

卡尔曼滤波(KF)和扩展卡尔曼滤波(EKF)是最常用的滤波器优化算法,本文主要是介绍一下卡尔曼滤波,从国外的一篇博客翻译过来的,如果有翻译的不当的地方,烦请指出,最后会给出原文链接,有大佬英文不错的话,推荐直接看原文。
简介卡尔曼滤波
为了更好的说明卡尔曼滤波,假设有一个小机器人在一片树林里,它需要准确的知道自己的位置以便于能够向着目标点移动。


机器人的状态向量(位置和速度)用x ⃗ k \vec{x}{k}x k 表示,
x ⃗ k = ( p ⃗ , v ⃗ ) (1) \vec{x}{k}=(\vec{p},\vec{v}) \tag{1}x k =(p ,v )(1 )
注意状态向量可以是任何东西,只要是能够表示系统当前状态的量,都可以放在状态向量中。在我们的例子中,状态向量是位置和速度,在其他工程中,需要滤波的量可以是油罐中的油量、发动机的温度或者手指在触摸板上的位置,万物皆可模型化,就意味着万物皆可卡尔曼。
机器人是带有一个精度10m的GPS定位,但是在实际情况中,这个精度无法满足机器人的定位需求,森林里面有许多悬崖峭壁,机器人的位置信息哪怕偏差了十厘米,都有可能掉下悬崖,因此仅仅依靠GPS定位信息是无法满足机器人的定位需求的。
我们同时也知道机器人的运动特性,机器人接收到控制指令后,会根据指令控制轮子上的电机调整相应转速,同时,机器人也会根据自身的运动状态推算出自己当前的朝向,理论上来说,是可以根据机器的轮子转速来更新机器人的位置和朝向信息的。然而实际情况是,机器人的运动会受到风的影响,轮子可能会打滑,或者机器人可能经过一段特别崎岖的道路,这些都会对机器人运动状态的估算造成影响。因此,不能单纯的用机器人轮子转动的圈数来表示机器人行驶过的路程,同样的,也不能单纯的用机器人的轮子去推算机器人当前的位置朝向信息。
好吧,目前可以通过两种方式来确定机器人的位置信息,第一种,通过机器人自带的GPS定位,但是这种方式噪声太大,定位精度不够,很容易翻车;第二种方式,通过机器人自身的轮速信息,对机器人现有位置进行预测,这种方式,会因为外界环境的影响,造成对位置的估算不准确。
综合来看,机器人的位置信息,可以有两种方式获得,
- 通过传感器直接观测,但是传感器测量有误差;
- 通过机器人运动学方程进行推算,但是会有干扰,会导致机器人位置估算有误差,误差会随着机器人的行驶不断累积,位置精度也会很大。
那么有没有一种方式,能让我们利用所有的可用信息,来提高机器人的定位信息呢?当然有,下面就来介绍一下卡尔曼。
; 卡尔曼滤波原理
让我们来看一下需要处理的场景。
用一个状态向量表示当前机器人的状态,状态量包含位置和速度两个信息,
x ⃗ = [ p v ] \vec{x}=\begin{bmatrix} p \ v \ \end{bmatrix}x =[p v ]
结合下图来看,坐标系横轴为速度量,纵轴为位置量,我们虽然不知道机器人当前准确的状态信息,但是机器人在下图中某些点的概率更大一些(图中颜色越浅,表示机器人为此状态的概率越大),

卡尔曼滤波主要适用于误差符合高斯分布的随机变量,设定随机变量的均值为μ \mu μ,方差为δ 2 \delta^{2}δ2,如下图所示,
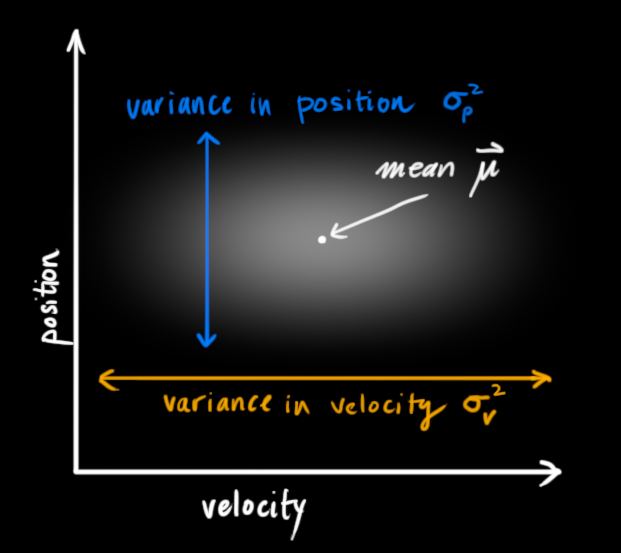
