

反屏蔽
现在很多网站都加上了对 Selenium 的检测,来防止一些爬虫的恶意爬取。即如果检测到有人在使用 Selenium 打开浏览器,那就直接屏蔽。
其大多数情况下,检测基本原理是检测当前浏览器窗口下的 window.navigator 对象是否包含 webdriver 这个属性。因为在正常使用浏览器的情况下,这个属性是 undefined,然而一旦我们使用了 Selenium,Selenium 会给 window.navigator 设置 webdriver 属性。很多网站就通过 JavaScript 判断如果 webdriver 属性存在,那就直接屏蔽。
这边有一个典型的案例网站:
Scrape | Movie antispider1.scrape.cuiqingcai.com/
这个网站就是使用了上述原理实现了 WebDriver 的检测,如果使用 Selenium 直接爬取的话,那就会返回如下页面:


这时候我们可能想到直接使用 JavaScript 直接把这个 webdriver 属性置空,比如通过调用 execute_script 方法来执行如下代码:
Object.defineProperty(navigator, "webdriver", {get: () => undefined})
这行 JavaScript 的确是可以把 webdriver 属性置空,但是 execute_script 调用这行 JavaScript 语句实际上是在页面加载完毕之后才执行的,执行太晚了,网站早在最初页面渲染之前就已经对 webdriver 属性进行了检测,所以用上述方法并不能达到效果。
在 Selenium 中,我们可以使用 CDP(即 Chrome Devtools-Protocol,Chrome 开发工具协议)来解决这个问题,通过 CDP 我们可以实现在每个页面刚加载的时候执行 JavaScript 代码,执行的 CDP 方法叫作 Page.addScriptToEvaluateOnNewDocument,然后传入上文的 JavaScript 代码即可,这样我们就可以在每次页面加载之前将 webdriver 属性置空了。另外我们还可以加入几个选项来隐藏 WebDriver 提示条和自动化扩展信息,代码实现如下:
from selenium import webdriver
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
browser = webdriver.Chrome(options=option)
browser.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'
})
browser.get('https://antispider1.scrape.cuiqingcai.com/')
这样整个页面就能被加载出来了:
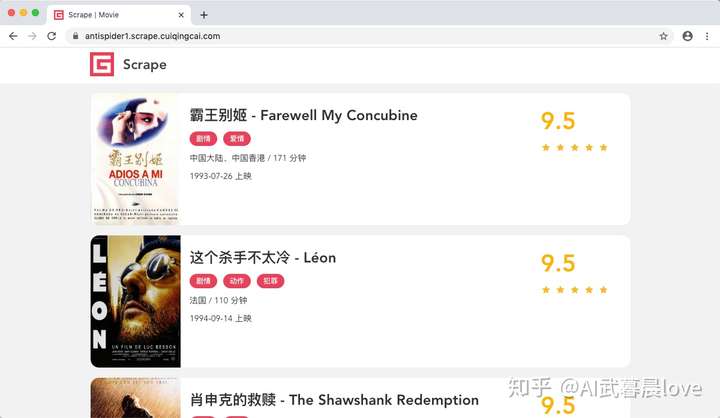
对于大多数的情况,以上的方法均可以实现 Selenium 反屏蔽。但对于一些特殊的网站,如果其有更多的 WebDriver 特征检测,可能需要具体排查。
Original: https://www.cnblogs.com/lvye001/p/16053580.html
Author: lvye001
Title: selenium被识别如何反屏蔽
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/597010/
转载文章受原作者版权保护。转载请注明原作者出处!