

一·Pands的数据结构分析
Pandas的两个主要的数据结构:Senes和DataFrame
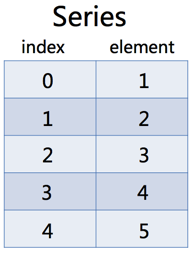
(一)1·Series是一个类似一维数组的对象,它能够保存任何类型的数据,主要由一组数据和与之相关的索引两部分构成。

2.通过传入一个列表来创建一个Series类对象:
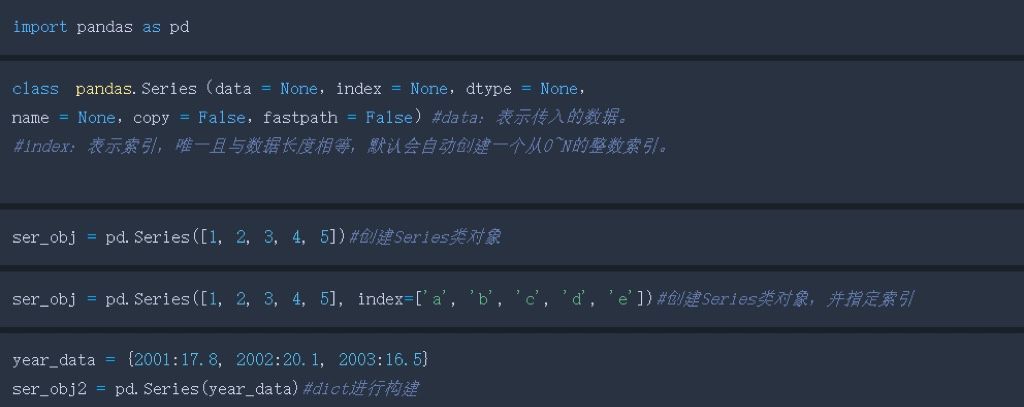
。
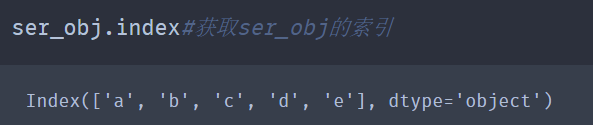
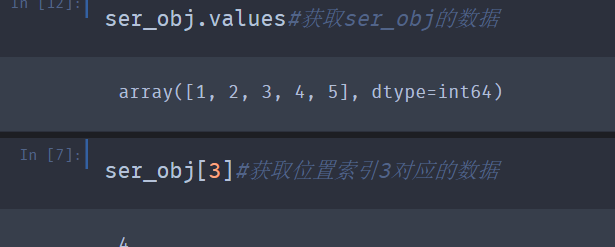
4.为了能方便地操作Series对象中的索引和数据,所以该对象提供了两个属性index和values分别进行获取。
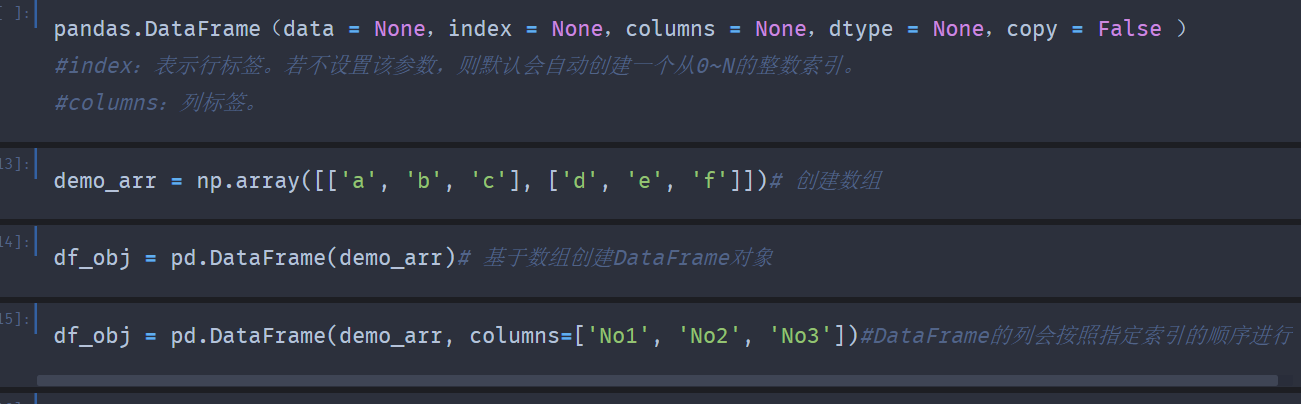
(二)1.DataFrame类对象可以使用以下构造方法创建:pandas.DataFrame(data = None,index = None,columns = None, dtype = None,copy = False )
2.通过传入数组来创建DataFrame类对象:
创建数组
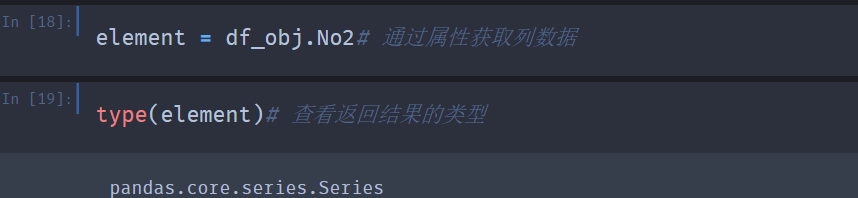
3,可以使用列索引的方式来获取一列数据,返回的结果是一个Series对象。
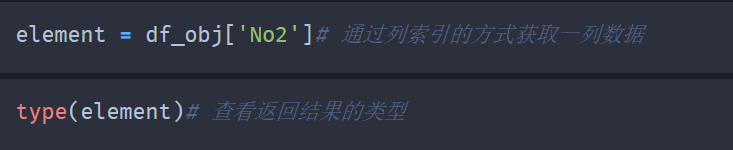
通过列索引的方式获取一列数据
4.删除某一列数据,则可以使用del语句实现。

