

本课程是中国大学慕课《机器学习》的”KNN”章节的课后代码。
课程地址:
https://www.icourse163.org/course/WZU-1464096179
课程完整代码:
https://github.com/fengdu78/WZU-machine-learning-course
代码修改并注释:黄海广,haiguang2000@wzu.edu.cn
1.近邻法是基本且简单的分类与回归方法。近邻法的基本做法是:对给定的训练实例点和输入实例点,首先确定输入实例点的个最近邻训练实例点,然后利用这个训练实例点的类的多数来预测输入实例点的类。
2.近邻模型对应于基于训练数据集对特征空间的一个划分。近邻法中,当训练集、距离度量、值及分类决策规则确定后,其结果唯一确定。
3.近邻法三要素:距离度量、值的选择和分类决策规则。常用的距离度量是欧氏距离及更一般的 pL距离。值小时,近邻模型更复杂;值大时,近邻模型更简单。值的选择反映了对近似误差与估计误差之间的权衡,通常由交叉验证选择最优的。
常用的分类决策规则是多数表决,对应于经验风险最小化。
4.近邻法的实现需要考虑如何快速搜索k个最近邻点。 kd树是一种便于对k维空间中的数据进行快速检索的数据结构。kd树是二叉树,表示对维空间的一个划分,其每个结点对应于维空间划分中的一个超矩形区域。利用 kd树可以省去对大部分数据点的搜索, 从而减少搜索的计算量。
1.距离度量
在机器学习算法中,我们经常需要计算样本之间的相似度,通常的做法是计算样本之间的距离。
设和为两个向量,求它们之间的距离。
这里用Numpy实现,设和为 ndarray <numpy.ndarray></numpy.ndarray>,它们的shape都是 (N,)
为所求的距离,是个浮点数( float)。
import numpy as np #注意:运行代码时候需要导入NumPy库。
欧氏距离(Euclidean distance)
欧几里得度量(euclidean metric)(也称欧氏距离)是一个通常采用的距离定义,指在维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离。
距离公式:
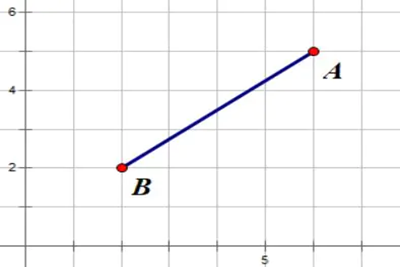

代码实现:
def euclidean(x, y):
return np.sqrt(np.sum((x - y)**2))
曼哈顿距离(Manhattan distance)
想象你在城市道路里,要从一个十字路口开车到另外一个十字路口,驾驶距离是两点间的直线距离吗?显然不是,除非你能穿越大楼。实际驾驶距离就是这个”曼哈顿距离”。而这也是曼哈顿距离名称的来源,曼哈顿距离也称为城市街区距离(City Block distance)。
距离公式:
代码实现:
def manhattan(x, y):
return np.sum(np.abs(x - y))
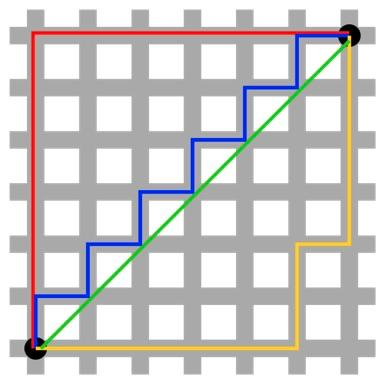
切比雪夫距离(Chebyshev distance)
在数学中,切比雪夫距离(Chebyshev distance)或是L∞度量,是向量空间中的一种度量,二个点之间的距离定义是其各坐标数值差绝对值的最大值。以数学的观点来看,切比雪夫距离是由一致范数(uniform norm)(或称为上确界范数)所衍生的度量,也是超凸度量(injective metric space)的一种。
距离公式:

若将国际象棋棋盘放在二维直角座标系中,格子的边长定义为1,座标的轴及轴和棋盘方格平行,原点恰落在某一格的中心点,则王从一个位置走到其他位置需要的步数恰为二个位置的切比雪夫距离,因此切比雪夫距离也称为棋盘距离。例如位置F6和位置E2的切比雪夫距离为4。任何一个不在棋盘边缘的位置,和周围八个位置的切比雪夫距离都是1。
代码实现:
def chebyshev(x, y):
return np.max(np.abs(x - y))
闵可夫斯基距离(Minkowski distance)
闵氏空间指狭义相对论中由一个时间维和三个空间维组成的时空,为俄裔德国数学家闵可夫斯基(H.Minkowski,1864-1909)最先表述。他的平坦空间(即假设没有重力,曲率为零的空间)的概念以及表示为特殊距离量的几何学是与狭义相对论的要求相一致的。闵可夫斯基空间不同于牛顿力学的平坦空间。取1或2时的闵氏距离是最为常用的,即为欧氏距离,而时则为曼哈顿距离。
当取无穷时的极限情况下,可以得到切比雪夫距离。
距离公式:
代码实现:
def minkowski(x, y, p):
return np.sum(np.abs(x - y)**p)**(1 / p)
汉明距离(Hamming distance)
汉明距离是使用在数据传输差错控制编码里面的,汉明距离是一个概念,它表示两个(相同长度)字对应位不同的数量,我们以表示两个字,之间的汉明距离。对两个字符串进行异或运算,并统计结果为1的个数,那么这个数就是汉明距离。
距离公式:
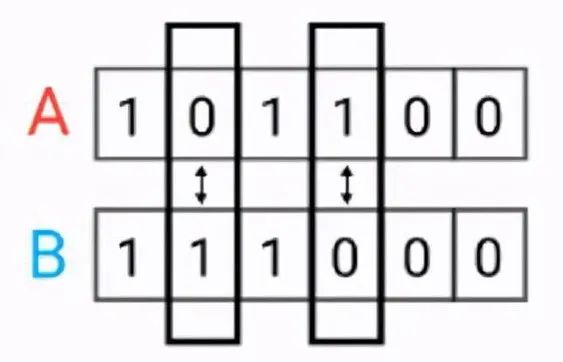
代码实现:
def hamming(x, y):
return np.sum(x != y) / len(x)
余弦相似度(Cosine Similarity)
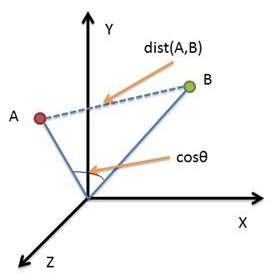
余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性。0度角的余弦值是1,而其他任何角度的余弦值都不大于1;并且其最小值是-1。从而两个向量之间的角度的余弦值确定两个向量是否大致指向相同的方向。两个向量有相同的指向时,余弦相似度的值为1;两个向量夹角为90°时,余弦相似度的值为0;两个向量指向完全相反的方向时,余弦相似度的值为-1。这结果是与向量的长度无关的,仅仅与向量的指向方向相关。余弦相似度通常用于正空间,因此给出的值为0到1之间。
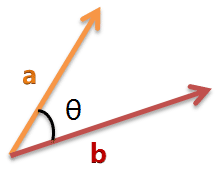
二维空间为例,上图的和是两个向量,我们要计算它们的夹角θ。余弦定理告诉我们,可以用下面的公式求得:
假定向量是
, 向量是 ,两个向量间的余弦值可以通过使用欧几里得点积公式求出:
如果向量和不是二维而是维,上述余弦的计算法仍然正确。假定和是两个维向量,是
, 是 ,则 与 的夹角余弦等于:
代码实现:
from math import *
def square_rooted(x):
return round(sqrt(sum([a*a for a in x])),3)
def cosine_similarity(x, y):
numerator = sum(a * b for a, b in zip(x, y))
denominator = square_rooted(x) * square_rooted(y)
return round(numerator / float(denominator), 3)
print(cosine_similarity([3, 45, 7, 2], [2, 54, 13, 15]))
0.972
KNN算法
1.近邻法是基本且简单的分类与回归方法。近邻法的基本做法是:对给定的训练实例点和输入实例点,首先确定输入实例点的个最近邻训练实例点,然后利用这个训练实例点的类的多数来预测输入实例点的类。
2.近邻模型对应于基于训练数据集对特征空间的一个划分。近邻法中,当训练集、距离度量、值及分类决策规则确定后,其结果唯一确定。
3.近邻法三要素:距离度量、值的选择和分类决策规则。常用的距离度量是欧氏距离。值小时,近邻模型更复杂;值大时,近邻模型更简单。值的选择反映了对近似误差与估计误差之间的权衡,通常由交叉验证选择最优的。
常用的分类决策规则是多数表决,对应于经验风险最小化。
4.近邻法的实现需要考虑如何快速搜索k个最近邻点。 kd树是一种便于对k维空间中的数据进行快速检索的数据结构。kd树是二叉树,表示对维空间的一个划分,其每个结点对应于维空间划分中的一个超矩形区域。利用 kd树可以省去对大部分数据点的搜索, 从而减少搜索的计算量。
python实现,遍历所有数据点,找出个距离最近的点的分类情况,少数服从多数
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
导入鸢尾花数据集
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
df.head()
sepal lengthsepal widthpetal lengthpetal widthlabel05.13.51.40.2014.93.01.40.2024.73.21.30.2034.63.11.50.2045.03.61.40.20
