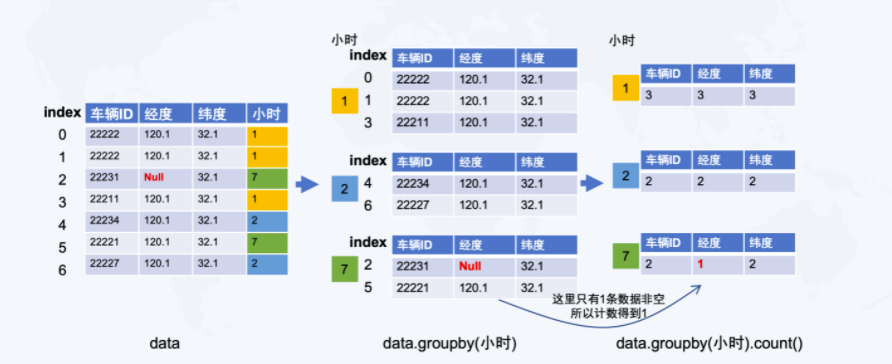
data7 = pd.DataFrame([{'车辆ID':'22222','经度':120.1,'纬度':32.1,'小时':1},
{'车辆ID':'22222','经度':120.1,'纬度':32.1,'小时':1},
{'车辆ID':'22231','经度':None,'纬度':32.1,'小时':7},
{'车辆ID':'22211','经度':120.1,'纬度':32.1,'小时':1},
{'车辆ID':'22234','经度':120.1,'纬度':32.1,'小时':2},
{'车辆ID':'22221','经度':120.1,'纬度':32.1,'小时':7},
{'车辆ID':'22227','经度':120.1,'纬度':32.1,'小时':2},
])
data7
车辆ID经度纬度小时022222120.132.11122222120.132.11222231NaN32.17322211120.132.11422234120.132.12522221120.132.17622227120.132.12
- 根据发生时间用
.groupby()归类 ,但此对象不显示 - .groupby(‘小时’).count()进行统计
data7.groupby('小时')
data7.groupby('小时').count()
车辆ID经度纬度小时133322227212
data7.groupby('小时')["车辆ID"].count()
小时
1 3
2 2
7 2
Name: 车辆ID, dtype: int64
data7.groupby('小时')["车辆ID"].count().reset_index()
小时车辆ID013122272
data7.groupby('小时')["车辆ID"].count().rename("每小时车辆数").reset_index()
小时每小时车辆数013122272
- 按小时聚合,取出名字”车辆ID”列,对这列进行重命名,对列表进行重排列
3.3.4 表的遍历
用 apply()表的遍历
- 用
apply(,axis = 1)行遍历
data7
车辆ID经度纬度小时022222120.132.11122222120.132.11222231NaN32.17322211120.132.11422234120.132.12522221120.132.17622227120.132.12
r = data7.iloc[0]
r
车辆ID 22222
经度 120.1
纬度 32.1
小时 1
Name: 0, dtype: object
def f(r):
d = r['经度']*r["纬度"]
d = d-r['小时']
return d
f(r)
3854.21
data7.apply(f,axis = 1)
0 3854.21
1 3854.21
2 NaN
3 3854.21
4 3853.21
5 3848.21
6 3853.21
dtype: float64
- 赋值操作将生成的值成新的列
data7["值"]=data7.apply(f,axis = 1)
data7
车辆ID经度纬度小时值022222120.132.113854.21122222120.132.113854.21222231NaN32.17NaN322211120.132.113854.21422234120.132.123853.21522221120.132.173848.21622227120.132.123853.21
data7['值']= data7.apply(lambda r:r['经度']*r['纬度']-r['小时'], axis = 1)
data7
车辆ID经度纬度小时值022222120.132.113854.21122222120.132.113854.21222231NaN32.17NaN322211120.132.113854.21422234120.132.123853.21522221120.132.173848.21622227120.132.123853.21
data7['值']= data7['小时'].apply(lambda r:r*2)
data7
车辆ID经度纬度小时值022222120.132.112122222120.132.112222231NaN32.1714322211120.132.112422234120.132.124522221120.132.1714622227120.132.124
3.4 练习
3.4.1 表基本操作
- 生成一个表,包括一列,内容是从0~100的数字
data11 = pd.DataFrame(range(101))
data11
- 在上表中保留奇数
data11[data11[0] %2 ==1]
01137373939414143434545474749495151535355555757595961616363656567676969717173737575777779798181838385858787898991919393959597979999
- 生成一个表,里面的内容是连续150行星号(*),每一行星号的数量依次递增
result = []
for i in range(150):
result.append('*'*(i+1))
results = pd.DataFrame(result)
results
001234……145******…146******…147******…148******…149*******…
150 rows × 1 columns
3.4.2 字符串处理
- 生成一个数据表,里面内容是将下面整个字符串的每个单词为一行,且列名为word
c = 'I could still see the airport buildings far below'
data_c = pd.DataFrame(c.split(" "), columns = ['word'])
data_c
word0I1could2still3see4the5airport6buildings7far8below
- 将上面的表按照首字母排序(排序可以用sort_values函数),并在排序后剔除表的最后一行
data_c2 = data_c.sort_values(by = "word")
data_c2 = data_c2.iloc[:-1]
data_c2
word0I5airport8below6buildings1could7far3see2still
- 大写字母Acsii码在小写前面
3.4.3 坐标处理
- *① 下面的一串字符串是一个坐标:d = ‘124.456704,51.360794’,请把它变为一个两列的表,一列存储x坐标,列名为lon,一列存储y坐标,列名为lat
d = '124.456704,51.360794'
data_d = d.split(',')
data_d
['124.456704', '51.360794']
data_d1 = pd.DataFrame([{"lon" : data_d[0], "lat" : data_d[1]}])
data_d1
lonlat0124.45670451.360794
- ② 请把它变为一个两列的表,一列存储x坐标,列名为lon,一列存储y坐标,列名为lat
- 数据d2:每个坐标点用;分割,坐标内又同时包含x和y坐标,以逗号分割。
d2 ='data_test:124.456704,51.360794;124.470579,51.360967;124.477988,51.362294;124.482691,51.366009;124.490196,51.380395;124.500132,51.381395;124.502327,51.381232;124.516331,51.379176;124.526475,51.374428;124.540962,51.373421;124.555744,51.375379;124.567144,51.372207;124.574999,51.370307;124.587184,51.363671;124.595319,51.356729;124.600498,51.34944;124.604882,51.345385;124.606956,51.343215;124.612089,51.339088;124.624557,51.328643;124.626609,51.327512;124.635593,51.326618;124.638012,51.32798;124.642859,51.331108;124.648612,51.332627;124.669118,51.333266;124.689629,51.332398;124.69347,51.332709;124.713271,51.340195;124.717057,51.340791;124.721704,51.343376;124.729691,51.346302_ok'
d3 = d2.lstrip('data_test:').rstrip('_ok').split(';')
results = []
for point in d3:
x = point.split(',')[0]
