

本篇主要讲解的知识:
- 数据分析中数据去重的概念及目标
- 如何借助df.describe()帮助去重
- df.drop_duplicates()
- 如何简单高效去除重复 *列
什么是数据去重?
很多刚入门 入坑 数据分析的小伙伴在进行数据预处理的时候,都会面临考虑如何进行数据去重的情况。这时候一些人会觉得:”啊哈哈哈哈数据去重还不简单,不就是把一样的行或列舍掉就ok了吗”
然后他们啪啪一顿敲,跑出来的结果连外行看起来都觉得怪怪的。
他们便疑惑了,我做的数据预处理,数据去重有什么不对的吗?数据去重不就是把一样的行或列删掉就完事儿吗?
事实上,数据去重并不是简单地把数据表中相同的行列舍掉就可以了。真正意义上的数据去重这一步骤,需要仔细考虑一下几个方面:
- 该数据分析任务下,重复值对既定指标有影响吗?可能造成的影响有哪些?
- 需要按照什么标准进行去重?
- 是否需要删除重复的行或者列?是否需要将所有重复的行或列全部舍掉而不保留?如果要保留的话,保留哪个位置的?第一个还是最后一个?
- 如果一行或者一列里的值都是相同的,需要删除这行或者这列吗?
- 一部分数据为空,但是另一部分数据完全重复的行/列,需要删除吗?
具体一点来说,数据去重,是数据预处理中的一个环节,这个环节的主要目的,是为了 将异常的重复数据进行处理,从而让得到的指标更加合理。这里所说的重复数据,是没有一个严格的界限的,它的定义需要根据实际问题进行具体分析和判别。且这里所说的处理,不一定是删除,也有可能是替换等操作。
比如,我们现在需要对一个班上的学生的整体考试成绩情况进行分析(咱就假装一个班上只有这几个人),有以下的数据:
姓名语文成绩数学成绩小牟90100黑哥5360能小胖100100能小胖2359.5阿西缺考88
这个表咱定睛一看,诶,这怎么有俩能小胖?这货该不会是请的代考,结果又忘了有这事儿结果自己又去考了一次吧?
这种情况下,你会知道,重复值对指标产生影响(毕竟两个相同的同学有着不同的成绩,总不可能在分析的时候都分析吧?),于是为了确保数据的准确,你应该从数据的源头出发,弄明白为什么会出现这种情况。于是你应该把能小胖这货拉过来严刑逼供,询问他是否找了代考,还是发生了其他什么情况。
经过仔细的询问 严刑拷打 ,你最终得知是班上有个叫赵大憨的差生在考试的时候填错了名字,导致数据表中出现了两个能小胖。
在弄清楚重复数据产生的原因之后,现在我们就应该对重复值进行处理了。这种情况下,我们对重复值采用的应该是 替换操作,(因为只有名字有重复,且其他字段都是真实有效的)我们需要将第二个能小胖的名字替换为赵大憨,从而完成这一步的去重。去重后得到的数据表如下:
姓名语文成绩数学成绩小牟90100黑哥5360能小胖100100赵大憨2359.5阿西缺考88
当然,如果能小胖说自己找了代考且自己也去参加了考试,对重复值的处理就应该是 删除其中的一条,保留其中的一条。
这下你再一看,诶,能小胖的语文成绩和数学成绩怎么重复了,都是100分。这时候,你应该保留这个重复值(因为不同学科获得相同的成绩 是可能发生的)而不是将他们舍掉。
使用df.describe()帮助去重
我们在了解了去重的概念之后,接下来再深入一些。
假如我们现在需要去除所有值都相同的行,或者列,应该怎么做?