在上图中,位置变量和速度变量两个量之间是不相关的,其中一个变量无论如何变化都不会引起另一个量的变化。
这里只是举个例子,实际情况位置与速度的关系是正相关的,如下图所示,
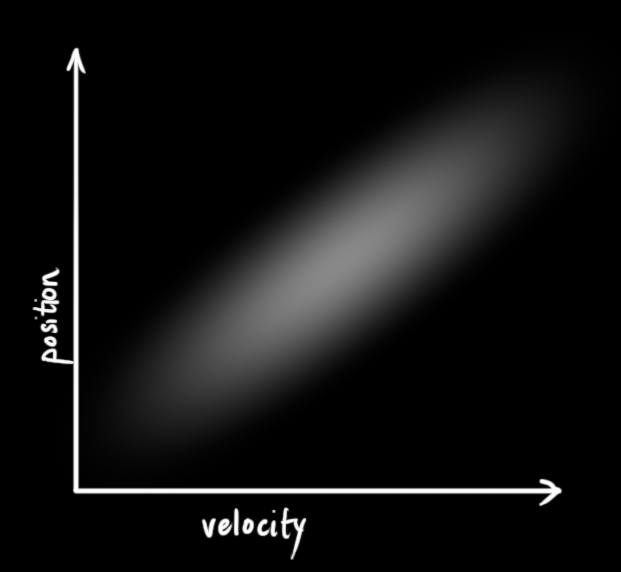
我们可以根据当前机器人的位置和运动速度去预测机器人下一段时间的位置信息。机器人的运动速度越快,下一段时间内移动的距离就越远;反之,速度越慢,机器人运动的距离就比较近。
两个变量之间的相关性,是一种很重要的性质,因为它能从一个变量的变化来推断出另外一个与之相关变量的变化。同时这也是卡尔曼滤波的主要目的,我们希望能根据所获得的信息最大限度的去确定不确定量的范围。
表示两个变量之间的变化相互影响的关系矩阵,叫做协方差矩阵。矩阵中的元素∑ i j \sum_{ij}∑i j 表示行变量上的第i i i个元素与列变量上的第j j j个元素之间的相关度,这里不难看出啊,协方差矩阵是对称的,∑ j i \sum_{ji}∑j i 与∑ i j \sum_{ij}∑i j 其实是同一个量。
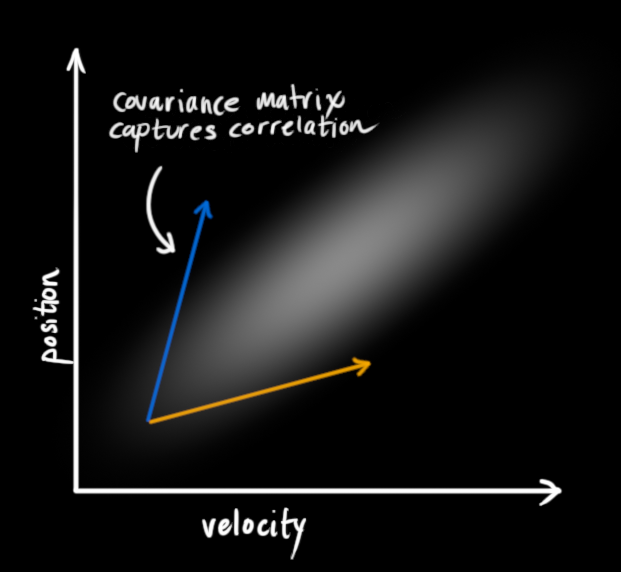
用矩阵来表述问题
有上述分析可知,我们需要估算的状态量都是高斯分布,因此,在进行滤波时,我们需要知道当前时刻k k k的的两个信息量:当前系统状态的最优估计值x ^ k \hat{x}{k}x ^k (其平均值为μ \mu μ),以及此刻的协方差矩阵P k P{k}P k 。
x ^ k = [ p o s i t i o n v e l o c i t y ] P k = [ ∑ p p ∑ p v ∑ v p ∑ v v ] (1) \hat{x}{k}=\begin{bmatrix} position \ velocity \ \end{bmatrix} \ \space \ P{k}=\begin{bmatrix} \sum_{pp} & \sum_{pv} \ \sum_{vp} & \sum_{vv} \ \end{bmatrix} \tag{1}x ^k =[p o s i t i o n v e l o c i t y ]P k =∑p p ∑v p ∑p v ∑v v
这里我们只用了位置和速度两个量,当然也可有根据实际情况的需求增加更多的状态量来表示系统的状态,这里只是举个例子做个说明。
下面,我们需要找到入一种从当前时刻k − 1 k-1 k −1系统状态去预测下一个时刻k k k系统状态的方法。要注意的是,卡尔曼滤波对系统的初始状态并不是要求十分精确。
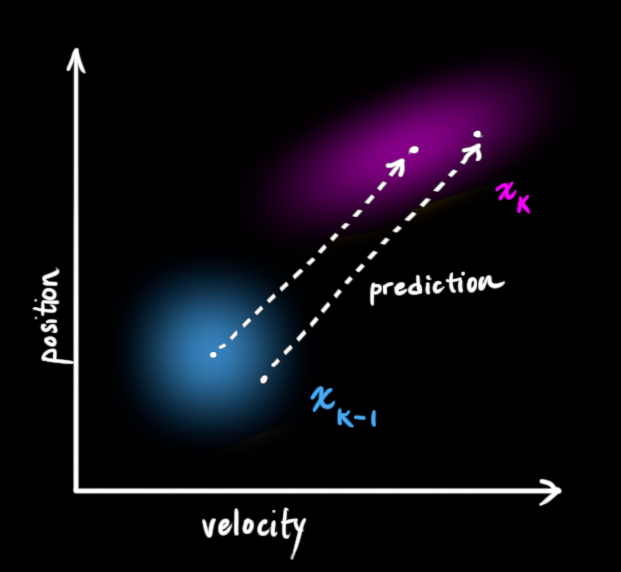
我们用F k F_{k}F k 表示系统状态转移矩阵,如下图所示,
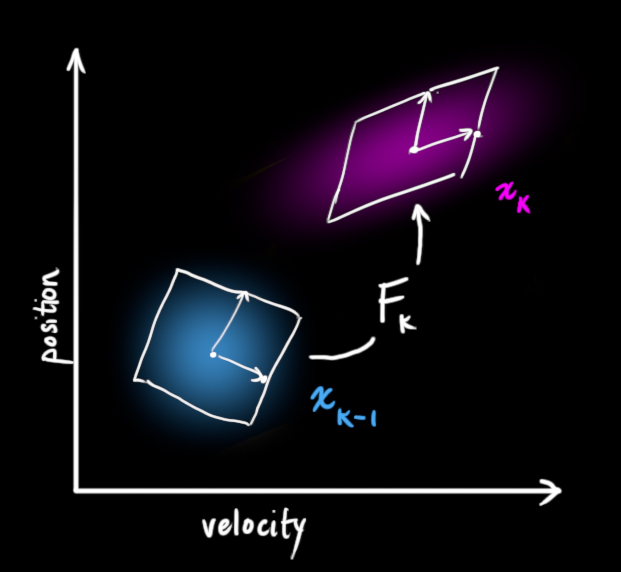
通过状态转移矩阵,可以将蓝色区域内的点移动到红色的区域。用卡尔曼的方式来表达就是,蓝色区域为当前状态,红色区域为预测状态。
下面来说一下如何应用上述理论,如何通过状态转移矩阵去预测下一时刻机器人的位置和速度?
首先,建立机器人运动方程:
p k = p k − 1 + v k − 1 Δ t v k = v k − 1 p_k=p_{k-1}+v_{k-1}\Delta{t} \ v_{k} = v_{k-1}p k =p k −1 +v k −1 Δt v k =v k −1