y = point.split(',')[1]
results.append([float(x),float(y)])
results
data_d3 = pd.DataFrame(results,columns = ['lon','lat'])
data_d3
lonlat0124.45670451.3607941124.47057951.3609672124.47798851.3622943124.48269151.3660094124.49019651.3803955124.50013251.3813956124.50232751.3812327124.51633151.3791768124.52647551.3744289124.54096251.37342110124.55574451.37537911124.56714451.37220712124.57499951.37030713124.58718451.36367114124.59531951.35672915124.60049851.34944016124.60488251.34538517124.60695651.34321518124.61208951.33908819124.62455751.32864320124.62660951.32751221124.63559351.32661822124.63801251.32798023124.64285951.33110824124.64861251.33262725124.66911851.33326626124.68962951.33239827124.69347051.33270928124.71327151.34019529124.71705751.34079130124.72170451.34337631124.72969151.346302
- *③ 提取出下表中”经度”为空值的行
import pandas as pd
data_e = pd.DataFrame([{'车辆ID':'22222','经度':120.1,'纬度':32.1,'小时':1},
{'车辆ID':'22222','经度':122.1,'纬度':32.1,'小时':1},
{'车辆ID':'22231','经度':None,'纬度':32.6,'小时':7},
{'车辆ID':'22211','经度':121.5,'纬度':32.2,'小时':1},
{'车辆ID':'22234','经度':121.4,'纬度':32.5,'小时':2},
{'车辆ID':'22221','经度':123.3,'纬度':32.2,'小时':7},
{'车辆ID':'22227','经度':124.6,'纬度':31.1,'小时':2},
])
data_e
车辆ID经度纬度小时022222120.132.11122222122.132.11222231NaN32.67322211121.532.21422234121.432.52522221123.332.27622227124.631.12
data_e[data_e["经度"].isnull()]
车辆ID经度纬度小时222231NaN32.67
- *④ 提取出上面data表中,”车辆ID”在下面list中的行
e = ['22222','22231','22211','22221','22213']
data_e[data_e['车辆ID'].apply(lambda r:str(r) in e)]
车辆ID经度纬度小时022222120.132.11122222122.132.11222231NaN32.67322211121.532.21522221123.332.27
- *提取出上面data表中,”车辆ID” 不在 上面list中的行
data_e[-data_e['车辆ID'].apply(lambda r:str(r) in e)]
车辆ID经度纬度小时422234121.432.52622227124.631.12
- *⑤ 让data表中,车辆ID为22222的记录的小时字段的数值都+1
data_e
车辆ID经度纬度小时022222120.132.11122222122.132.11222231NaN32.67322211121.532.21422234121.432.52522221123.332.27622227124.631.12
data_e.loc[data_e['车辆ID']=='22222','小时'] += 1
data_e
有了加一和赋值操作
车辆ID经度纬度小时022222120.132.12122222122.132.12222231NaN32.67322211121.532.21422234121.432.52522221123.332.27622227124.631.12
- *⑥ 求出上面data表中,小时列的平均值
data_e['小时'].mean()
3.2857142857142856
- *⑦ 求出小时为2时的所有车的ID,要求结果是DataFrame,每个车ID为一行
data_e[data_e['小时']==2][['车辆ID']].drop_duplicates()
车辆ID022222422234622227
单引号取出的是series, 两层中括号取出的是字表 类型DataFrame,所以用了[[‘车辆ID’]]
求出每小时经度纬度数值差异的最大值,要求结果为DataFrame,包含两列分别为:小时,差异最大值
data1_e = data_e.copy()
data1_e['差异'] = abs(data1_e['经度']-data1_e['纬度'])
data1_e.groupby(['小时'])['差异'].max().reset_index()
小时差异0189.31293.52791.1
data_e.columns = ['车辆ID','lon','lat','小时']
data_e = data_e.rename(columns = {'经度':'lon','纬度':'lat'})
data_e
车辆IDlonlat小时022222120.132.12122222122.132.12222231NaN32.67322211121.532.21422234121.432.52522221123.332.27622227124.631.12
- *⑧ 对data按照小时、车辆ID两列的顺序排序,然后取出前3行
data_e = data_e.sort_values(by = ['小时', '车辆ID'])
data_e.iloc[:3]
车辆IDlonlat小时322211121.532.21022222120.132.12122222122.132.12
- *⑨ 对data的车辆ID列,每一个车辆ID只保留最后的3位
data1_e["车辆ID"] = data1_e["车辆ID"].apply(lambda r:r[-3:])
data1_e
车辆ID经度纬度小时差异0222120.132.1288.01222122.132.1290.02231NaN32.67NaN3211121.532.2189.34234121.432.5288.95221123.332.2791.16227124.631.1293.5
– ⑩ 对data增加一列type:
如果车辆ID的最后一位小于3且小时为1,则type为 公交车
如果车辆ID大于等于3,则type为 小汽车
其余情况则为 出租车
- 要求:
用apply方法遍历,loc方法条件修改
两种方式实现
data1_e['type'] = '出租车'
data1_e.loc[(data1_e['车辆ID'].apply(lambda r:int(r[-1]) <3))&(data1_e['小时']==1),'type'] = '公交车'
data1_e.loc[(data1_e['车辆ID'].apply(lambda r:int(r[-1]) >=3)),'type'] = '小汽车'
data1_e
车辆ID经度纬度小时差异type0222120.132.1288.0出租车1222122.132.1290.0出租车2231NaN32.67NaN出租车3211121.532.2189.3公交车4234121.432.5288.9小汽车5221123.332.2791.1出租车6227124.631.1293.5小汽车
def f(r):
if (int(r['车辆ID'][-1]) <3)&(r['小时']==1):
return '公交车'
elif (int(r['车辆ID'][-1]) >=3):
return '小汽车'
else:
return '出租车'
data1_e['type'] = data1_e.apply(lambda r:f(r),axis = 1)
data1_e
车辆ID经度纬度小时差异type0222120.132.1288.0出租车1222122.132.1290.0出租车2231NaN32.67NaN出租车3211121.532.2189.3公交车4234121.432.5288.9小汽车5221123.332.2791.1出租车6227124.631.1293.5小汽车
四. Pandas 数据处理进阶
4.1 Pandas数据处理的起个重要技巧
4.1.1 分组编号
import pandas as pd
