

题目需求描述
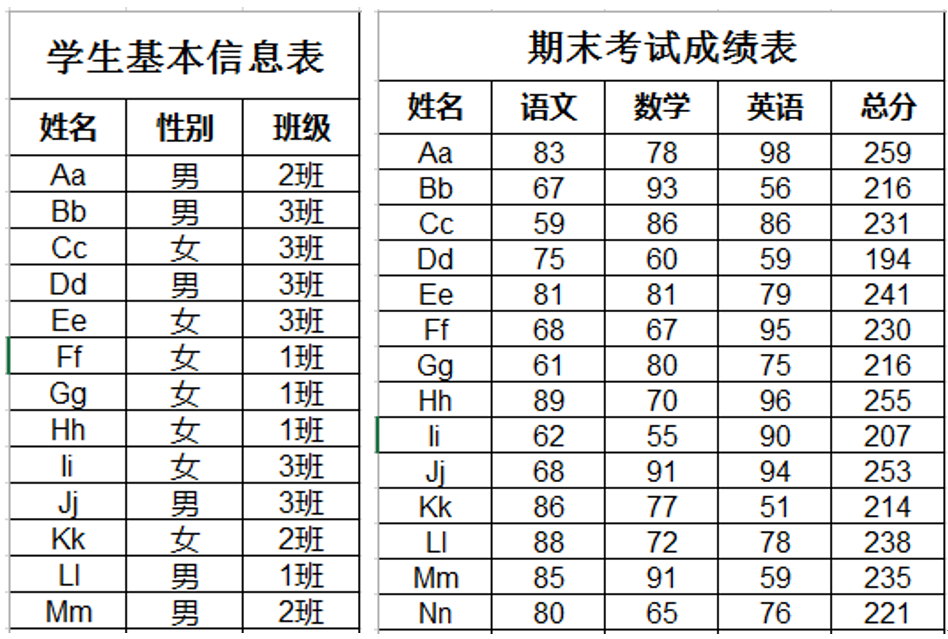
已知两个Excel表格: 学生基本信息表、 期末考试成绩表分别用于存放学生的基本信息(包括 姓名、 性别、 班级)和学生的期末成绩(包括 姓名、 语文、 数学、 英语、 总分),部分数据如下图所示(完整数据见 学生基本信息表 .xls、 期末考试成绩表 .xls),完成以下操作。

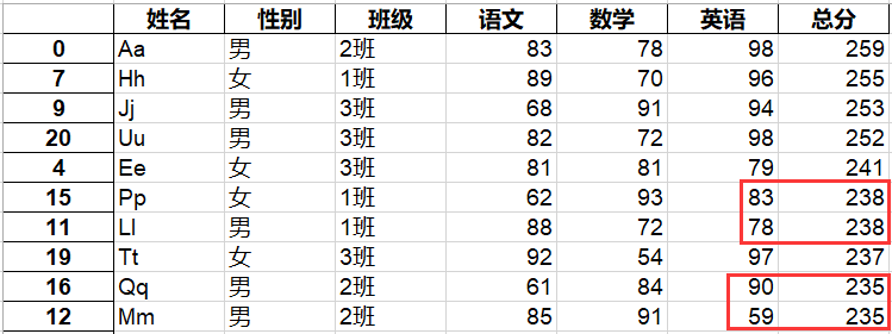
(1)编写程序读取两张表中的数据,并将其 根据姓名进行合并,然后将合并后的数据 按照总分从高到低进行排序,总分相同时, 根据英语成绩从高到低排序,并将结果存放在 学生期末考试成绩排名表 .xls中,最终表中的部分数据如下。
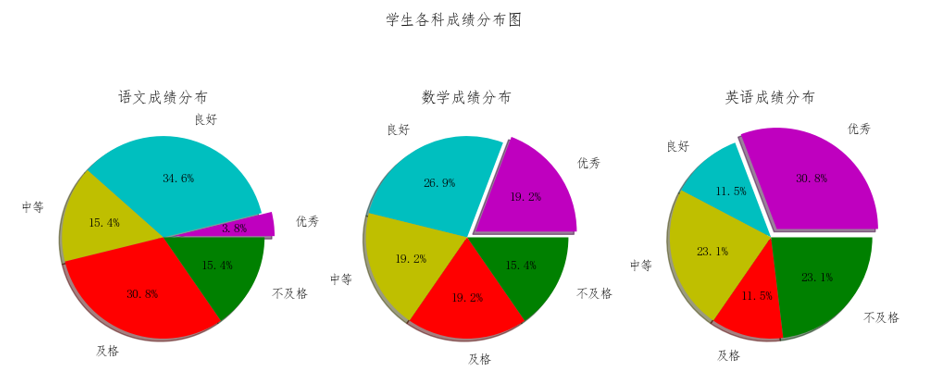
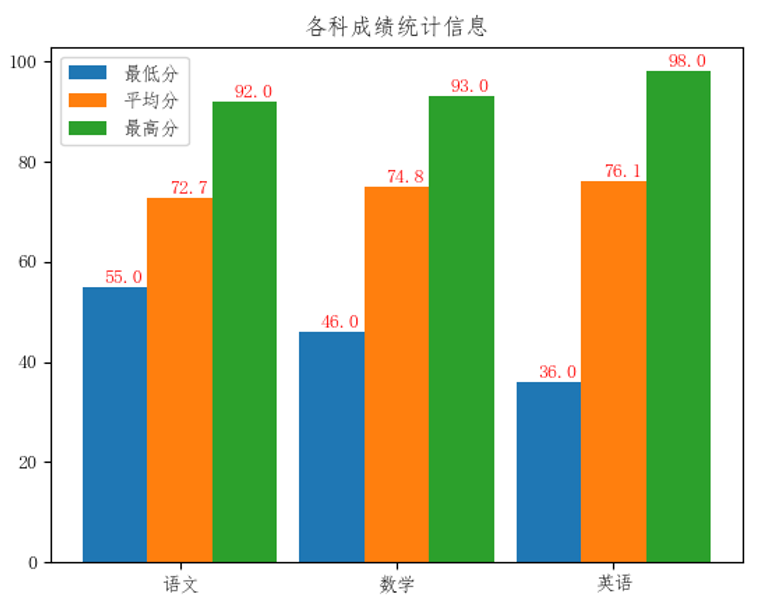
(3)编写程序分别用 条形图绘制出语文、数学、英语课程的最低分、最高分以及平均分。最终效果图如图所示,要求图中显示 图例、 标题,条形图上方显示相应数字,最终的图保存为 条形 .png。
代码参考
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
def get_datas(df, col):
level_1 = len(df[df[col] >= 90])
level_2 = len(df[(df[col] < 90) & (df[col] >= 80)])
level_3 = len(df[(df[col] < 80) & (df[col] >= 70)])
level_4 = len(df[(df[col] < 70) & (df[col] >= 60)])
level_5 = len(df[df[col] < 60])
return level_1, level_2, level_3, level_4, level_5
第一小题
d_1 = pd.read_excel("学生基本信息表.xls", skiprows=1)
d_2 = pd.read_excel("期末考试成绩表.xls", skiprows=1)
d_3 = pd.merge(d_1, d_2)
d_3 = d_3.sort_values(by=["总分", "英语"], ascending=False)
d_3.to_excel("学生期末考试成绩排名表.xls")
第二小题
results = []
titles = ["语文", "数学", "英语"]
plt.rcParams["font.family"] = "FangSong" # 设置字体
labels = ["优秀", "良好", "中等", "及格", "不及格"]
for title in titles:
results.append(get_datas(d_3, title))
plt.figure(figsize=(12, 5)) # 创建一个新图