写成矩阵的形式,
x ^ k = [ p k v k ] = [ 1 Δ t 0 1 ] [ p k − 1 v k − 1 ] = F k x ^ k − 1 (2) \hat{x}{k}=\begin{bmatrix} p{k} \ v_{k} \ \end{bmatrix}=\begin{bmatrix} 1 & \Delta{t} \ 0 & 1 \ \end{bmatrix}\begin{bmatrix} p_{k-1} \ v_{k-1} \ \end{bmatrix}=F_{k} \hat{x}_{k-1} \tag{2}x ^k =[p k v k ]=[1 0 Δt 1 ][p k −1 v k −1 ]=F k x ^k −1 (2 )
现在,我们可以通过公式(2)对机器人的下一个状态进行预测,但是此时仍然不知道如何去更新协方差矩阵。如果状态向量中的每个状态乘以一个矩阵A A A,那么协方差矩阵会如何变化?
看一下下面的公式,
C o v ( x ) = ∑ C o v ( A x ) = A ∑ A T (3) Cov(x)=\sum \ \space \ Cov(Ax)=A\sum A^{T} \tag{3}C o v (x )=∑C o v (A x )=A ∑A T (3 )
综上,有
x ^ k = F k x ^ k − 1 P k = F k P k − 1 F k T (4) \hat{x}{k}=F{k} \hat{x}{k-1} \ P{k}=F_{k}P_{k-1}F_{k}^{T} \tag{4}x ^k =F k x ^k −1 P k =F k P k −1 F k T (4 )
注意,这里的P P P是协方差矩阵,不是位置。
; 外部影响
上述的推导过程是没有考虑外部的影响的,机器人在行走的过程中,难免会受到外界环境的影响,这些影响都会影响到机器人的位置估算。
举个例子,给火车建立运动学模型时,火车司机加了油门后,火车就会加速行驶。同样的,在我们的机器人的例子中,机器人导航也一样会下发命令给机器人的驱动电机,从而使得机器人按照期望去运动。如果我们知道可能会对机器人运动产生影响的因素,将这些因素都考虑进来,可以提高机器人位置预测的准确性,将外界可能对机器人运动有影响的约束向量用u ⃗ k \vec{u}_{k}u k 表示。
在此文使用的例子中,能对机器人的运动造成影响的向量就是加速度a a a,由此,可以得到机器人的动力学模型,
p k = p k − 1 + v k − 1 Δ t + 1 2 a Δ t 2 v k = v k − 1 + a Δ t p_k=p_{k-1}+v_{k-1}\Delta{t}+\frac{1}{2}a \Delta{t}^{2} \ v_{k} = v_{k-1}+a \Delta{t}p k =p k −1 +v k −1 Δt +2 1 a Δt 2 v k =v k −1 +a Δt
转化成矩阵形式,
x ^ k = F k x ^ k − 1 + [ Δ t 2 2 Δ t ] a = F k x ^ k − 1 + B k u ⃗ k (5) \hat{x}{k}=F{k}\hat{x}{k-1}+\begin{bmatrix} \frac{\Delta{t}^{2}}{2} \ \Delta {t} \end{bmatrix}a =F{k}\hat{x}{k-1}+B{k}\vec{u}_{k} \tag{5}x ^k =F k x ^k −1 +[2 Δt 2 Δt ]a =F k x ^k −1 +B k u k (5 )