选择长和宽的数据进行可视化
plt.figure(figsize=(12, 8))
plt.scatter(df[:50]['sepal length'], df[:50]['sepal width'], label='0')
plt.scatter(df[50:100]['sepal length'], df[50:100]['sepal width'], label='1')
plt.xlabel('sepal length', fontsize=18)
plt.ylabel('sepal width', fontsize=18)
plt.legend()
plt.show()
Numpy实现
class KNN:
def __init__(self, X_train, y_train, n_neighbors=3, p=2):
"""
parameter: n_neighbors 临近点个数
parameter: p 距离度量
"""
self.n = n_neighbors
self.p = p
self.X_train = X_train
self.y_train = y_train
def predict(self, X):
# 取出n个点
knn_list = []
for i in range(self.n):
dist = np.linalg.norm(X - self.X_train[i], ord=self.p)
knn_list.append((dist, self.y_train[i]))
for i in range(self.n, len(self.X_train)):
max_index = knn_list.index(max(knn_list, key=lambda x: x[0]))
dist = np.linalg.norm(X - self.X_train[i], ord=self.p)
if knn_list[max_index][0] > dist:
knn_list[max_index] = (dist, self.y_train[i])
# 统计
knn = [k[-1] for k in knn_list]
count_pairs = Counter(knn)
# max_count = sorted(count_pairs, key=lambda x: x)[-1]
max_count = sorted(count_pairs.items(), key=lambda x: x[1])[-1][0]
return max_count
def score(self, X_test, y_test):
right_count = 0
n = 10
for X, y in zip(X_test, y_test):
label = self.predict(X)
if label == y:
right_count += 1
return right_count / len(X_test)
data = np.array(df.iloc[:150, [0, 1, -1]])
X, y = data[:,:-1], data[:,-1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
clf = KNN(X_train, y_train)
clf.score(X_test, y_test)
0.7777777777777778
test_point = [6.0, 3.0]
print('Test Point: {}'.format(clf.predict(test_point)))
Test Point: 2.0
Scikit-learn实例
sklearn.neighbors.KNeighborsClassifier
- n_neighbors: 临近点个数,即k的个数,默认是5
- p: 距离度量,默认
- algorithm: 近邻算法,可选{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}
- weights: 确定近邻的权重
- n_neighbors :int,optional(default = 5) 默认情况下kneighbors查询使用的邻居数。就是k-NN的k的值,选取最近的k个点。
- weights :str或callable,可选(默认=’uniform’) 默认是uniform,参数可以是uniform、distance,也可以是用户自己定义的函数。uniform是均等的权重,就说所有的邻近点的权重都是相等的。distance是不均等的权重,距离近的点比距离远的点的影响大。用户自定义的函数,接收距离的数组,返回一组维数相同的权重。
- algorithm :{‘auto’,’ball_tree’,’kd_tree’,’brute’},可选 快速k近邻搜索算法,默认参数为auto,可以理解为算法自己决定合适的搜索算法。除此之外,用户也可以自己指定搜索算法ball_tree、kd_tree、brute方法进行搜索,brute是蛮力搜索,也就是线性扫描,当训练集很大时,计算非常耗时。kd_tree,构造kd树存储数据以便对其进行快速检索的树形数据结构,kd树也就是数据结构中的二叉树。以中值切分构造的树,每个结点是一个超矩形,在维数小于20时效率高。ball tree是为了克服kd树高纬失效而发明的,其构造过程是以质心C和半径r分割样本空间,每个节点是一个超球体。
- leaf_size :int,optional(默认值= 30) 默认是30,这个是构造的kd树和ball树的大小。这个值的设置会影响树构建的速度和搜索速度,同样也影响着存储树所需的内存大小。需要根据问题的性质选择最优的大小。
- p :整数,可选(默认= 2) 距离度量公式。在上小结,我们使用欧氏距离公式进行距离度量。除此之外,还有其他的度量方法,例如曼哈顿距离。这个参数默认为2,也就是默认使用欧式距离公式进行距离度量。也可以设置为1,使用曼哈顿距离公式进行距离度量。
- metric :字符串或可调用,默认为’minkowski’ 用于距离度量,默认度量是minkowski,也就是p=2的欧氏距离(欧几里德度量)。
- metric_params :dict,optional(默认=None) 距离公式的其他关键参数,这个可以不管,使用默认的None即可。
- n_jobs :int或None,可选(默认=None) 并行处理设置。默认为1,临近点搜索并行工作数。如果为-1,那么CPU的所有cores都用于并行工作。
from sklearn.neighbors import KNeighborsClassifier
不同k(n_neighbors)值下的结果:
clf_sk = KNeighborsClassifier(n_neighbors=3)
clf_sk.fit(X_train, y_train)
KNeighborsClassifier(n_neighbors=3)
clf_sk.score(X_test, y_test)
0.7777777777777778
clf_sk = KNeighborsClassifier(n_neighbors=4)
clf_sk.fit(X_train, y_train)
clf_sk.score(X_test, y_test)
0.8
clf_sk = KNeighborsClassifier(n_neighbors=5)
clf_sk.fit(X_train, y_train)
clf_sk.score(X_test, y_test)
0.7555555555555555
自动调参吧,试试循环,找到最优的k值
best_score = 0.0
best_k = -1
for k in range(1, 11):
knn_clf = KNeighborsClassifier(n_neighbors=k)
knn_clf.fit(X_train, y_train)
score = knn_clf.score(X_test, y_test)
if score > best_score:
best_k = k
best_score = score
print("best_k = " + str(best_k))
print("best_score = " + str(best_score))
best_k = 2
best_score = 0.8
KD树的划分和搜索
KD树
KD树(K-Dimension Tree),,也可称之为维树,可以用更高的效率来对空间进行划分,并且其结构非常适合寻找最近邻居和碰撞检测。KD树是一种便于对维空间中的数据进行快速检索的数据结构。KD树是二叉树,表示对维空间的一个划分,其每个结点对应于维空间划分中的一个超矩形区域。利用KD树可以省去对大部分数据点的搜索,从而减少搜索的计算量。