testdata = pd.DataFrame([['A','8:00',120.7,30.8],
['A','9:00',120.1,31.1],
['A','10:00',120.1,31.1],
['B','8:00',122.1,30.2],
['B','9:00',121.4,30.2],
['B','10:00',120.1,31.1],
['C','8:00',121.3,30.7],
['D','9:00',121.7,30.4],
['D','10:00',120.1,31.1],
],columns = ['ID','Time','lon','lat'])
testdata
IDTimelonlat0A8:00120.730.81A9:00120.131.12A10:00120.131.13B8:00122.130.24B9:00121.430.25B10:00120.131.16C8:00121.330.77D9:00121.730.48D10:00120.131.1
① 首先,按照我们想得到的排序顺序,生成一个可排序的列,命名为new_id
testdata['new_id'] = range(len(testdata))
testdata
IDTimelonlatnew_id0A8:00120.730.801A9:00120.131.112A10:00120.131.123B8:00122.130.234B9:00121.430.245B10:00120.131.156C8:00121.330.767D9:00121.730.478D10:00120.131.18
② 然后,对ID进行groupby后,指定对new_id这一列生成序号
testdata["new_id"] = testdata.groupby('ID')["new_id"].rank(method = 'first')
testdata
IDTimelonlatnew_id0A8:00120.730.81.01A9:00120.131.12.02A10:00120.131.13.03B8:00122.130.21.04B9:00121.430.22.05B10:00120.131.13.06C8:00121.330.71.07D9:00121.730.41.08D10:00120.131.12.0
4.1.2 去重处理
用 drop_duplicates(去副本)去重
- 出去在某时刻重复的记录
testdata_2 = pd.DataFrame([['A','8:00',1],
['A','8:00',1],
['A','9:00',2],
['B','8:00',1],
['B','8:00',2],
['B','9:00',3],
['C','8:00',4],
['D','9:00',5],
],columns = ['ID','Time','value'])
testdata_2
IDTimevalue0A8:0011A8:0012A9:0023B8:0014B8:0025B9:0036C8:0047D9:005
- 通过定义subset实现以部分列为依据的去重(同时成立去重)
testdata_2.drop_duplicates(subset = ['ID','Time'])
IDTimevalue0A8:0012A9:0023B8:0015B9:0036C8:0047D9:005
4.1.3 重新编号
testdata_3 = pd.DataFrame([['A','8:00',1],
['A','8:00',1],
['A','9:00',2],
['B','8:00',1],
['B','8:00',2],
['B','9:00',3],
['C','8:00',4],
['D','9:00',5],
],columns = ['ID','Time','value'])
testdata_3
IDTimevalue0A8:0011A8:0012A9:0023B8:0014B8:0025B9:0036C8:0047D9:005
① 先把有几类找出来
tmp = testdata_3[['ID']].drop_duplicates()
tmp
ID0A3B6C7D
② 重新安排编号
tmp['new_id'] = range(1,len(tmp)+1)
tmp
IDnew_id0A13B26C37D4
③ 用merge以ID为标准,对testdata_3进行左连接
pd.merge(testdata_3,tmp,on = "ID")
IDTimevaluenew_id0A8:00111A8:00112A9:00213B8:00124B8:00225B9:00326C8:00437D9:0054
意义就在于 有时候数字命名比汉语字符串使用起来较方便
- ID重新编号,后面再次出现视为新的ID
用 shift对前一条数据进行对比
testdata_4 = pd.DataFrame([['A','8:00',120.7,30.8],
['A','9:00',120.1,31.1],
['A','10:00',120.1,31.1],
['B','8:00',122.1,30.2],
['B','9:00',121.4,30.2],
['B','10:00',120.1,31.1],
['C','8:00',121.3,30.7],
['A','9:00',121.7,30.4],
['A','10:00',120.1,31.1],
],columns = ['ID','Time','lon','lat'])
testdata_4
IDTimelonlat0A8:00120.730.81A9:00120.131.12A10:00120.131.13B8:00122.130.24B9:00121.430.25B10:00120.131.16C8:00121.330.77A9:00121.730.48A10:00120.131.1
① 看上下两行是够ID有变化
testdata_4['new_id'] = testdata_4['ID'] != testdata_4['ID'].shift()
testdata_4
IDTimelonlatnew_id0A8:00120.730.8True1A9:00120.131.1False2A10:00120.131.1False3B8:00122.130.2True4B9:00121.430.2False5B10:00120.131.1False6C8:00121.330.7True7A9:00121.730.4True8A10:00120.131.1False
.shift为下一行
如果上下两行ID有相异,那么输出True
testdata_4['new_id'] = testdata_4['new_id'].cumsum()
testdata_4
IDTimelonlatnew_id0A8:00120.730.811A9:00120.131.112A10:00120.131.113B8:00122.130.224B9:00121.430.225B10:00120.131.126C8:00121.330.737A9:00121.730.448A10:00120.131.14
.cumsum()累加求和
4.1.4 生成两两之间的表(某时刻)
import pandas as pd
testdata_5 = pd.DataFrame([['A','8:00',120.7,30.8],
['A','9:00',120.1,31.1],
['A','10:00',120.1,31.1],
['B','8:00',122.1,30.2],
['B','9:00',121.4,30.2],
['B','10:00',120.1,31.1],
['C','8:00',121.3,30.7],
['D','9:00',121.7,30.4],
['D','10:00',120.1,31.1],
],columns = ['ID','Time','lon','lat'])
testdata_5
IDTimelonlat0A8:00120.730.81A9:00120.131.12A10:00120.131.13B8:00122.130.24B9:00121.430.25B10:00120.131.16C8:00121.330.77D9:00121.730.48D10:00120.131.1
① 对测试数据,给定时间为8点,提取出这一时刻出现的所有
tmp = testdata_5[testdata_5["Time"] == "8:00"]
tmp
IDTimelonlat0A8:00120.730.83B8:00122.130.26C8:00121.330.7
② 因为要交叉互换,所以提取这一时刻ID
tmp1 = tmp[["ID"]]
tmp1
ID0A3B6C
③ 设定临时列
tmp1["tmp"] = 1
tmp1
C:\ProgramData\Anaconda3\envs\tensorflow\lib\site-packages\ipykernel_launcher.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
"""Entry point for launching an IPython kernel.