reindex()方法的语法格式
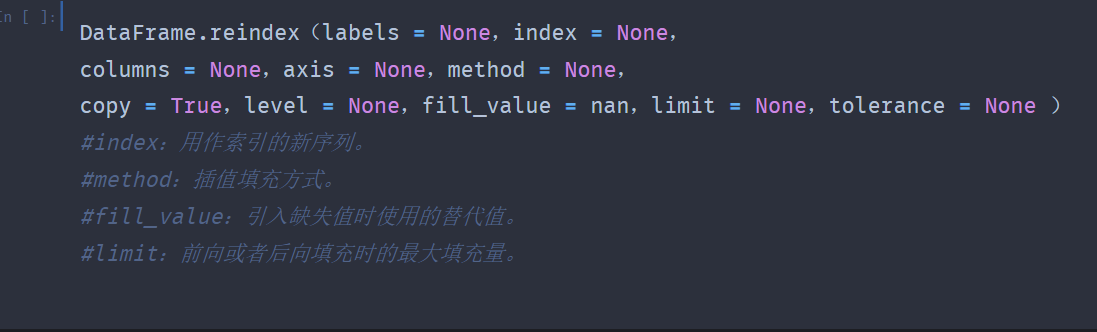
如果不想填充为NaN,则可以使用fill_value参数来指定缺失值。
ser_obj.reindex([‘a’, ‘b’, ‘c’, ‘d’, ‘e’, ‘f’],
fill_value = 6)
Series有关索引的用法类似于NumPy数组的索引,只不过Series的索引值不只是整数。如果我们希望获取某个数据,既可以通过索引的位置来获取,也可以使用索引名称来获取。
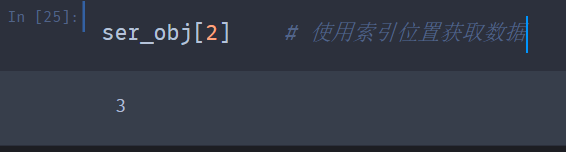
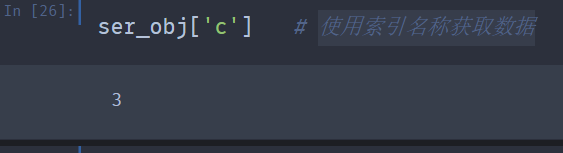
布尔型索引同样适用于Pandas,具体的用法跟数组的用法一样,将布尔型的数组索引作为模板筛选数据,返回与模板中True位置对应的元素。
ser_bool = ser_obj > 2
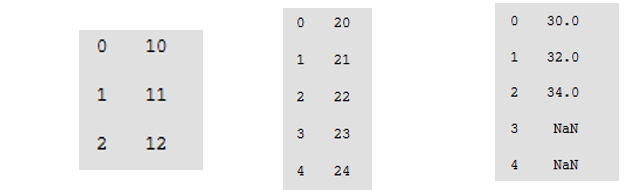
算数运算与数据对齐:
1.Pandas执行算术运算时,会先按照索引进行对齐,对齐以后再进行相应的运算,没有对齐的位置会用NaN进行补齐。

