

利用python爬取东方财富网股吧评论(一)
python-东方财富网贴吧文本数据爬取
分享一下写论文时爬数据用到的代码,有什么问题或者改善的建议的话小伙伴们一起评论区讨论。涉及内容在前人的研究基础之上,探索适合自己一些知识点,本人非计算机专业,金融专业,学习爬虫用于项目研究,以此发表供大家学习与指点。
一、论文说明
论文需求:股吧中人们发表的评论和创业板股市价格波动
数据来源:东方财富网创业板股吧
数据标签:阅读、评论、标题、作者、更新时间,
实现功能:读取每个股吧的全部页面的评论并写入excel表中
二、实施过程
1.明确评论数据
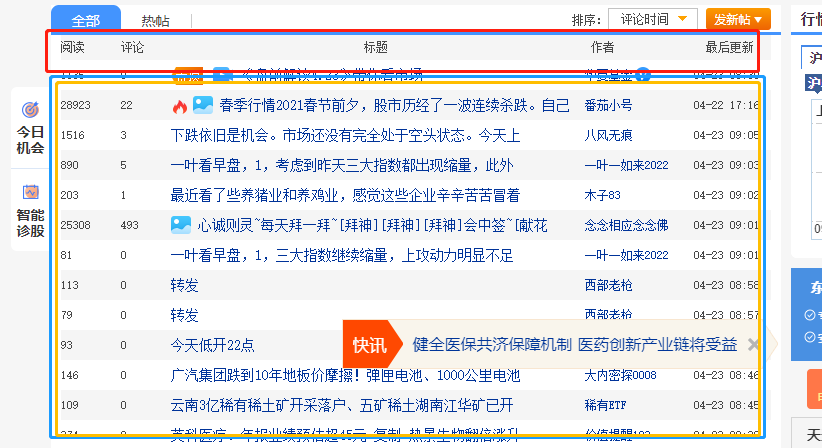

2.查看网页源代码结构
① 网页源代码
首先打开网页的开发者工具(右击-检查)或者右击网页源代码,在源代码中查找对应字段的标签。
以下是大多数学者的分析:
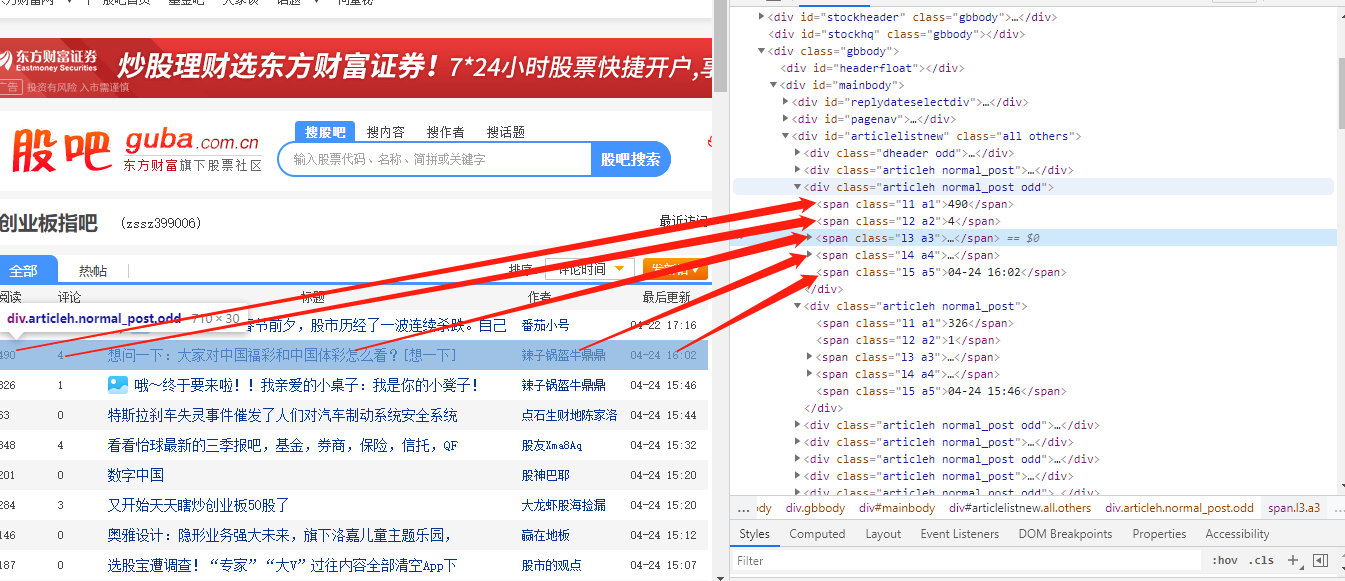
从图中可以看出,这五个字段分别位于行标签内,对应的属性分别是”l1 a1″、”l2 a2″、”l3 a3″、”l4 a4″、”l5 a5″。
如果单纯想要获取此网址所对应的数据,参考此方法都可以进行爬取。但是,爬取之后会发现标题内容是不全,缺失的:

