

大家好,我是Mr数据杨。今天我们将一同走进充满数字的Python世界,我想拿《三国演义》的例子来阐述一下学习笔记中的主题。
首先得有数据。试想一下,如果三国的谋士们如诸葛亮,郭嘉,周瑜,手中没有了兵力、粮草、城池的数据,他们又怎能谋划出赢得战争的策略呢?这就如同在学习Python的过程中需要用到的三国志人物数据,空气质量数据集,新闻聚合器数据集。数据是分析的基石,就像每一场战争的胜败都基于谋士手中的资料。
然后,将这些数据如何有效地整理和使用就像《三国演义》中的谋士们一样,他们如何利用手中的信息,才是关键。比如说,Python里的GroupBy的工作原理。GroupBy就像诸葛亮把不同战区的信息整理归类,把相同的数据放在一起,这样便于分析和利用。或许周瑜就是这样利用GroupBy原理,将敌人的兵力分布、粮草储备等信息整理出来,然后决定是否施行火攻。
最后来聊聊提高GroupBy的性能。性能,对于Python来说是至关重要的,这就如同战场上,郭嘉总能运筹帷幄之中,决胜千里之外,这就是他提高了策略的效率,GroupBy的性能也是如此,优化它,能更快更准确地帮助拿到想要的结果。
当然,这只是个开头,接下来我们还会一起深入探讨Pandas GroupBy方法的汇总,就像三国演义的战役一样,每一场都充满惊奇和学问。
文章目录
数据准备
示例1:三国志人物数据
我们以剖析《三国志》人物数据为例,来介绍GroupBy操作的具体用法。
首先,我们需要导入pandas库,并读取人物数据的Excel文件。
import pandas as pd
df = pd.read_excel("Romance of the Three Kingdoms 13/人物详情数据.xlsx")
df.head()
下面是导入数据并显示前几行的示例结果:
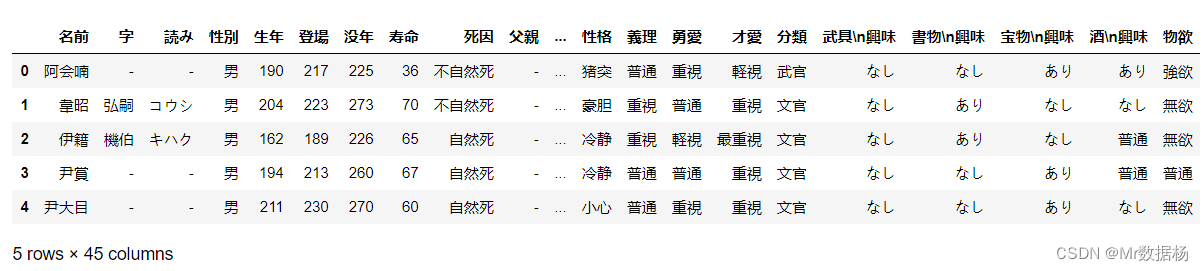

问题1(单列聚合): 如果想了解所有人物中的分类情况,即文臣和武将的数量分别是多少,应该如何操作?
我们可以使用SQL语句和Pandas操作来实现。
SQL操作:
SELECT 分類, count(名前) as 数量
FROM df
GROUP BY 分類
ORDER BY 分類;
Pandas操作:
n_by_state = df.groupby("分類")["名前"].count().nlargest(2)
n_by_state
执行以上操作后,可以得到文官和武官的数量分别为336和520。
问题2(多列聚合): 如何按照性别和分类进行人物的区分?