KD树是二叉树,表示对𝑘维空间的一个划分(partition)。构造KD树相当于不断地用垂直于坐标轴的超平面将𝑘维空间切分,构成一系列的维超矩形区域。KD树的每个结点对应于一个维超矩形区域。
构造KD树的方法
构造根结点,使根结点对应于维空间中包含所有实例点的超矩形区域;
通过下面的递归方法,不断地对维空间进行切分,生成子结点。
在超矩形区域(结点)上选择一个坐标轴和在此坐标轴上的一个切分点,确定一个超平面,这个超平面通过选定的切分点并垂直于选定的坐标轴,将当前超矩形区域切分为左右两个子区域(子结点);
这时,实例被分到两个子区域。这个过程直到子区域内没有实例时终止(终止时的结点为叶结点)。
在此过程中,将实例保存在相应的结点上。
通常,依次选择坐标轴对空间切分,选择训练实例点在选定坐标轴上的中位数(median)为切分点,这样得到的KD树是平衡的。
注意,平衡的KD树搜索时的效率未必是最优的。
对于构建过程,有两个优化点:
- 选择切分维度
根据数据点在各维度上的分布情况,方差越大,分布越分散从方差大的维度开始切分,有较好的切分效果和平衡性。
- 确定中值点
预先对原始数据点在所有维度进行一次排序,存储下来,然后在后续的中值选择中,无须每次都对其子集进行排序,提升了性能。也可以从原始数据点中随机选择固定数目的点,然后对其进行排序,每次从这些样本点中取中值,来作为分割超平面。该方式在实践中被证明可以取得很好性能及很好的平衡性。
from collections import namedtuple
from pprint import pformat
class Node(namedtuple('Node', 'location left_child right_child')):
def __repr__(self):
return pformat(tuple(self))
# kd-tree每个结点中主要包含的数据结构如下
class KdNode(object):
def __init__(self, dom_elt, split, left, right):
self.dom_elt = dom_elt # k维向量节点(k维空间中的一个样本点)
self.split = split # 整数(进行分割维度的序号)
self.left = left # 该结点分割超平面左子空间构成的kd-tree
self.right = right # 该结点分割超平面右子空间构成的kd-tree
class KdTreeCreate(object):
def __init__(self, data):
k = len(data[0]) # 数据维度
def CreateNode(split, data_set): # 按第split维划分数据集exset创建KdNode
if not data_set: # 数据集为空
return None
# key参数的值为一个函数,此函数只有一个参数且返回一个值用来进行比较
# operator模块提供的itemgetter函数用于获取对象的哪些维的数据,参数为需要获取的数据在对象中的序号
#data_set.sort(key=itemgetter(split)) # 按要进行分割的那一维数据排序
data_set.sort(key=lambda x: x[split])
split_pos = len(data_set) // 2 # //为Python中的整数除法
median = data_set[split_pos] # 中位数分割点
split_next = (split + 1) % k # cycle coordinates
# 递归的创建kd树
return KdNode(
median,
split,
CreateNode(split_next, data_set[:split_pos]), # 创建左子树
CreateNode(split_next, data_set[split_pos + 1:])) # 创建右子树
self.root = CreateNode(0, data) # 从第0维分量开始构建kd树,返回根节点
# KDTree的前序遍历
def preorder(root):
print(root.dom_elt)
if root.left: # 节点不为空
preorder(root.left)
if root.right:
preorder(root.right)
# 对构建好的kd树进行搜索,寻找与目标点最近的样本点:
from math import sqrt
from collections import namedtuple
# 定义一个namedtuple,分别存放最近坐标点、最近距离和访问过的节点数
result = namedtuple("Result_tuple",
"nearest_point nearest_dist nodes_visited")
def find_nearest(tree, point):
k = len(point) # 数据维度
def travel(kd_node, target, max_dist):
if kd_node is None:
return result([0] * k, float("inf"),
0) # python中用float("inf")和float("-inf")表示正负无穷
nodes_visited = 1
s = kd_node.split # 进行分割的维度
pivot = kd_node.dom_elt # 进行分割的"轴"
if target[s]
from time import process_time
from random import random
# 产生一个k维随机向量,每维分量值在0~1之间
def random_point(k):
return [random() for _ in range(k)]
# 产生n个k维随机向量
def random_points(k, n):
return [random_point(k) for _ in range(n)]
N = 400000
t0 = process_time()
kd2 = KdTreeCreate(random_points(3, N)) # 构建包含四十万个3维空间样本点的kd树
ret2 = find_nearest(kd2, [0.1, 0.5, 0.8]) # 四十万个样本点中寻找离目标最近的点
t1 = process_time()
print("time: ", t1 - t0, "s")
print(ret2)
time: 6.28125 s
Result_tuple(nearest_point=[0.10173282609374357, 0.501003167941415, 0.8000047195369713], nearest_dist=0.002002262336426111, nodes_visited=36)
KD树的绘图代码
from operator import itemgetter
def kdtree(point_list, depth=0):
if len(point_list) == 0:
return None
# 选择"基于深度的轴",以便轴在所有有效值之间循环
# 只支持二维
axis = depth % 2
# Sort point list and choose median as pivot element
point_list.sort(key=itemgetter(axis))
median = len(point_list) // 2 # 选择中值点
# 创建节点并构造子树
return Node(
location = point_list[median],
left_child = kdtree(point_list[:median], depth + 1),
right_child = kdtree(point_list[median + 1:], depth + 1)
)
import matplotlib.pyplot as plt
# KD树的线宽
line_width = [4., 3.5, 3., 2.5, 2., 1.5, 1., .5, 0.3]
def plot_tree(tree, min_x, max_x, min_y, max_y, prev_node, branch, depth=0):
""" plot K-D tree
:param tree input tree to be plotted
:param min_x
:param max_x
:param min_y
:param max_y
