

学习的博客: 推荐系统遇上深度学习(二十六)–知识图谱与推荐系统结合之DKN模型原理及实现
知识图谱特征学习的模型分类汇总
知识图谱嵌入(KGE):方法和应用的综述
论文: Knowledge Graph Embedding: A Survey of Approaches and Applications
知识表示学习的研究与进展
基于距离的翻译模型
这类模型使用基于距离的评分函数评估三元组的概率,将尾节点视为头结点和关系翻译得到的结果。这类方法的代表有TransE、TransH、TransR等;
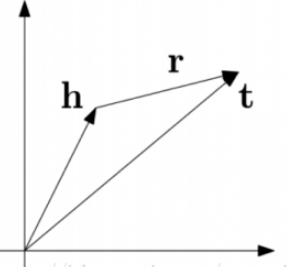

上面三个方法的基本思想都是一样的,我们以TransE为例来介绍一下这些方法的核心思想。在空间中,三元组的头节点h、关系r、尾节点t都有对应的向量,我们希望的是h + r = t,如果h + r的结果和t越接近,那么我们认为这些向量能够很好的表示知识图谱中的实体和关系。
https://blog.csdn.net/wp_csdn/article/details/79607727
https://zhuanlan.zhihu.com/p/50491255
; 基于语义的匹配模型
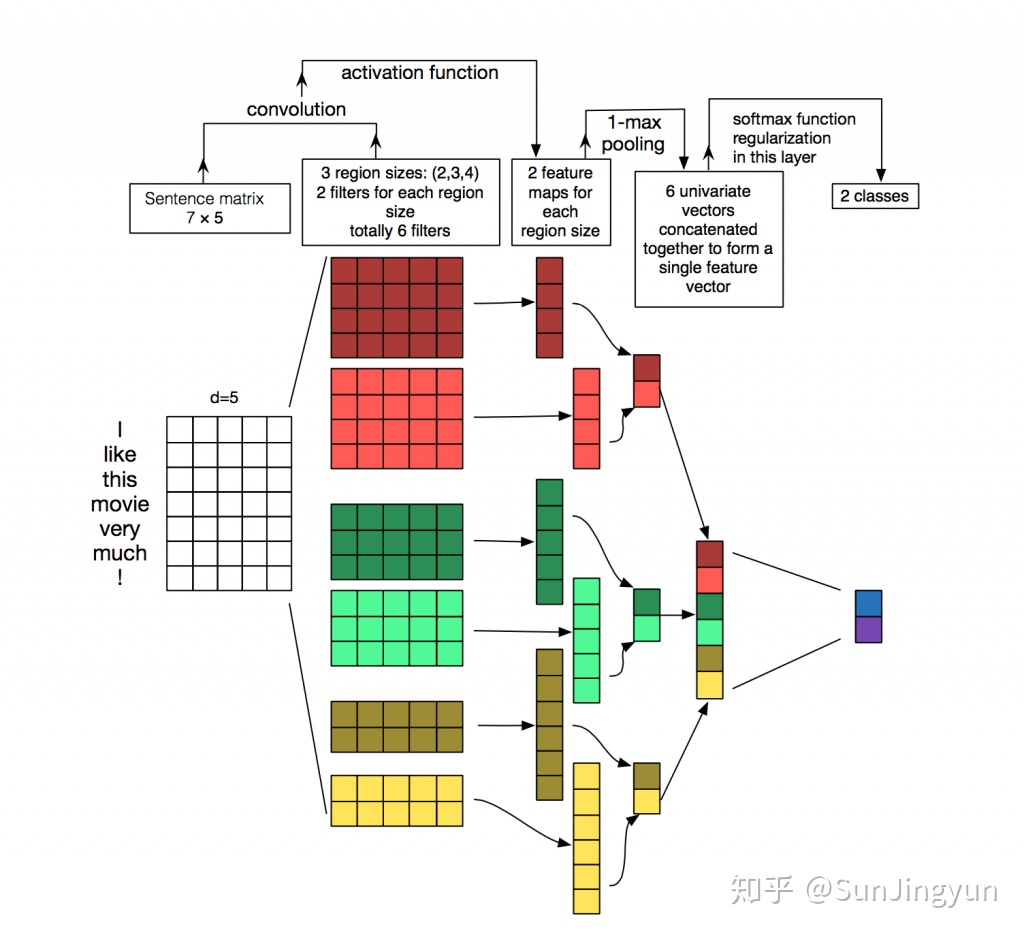
基于CNN的句子特征提取
下图中是第一个作者中的插图。 但是我没懂,因为一般过滤器是需要三个参数的,(size, step,num)。 这里给出了了size和个数,但是没有给出步长, size为2和3是没有办法访问整个句子的! 不懂?
在视觉处理上,我们的滤波器滑过图像的局部块,但在 NLP 中, 我们通常使用滤波器滑过矩阵的一整行(一个单词)。因此,我们的滤波器的”宽度”通常与输入矩阵的宽度相同。高度或者说区域大小可能会有所不同,但通常每次将窗口滑过 2-5 个单词。