IDtmp0A13B16C1
④ 做表的连接
tmp1 = pd.merge(tmp1, tmp1, on = "tmp")
tmp1
ID_xtmpID_y0A1A1A1B2A1C3B1A4B1B5B1C6C1A7C1B8C1C
⑤ 去重
tmp1 = tmp1[tmp1['ID_x'] > tmp1['ID_y']]
tmp1
ID_xtmpID_y3B1A6C1A7C1B
⑥ 把其他信息联到表上
tmp.columns = ['ID_x','Time_x','lon_x','lat_x']
tmp1 = pd.merge(tmp1,tmp,on = 'ID_x')
tmp.columns = ['ID_y','Time_y','lon_y','lat_y']
tmp1 = pd.merge(tmp1,tmp,on = 'ID_y')
tmp1
ID_xtmpID_yTime_xlon_xlat_xTime_ylon_ylat_y0B1A8:00122.130.28:00120.730.81C1A8:00121.330.78:00120.730.82C1B8:00121.330.78:00122.130.2
⑦ 删除多余的列,重命名列
tmp1 = tmp1.drop(['tmp','Time_y'],axis = 1).rename(columns = {'Time_x':'Time'})
tmp1
ID_xID_yTimelon_xlat_xlon_ylat_y0BA8:00122.130.2120.730.81CA8:00121.330.7120.730.82CB8:00121.330.7122.130.2
4.1.5 对某一时刻生成两两之间的对应表
我们上一问写了其中一个时刻的表
① 先看看有几个时刻
testdata_5['Time'].drop_duplicates()
0 8:00
1 9:00
2 10:00
Name: Time, dtype: object
② 我们以此做循环
ls = []
for t in testdata_5['Time'].drop_duplicates():
tmp = testdata_5[testdata_5['Time']==t]
tmp1 = tmp[['ID']]
tmp1['tmp'] = 1
tmp1 = pd.merge(tmp1,tmp1,on = ['tmp'])
tmp1 = tmp1[tmp1['ID_x'] > tmp1['ID_y']]
tmp.columns = ['ID_x','Time_x','lon_x','lat_x']
tmp1 = pd.merge(tmp1,tmp,on = 'ID_x')
tmp.columns = ['ID_y','Time_y','lon_y','lat_y']
tmp1 = pd.merge(tmp1,tmp,on = 'ID_y')
tmp1 = tmp1.drop(['tmp','Time_y'],axis = 1).rename(columns = {'Time_x':'Time'})
ls.append(tmp1)
ls
C:\ProgramData\Anaconda3\envs\tensorflow\lib\site-packages\ipykernel_launcher.py:10: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
# Remove the CWD from sys.path while we load stuff.
[ ID_x ID_y Time lon_x lat_x lon_y lat_y
0 B A 8:00 122.1 30.2 120.7 30.8
1 C A 8:00 121.3 30.7 120.7 30.8
2 C B 8:00 121.3 30.7 122.1 30.2,
ID_x ID_y Time lon_x lat_x lon_y lat_y
0 B A 9:00 121.4 30.2 120.1 31.1
1 D A 9:00 121.7 30.4 120.1 31.1
2 D B 9:00 121.7 30.4 121.4 30.2,
ID_x ID_y Time lon_x lat_x lon_y lat_y
0 B A 10:00 120.1 31.1 120.1 31.1
1 D A 10:00 120.1 31.1 120.1 31.1
2 D B 10:00 120.1 31.1 120.1 31.1]
③ 我们对上表标题进行合并
pd.concat(ls)
ID_xID_yTimelon_xlat_xlon_ylat_y0BA8:00122.130.2120.730.81CA8:00121.330.7120.730.82CB8:00121.330.7122.130.20BA9:00121.430.2120.131.11DA9:00121.730.4120.131.12DB9:00121.730.4121.430.20BA10:00120.131.1120.131.11DA10:00120.131.1120.131.12DB10:00120.131.1120.131.1
方法2:自己和自己 merge Time
tmp = pd.merge(testdata_5, testdata_5, on="Time")
tmp
ID_xTimelon_xlat_xID_ylon_ylat_y0A8:00120.730.8A120.730.81A8:00120.730.8B122.130.22A8:00120.730.8C121.330.73B8:00122.130.2A120.730.84B8:00122.130.2B122.130.25B8:00122.130.2C121.330.76C8:00121.330.7A120.730.87C8:00121.330.7B122.130.28C8:00121.330.7C121.330.79A9:00120.131.1A120.131.110A9:00120.131.1B121.430.211A9:00120.131.1D121.730.412B9:00121.430.2A120.131.113B9:00121.430.2B121.430.214B9:00121.430.2D121.730.415D9:00121.730.4A120.131.116D9:00121.730.4B121.430.217D9:00121.730.4D121.730.418A10:00120.131.1A120.131.119A10:00120.131.1B120.131.120A10:00120.131.1D120.131.121B10:00120.131.1A120.131.122B10:00120.131.1B120.131.123B10:00120.131.1D120.131.124D10:00120.131.1A120.131.125D10:00120.131.1B120.131.126D10:00120.131.1D120.131.1