:param prev_node parent's node
:param branch True if left, False if right
:param depth tree's depth
:return tree node
"""
cur_node = tree.location # 当前树节点
left_branch = tree.left_child # 左分支
right_branch = tree.right_child # 右分支
#根据树的深度设置线条的宽度
if depth > len(line_width) - 1:
ln_width = line_width[len(line_width) - 1]
else:
ln_width = line_width[depth]
k = len(cur_node)
axis = depth % k
# 画垂直分割线
if axis == 0:
if branch is not None and prev_node is not None:
if branch:
max_y = prev_node[1]
else:
min_y = prev_node[1]
plt.plot([cur_node[0], cur_node[0]], [min_y, max_y],
linestyle='-',
color='red',
linewidth=ln_width)
# 画水平分割线
elif axis == 1:
if branch is not None and prev_node is not None:
if branch:
max_x = prev_node[0]
else:
min_x = prev_node[0]
plt.plot([min_x, max_x], [cur_node[1], cur_node[1]],
linestyle='-',
color='blue',
linewidth=ln_width)
# 画当前节点
plt.plot(cur_node[0], cur_node[1], 'ko')
# 绘制当前节点的左分支和右分支
if left_branch is not None:
plot_tree(left_branch, min_x, max_x, min_y, max_y, cur_node, True,
depth + 1)
if right_branch is not None:
plot_tree(right_branch, min_x, max_x, min_y, max_y, cur_node, False,
depth + 1)
def create_diagram(tree, width, height, min_val, max_val, delta):
plt.figure("Kd Tree", figsize=(width, height))
plt.axis(
[min_val - delta, max_val + delta, min_val - delta, max_val + delta])
plt.grid(b=True, which='major', color='0.75', linestyle='--')
plt.xticks([i for i in range(min_val - delta, max_val + delta, 1)])
plt.yticks([i for i in range(min_val - delta, max_val + delta, 1)])
# 画出树
plot_tree(tree, min_val - delta, max_val + delta, min_val - delta,
max_val + delta, None, None)
plt.title('KD Tree')
def label_nodes(node, i):
loc = node.location
plt.text(loc[0] + 0.15, loc[1] + 0.15, str(i), fontsize=10)
if node.left_child:
i = label_nodes(node.left_child, i + 1)
if node.right_child:
i = label_nodes(node.right_child, i + 1)
return i
def draw_target(point, radius):
plt.plot(point[0], point[1], marker='o', color='#ff007f')
circle = plt.Circle(point,
0.3,
facecolor='#ff007f',
edgecolor='#ff007f',
alpha=0.5)
plt.gca().add_patch(circle)
# 围绕目标点绘制超球体
circle = plt.Circle(point,
radius,
facecolor='#ffd83d',
edgecolor='#ffd83d',
alpha=0.5)
plt.gca().add_patch(circle)
def draw_neighbors(point_list):
for point in point_list:
# 画出找到的最近的邻居
plt.plot(point[0], point[1], 'go')
circle = plt.Circle(point,
0.3,
facecolor='#33cc00',
edgecolor='#33cc00',
alpha=0.5)
plt.gca().add_patch(circle)
from graphviz import Digraph
def add_node(dot, node, parent_id=None, i=0, edge_label=''):
loc = node.location
node_id = str(i)
dot.node(node_id, f"{i}\n({loc[0]},{loc[1]})")
if parent_id:
dot.edge(parent_id, node_id, label=edge_label)
if node.left_child:
i = add_node(dot, node.left_child, node_id, i + 1, 'l')
if node.right_child:
i = add_node(dot, node.right_child, node_id, i + 1, 'r')
return i
def create_graph(tree):
dot = Digraph(comment='Kd-tree')
dot.attr('node',
fontsize='20',
shape='circle',
width='1',
fixedsize='true')
dot.attr('edge', arrowsize='0.7')
add_node(dot, tree)
return dot
# point_list = [[2,3],[5,7],[9,6],[4,5],[6,4],[7,2]]
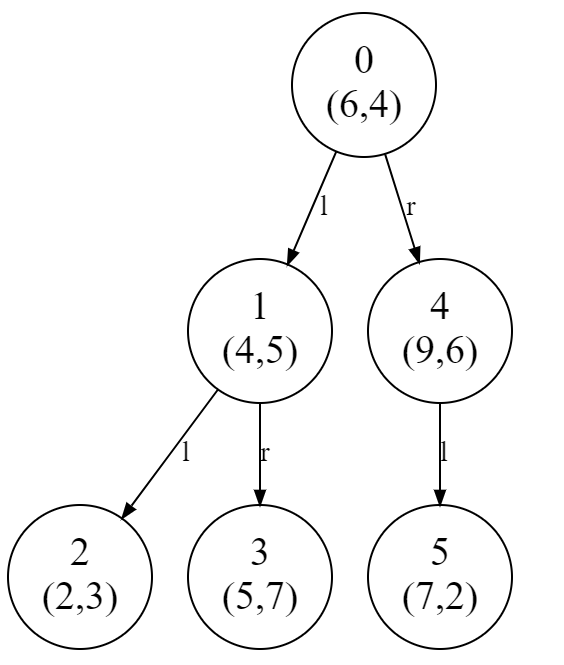
point_list1 = [(2,3),(5,7),(9,6),(4,5),(6,4),(7,2)]
tree = kdtree(point_list1)
print(tree)
create_graph(tree)
((6, 4),
((4, 5), ((2, 3), None, None), ((5, 7), None, None)),
((9, 6), ((7, 2), None, None), None))
max_int = 10000000
min_int = -max_int - 1
max_float = float('inf')
def get_val_range(point_list):
min_val = max_int
max_val = -max_int - 1
for point in point_list:
min_v = min(point)
if min_v max_val:
max_val = max_v
return (min_val, max_val)
min_val, max_val=get_val_range(point_list1)
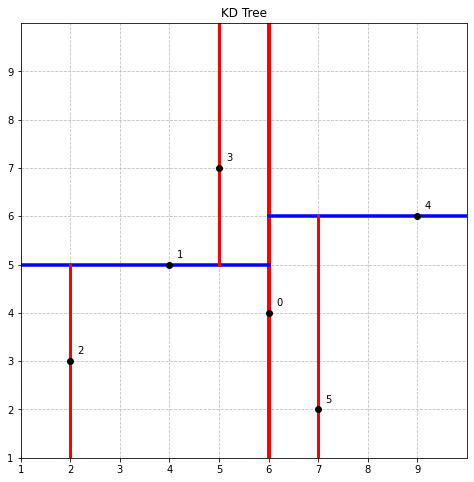
create_diagram(tree, 8., 8., min_val, max_val, 1)
label_nodes(tree, 0)
plt.show()
参考
- Prof. Andrew Ng. Machine Learning. Stanford University
