

公众号:尤而小屋
作者:Peter
编辑:Peter
大家好,我是Peter~
本文主要是记录Pandas中单层索引的一些基本操作。


; 10种索引
下面简单回顾下之前学习创建的10种索引:
pd.Index
In [1]:
import pandas as pd
import numpy as np
In [2]:
指定类型和名称
s1 = pd.Index([1,2,3,4,5,6,7],
dtype="int",
name="Peter")
s1
Out[2]:
Int64Index([1, 2, 3, 4, 5, 6, 7], dtype='int64', name='Peter')
pd.RangeIndex
指定整数范围内的不可变索引
In [3]:
s2 = pd.RangeIndex(0,20,2)
s2
Out[3]:
RangeIndex(start=0, stop=20, step=2)
pd.Int64Index
64位整数型索引
In [4]:
s3 = pd.Int64Index([1,2,3,4,5,6,7,8],name="Peter")
s3
Out[4]:
Int64Index([1, 2, 3, 4, 5, 6, 7, 8], dtype='int64', name='Peter')
pd.UInt64Index
无符号整数索引
In [5]:
s4 = pd.UInt64Index([1, 2.0, 3, 4],name="Tom")
s4
Out[5]:
UInt64Index([1, 2, 3, 4], dtype='uint64', name='Tom')
pd.Float64Index
64位浮点型的索引
In [6]:
s5 = pd.Float64Index([1.5, 2.4, 3.7, 4.9],name="peter")
s5
Out[6]:
Float64Index([1.5, 2.4, 3.7, 4.9], dtype='float64', name='peter')
pd.IntervalIndex
新的间隔索引 IntervalIndex 通常使用 interval_range()函数来进行构造,它使用的是数据或者数值区间,基本用法:
In [7]:
s6 = pd.interval_range(start=0, end=6, closed="left")
s6
Out[7]:
IntervalIndex([[0, 1), [1, 2), [2, 3), [3, 4), [4, 5), [5, 6)],
closed='left',
dtype='interval[int64]')
pd.CategoricalIndex
In [8]:
s7 = pd.CategoricalIndex(
# 待排序的数据
["S","M","L","XS","M","L","S","M","L","XL"],
# 指定分类顺序
categories=["XS","S","M","L","XL"],
# 排需
ordered=True,
# 索引名字
name="category"
)
s7
Out[8]:
CategoricalIndex(['S', 'M', 'L', 'XS', 'M', 'L', 'S', 'M', 'L', 'XL'],
categories=['XS', 'S', 'M', 'L', 'XL'],
ordered=True,
name='category',
dtype='category')
pd.DatetimeIndex
以时间和日期作为索引,通过date_range函数来生成,具体例子为:
In [9]:
日期作为索引,D代表天
s8 = pd.date_range("2022-01-01",periods=6, freq="D")
s8
Out[9]:
DatetimeIndex(['2022-01-01', '2022-01-02', '2022-01-03',
'2022-01-04','2022-01-05', '2022-01-06'],
dtype='datetime64[ns]', freq='D')
pd.PeriodIndex
pd.PeriodIndex是一个专门针对周期性数据的索引,方便针对具有一定周期的数据进行处理,具体用法如下:
In [10]:
s9 = pd.PeriodIndex(['2022-01-01', '2022-01-02',
'2022-01-03', '2022-01-04'],
freq = '2H')
s9
Out[10]:
PeriodIndex(['2022-01-01 00:00', '2022-01-02 00:00',
'2022-01-03 00:00', '2022-01-04 00:00'],
dtype='period[2H]', freq='2H')
pd.TimedeltaIndex
In [11]:
data = pd.timedelta_range(start='1 day', end='3 days', freq='6H')
data
Out[11]:
TimedeltaIndex(['1 days 00:00:00', '1 days 06:00:00', '1 days 12:00:00',
'1 days 18:00:00', '2 days 00:00:00', '2 days 06:00:00',
'2 days 12:00:00', '2 days 18:00:00', '3 days 00:00:00'],
dtype='timedelta64[ns]', freq='6H')
In [12]:
s10 = pd.TimedeltaIndex(data)
s10
Out[12]:
TimedeltaIndex(['1 days 00:00:00', '1 days 06:00:00', '1 days 12:00:00',
'1 days 18:00:00', '2 days 00:00:00', '2 days 06:00:00',
'2 days 12:00:00', '2 days 18:00:00', '3 days 00:00:00'],
dtype='timedelta64[ns]', freq='6H')
操作1:读取文件时自动生成索引
默认情况下,pandas以0到 len(df)-1 的自然数为索引
In [13]:
df = pd.read_csv("student.csv")
df