式中,B k B_{k}B k 为控制矩阵,u ⃗ k \vec{u}_{k}u k 为控制向量。(这里只是举个例子,所以用的都是很简单的模型,这里只有加速度一个外部影响,当然实际情况,会根据需要添加别的量。)
外部的不确定量
如果机器人完全按照动力学方程去运动,那就没卡尔曼滤波什么事了。另外,如果我们知道所有会对机器人运动产生影响的外界因素,并将其考虑进来,计算出所产生力的影响,那也能很准确的推算出机器人的位置。
但是,总有些无法考虑到的外部影响因素,这些因素怎么处理呢?就好像无人机的定位一样,无人机很容易受到风力的影响,想想怎么对风力建模,脑袋都大。同样的,如果是机器人的话,机器人的轮子难免发生打滑,碰到地面等,都会对机器人的移动造成影响。我们没法将所有的外界的影响都考虑进来,但是,如果任意一个外界不可控的因素发生时,我们对机器人的位置预测都会不准确。
为了解决这个问题,我们会在每一次预测中增加一个扰动量,来表示这些无法避免的且不好建模的外界影响因素。
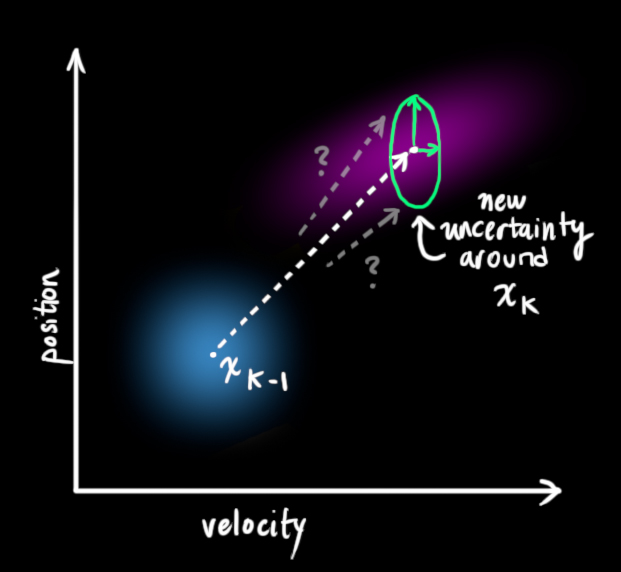
机器人的每个状态量都可以从初始时的状态(x k − 1 x_{k-1}x k −1 )转移到新的状态范围内(x k x_k x k )。
k − 1 k-1 k −1时刻机器人状态可以转移到一个新的范围内,这个状态范围符合高斯分布且其方差为Q k Q_{k}Q k ,换句话说,就是我们把可能造成系统扰动的外部环境因素当做一个方差为Q k Q_{k}Q k 的白噪声来处理,如下图所示,

由于系统加入了白噪声,这样就产生了一个新的高斯分布(与原来的系统有着相同的期望,但是方差不同)。

在加入白噪声Q k Q_{k}Q k 之后,有预测方程,
x ^ k = F k x ^ k − 1 + B k u ⃗ k P k = F k P k − 1 F k T + Q k (6) \hat{x}{k}=F{k} \hat{x}{k-1} +B{k}\vec{u}{k} \ P{k}=F_{k}P_{k-1}F_{k}^{T} +Q_{k} \tag{6}x ^k =F k x ^k −1 +B k u k P k =F k P k −1 F k T +Q k (6 )
新的系统状态x ^ k \hat{x}{k}x ^k 是从上一时刻的系统状态x ^ k − 1 \hat{x}{k-1}x ^k −1 和输入的系统控制量u ⃗ k \vec{u}_{k}u k 计算出来的系统估计值,此估值也叫做先验估计值,是各个变量高斯分布的均值。另外,P k P_k P k 为协方差矩阵,表示系统的不确定性,是由上一时刻的协方差矩阵和当前时刻外部噪声的协方差一起计算得到的。
好,到目前位置,我们已经有了系统状态方程,可以通过此方程去预测系统下一时刻的状态x ^ k \hat{x}_{k}x ^k 和协方差P k P_k P k 。另外,我们还有机器人的传感器这个信息没有使用呢,如果加上GPS信号,是不是可以进一步的提高机器人的定位精度?