- 李航,《统计学习方法》
机器学习练习6 KNN算法
代码修改并注释:黄海广,haiguang2000@wzu.edu.cn
1.近邻法是基本且简单的分类与回归方法。近邻法的基本做法是:对给定的训练实例点和输入实例点,首先确定输入实例点的个最近邻训练实例点,然后利用这个训练实例点的类的多数来预测输入实例点的类。
2.近邻模型对应于基于训练数据集对特征空间的一个划分。近邻法中,当训练集、距离度量、值及分类决策规则确定后,其结果唯一确定。
3.近邻法三要素:距离度量、值的选择和分类决策规则。常用的距离度量是欧氏距离及更一般的 pL距离。值小时,近邻模型更复杂;值大时,近邻模型更简单。值的选择反映了对近似误差与估计误差之间的权衡,通常由交叉验证选择最优的。
常用的分类决策规则是多数表决,对应于经验风险最小化。
4.近邻法的实现需要考虑如何快速搜索k个最近邻点。 kd树是一种便于对k维空间中的数据进行快速检索的数据结构。kd树是二叉树,表示对维空间的一个划分,其每个结点对应于维空间划分中的一个超矩形区域。利用 kd树可以省去对大部分数据点的搜索, 从而减少搜索的计算量。
1.距离度量
在机器学习算法中,我们经常需要计算样本之间的相似度,通常的做法是计算样本之间的距离。
设和为两个向量,求它们之间的距离。
这里用Numpy实现,设和为 ndarray <numpy.ndarray></numpy.ndarray>,它们的shape都是 (N,)
为所求的距离,是个浮点数( float)。
import numpy as np #注意:运行代码时候需要导入NumPy库。
欧氏距离(Euclidean distance)
欧几里得度量(euclidean metric)(也称欧氏距离)是一个通常采用的距离定义,指在维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离。
距离公式:
代码实现:
def euclidean(x, y):
return np.sqrt(np.sum((x - y)**2))
曼哈顿距离(Manhattan distance)
想象你在城市道路里,要从一个十字路口开车到另外一个十字路口,驾驶距离是两点间的直线距离吗?显然不是,除非你能穿越大楼。实际驾驶距离就是这个”曼哈顿距离”。而这也是曼哈顿距离名称的来源,曼哈顿距离也称为城市街区距离(City Block distance)。
距离公式:
代码实现:
def manhattan(x, y):
return np.sum(np.abs(x - y))
切比雪夫距离(Chebyshev distance)
在数学中,切比雪夫距离(Chebyshev distance)或是L∞度量,是向量空间中的一种度量,二个点之间的距离定义是其各坐标数值差绝对值的最大值。以数学的观点来看,切比雪夫距离是由一致范数(uniform norm)(或称为上确界范数)所衍生的度量,也是超凸度量(injective metric space)的一种。
距离公式:
若将国际象棋棋盘放在二维直角座标系中,格子的边长定义为1,座标的轴及轴和棋盘方格平行,原点恰落在某一格的中心点,则王从一个位置走到其他位置需要的步数恰为二个位置的切比雪夫距离,因此切比雪夫距离也称为棋盘距离。例如位置F6和位置E2的切比雪夫距离为4。任何一个不在棋盘边缘的位置,和周围八个位置的切比雪夫距离都是1。
代码实现:
def chebyshev(x, y):
return np.max(np.abs(x - y))
闵可夫斯基距离(Minkowski distance)
闵氏空间指狭义相对论中由一个时间维和三个空间维组成的时空,为俄裔德国数学家闵可夫斯基(H.Minkowski,1864-1909)最先表述。他的平坦空间(即假设没有重力,曲率为零的空间)的概念以及表示为特殊距离量的几何学是与狭义相对论的要求相一致的。闵可夫斯基空间不同于牛顿力学的平坦空间。取1或2时的闵氏距离是最为常用的,即为欧氏距离,而时则为曼哈顿距离。
当取无穷时的极限情况下,可以得到切比雪夫距离。
距离公式:
代码实现:
def minkowski(x, y, p):
return np.sum(np.abs(x - y)**p)**(1 / p)
汉明距离(Hamming distance)
汉明距离是使用在数据传输差错控制编码里面的,汉明距离是一个概念,它表示两个(相同长度)字对应位不同的数量,我们以表示两个字,之间的汉明距离。对两个字符串进行异或运算,并统计结果为1的个数,那么这个数就是汉明距离。
距离公式:
代码实现:
def hamming(x, y):
return np.sum(x != y) / len(x)
余弦相似度(Cosine Similarity)
余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性。0度角的余弦值是1,而其他任何角度的余弦值都不大于1;并且其最小值是-1。从而两个向量之间的角度的余弦值确定两个向量是否大致指向相同的方向。两个向量有相同的指向时,余弦相似度的值为1;两个向量夹角为90°时,余弦相似度的值为0;两个向量指向完全相反的方向时,余弦相似度的值为-1。这结果是与向量的长度无关的,仅仅与向量的指向方向相关。余弦相似度通常用于正空间,因此给出的值为0到1之间。
二维空间为例,上图的和是两个向量,我们要计算它们的夹角θ。余弦定理告诉我们,可以用下面的公式求得:
假定向量是
, 向量是 ,两个向量间的余弦值可以通过使用欧几里得点积公式求出:
如果向量和不是二维而是维,上述余弦的计算法仍然正确。假定和是两个维向量,是
, 是 ,则 与 的夹角余弦等于:
代码实现:
from math import *
def square_rooted(x):
return round(sqrt(sum([a*a for a in x])),3)
def cosine_similarity(x, y):
numerator = sum(a * b for a, b in zip(x, y))
denominator = square_rooted(x) * square_rooted(y)
return round(numerator / float(denominator), 3)
print(cosine_similarity([3, 45, 7, 2], [2, 54, 13, 15]))
0.972
KNN算法
1.近邻法是基本且简单的分类与回归方法。近邻法的基本做法是:对给定的训练实例点和输入实例点,首先确定输入实例点的个最近邻训练实例点,然后利用这个训练实例点的类的多数来预测输入实例点的类。
2.近邻模型对应于基于训练数据集对特征空间的一个划分。近邻法中,当训练集、距离度量、值及分类决策规则确定后,其结果唯一确定。
3.近邻法三要素:距离度量、值的选择和分类决策规则。常用的距离度量是欧氏距离。值小时,近邻模型更复杂;值大时,近邻模型更简单。值的选择反映了对近似误差与估计误差之间的权衡,通常由交叉验证选择最优的。
常用的分类决策规则是多数表决,对应于经验风险最小化。
4.近邻法的实现需要考虑如何快速搜索k个最近邻点。 kd树是一种便于对k维空间中的数据进行快速检索的数据结构。kd树是二叉树,表示对维空间的一个划分,其每个结点对应于维空间划分中的一个超矩形区域。利用 kd树可以省去对大部分数据点的搜索, 从而减少搜索的计算量。
python实现,遍历所有数据点,找出个距离最近的点的分类情况,少数服从多数
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
导入鸢尾花数据集
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
df.head()
sepal lengthsepal widthpetal lengthpetal widthlabel05.13.51.40.2014.93.01.40.2024.73.21.30.2034.63.11.50.2045.03.61.40.20
选择长和宽的数据进行可视化
plt.figure(figsize=(12, 8))
plt.scatter(df[:50]['sepal length'], df[:50]['sepal width'], label='0')
plt.scatter(df[50:100]['sepal length'], df[50:100]['sepal width'], label='1')
plt.xlabel('sepal length', fontsize=18)
plt.ylabel('sepal width', fontsize=18)
plt.legend()
plt.show()
Numpy实现