下面是每一条标题评论的详细网页的内容,与总页对比,详情页内容是完整的:

所以我们需要确定每一条详细评论的详情网页:

以上通过简单分析,我们确定了所需要数据对应的标签结构所在处。
我们需要爬取不止一页的数据,因此还要分析以下情况:
首页:http://guba.eastmoney.com/list,zssz399006.html
第二页:http://guba.eastmoney.com/list,zssz399006_2.html
可以看出个股吧链接主要由三部分组成:list、名称代码、页数
通过以上分析,我们基本可以爬取需要的数据。
; 三、部分代码
1.以下是仅仅获取每一个总页中标题内容的代码
max_page= #爬取的最大页数
all_title = [] #爬取的标题存储列表
all_time = [] #爬取的发表时间储存列表
headers = {'User-Agent': ''} #构造头文件,模拟浏览器。
for page in range(1,max_page+1):
#获取网页源代码
print('crawling the page is {}'.format(page))
url= f'http://guba.eastmoney.com/list,zssz399006,f_{page}.html'
response = requests.get(url, headers=headers)
#解析网页源代码
root = etree.HTML(response.text)
title = root.xpath("//div[contains(@class,'articleh normal_post')]//span[@class='l3 a3']//a//text()")
time = root.xpath("//div[contains(@class,'articleh normal_post')]//span[@class='l5 a5']//text()")
all_title += title #保存到总数组上
all_time += time
data_raw = pd.DataFrame()
data_raw['title'] = all_title
data_raw['time'] = all_time
data_raw.to_excel('.//data_raw.xlsx', index=False)
四、完整代码
以下是本人长时间自己摸索所写,因本人非计算机专业,所写内容如有错误请各位前辈同仁所担待并提出宝贵意见,原谅本人不能提供相对完整代码,框架已写好,缺失部分填写对应的标签即可,如有需要请联系本人(注明来意)
import requests
from lxml import etree
import re
import csv
f = open('创业板股吧评.csv',mode='a',encoding='utf-8',newline='')#可以自己改文件名
csv_writer = csv.DictWriter(f,fieldnames=['标题','标题url','发布时间','总阅读人数','总评论数','正文'])#这个是表的字段名称
csv_writer.writeheader()
def xiangqing(n):
url = 'http://guba.eastmoney.com/list,zssz399006_{}.html'.format(n)
print('crawling the page is {}'.format(n))
header = {
'User-Agent': ' '
}
response = requests.get(url,headers=header)
html = etree.HTML(response.text)
text = html.xpath(' ')
url_list = html.xpath(' ')
return url_list
def a(url_list):
header = {
'User-Agent': ' '
}
for url in url_list:
new_url = 'http://guba.eastmoney.com' + url
response = requests.get(new_url,headers = header)
html = etree.HTML(response.text)
title = re.findall(' ',response.text)[0].replace('"','')
text = re.findall(' ',response.text)[0].replace('"','')
readers = re.findall(r' ', response.text)[0] # 获取总人数
comments = re.findall(r' ', response.text)[0] # 获取总评价数
date = html.xpath(' ')[0] # 获取发布时间
dic = {
}
csv_writer.writerow(dic) #将获取到的数据写入创建的csv文件中# def bianli():
if __name__ == '__main__':
for i in range(3195,3295):
#以下是循环代码
五、爬取结果
由于本人正处在多进程学习当中,多进程代码无法提供,请谅解。


此正文部分可进行相关情绪分析且内容完整。
; 六、自我介绍
本人初次接触爬虫,一名金融非计算机专业的研究生二年级学生,学习之路漫漫且困难重重,以上信息如有雷同,请谅解。
希望广大学者指导交流。
接下来会写一篇lstm进行情感分析,请广大读者持续关注,谢谢。
本人 QQ:私信联系博主
Original: https://blog.csdn.net/YMG521000/article/details/114820502
Author: 学无止境_mg
Title: 利用python爬取东方财富网股吧评论并进行情感分析(一)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/600513/
转载文章受原作者版权保护。转载请注明原作者出处!