; 传感器的观测值
一个机器人可能有很多个传感器,这些传感器可以帮助我们更好的了解当前系统的状态。有的传感器可能返回位置信息,有的返回速度信息,每个传感器会都会监测系统的某一个状态,并周期性的返回所监测的系统状态。

需要注意的是,传感器返回值的单位可能和我们预测使用的单位是不一致的,要注意保持一致。下面,我们需要找到真实值和测量值之间的关系矩阵K k K_{k}K k 。
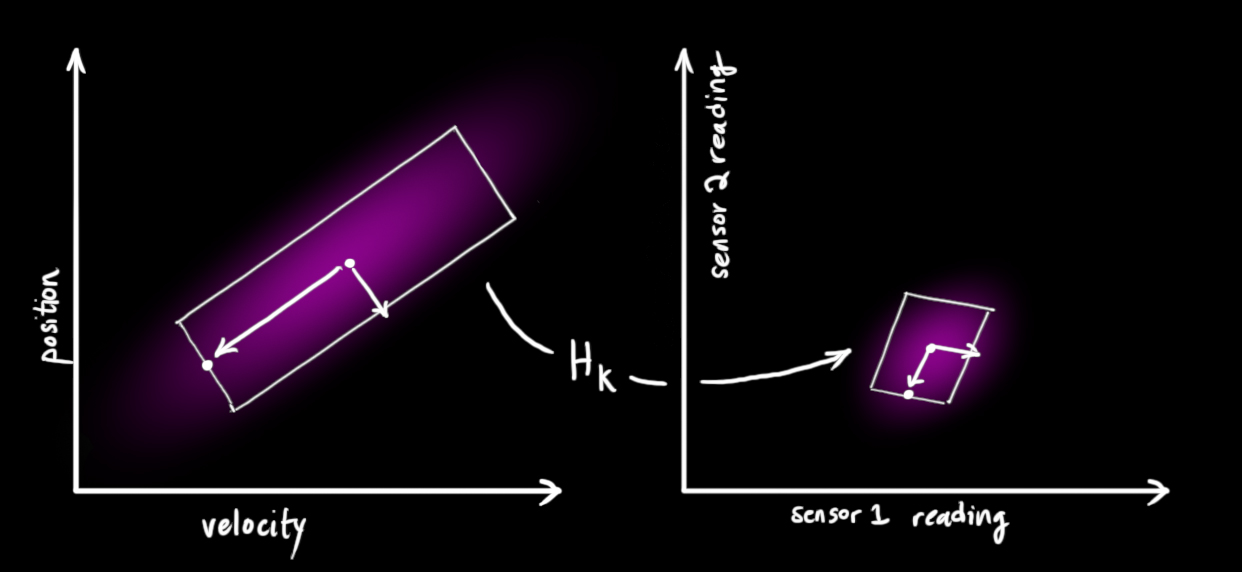
我们能够计算出传感器返回值的分布情况,如下所示,
μ ⃗ e x p e c t e d = H k x ^ k ∑ e x p e c t e d = H k P k H k T (7) \vec{\mu}{expected}=H{k}\hat{x}{k} \ \space \ \sum{expected}=H_{k}P_{k}H_{k}^{T} \tag{7}μe x p e c t e d =H k x ^k e x p e c t e d ∑=H k P k H k T (7 )