tmp = tmp[tmp['ID_x'] > tmp['ID_y']]
tmp
ID_xTimelon_xlat_xID_ylon_ylat_y3B8:00122.130.2A120.730.86C8:00121.330.7A120.730.87C8:00121.330.7B122.130.212B9:00121.430.2A120.131.115D9:00121.730.4A120.131.116D9:00121.730.4B121.430.221B10:00120.131.1A120.131.124D10:00120.131.1A120.131.125D10:00120.131.1B120.131.1
4.1.6 遍历每一行
r = tmp.iloc[0]
r
ID_x B
Time 8:00
lon_x 122.1
lat_x 30.2
ID_y A
lon_y 120.7
lat_y 30.8
Name: 3, dtype: object
def f(r):
dis = ((r['lon_x']-r['lon_y'])**2+(r['lat_x']-r['lat_y'])**2)**0.5
return dis
f(r)
1.5231546211727744
对函数遍历每一行,得到结果存放在新的列,axis = 1才是行
tmp['distance'] = tmp.apply(lambda r:f(r),axis = 1)
tmp
ID_xTimelon_xlat_xID_ylon_ylat_ydistance3B8:00122.130.2A120.730.81.5231556C8:00121.330.7A120.730.80.6082767C8:00121.330.7B122.130.20.94339812B9:00121.430.2A120.131.11.58113915D9:00121.730.4A120.131.11.74642516D9:00121.730.4B121.430.20.36055521B10:00120.131.1A120.131.10.00000024D10:00120.131.1A120.131.10.00000025D10:00120.131.1B120.131.10.000000
2.1.7 插值和时空差值
如果我们知道一个个体8:00 在哪,9:00在哪,假设他们匀速运动,那么8:30在哪?我们可以计算出来
- 我们先对一组简单的数据进行插值
testdata1 = pd.DataFrame([[1,100],
[None,110],
[3,300]
],columns = ['a','b'])
testdata1
ab01.01001NaN11023.0300
- 采用
interpolate函数对缺失值进行插值
testdata1.interpolate()
ab01.010012.011023.0300
什么都不填,默认缺省值做插值,但我们想让a随着b的比例来进行插值
testdata1.set_index('b').interpolate(method='index').reset_index()
ba01001.011101.123003.0
先把b当成index,然后进行根据index进行插值,然后再掉征程最初的index
例2:
testdata2 = pd.DataFrame([['A','2010-10-02 08:23:10',120.7,30.8],
['A','2010-10-02 09:35:00',120.1,31.1],
['A','2010-10-02 10:04:00',120.1,31.1]
],columns = ['ID','Time','lon','lat'])
testdata2
IDTimelonlat0A2010-10-02 08:23:10120.730.81A2010-10-02 09:35:00120.131.12A2010-10-02 10:04:00120.131.1
testdata_time = pd.DataFrame([['2010-10-02 08:00:00'],
['2010-10-02 08:30:00'],
['2010-10-02 09:00:00'],
['2010-10-02 09:30:00'],
['2010-10-02 10:00:00']],columns = ['Time'])
testdata_time
Time02010-10-02 08:00:0012010-10-02 08:30:0022010-10-02 09:00:0032010-10-02 09:30:0042010-10-02 10:00:00
① 将两个表合起来,以便后续插值
tmp = pd.concat([testdata2,testdata_time])
tmp
IDTimelonlat0A2010-10-02 08:23:10120.730.81A2010-10-02 09:35:00120.131.12A2010-10-02 10:04:00120.131.10NaN2010-10-02 08:00:00NaNNaN1NaN2010-10-02 08:30:00NaNNaN2NaN2010-10-02 09:00:00NaNNaN3NaN2010-10-02 09:30:00NaNNaN4NaN2010-10-02 10:00:00NaNNaN
② 将时间由字符串转换为datetime格式,虽然形式看着没变化,但变化后可以排序了
tmp['Time'] = pd.to_datetime(tmp['Time'])
③ 将时间转换为index,然后以此为依据对lon和lat进行时空插值
tmp = tmp.set_index('Time').interpolate(method = 'index').reset_index().sort_values(by = 'Time')
tmp[tmp['ID'].isnull()]
TimeIDlonlat32010-10-02 08:00:00NaN120.70000030.80000042010-10-02 08:30:00NaN120.64292330.82853852010-10-02 09:00:00NaN120.39234330.95382862010-10-02 09:30:00NaN120.14176331.07911872010-10-02 10:00:00NaN120.10000031.100000
4.2 复杂数据处理任务的解决思路
当我们遇到具体的大数据分析人物的时候,我们把复杂任务分解成一个个小人物,然后每个小人物逐个解决。
- 我们有什么样的数据?
- 数据是如何存储的?
- 我们要得到什么的结果?
- 结果的数据又是什么形式的?