这看起来是一个很简单的问题,但绝大多数时候,我们面对的数据量都是万级、十万级甚至是千万级的,这些数据中还不乏空值、乱码、不规范字符等异常数据值。在几乎所有时候,数据表都很难显示完全(可能会导致操作者在处理数据时带入主观因素:这一列/行看起来全是相同值),这导致确认重复数据列或行不是那样简单。

这时候,df.describe()就派上用场了。
我们可以通过df.describe()查看数据表的概览,为了确认有哪些行/列中的值是相同的,我们需要重点关注describe()数据表中std(标准差)和count这两项。
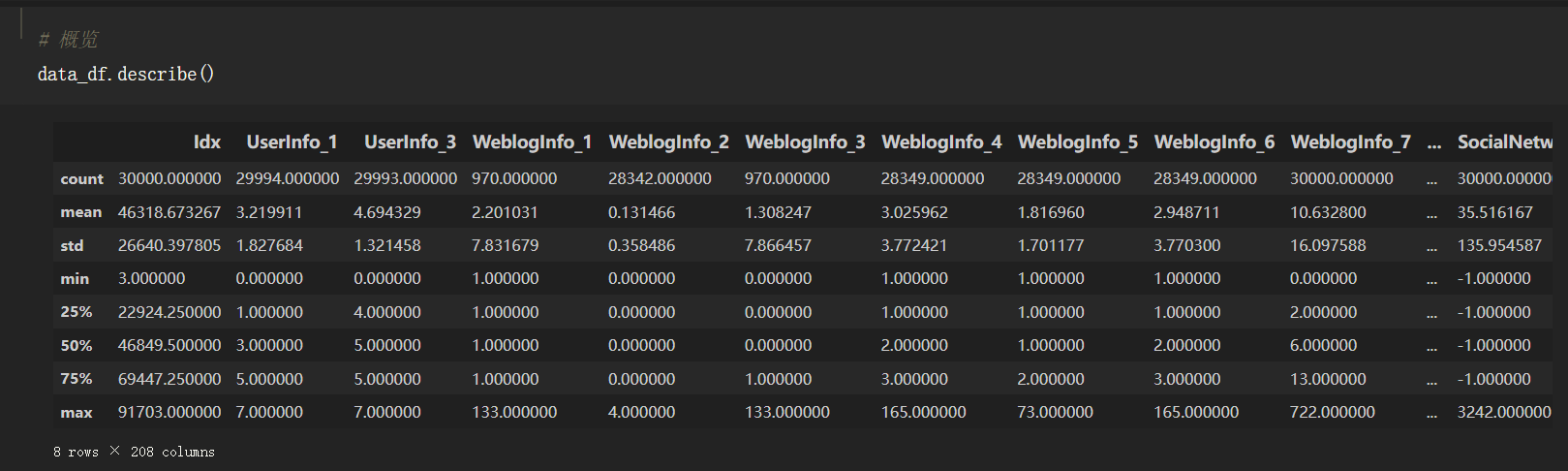
std为0的数据列,就是所有数据都相同的列。(原因很好理解,就不在这里过多赘述。)而count这一项统计的是这一数据列中不为空的数据总数,假设这一列中所有数据都为空(也是所有数据都相同),那么count就为0,这样的列也需要去除。
好了,那如果需要去除所有数据都相同的行呢?如何确认?
很简单,我们只需调用T对原数据表进行转置,将行变为列,列变为行,然后进行和上面相同的步骤即可。
此外,这里顺带提一下,df.describe()是可以传入参数的(不会真的还有人不知道吧),df.describe()的函数定义是这样的:
def describe(
self: FrameOrSeries,
percentiles=None,
include=None,
exclude=None,
datetime_is_numeric=False,
) -> FrameOrSeries:
具体每个参数的含义,大家可以去看看官方文档中的描述。这里就不一 一解释了。
默认情况下,df.describe()会忽略含有非数字的列,仅仅对全部为数字的列进行描述。所以有些时候我们会发现df.describe()得到的数据表和原本的数据表规格不一致。如果需要对全部的列进行描述,需要将参数include设置为’all’。这样做可以将df.describe()相关的语句用在布尔索引中,而不抛出数据表规格大小不相同的报错。
例如,下面对值相同的列(注意,这里所说的值相同的列,包含一部分值为空,而其余值相同的列)的删除,就是通过这种方法实现的。
data_df.T[data_df.describe(include='all').loc['std'] != 0]
这里如果不将include设置为all,则会抛出异常:
IndexingError: Unalignable boolean Series provided as indexer (index of the boolean Series and of the indexed object do not match).