卡尔曼滤波之所以好用,主要是因为它可以很好的处理传感器的噪声。换句话说,就是我们的传感器返回值是不能完全相信的,我们每次预测的系统状态也是在某个有效范围内,并不是完完全全的真值。
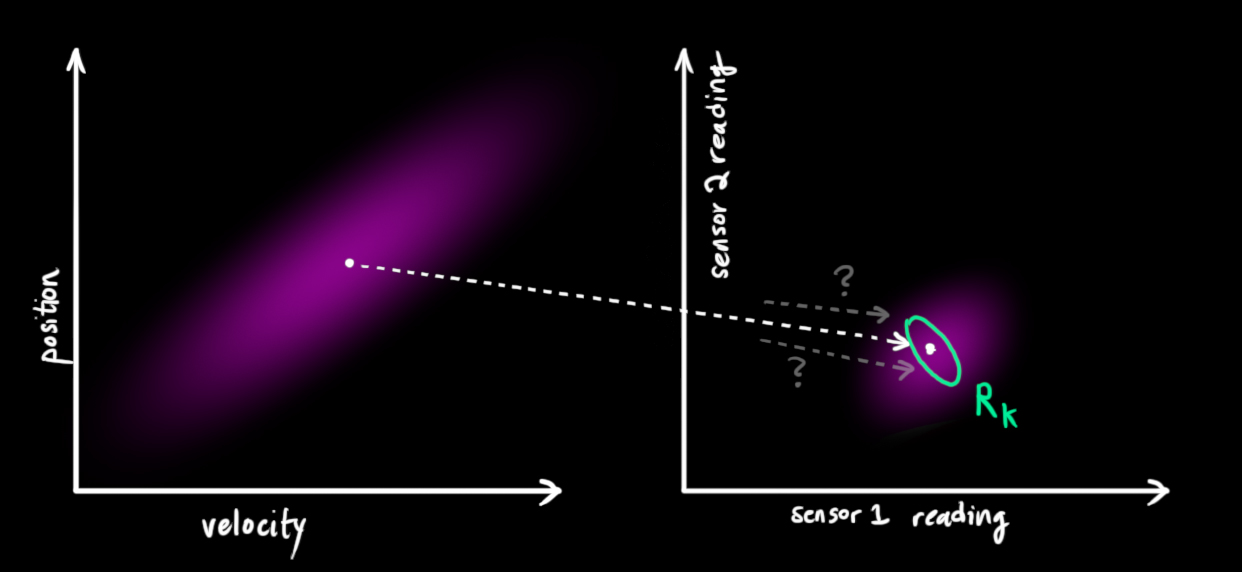
通过传感器每次返回的观测值,我们可以大致估算出当前时刻的系统状态。但是,观测值是存在噪声的,所以估算出的一些状态是比另一些估算出的状态可能性更高。
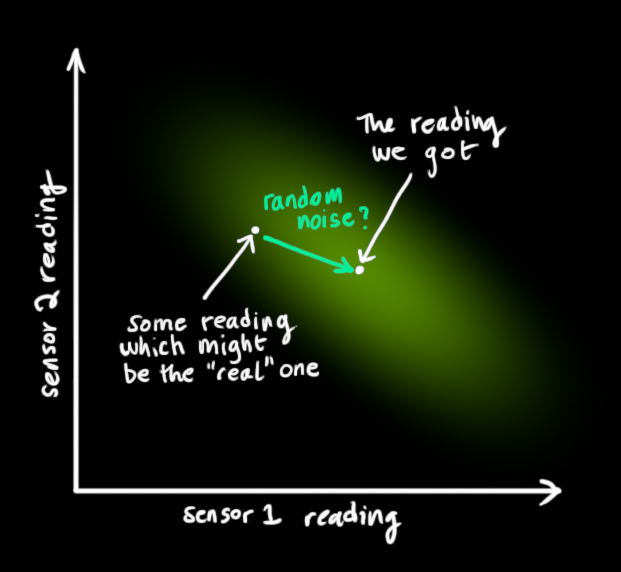
我们使用R k R_k R k 来表示传感器噪声的协方差。传感器噪声同样也符合高斯分布,其均值就是传感器读到值的平均值,用z ⃗ k \vec{z}_{k}z k 表示。
好,到目前为止,我们已经有了两个高斯分布:一个是预测带来的,另一个就是传感器返回值带来的噪声。
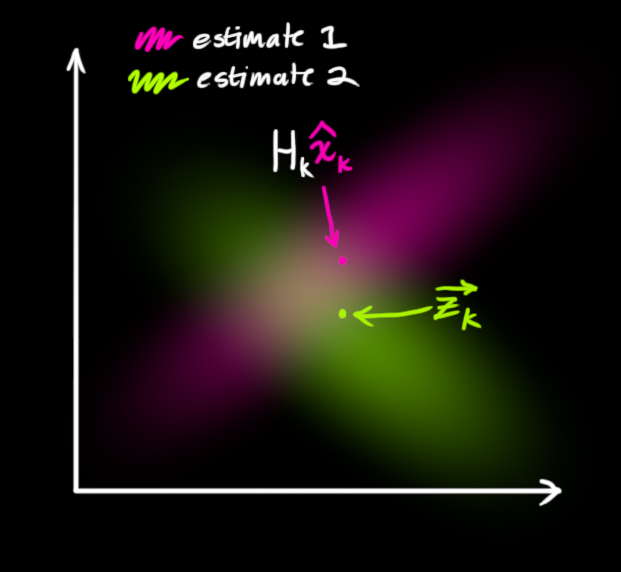
如图所示,其中红色的部分为根据模型进行的预测,绿色部分为传感器返回的值。我们现在需要对预测的值和传感器的返回值进行相关的处理,得到一个更为准确的系统状态信息。
那么如何使用这两个信息来提高机器人当前的位置准确性呢?