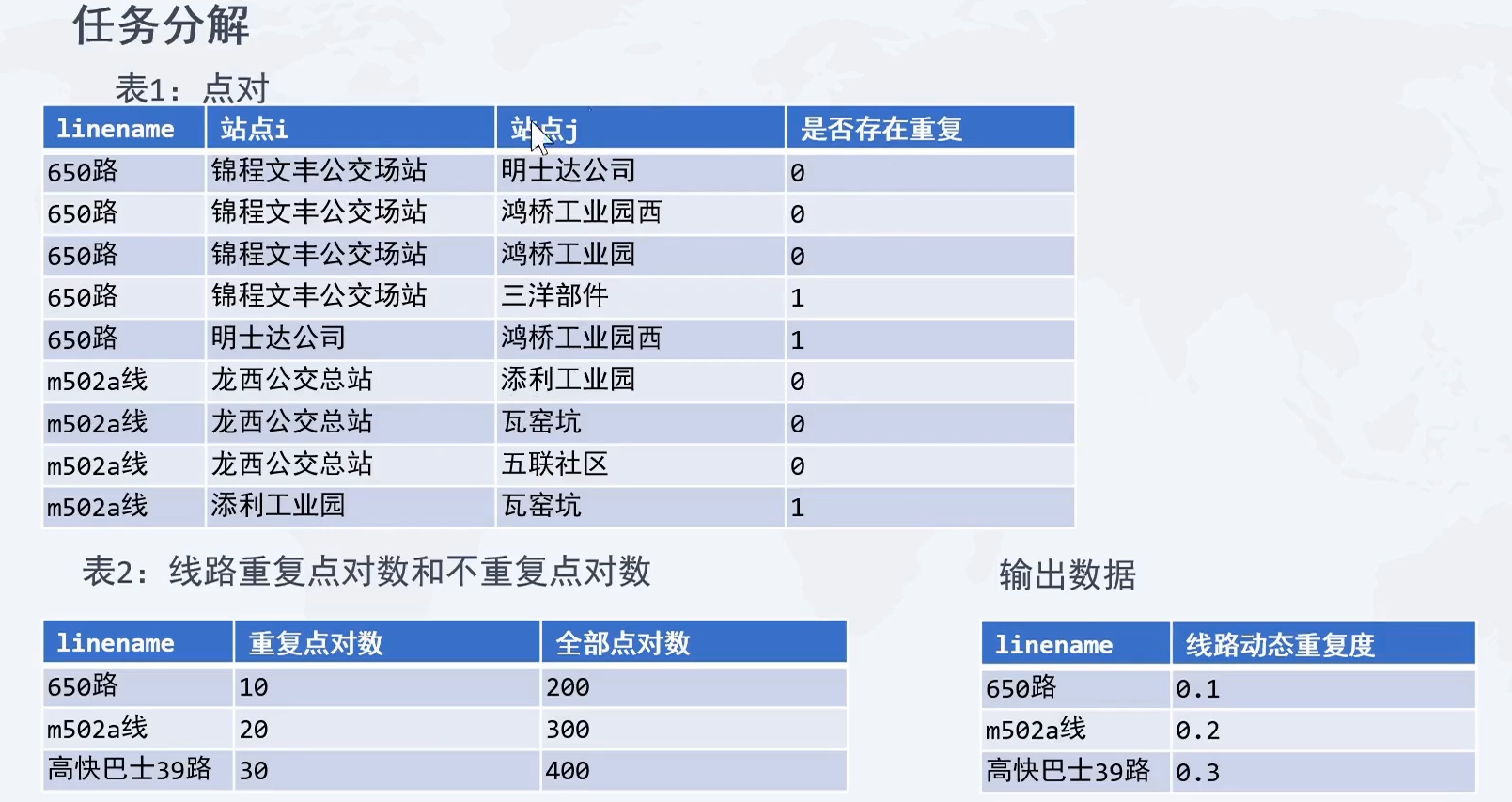
练习:尝试计算公交线路的动态重复度
import pandas as pd
busline = pd.read_csv(r'/data/PythonTrans/Data/busline.csv')
busline.head(5)
linenamestationnamestationgeo0650路(锦程文丰公交场站-凤凰山脚)[‘锦程文丰公交场站’, ‘明士达公司’, ‘鸿桥工业园西’, ‘鸿桥工业园’, ‘三洋部件…[‘113.78947398104066,22.728276040706554’, ‘113…1650路(凤凰山脚-锦程文丰公交场站)[‘凤凰山脚’, ‘凤凰第二工业区’, ‘凤凰台湾街’, ‘凤凰社区’, ‘凤凰广场’, ‘…[‘113.8559999718322,22.68862002580157’, ‘113.8…2m502a线(龙西公交总站-龙西公交总站)[‘龙西公交总站’, ‘添利工业园’, ‘瓦窑坑’, ‘五联社区’, ‘崇和学校’, ‘美信…[‘114.25368997182035,22.759529012563924’, ‘114…3高快巴士39路(华富路②-坂田风门坳总站)[‘华富路②’, ‘宏杨学校’, ‘坂田地铁站’, ‘扬马市场’, ‘金洲嘉丽园’, ‘坂田…[‘114.08788496287927,22.548925018156375’, ‘114…4高快巴士39路(坂田风门坳总站-华富路②)[‘坂田风门坳总站’, ‘岗头市场’, ‘华为基地’, ‘华为单身公寓北’, ‘万科城’, …[‘114.0748459685757,22.675367010065482’, ‘114….