plt.suptitle("学生各科成绩分布图")
for index, data in enumerate(results):
print(data)
plt.subplot(1, 3, index + 1)
plt.title(titles[index] + "成绩分布")
plt.pie(data, labels=labels, autopct='%.1f%%', shadow=True, labeldistance=1.2,
explode=(0.1, 0, 0, 0, 0), colors=['m', 'c', 'y', 'r', 'g'])
plt.savefig("饼状图")
第三小题
plt.figure() # 创建一个新图
min_datas =[np.min(d_3["语文"]), np.min(d_3["数学"]), np.min(d_3["英语"])]
mean_datas =[np.mean(d_3["语文"]), np.mean(d_3["数学"]), np.mean(d_3["英语"])]
max_datas =[np.max(d_3["语文"]), np.max(d_3["数学"]), np.max(d_3["英语"])]
kemu_datas = [min_datas, mean_datas, max_datas]
legends = ["最低分", "平均分", "最高分"]
x = range(len(titles))
plt.title("各科成绩统计信息")
for index, data in enumerate(kemu_datas):
plt.bar([i + 0.3 * index for i in x], height=data, width=0.3, label=legends[index])
for j, num in enumerate(data):
plt.text(0.3 * index + j, num + 1, "{:.1f}".format(num), ha="center", va="bottom", color="r")
plt.xticks([i + 0.3 for i in x], titles) # 绘制底部标签
plt.legend()
plt.savefig("条形图")
plt.show()
相关资源和代码可以关注微信公众号: Python资源分享,回复 0603即可获取。或者通过CSDN资源下载页下载:https://download.csdn.net/download/Dream_Gao1989/19358882
Original: https://blog.csdn.net/Dream_Gao1989/article/details/117506797
Author: 高成珍
Title: Python数据分析与可视化案例解析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/600253/
转载文章受原作者版权保护。转载请注明原作者出处!