我们可以使用SQL语句和Pandas操作来实现。
SQL操作:
SELECT 分類, 性別, count(名前) as 数量
FROM df
GROUP BY 分類, 性別
ORDER BY 分類, 性別;
Pandas操作:
n_by_state = df.groupby(["分類", "性別"])["名前"].count()
n_by_state
执行以上操作后,可以得到按照性别和分类进行区分的结果。
示例2:空气质量数据集
接下来,我们以空气质量数据集为例,介绍GroupBy操作的更多用法。
import pandas as pd
df = pd.read_excel("数据科学必备Pandas实用操作GroupBy数据分组详解/AirQualityUCI.xlsx", parse_dates=[["Date", "Time"]])
df.rename(columns={
"CO(GT)": "co",
"Date_Time": "tstamp",
"T": "temp_c",
"RH": "rel_hum",
"AH": "abs_hum",
}, inplace=True)
df.set_index("tstamp", inplace=True)
下面是导入数据并对其进行处理后的示例结果:

在这个数据集中, co 是每小时的平均一氧化碳读数, temp_c、 rel_hum 和 abs_hum 分别是每小时的平均温度、相对湿度和绝对湿度。观察时间跨度从 2004 年 3 月持续到 2005 年 4 月。
派生数组进行分组
我们可以利用星期的数据(转化后的字符串)进行分组聚合。
day_names = df.index.day_name()
day_names[:10]
执行以上操作后,可以得到每天的星期名称。
问题1: 如何计算一周中某天的平均一氧化碳 (co) 的数据?
df.groupby(day_names)["co"].mean()
执行以上操作后,可以得到一周中每天的平均一氧化碳 (co) 数据。
问题2: 如何按照星期和每个时间段对数据进行聚合?
hr = df.index.hour
df.groupby([day_names, hr])["co"].mean().rename_axis(["dow", "hr"])
执行以上操作后,可以按照星期和每个时间段对数据进行聚合。
问题3: 如何根据温度划分离散区间对数据进行分组聚合?
bins = pd.cut(df["temp_c"], bins=3, labels=("cool", "warm", "hot"))
df[["rel_hum", "abs_hum"]].groupby(bins).agg(["mean", "median"])
执行以上操作后,可以根据温度划分离散区间对数据进行分组聚合。
问题4: 如何按年度和季度对数据进行聚合?
df.groupby([df.index.year, df.index.quarter])["co"].agg(["max", "min"]).rename_axis(["year", "quarter"])
执行以上操作后,可以按照年度和季度对数据进行聚合。
示例3:新闻聚合器数据集
最后,我们以新闻
聚合器数据集为例,介绍GroupBy操作的更多用法。
import datetime as dt
import pandas as pd
def parse_millisecond_timestamp(ts):
return dt.datetime.fromtimestamp(ts / 1000, tz=dt.timezone.utc)
df = pd.read_csv(
"数据科学必备Pandas实用操作GroupBy数据分组详解/newsCorpora.csv",
sep="\t",
header=None,
index_col=0,
names=["title", "url", "outlet", "category", "cluster", "host", "tstamp"],
parse_dates=["tstamp"],
date_parser=parse_millisecond_timestamp,
dtype={
"outlet": "category",
"category": "category",
"cluster": "category",
"host": "category",
},
)
df.head()
下面是导入数据并显示前几行的示例结果:
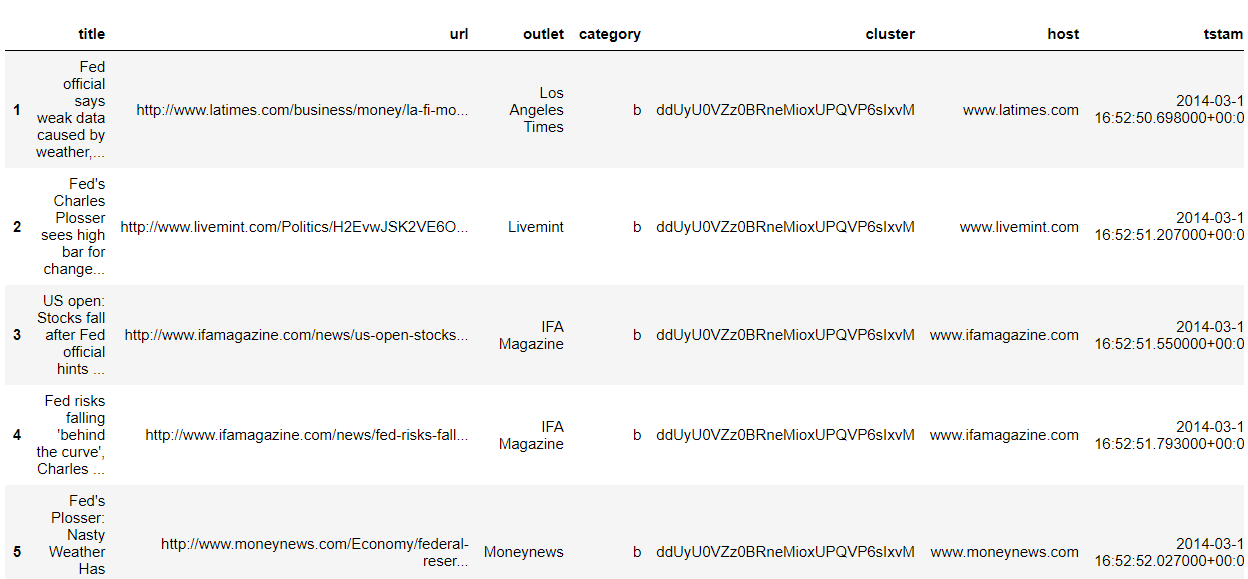
在这个数据集中, category 列包含了新闻的分类,分别是 b 商业、t 科技、e 娱乐和 m 健康。
问题1: 如何计算包含某关键字的数据在不同出版机构中的出现次数,并按次数排序?