busline = busline[['linename','stationname']]
busline
linenamestationname0650路(锦程文丰公交场站-凤凰山脚)[‘锦程文丰公交场站’, ‘明士达公司’, ‘鸿桥工业园西’, ‘鸿桥工业园’, ‘三洋部件…1650路(凤凰山脚-锦程文丰公交场站)[‘凤凰山脚’, ‘凤凰第二工业区’, ‘凤凰台湾街’, ‘凤凰社区’, ‘凤凰广场’, ‘…2m502a线(龙西公交总站-龙西公交总站)[‘龙西公交总站’, ‘添利工业园’, ‘瓦窑坑’, ‘五联社区’, ‘崇和学校’, ‘美信…3高快巴士39路(华富路②-坂田风门坳总站)[‘华富路②’, ‘宏杨学校’, ‘坂田地铁站’, ‘扬马市场’, ‘金洲嘉丽园’, ‘坂田…4高快巴士39路(坂田风门坳总站-华富路②)[‘坂田风门坳总站’, ‘岗头市场’, ‘华为基地’, ‘华为单身公寓北’, ‘万科城’, …………2108m359路(观澜大水田总站-坪山火车站总站)[‘观澜大水田总站’, ‘大水田社康中心’, ‘天堂围路口’, ‘铭可达物流园’, ‘兴发路…2109高峰专线102路(宝安客运中心-香山里花园公交总站)[‘宝安客运中心’, ‘丽景城’, ‘富盈门’, ‘前进天虹商场’, ‘诺铂广场’, ‘公园…2110高峰专线102路(香山里花园公交总站-宝安客运中心)[‘香山里花园公交总站’, ‘香山西街路口’, ‘白石洲西’, ‘沙河东路口’, ‘世纪村’…2111m308路(宝龙南同总站-坪地二办总站)[‘宝龙南同总站’, ‘兄弟厂’, ‘天马微’, ‘鸿源工业区’, ‘亚星厂’, ‘老大坑’…2112m308路(坪地二办总站-宝龙南同总站)[‘坪地二办总站’, ‘耀群厂’, ‘深南电路厂’, ‘冠旭电子’, ‘白石塘’, ‘吉祥三…
2113 rows × 2 columns
4.2.1 双向的线路只保留单向
busline['线路名'] = busline['linename'].apply(lambda r:r.split('(')[0])
busline['id'] = range(len(busline))
busline
linenamestationname线路名id0650路(锦程文丰公交场站-凤凰山脚)[‘锦程文丰公交场站’, ‘明士达公司’, ‘鸿桥工业园西’, ‘鸿桥工业园’, ‘三洋部件…650路01650路(凤凰山脚-锦程文丰公交场站)[‘凤凰山脚’, ‘凤凰第二工业区’, ‘凤凰台湾街’, ‘凤凰社区’, ‘凤凰广场’, ‘…650路12m502a线(龙西公交总站-龙西公交总站)[‘龙西公交总站’, ‘添利工业园’, ‘瓦窑坑’, ‘五联社区’, ‘崇和学校’, ‘美信…m502a线23高快巴士39路(华富路②-坂田风门坳总站)[‘华富路②’, ‘宏杨学校’, ‘坂田地铁站’, ‘扬马市场’, ‘金洲嘉丽园’, ‘坂田…高快巴士39路34高快巴士39路(坂田风门坳总站-华富路②)[‘坂田风门坳总站’, ‘岗头市场’, ‘华为基地’, ‘华为单身公寓北’, ‘万科城’, …高快巴士39路4……………2108m359路(观澜大水田总站-坪山火车站总站)[‘观澜大水田总站’, ‘大水田社康中心’, ‘天堂围路口’, ‘铭可达物流园’, ‘兴发路…m359路21082109高峰专线102路(宝安客运中心-香山里花园公交总站)[‘宝安客运中心’, ‘丽景城’, ‘富盈门’, ‘前进天虹商场’, ‘诺铂广场’, ‘公园…高峰专线102路21092110高峰专线102路(香山里花园公交总站-宝安客运中心)[‘香山里花园公交总站’, ‘香山西街路口’, ‘白石洲西’, ‘沙河东路口’, ‘世纪村’…高峰专线102路21102111m308路(宝龙南同总站-坪地二办总站)[‘宝龙南同总站’, ‘兄弟厂’, ‘天马微’, ‘鸿源工业区’, ‘亚星厂’, ‘老大坑’…m308路21112112m308路(坪地二办总站-宝龙南同总站)[‘坪地二办总站’, ‘耀群厂’, ‘深南电路厂’, ‘冠旭电子’, ‘白石塘’, ‘吉祥三…m308路2112
2113 rows × 4 columns
busline['rank'] = busline.groupby(['线路名'])['id'].rank()
busline = busline[busline['rank'] == 1].drop(['linename','id','rank'],axis = 1)
busline
stationname线路名0[‘锦程文丰公交场站’, ‘明士达公司’, ‘鸿桥工业园西’, ‘鸿桥工业园’, ‘三洋部件…650路2[‘龙西公交总站’, ‘添利工业园’, ‘瓦窑坑’, ‘五联社区’, ‘崇和学校’, ‘美信…m502a线3[‘华富路②’, ‘宏杨学校’, ‘坂田地铁站’, ‘扬马市场’, ‘金洲嘉丽园’, ‘坂田…高快巴士39路5[‘红湖总站’, ‘红湖村口’, ‘红湖工业区’, ‘光明书院’, ‘光明书院路口’, ‘新…高峰专线113路6[‘桃源村总站’, ‘桃源村’, ‘鼎胜山邻’, ‘新屋村’, ‘龙辉花园①’, ‘珠光村①…高峰专线69路………2101[‘大发埔村路口’, ‘龙壁工业区’, ‘坂田天虹’, ‘四季花城②’, ‘坂田石化新村’,…m533路2103[‘群星广场始发站①’, ‘华强路口’, ‘上海宾馆西②’, ‘岗厦北地铁站①’, ‘广电大…高峰专线119路2107[‘坪山火车站总站’, ‘坪山交通运输局’, ‘同乐社区’, ‘同乐工业区’, ‘新大坑市场…m359路2109[‘宝安客运中心’, ‘丽景城’, ‘富盈门’, ‘前进天虹商场’, ‘诺铂广场’, ‘公园…高峰专线102路2111[‘宝龙南同总站’, ‘兄弟厂’, ‘天马微’, ‘鸿源工业区’, ‘亚星厂’, ‘老大坑’…m308路
1054 rows × 2 columns
4.2.2 将站点字符串变为list
busline['stationname'].iloc[0:1]
0 ['锦程文丰公交场站', '明士达公司', '鸿桥工业园西', '鸿桥工业园', '三洋部件...