class KNN:
def __init__(self, X_train, y_train, n_neighbors=3, p=2):
"""
parameter: n_neighbors 临近点个数
parameter: p 距离度量
"""
self.n = n_neighbors
self.p = p
self.X_train = X_train
self.y_train = y_train
def predict(self, X):
# 取出n个点
knn_list = []
for i in range(self.n):
dist = np.linalg.norm(X - self.X_train[i], ord=self.p)
knn_list.append((dist, self.y_train[i]))
for i in range(self.n, len(self.X_train)):
max_index = knn_list.index(max(knn_list, key=lambda x: x[0]))
dist = np.linalg.norm(X - self.X_train[i], ord=self.p)
if knn_list[max_index][0] > dist:
knn_list[max_index] = (dist, self.y_train[i])
# 统计
knn = [k[-1] for k in knn_list]
count_pairs = Counter(knn)
# max_count = sorted(count_pairs, key=lambda x: x)[-1]
max_count = sorted(count_pairs.items(), key=lambda x: x[1])[-1][0]
return max_count
def score(self, X_test, y_test):
right_count = 0
n = 10
for X, y in zip(X_test, y_test):
label = self.predict(X)
if label == y:
right_count += 1
return right_count / len(X_test)
data = np.array(df.iloc[:150, [0, 1, -1]])
X, y = data[:,:-1], data[:,-1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
clf = KNN(X_train, y_train)
clf.score(X_test, y_test)
0.7777777777777778
test_point = [6.0, 3.0]
print('Test Point: {}'.format(clf.predict(test_point)))
Test Point: 2.0
Scikit-learn实例
sklearn.neighbors.KNeighborsClassifier
- n_neighbors: 临近点个数,即k的个数,默认是5
- p: 距离度量,默认
- algorithm: 近邻算法,可选{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}
- weights: 确定近邻的权重
- n_neighbors :int,optional(default = 5) 默认情况下kneighbors查询使用的邻居数。就是k-NN的k的值,选取最近的k个点。
- weights :str或callable,可选(默认=’uniform’) 默认是uniform,参数可以是uniform、distance,也可以是用户自己定义的函数。uniform是均等的权重,就说所有的邻近点的权重都是相等的。distance是不均等的权重,距离近的点比距离远的点的影响大。用户自定义的函数,接收距离的数组,返回一组维数相同的权重。
- algorithm :{‘auto’,’ball_tree’,’kd_tree’,’brute’},可选 快速k近邻搜索算法,默认参数为auto,可以理解为算法自己决定合适的搜索算法。除此之外,用户也可以自己指定搜索算法ball_tree、kd_tree、brute方法进行搜索,brute是蛮力搜索,也就是线性扫描,当训练集很大时,计算非常耗时。kd_tree,构造kd树存储数据以便对其进行快速检索的树形数据结构,kd树也就是数据结构中的二叉树。以中值切分构造的树,每个结点是一个超矩形,在维数小于20时效率高。ball tree是为了克服kd树高纬失效而发明的,其构造过程是以质心C和半径r分割样本空间,每个节点是一个超球体。
- leaf_size :int,optional(默认值= 30) 默认是30,这个是构造的kd树和ball树的大小。这个值的设置会影响树构建的速度和搜索速度,同样也影响着存储树所需的内存大小。需要根据问题的性质选择最优的大小。
- p :整数,可选(默认= 2) 距离度量公式。在上小结,我们使用欧氏距离公式进行距离度量。除此之外,还有其他的度量方法,例如曼哈顿距离。这个参数默认为2,也就是默认使用欧式距离公式进行距离度量。也可以设置为1,使用曼哈顿距离公式进行距离度量。
- metric :字符串或可调用,默认为’minkowski’ 用于距离度量,默认度量是minkowski,也就是p=2的欧氏距离(欧几里德度量)。
- metric_params :dict,optional(默认=None) 距离公式的其他关键参数,这个可以不管,使用默认的None即可。
- n_jobs :int或None,可选(默认=None) 并行处理设置。默认为1,临近点搜索并行工作数。如果为-1,那么CPU的所有cores都用于并行工作。
from sklearn.neighbors import KNeighborsClassifier
不同k(n_neighbors)值下的结果:
clf_sk = KNeighborsClassifier(n_neighbors=3)
clf_sk.fit(X_train, y_train)
KNeighborsClassifier(n_neighbors=3)
clf_sk.score(X_test, y_test)
0.7777777777777778
clf_sk = KNeighborsClassifier(n_neighbors=4)
clf_sk.fit(X_train, y_train)
clf_sk.score(X_test, y_test)
0.8
clf_sk = KNeighborsClassifier(n_neighbors=5)
clf_sk.fit(X_train, y_train)
clf_sk.score(X_test, y_test)
0.7555555555555555
自动调参吧,试试循环,找到最优的k值
best_score = 0.0
best_k = -1
for k in range(1, 11):
knn_clf = KNeighborsClassifier(n_neighbors=k)
knn_clf.fit(X_train, y_train)
score = knn_clf.score(X_test, y_test)
if score > best_score:
best_k = k
best_score = score
print("best_k = " + str(best_k))
print("best_score = " + str(best_score))
best_k = 2
best_score = 0.8
KD树的划分和搜索
KD树
KD树(K-Dimension Tree),,也可称之为维树,可以用更高的效率来对空间进行划分,并且其结构非常适合寻找最近邻居和碰撞检测。KD树是一种便于对维空间中的数据进行快速检索的数据结构。KD树是二叉树,表示对维空间的一个划分,其每个结点对应于维空间划分中的一个超矩形区域。利用KD树可以省去对大部分数据点的搜索,从而减少搜索的计算量。
KD树是二叉树,表示对𝑘维空间的一个划分(partition)。构造KD树相当于不断地用垂直于坐标轴的超平面将𝑘维空间切分,构成一系列的维超矩形区域。KD树的每个结点对应于一个维超矩形区域。
构造KD树的方法
构造根结点,使根结点对应于维空间中包含所有实例点的超矩形区域;
通过下面的递归方法,不断地对维空间进行切分,生成子结点。
在超矩形区域(结点)上选择一个坐标轴和在此坐标轴上的一个切分点,确定一个超平面,这个超平面通过选定的切分点并垂直于选定的坐标轴,将当前超矩形区域切分为左右两个子区域(子结点);