数据排序:
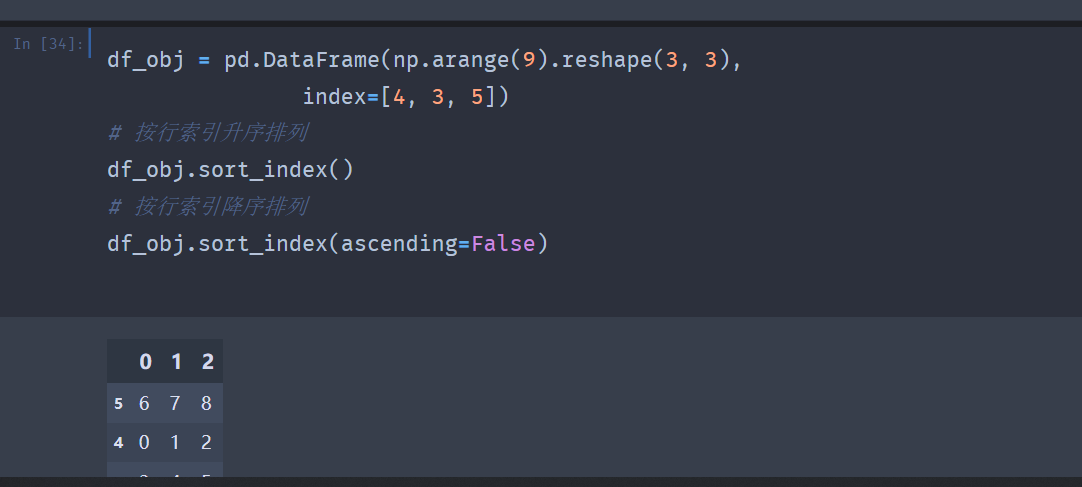
- Pandas中按索引排序使用的是sort_index()方法,该方法可以用行索引或者列索引进行排序。

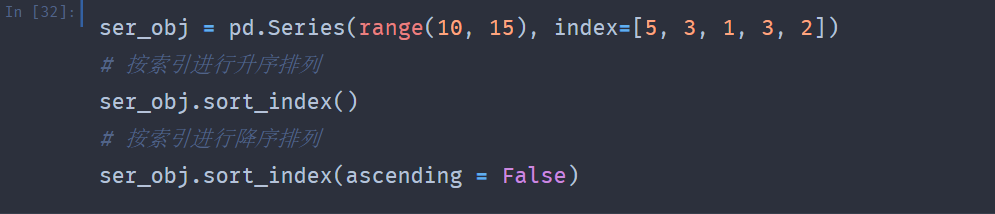
按索引对DataFrame进行分别排序,示例如下。
pandas中用来按值排序的方法为sort_values(),该方法的语法格式如下。

常用的统计计算
1.Pandas为我们提供了非常多的描述性统计分析的指标方法,比如总和、均值、最小值、最大值等。
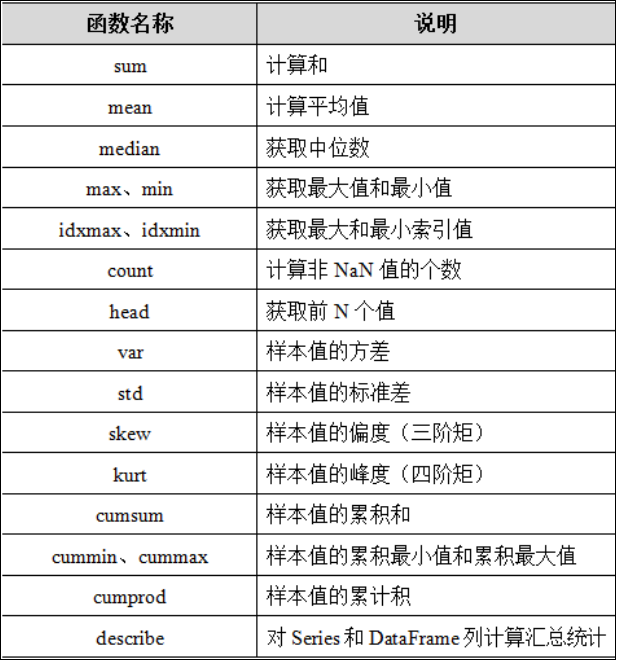
- 如果希望一次性输出多个统计指标,则我们可以调用describe()方法实现,语法格式如下。