df.drop_duplicates()
该方法是去重操作中用得最多的方法之一了。它可以将值相同的 行(包括一部分值为空,而另一部分值相同的行)进行去重操作。该函数的定义如下:
def drop_duplicates(
self,
subset: Optional[Union[Hashable, Sequence[Hashable]]] = None,
keep: Union[str, bool] = "first",
inplace: bool = False,
ignore_index: bool = False,
) -> Optional["DataFrame"]:
其中,keep参数决定了重复列的保留方式,有三个可以传入的值:’first’, ‘last’, False。将keep设置为’first’,则数据表中会保留重复数据列的 第一条,而其余的重复数据列会被删除;将keep设置为’last’,则数据表中会保留重复数据列中的 最后一条, 而其余重复数据列会被删除;将keep设置为False,则该方法返回的数据表中重复的数据列都会被删除,不会保留。
inplace参数表示是否在原表上进行操作,如果被设置为True,那么删除操作会在原表上进行,否则方法会返回一个新的DataFrame。
subset参数决定了重复列的判定方式,这让我们有机会利用多列作为判定重复的依据。比如现在有一个数据表是这样的:
df = pd.DataFrame(
[['Apple', 13, 'big', 20], ['Pear', 22, 'small', 15], ['Orange', 9, 'big', 10], ['Kiwi', 13, 'big', 9]],
columns=['name', 'price', 'figure', 'day']
)
namepricefiguredayApple13big20Pear22small15Orange9big10Kiwi13big9
假如我们要依据price和figure对重复数据进行去除,则代码可以这样写:
df.drop_duplicates(subset=['price', 'figure'], keep=False)
得到的数据表如下:
namepricefiguredayPear22small15Orange9big10
最后一个ignore_index参数是对数据表的index进行设置,如果设置为True,则生成的数据表会从0开始重新进行排号,若为False,则舍去重复值后的index不变。
另外,还有一点需要注意的是,drop_duplicates()方法是可以去除 含空值的重复行的。
比如下面这个例子,大家可以在Jupyter中运行一下看下结果。
temp_df = pd.DataFrame(
[[1, 2, 3, 4, 5],
[4, None, None, 1, None],
[2, 3, 2, 5, 3],
[4, None, None, 1, None]]
)
temp_df.drop_duplicates()
但是如果遇到空值的位置不匹配的情况,则需要借助前文提到的利用std进行去重了。如下:
123450nannannan000nannan043210
这张表中,第二行和第三行的数据均是0值和空值,在一些情况下是需要舍弃的,但是使用drop_duplicates()无法去重,而我们可以使用前文的std=0进行识别并去重。(因为第二行和第三行的数据std都为0)
如何简单高效去除重复列
之前我们说过的drop_duplicates()看起来很好用,但是它只能去除重复的 行,而且该方法并不能(至少到现在没有,希望以后会被扩充)像drop方法那样通过设置axis参数的值来去除重复的列。但是,我们依旧可以使用它来对重复的列进行去重操作。如下:
df.T.drop_duplicates().T
我们只需要通过调用T对数据表进行转置,然后调用drop_duplicates()方法去重,最后再调用T转置回来即可。
Original: https://blog.csdn.net/weixin_45380689/article/details/121576682
Author: 能小胖
Title: Pandas数据分析去重:去重,真的只是去除一样的行或列吗?
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/600922/
转载文章受原作者版权保护。转载请注明原作者出处!