这时,实例被分到两个子区域。这个过程直到子区域内没有实例时终止(终止时的结点为叶结点)。
在此过程中,将实例保存在相应的结点上。
通常,依次选择坐标轴对空间切分,选择训练实例点在选定坐标轴上的中位数(median)为切分点,这样得到的KD树是平衡的。
注意,平衡的KD树搜索时的效率未必是最优的。
对于构建过程,有两个优化点:
- 选择切分维度
根据数据点在各维度上的分布情况,方差越大,分布越分散从方差大的维度开始切分,有较好的切分效果和平衡性。
- 确定中值点
预先对原始数据点在所有维度进行一次排序,存储下来,然后在后续的中值选择中,无须每次都对其子集进行排序,提升了性能。也可以从原始数据点中随机选择固定数目的点,然后对其进行排序,每次从这些样本点中取中值,来作为分割超平面。该方式在实践中被证明可以取得很好性能及很好的平衡性。
from collections import namedtuple
from pprint import pformat
class Node(namedtuple('Node', 'location left_child right_child')):
def __repr__(self):
return pformat(tuple(self))
# kd-tree每个结点中主要包含的数据结构如下
class KdNode(object):
def __init__(self, dom_elt, split, left, right):
self.dom_elt = dom_elt # k维向量节点(k维空间中的一个样本点)
self.split = split # 整数(进行分割维度的序号)
self.left = left # 该结点分割超平面左子空间构成的kd-tree
self.right = right # 该结点分割超平面右子空间构成的kd-tree
class KdTreeCreate(object):
def __init__(self, data):
k = len(data[0]) # 数据维度
def CreateNode(split, data_set): # 按第split维划分数据集exset创建KdNode
if not data_set: # 数据集为空
return None
# key参数的值为一个函数,此函数只有一个参数且返回一个值用来进行比较
# operator模块提供的itemgetter函数用于获取对象的哪些维的数据,参数为需要获取的数据在对象中的序号
#data_set.sort(key=itemgetter(split)) # 按要进行分割的那一维数据排序
data_set.sort(key=lambda x: x[split])
split_pos = len(data_set) // 2 # //为Python中的整数除法
median = data_set[split_pos] # 中位数分割点
split_next = (split + 1) % k # cycle coordinates
# 递归的创建kd树
return KdNode(
median,
split,
CreateNode(split_next, data_set[:split_pos]), # 创建左子树
CreateNode(split_next, data_set[split_pos + 1:])) # 创建右子树
self.root = CreateNode(0, data) # 从第0维分量开始构建kd树,返回根节点
# KDTree的前序遍历
def preorder(root):
print(root.dom_elt)
if root.left: # 节点不为空
preorder(root.left)
if root.right:
preorder(root.right)
# 对构建好的kd树进行搜索,寻找与目标点最近的样本点:
from math import sqrt
from collections import namedtuple
# 定义一个namedtuple,分别存放最近坐标点、最近距离和访问过的节点数
result = namedtuple("Result_tuple",
"nearest_point nearest_dist nodes_visited")
def find_nearest(tree, point):
k = len(point) # 数据维度
def travel(kd_node, target, max_dist):
if kd_node is None:
return result([0] * k, float("inf"),
0) # python中用float("inf")和float("-inf")表示正负无穷
nodes_visited = 1
s = kd_node.split # 进行分割的维度
pivot = kd_node.dom_elt # 进行分割的"轴"
if target[s]
from time import process_time
from random import random
# 产生一个k维随机向量,每维分量值在0~1之间
def random_point(k):
return [random() for _ in range(k)]
# 产生n个k维随机向量
def random_points(k, n):
return [random_point(k) for _ in range(n)]
N = 400000
t0 = process_time()
kd2 = KdTreeCreate(random_points(3, N)) # 构建包含四十万个3维空间样本点的kd树
ret2 = find_nearest(kd2, [0.1, 0.5, 0.8]) # 四十万个样本点中寻找离目标最近的点
t1 = process_time()
print("time: ", t1 - t0, "s")
print(ret2)
time: 6.28125 s
Result_tuple(nearest_point=[0.10173282609374357, 0.501003167941415, 0.8000047195369713], nearest_dist=0.002002262336426111, nodes_visited=36)
KD树的绘图代码
from operator import itemgetter
def kdtree(point_list, depth=0):
if len(point_list) == 0:
return None
# 选择"基于深度的轴",以便轴在所有有效值之间循环
# 只支持二维
axis = depth % 2
# Sort point list and choose median as pivot element
point_list.sort(key=itemgetter(axis))
median = len(point_list) // 2 # 选择中值点
# 创建节点并构造子树
return Node(
location = point_list[median],
left_child = kdtree(point_list[:median], depth + 1),
right_child = kdtree(point_list[median + 1:], depth + 1)
)
import matplotlib.pyplot as plt
# KD树的线宽
line_width = [4., 3.5, 3., 2.5, 2., 1.5, 1., .5, 0.3]
def plot_tree(tree, min_x, max_x, min_y, max_y, prev_node, branch, depth=0):
""" plot K-D tree
:param tree input tree to be plotted
:param min_x
:param max_x
:param min_y
:param max_y
:param prev_node parent's node
:param branch True if left, False if right
:param depth tree's depth
:return tree node
"""
cur_node = tree.location # 当前树节点
left_branch = tree.left_child # 左分支
right_branch = tree.right_child # 右分支
#根据树的深度设置线条的宽度
if depth > len(line_width) - 1:
ln_width = line_width[len(line_width) - 1]
else:
ln_width = line_width[depth]
k = len(cur_node)
axis = depth % k
# 画垂直分割线
if axis == 0:
if branch is not None and prev_node is not None:
if branch:
max_y = prev_node[1]
else:
min_y = prev_node[1]
plt.plot([cur_node[0], cur_node[0]], [min_y, max_y],
linestyle='-',
color='red',
linewidth=ln_width)
# 画水平分割线
elif axis == 1:
if branch is not None and prev_node is not None:
if branch:
max_x = prev_node[0]
else:
min_x = prev_node[0]
plt.plot([min_x, max_x], [cur_node[1], cur_node[1]],
linestyle='-',
color='blue',
linewidth=ln_width)
# 画当前节点
plt.plot(cur_node[0], cur_node[1], 'ko')
# 绘制当前节点的左分支和右分支
if left_branch is not None:
plot_tree(left_branch, min_x, max_x, min_y, max_y, cur_node, True,
depth + 1)
if right_branch is not None:
plot_tree(right_branch, min_x, max_x, min_y, max_y, cur_node, False,
depth + 1)
def create_diagram(tree, width, height, min_val, max_val, delta):
plt.figure("Kd Tree", figsize=(width, height))
plt.axis(
[min_val - delta, max_val + delta, min_val - delta, max_val + delta])
plt.grid(b=True, which='major', color='0.75', linestyle='--')
plt.xticks([i for i in range(min_val - delta, max_val + delta, 1)])
plt.yticks([i for i in range(min_val - delta, max_val + delta, 1)])
# 画出树
plot_tree(tree, min_val - delta, max_val + delta, min_val - delta,
max_val + delta, None, None)
plt.title('KD Tree')
def label_nodes(node, i):
loc = node.location
plt.text(loc[0] + 0.15, loc[1] + 0.15, str(i), fontsize=10)
if node.left_child:
i = label_nodes(node.left_child, i + 1)
if node.right_child:
i = label_nodes(node.right_child, i + 1)
return i
def draw_target(point, radius):
plt.plot(point[0], point[1], marker='o', color='#ff007f')
circle = plt.Circle(point,
0.3,
facecolor='#ff007f',
edgecolor='#ff007f',
alpha=0.5)
plt.gca().add_patch(circle)
# 围绕目标点绘制超球体
circle = plt.Circle(point,
radius,
facecolor='#ffd83d',
edgecolor='#ffd83d',
alpha=0.5)
plt.gca().add_patch(circle)
def draw_neighbors(point_list):
for point in point_list:
# 画出找到的最近的邻居
plt.plot(point[0], point[1], 'go')
circle = plt.Circle(point,
0.3,
facecolor='#33cc00',
edgecolor='#33cc00',
alpha=0.5)
plt.gca().add_patch(circle)
from graphviz import Digraph
def add_node(dot, node, parent_id=None, i=0, edge_label=''):
loc = node.location
node_id = str(i)
dot.node(node_id, f"{i}\n({loc[0]},{loc[1]})")
if parent_id:
dot.edge(parent_id, node_id, label=edge_label)
if node.left_child:
i = add_node(dot, node.left_child, node_id, i + 1, 'l')
if node.right_child:
i = add_node(dot, node.right_child, node_id, i + 1, 'r')
return i
def create_graph(tree):
dot = Digraph(comment='Kd-tree')
dot.attr('node',
fontsize='20',
shape='circle',
width='1',
fixedsize='true')
dot.attr('edge', arrowsize='0.7')
add_node(dot, tree)
return dot
# point_list = [[2,3],[5,7],[9,6],[4,5],[6,4],[7,2]]
point_list1 = [(2,3),(5,7),(9,6),(4,5),(6,4),(7,2)]
tree = kdtree(point_list1)
print(tree)
create_graph(tree)
((6, 4),
((4, 5), ((2, 3), None, None), ((5, 7), None, None)),
((9, 6), ((7, 2), None, None), None))
svg
max_int = 10000000
min_int = -max_int - 1
max_float = float('inf')
def get_val_range(point_list):
min_val = max_int
max_val = -max_int - 1
for point in point_list:
min_v = min(point)
if min_v max_val:
max_val = max_v
return (min_val, max_val)
min_val, max_val=get_val_range(point_list1)
create_diagram(tree, 8., 8., min_val, max_val, 1)
label_nodes(tree, 0)
plt.show()
参考
- Prof. Andrew Ng. Machine Learning. Stanford University
- 李航,《统计学习方法》 叶斯估计。
undefined
undefined
undefined
undefined
undefined
往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载黄海广老师《机器学习课程》视频课黄海广老师《机器学习课程》711页完整版课件
本站qq群955171419,加入微信群请扫码:

Original: https://blog.csdn.net/fengdu78/article/details/121668444
Author: 风度78
Title: 【机器学习】KNN算法代码练习
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/599921/
转载文章受原作者版权保护。转载请注明原作者出处!