Name: stationname, dtype: object
exec('stop = '+busline['stationname'].iloc[1])
linename = busline['线路名'].iloc[1]
tmp = pd.DataFrame(stop,columns = ['stop'])
tmp['linename'] = linename
tmp
stoplinename0龙西公交总站m502a线1添利工业园m502a线2瓦窑坑m502a线3五联社区m502a线4崇和学校m502a线5美信佳百货m502a线6宏晟厂m502a线7五联市场m502a线8深圳技师学校m502a线9百合盛世m502a线10深中龙岗初级中学m502a线11中南人防加油站m502a线12爱地花园m502a线13君悦龙庭m502a线14龙岗疾控中心m502a线15龙岗实验学校m502a线16欧景花园m502a线17欧景城m502a线18愉园新村m502a线19新亚洲花园m502a线20龙城中学m502a线21鸿基花园m502a线22吉祥地铁站m502a线23龙兴联泰m502a线24龙城广场m502a线25龙岗文化中心m502a线26龙岗交通运输局m502a线27龙福一村m502a线28龙城小学m502a线29清林小学m502a线30中央悦城m502a线31紫麟山m502a线32欧意轩花园m502a线33陂头肚村m502a线34龙岗区福利院m502a线35务地埔村m502a线36龙西桥m502a线37龙溪幼儿园m502a线38龙西村委m502a线39民润百货m502a线40龙西公交总站m502a线
ls = []
for i in range(len(busline)):
exec('stop = '+busline['stationname'].iloc[i])
linename = busline['线路名'].iloc[i]
tmp = pd.DataFrame(stop,columns = ['stop'])
tmp['linename'] = linename
ls.append(tmp)
input_table = pd.concat(ls)
input_table
stoplinename0锦程文丰公交场站650路1明士达公司650路2鸿桥工业园西650路3鸿桥工业园650路4三洋部件厂650路………47白石塘m308路48冠旭电子m308路49深南电路厂m308路50耀群厂m308路51坪地二办总站m308路
29871 rows × 2 columns
4.2.3 获取站点对,并标注是否有重复
table1 = pd.merge(input_table,input_table,on =['linename'])
table1 = table1[-(table1['stop_x'] == table1['stop_y'])]
table1
stop_xlinenamestop_y1锦程文丰公交场站650路明士达公司2锦程文丰公交场站650路鸿桥工业园西3锦程文丰公交场站650路鸿桥工业园4锦程文丰公交场站650路三洋部件厂5锦程文丰公交场站650路锦程文丰大厦…………1111107坪地二办总站m308路吉祥三路口1111108坪地二办总站m308路白石塘1111109坪地二办总站m308路冠旭电子1111110坪地二办总站m308路深南电路厂1111111坪地二办总站m308路耀群厂
1079772 rows × 3 columns
tmp = table1.groupby(['stop_x','stop_y'])['linename'].count().rename('count').reset_index()
tmp
stop_xstop_ycount0182设计园三联广场11182设计园上李朗第二工业区22182设计园上李朗统建楼13182设计园上水径14182设计园上水径地铁站1…………762309龟山公园南荣健农批1762310龟山公园南马山头市场1762311龟山公园南马山头第三工业区1762312龟山公园南马山头路口1762313龟山公园南马田农商行1
762314 rows × 3 columns
tmp['is_duplicate'] = tmp['count']>=2
tmp['is_duplicate'] = tmp['is_duplicate'].astype(int)
tmp
stop_xstop_ycountis_duplicate0182设计园三联广场101182设计园上李朗第二工业区212182设计园上李朗统建楼103182设计园上水径104182设计园上水径地铁站10……………762309龟山公园南荣健农批10762310龟山公园南马山头市场10762311龟山公园南马山头第三工业区10762312龟山公园南马山头路口10762313龟山公园南马田农商行10
762314 rows × 4 columns
4.2.4 计算全部的站点对数量和重复的站点对数量
根据站点对,把是否可重复列+到tabel上
table1 = pd.merge(table1,tmp.drop('count',axis = 1),on = ['stop_x','stop_y'])
table1
stop_xlinenamestop_yis_duplicate_xis_duplicate_y0锦程文丰公交场站650路明士达公司111锦程文丰公交场站615路明士达公司112锦程文丰公交场站m341路明士达公司113锦程文丰公交场站781路明士达公司114锦程文丰公交场站650路鸿桥工业园西11………………1079767坪地二办总站m308路吉祥三路口001079768坪地二办总站m308路白石塘001079769坪地二办总站m308路冠旭电子001079770坪地二办总站m308路深南电路厂001079771坪地二办总站m308路耀群厂00
1079772 rows × 5 columns
all_count = table1.groupby('linename')['is_duplicate_x'].count().rename('all_count').reset_index()
all_count
linenameall_count0101路17221102路6502103路28623104路24504107路2070………1049高铁坪山快捷线接驳2线721050高铁坪山快捷线接驳3线561051龙华有轨电车1路2101052龙华有轨电车2路1321053龙华有轨电车3路30
1054 rows × 2 columns
is_duplicate = table1.groupby('linename')['is_duplicate_y'].sum().rename('is_duplicate').reset_index()
is_duplicate
linenameis_duplicate0101路8201102路3242103路10783104路5824107路684………1049高铁坪山快捷线接驳2线121050高铁坪山快捷线接驳3线121051龙华有轨电车1路301052龙华有轨电车2路321053龙华有轨电车3路2
1054 rows × 2 columns
table2 = pd.merge(is_duplicate,all_count,on ='linename')
table2
linenameis_duplicateall_count0101路82017221102路3246502103路107828623104路58224504107路6842070…………1049高铁坪山快捷线接驳2线12721050高铁坪山快捷线接驳3线12561051龙华有轨电车1路302101052龙华有轨电车2路321321053龙华有轨电车3路230
1054 rows × 3 columns
- 计算算线路的动态重复
table2['dynamic_degree']=table2['is_duplicate']/table2['all_count']
table2
linenameis_duplicateall_countdynamic_degree0101路82017220.4761901102路3246500.4984622103路107828620.3766603104路58224500.2375514107路68420700.330435……………1049高铁坪山快捷线接驳2线12720.1666671050高铁坪山快捷线接驳3线12560.2142861051龙华有轨电车1路302100.1428571052龙华有轨电车2路321320.2424241053龙华有轨电车3路2300.066667
1054 rows × 4 columns
Original: https://blog.csdn.net/wistonty11/article/details/121210664
Author: 羊老羊
Title: 【小旭学长-使用python进行城市数据分析】笔记篇(中)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/600956/
转载文章受原作者版权保护。转载请注明原作者出处!