df.index
RangeIndex(start=0, stop=4, step=1)
我们可以指定某个字段作为索引:
操作2:读取数据时指定索引
在读取文件的时候可以指定一个或者多个字段作为索引:
In [15]:
df1 = pd.read_csv("student.csv", index_col="name")
df1

pd.read_csv("student.csv", index_col=0)

我们查看具体的索引:
In [17]:
df1.index
Out[17]:
Index(['xiaoming', 'xiaozhou', 'peter', 'mike'], dtype='object', name='name')
同时指定多个字段作为索引:
In [18]:
df2 = pd.read_csv("student.csv", index_col=["name","sex"])
df2

我们发现此时数据框df2的索引是一个多层索引MultiIndex
In [20]:
df2.index
Out[20]:
MultiIndex([('xiaoming', 'male'),
('xiaozhou', 'female'),
( 'peter', 'male'),
( 'mike', 'male')],
names=['name', 'sex'])
操作3:指定索引set_index
在读取之后可以指定字段作为索引
指定单个索引

比如,我们把name字段作为索引:使用的是set_index函数
In [23]:
df.set_index("name")
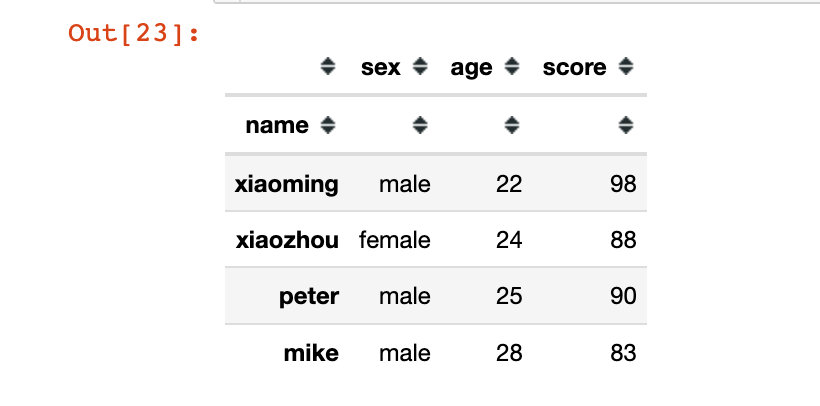
我们发现原始的df是没有变化的:

如果想直接改变df,有两种方法:
1、赋值法
通过对比赋值前后df的id,我们发现它们是不同的:

在Python内部其实创建了两个不同的对象,开辟了不同的内存地址,只不过对象的刚好都是df而已
2、原地修改
第二种方法是通过set_index的inplace参数,原地修改df:
In [28]:
id(df) # 改变前
Out[28]:
4633094992
In [29]:
df.set_index("name",inplace=True) # 原地修改
In [30]:
id(df) # 改变后
Out[30]:
4633094992
我们发现:修改后df和原来是一样的
指定多个索引
1、赋值改变

2、原地修改

; 指定Series数据为索引


其他操作
原来的列字段仍然保存:

原来的索引仍然保留:

Original: https://blog.csdn.net/qq_25443541/article/details/124185158
Author: 尤尔小屋的猫
Title: Pandas索引基本操作
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/599897/
转载文章受原作者版权保护。转载请注明原作者出处!