df.groupby("outlet", sort=False)["title"].apply(
lambda ser: ser.str.contains("Fed").sum()
).nlargest(10)
执行以上操作后,可以得到包含某关键字的数据在不同出版机构中的出现次数,并按次数排序。
GroupBy 的工作原理
实际上, .groupby() 操作是由三个步骤组成的:拆分、应用和合并。
拆分过程
我们可以通过对GroupBy对象进行迭代来查看拆分的结果。
by_state = df.groupby("分類")
for state, frame in by_state:
print(f"前2条数据 {state!r}")
print("------------------------")
print(frame.head(2), end="\n\n")
执行以上操作后,会显示每个组的前两条数据。
应用过程
将相同的操作(或可调用对象)应用于拆分阶段生成的每个小组。
state, frame = next(iter(by_state))
state
'文官'
frame.head(5)
执行以上操作后,可以查看应用操作后的结果。
合并过程
python
frame["名前"].count()
336
以上操作展示了合并阶段的结果。
提高GroupBy的性能
使用适当的方法可以提高GroupBy操作的性能。
Version 1: 使用 .apply()
df.groupby("outlet", sort=False)["title"].apply(
lambda ser: ser.str.contains("Fed").sum()
).nlargest(10)
Version 2: 使用矢量化操作
mentions_fed = df["title"].str.contains("Fed")
mentions_fed.groupby(
df["outlet"], sort=False
).sum().nlargest(10).astype(np.uintc)
以上是使用两种不同方法进行操作的示例,可以看到使用矢量化操作的性能更好。
Pandas GroupBy 方法汇总
Pandas提供了许多GroupBy方法,下面是一些常用的方法:
- 聚合方法(也称为归约方法):.agg()、.aggregate()、.all()、.any()、.apply()、.corr()、.corrwith()、.count()、.cov()、.cumcount()、.cummax()、.cummin()、.cumprod()、.cumsum()、.describe()、.idxmax()、.idxmin()、.mad()、.max()、.mean()、.median()、.min()、.nunique()、.prod()、.sem()、.size()、.skew()、.std()、.sum()、.var()。
- 过滤器方法:.filter()、.first()、.head()、.last()、.nth()、.tail()、.
take()。
- 转换方法:.bfill()、.diff()、.ffill()、.fillna()、.pct_change()、.quantile()、.rank()、.shift()、.transform()、.tshift()。
- 元方法:. iter()、.get_group()、.groups、.indices、.ndim、.ngroup()、.ngroups、.dtypes。
- 绘图方法:.hist()、.ohlc()、.boxplot()、.plot()。
以上是对GroupBy操作的示例和方法汇总,希望能帮助你更好地理解和应用Python编程中的GroupBy功能。
Original: https://blog.csdn.net/qq_20288327/article/details/124884920
Author: Mr数据杨
Title: 数据科学必备Pandas数据分组GroupBy方法汇总
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/600299/
转载文章受原作者版权保护。转载请注明原作者出处!