层次化索引:
前面所涉及的Pandas对象都只有一层索引结构,又称为单层索引,层次化索引可以理解为单层索引的延伸,即在一个轴方向上具有多层索引。
前面所涉及的Pandas对象都只有一层索引结构,又称为单层索引,层次化索引可以理解为单层索引的延伸,即在一个轴方向上具有多层索引。
Series和DataFrame均可以实现层次化索引,最常见的方式是在构造方法的index参数中传入一个嵌套列表。
认识层次化索引
1.from_tuples()方法可以将包含若干个元组的列表转换为MultiIndex对象,其中元组的第一个元素作为外层索引,元组的第二个元素作为内层索引。

2.from_arrays()方法是将数组列表转换为MultiIndex对象,其中嵌套的第一个列表将作为外层索引,嵌套的第二个列表将作为内层索引。

层次化索引的操作
1.例:根据书籍统计表,创建一个具有多层索引的Series对象,示例如下:

2.如果商城管理员需要统计小说销售的情况,则可以从表中筛选出外层索引标签为小说的数据。

3.交换分层顺序是指交换外层索引和内层索引的位置。
4.在Pandas中,交换分层顺序的操作可以使用swaplevel()方法来完成

5.在Pandas中,交换分层顺序的操作可以使用swaplevel()方法来完成。
要想按照分层索引对数据排序,则可以通过sort_index()方法实现。

读写文本文件:
1.在进行数据分析时,通常不会将需要分析的数据直接写入到程序中,这样不仅造成程序代码臃肿,而且可用率很低。常用的解决方法是将待分析的数据存储到本地中,之后再对存储文件进行读取。
2.CSV文件是一种纯文本文件,可以使用任何文本编辑器进行编辑,它支持追加模式,节省内存开销。
3.to_csv()方法的功能是将数据写入到CSV文件中。

- read_csv()函数的作用是将CSV文件的数据读取出来,转换成DataFrame对象展示。

5.Text格式的文件也是比较常见的存储数据的方式,后缀名为”.txt”,它与上面提到的CSV文件都属于文本文件。
6.to_excel()方法的功能是将DataFrame对象写入到Excel工作表中。

read_excel()函数的作用是将Excel中的数据读取出来,转换成DataFrame展示。
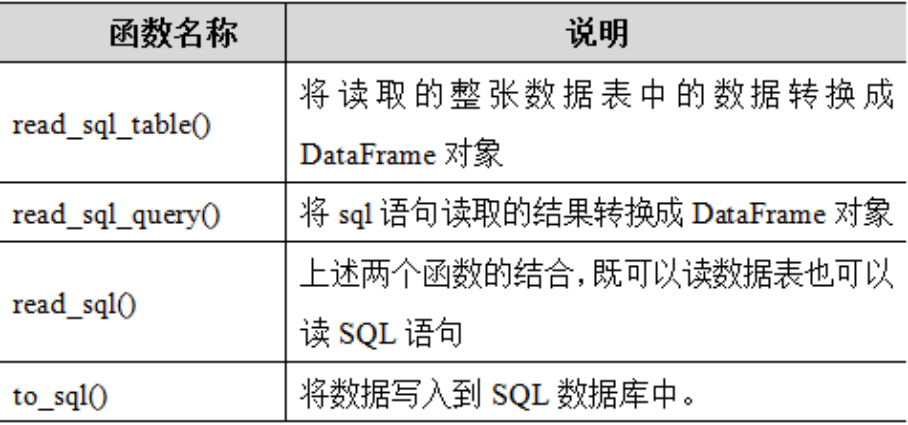
Pandas的io.sql模块中提供了常用的读写数据库函数。
Original: https://blog.csdn.net/m0_67668319/article/details/123307264
Author: m0_67668319
Title: Pandas
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/600171/
转载文章受原作者版权保护。转载请注明原作者出处!