对于任何从传感器上读到任意一组值( z 1 , z 2 ) (z_1,z_2)(z 1 ,z 2 ),都有下面两种可能:
- 传感器的观测值z ⃗ k \vec{z}_{k}z k 有问题,与通过模型预测的分布相差很大,没法很好的表示机器人的状态;
- 传感器的观测值z ⃗ k \vec{z}_{k}z k 没有问题,与通过模型预测的分布相差相同,可以很好的表示机器人的状态。
假如现在我们面临这两种可能,我们会认为这两种情况都是正确的,将这两个分布相乘就可以得到一个新的分布,如下所示:

注意看图中高亮的部分,是两个分布重叠的部分,这个新的分布比之前的两个分布都要更加精确(单独用模型去预测和用传感器去测量)。因此,新的分布是结合了两种方式对机器人当前状体的最好估计。
如下图所示,新的分布是不是像一个与之前两个高斯分布不同的新的高斯分布,

到此为止,可以知道,把两个不同的高斯分布(各自有自己的均值和协方差矩阵)相乘,可以得到一个新的高斯矩阵,新的高斯矩阵有新的均值和协方差矩阵!也许你会发现,我们可以通过原来的两个高斯分布参数计算出新的高斯分布的参数。
结合高斯分布
现在我们就来推导出如何从原来的高斯分布参数计算出新的高斯分布的参数。
首先,从一维来分析是最简单的,如下图所示,是一个均值为μ \mu μ,方差为δ 2 \delta^2 δ2的高斯分布函数,
N ( x , μ , δ ) = 1 σ 2 π e − ( x − μ ) 2 2 σ 2 (8) N(x,\mu,\delta)=\frac{1}{\sigma \sqrt{2\pi}}e^{-\frac{(x-\mu)^2}{2\sigma^2}} \tag{8}N (x ,μ,δ)=σ2 π1 e −2 σ2 (x −μ)2 (8 )
其实我们最想知道的就是,把两个高斯分布相乘之后得到一个新的高斯分布,如何从之前的分布参数计算出新高斯分布的参数。如下图所以,蓝色的曲线是由红色和绿色曲线所代表的高斯分布相乘得来,

N ( x , μ 0 , δ 0 ) ⋅ N ( x , μ 1 , δ 1 ) = ? N ( x , μ ′ , δ ′ ) (9) N(x,\mu_0,\delta_0) \cdot N(x,\mu_1,\delta_1)\stackrel{?}{=}N(x,\mu^{‘},\delta^{‘}) \tag{9}N (x ,μ0 ,δ0 )⋅N (x ,μ1 ,δ1 )=?N (x ,μ′,δ′)(9 )
将公式(8)带入公式(9)并化简之后有,
μ ′ = μ 0 + σ 0 2 ( μ 1 − μ 0 ) σ 0 2 + σ 1 2 σ ′ 2 = σ 0 2 − σ 0 4 σ 0 2 + σ 1 2 (10) \mu^{‘}=\mu_{0}+\frac{\sigma_0^{2}(\mu_1-\mu_0)}{\sigma_0^{2}+\sigma_1^{2}} \ \space \sigma^{‘2}=\sigma_0^{2}-\frac{\sigma_0^{4}}{\sigma_0^{2}+\sigma_1^{2}} \tag{10}μ′=μ0 +σ0 2 +σ1 2 σ0 2 (μ1 −μ0 )σ′2 =σ0 2 −σ0 2 +σ1 2 σ0 4 (1 0 )
令
k = σ 0 2 σ 0 2 + σ 1 2 (11) k=\frac{\sigma_0^{2}}{\sigma_0^{2}+\sigma_1^{2}} \tag{11}k =σ0 2 +σ1 2 σ0 2 (1 1 )
可以把上式简化为,
μ ′ = μ 0 + k ( μ 1 − μ 0 ) σ ′ 2 = σ 0 2 − k σ 0 2 (12) \mu^{‘}=\mu_{0}+k(\mu_1-\mu_0) \ \space \sigma^{‘2}=\sigma_0^{2}-k\sigma_0^{2} \tag{12}μ′=μ0 +k (μ1 −μ0 )σ′2 =σ0 2 −k σ0 2 (1 2 )
令∑ \sum ∑为高斯分布的协方差,μ ⃗ \vec{\mu}μ为高斯分布的均值,则式(11)(12)可以化简为,
K = ∑ 0 ( ∑ 0 + ∑ 1 ) − 1 (13) K={\sum}{0}({\sum}{0}+{\sum}_{1})^{-1} \tag{13}K =∑0 (∑0 +∑1 )−1 (1 3 )
μ ⃗ ′ = μ ⃗ 0 + K ( μ ⃗ 1 − μ ⃗ 0 ) ∑ ′ = ∑ 0 − K ∑ 0 (14) \vec{\mu}^{‘}=\vec{\mu}{0}+K(\vec{\mu}{1}-\vec{\mu}{0}) \ \space \ {\sum}^{‘}={\sum}{0}-K{\sum}_{0} \tag{14}μ′=μ0 +K (μ1 −μ0 )∑′=∑0 −K ∑0 (1 4 )
式中K K K就是卡尔曼增益,下面我们就会用到这个量。
; 整合
我们有两个正态分布:
- 一个是预测正态分布,其参数为( μ 0 , ∑ 0 ) = ( H k x ^ k , H k x ^ k H k T ) (\mu_{0},{\sum}{0})=(H{k}\hat{x}{k},H{k}\hat{x}{k}H{k}^{T})(μ0 ,∑0 )=(H k x ^k ,H k x ^k H k T );
- 另一个是观测正态分布,其参数为( μ 1 , ∑ 1 ) = ( z ⃗ k , R k ) (\mu_{1},{\sum}{1})=(\vec{z}{k},R_{k})(μ1 ,∑1 )=(z k ,R k )。
直接带入公式(14)有,
H k x ^ k ′ = H k x ^ k + K ( z ⃗ k − H k x ^ k ) H k P k ′ H k T = H k P k H k T − K H k P k H k T (15) H_{k}\hat{x}{k}^{‘}=H{k}\hat{x}{k}+K(\vec{z}{k}-H_{k}\hat{x}{k}) \ \space \ H{k}P_{k}^{‘}H_{k}^{T}=H_{k}P_{k}H_{k}^{T}-KH_{k}P_{k}H_{k}^{T} \tag{15}H k x ^k ′=H k x ^k +K (z k −H k x ^k )H k P k ′H k T =H k P k H k T −K H k P k H k T (1 5 )
从式(13)可以推出卡尔曼增益为,
K = H k P k H k T ( H k P k H k T + R k ) − 1 (16) K=H_{k}P_{k}H_{k}^{T}(H_{k}P_{k}H_{k}^{T}+R_{k})^{-1} \tag{16}K =H k P k H k T (H k P k H k T +R k )−1 (1 6 )
把式(15)(16)中的H k H_{k}H k 化简掉,有
x ^ k ′ = x ^ k + K ′ ( z ⃗ k − H k x ^ k ) P k ′ = P k − K ′ H k P k (17) \hat{x}{k}^{‘}=\hat{x}{k}+K^{‘}(\vec{z}{k}-H{k}\hat{x}{k}) \ \space \ P{k}^{‘}=P_{k}-K^{‘}H_{k}P_{k} \tag{17}x ^k ′=x ^k +K ′(z k −H k x ^k )P k ′=P k −K ′H k P k (1 7 )
K ′ = P k H k T ( H k P k H k T + R k ) − 1 (18) K^{‘}=P_{k}H_{k}^{T}(H_{k}P_{k}H_{k}^{T}+R_{k})^{-1} \tag{18}K ′=P k H k T (H k P k H k T +R k )−1 (1 8 )
这就是卡尔曼滤波剩下的三个公式了。
式中x ^ k ′ \hat{x}{k}^{‘}x ^k ′是得到的新的最优状态估计,P k ′ P{k}^{‘}P k ′则为当前新的最优状态估计的协方差矩阵。
将x ^ k ′ \hat{x}{k}^{‘}x ^k ′和P k ′ P{k}^{‘}P k ′当做下一个卡尔曼周期的输入。
卡尔曼滤波的工作流程大致如下所示,

总结
卡尔曼滤波总共有五个公式,为
- 预测步骤: x ^ k = F k x ^ k − 1 + B k u ⃗ k P k = F k P k − 1 F k T + Q k (6) \hat{x}{k}=F{k} \hat{x}{k-1} +B{k}\vec{u}{k} \ P{k}=F_{k}P_{k-1}F_{k}^{T} +Q_{k} \tag{6}x ^k =F k x ^k −1 +B k u k P k =F k P k −1 F k T +Q k (6 )
- 更新步骤: x ^ k ′ = x ^ k + K ′ ( z ⃗ k − H k x ^ k ) P k ′ = P k − K ′ H k P k (17) \hat{x}{k}^{‘}=\hat{x}{k}+K^{‘}(\vec{z}{k}-H{k}\hat{x}{k}) \ \space \ P{k}^{‘}=P_{k}-K^{‘}H_{k}P_{k} \tag{17}x ^k ′=x ^k +K ′(z k −H k x ^k )P k ′=P k −K ′H k P k (1 7 ) K ′ = P k H k T ( H k P k H k T + R k ) − 1 (18) K^{‘}=P_{k}H_{k}^{T}(H_{k}P_{k}H_{k}^{T}+R_{k})^{-1} \tag{18}K ′=P k H k T (H k P k H k T +R k )−1 (1 8 )
式中,
x ^ k \hat{x}_{k}x ^k 为k k k时刻的系统状态,
F k F_{k}F k 为k k k时刻的系统状态转移矩阵(为什么是k k k时刻的,看了EKF 就明白了),
u ⃗ k \vec{u}_{k}u k 为k k k时刻,当前系统的控制输入量,
B k B_k B k 为k k k时刻系统的控制输入矩阵,
P k P_k P k 为k k k时刻系统的协方差矩阵,
Q k Q_k Q k 为k k k时刻预测噪声协方差矩阵,
R k R_k R k 为k k k时刻测量噪声协方差矩阵,
H k H_k H k 为k k k时刻观测矩阵,
z ^ k \hat{z}_k z ^k 为k k k时刻的观测值,
K ′ K^{‘}K ′为当前时刻的卡尔曼增益。
卡尔曼滤波适用于任何线性系统,对于非线性系统,可以使用扩展卡尔曼滤波(EKF),后面会有详细的文章。
原文链接:
http://www.bzarg.com/p/how-a-kalman-filter-works-in-pictures/#mathybits
Original: https://blog.csdn.net/qq_24649627/article/details/122495547
Author: 碎步の流年
Title: Apollo学习笔记(17)卡尔曼滤波
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/598290/
转载文章受原作者版权保护。转载请注明原作者出处!