通常而言,绝大部分NLP问题可以归入上图所示的四类任务中:一类是序列标注,这是最典型的NLP任务,比如中文分词,词性标注,命名实体识别,语义角色标注等都可以归入这一类问题,它的特点是句子中每个单词要求模型根据上下文都要给出一个分类类别。第二类是分类任务,比如我们常见的文本分类,情感计算等都可以归入这一类。它的特点是不管文章有多长,总体给出一个分类类别即可。第三类任务是句子关系判断,比如Entailment,QA,语义改写,自然语言推理等任务都是这个模式,它的特点是给定两个句子,模型判断出两个句子是否具备某种语义关系;第四类是生成式任务,比如机器翻译,文本摘要,写诗造句,看图说话等都属于这一类。它的特点是输入文本内容后,需要自主生成另外一段文字。
解决这些不同的任务,从模型角度来讲什么最重要?是 特征抽取器的能力。尤其是深度学习流行开来后,这一点更凸显出来。因为深度学习最大的优点是”端到端(end to end)”,当然这里不是指的从客户端到云端,意思是以前研发人员得考虑设计抽取哪些特征,而端到端时代后,这些你完全不用管,把原始输入扔给好的特征抽取器,它自己会把有用的特征抽取出来。
; 模型框架
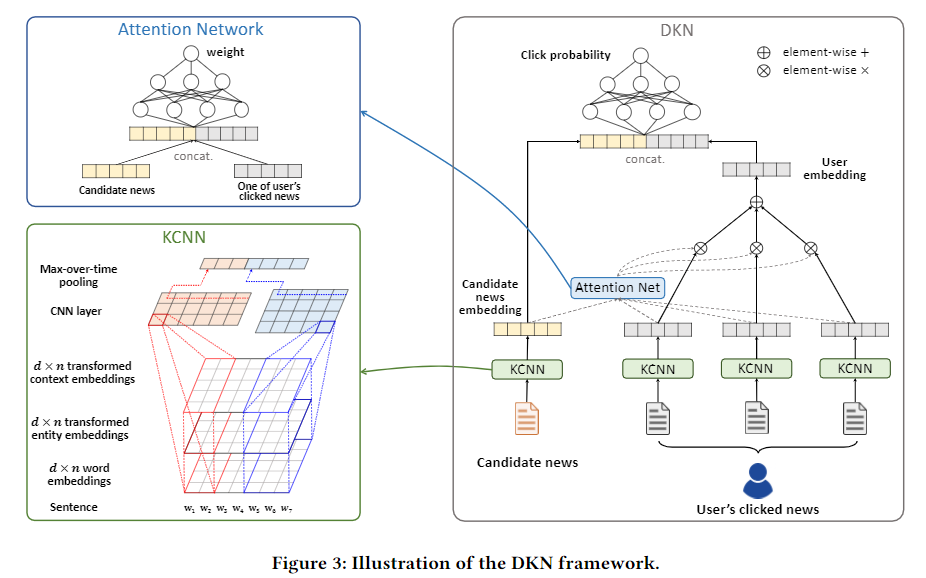
知识抽取
知识提取过程有三方面,一是得到标题中 每个单词的embedding,二是得到标题中每 个单词对应的实体的embedding。三是得到 每个单词的上下文embedding。每个单词对应的embedding可以通过word2vec预训练的模型得到。这里我们主要讲后两部分。
实体embedding
实体特征即标题中每个单词对应的实体的特征表示,通过下面四个步骤得到:
- 识别出标题中的实体并利用实体链接技术消除歧义
- 根据已有知识图谱,得到与标题中涉及的实体链接在一个step之内的所有 实体所形成的子图。
- 构建好知识子图以后,利用基于距离的翻译模型得到子图中每个 实体embedding(利用的是与上面构成的子图中节点之间的关系)
- 得到标题中每个单词对应的实体embedding。
上下文embedding
尽管目前现有的知识图谱特征学习方法得到的向量保存了绝大多数的结构信息,但还有一定的信息损失,为了更好地利用一个实体在原知识图谱的位置信息,文中还提到了利用一个实体的上下文来进一步的刻画每个实体,具体来说,即用每个实体相连的实体embedding的平均值来进一步刻画每个实体,计算公式如下:

; 新闻特征提取KCNN
在知识抽取部分,我们得到了三部分的embedding,一种最简单的使用方式就是直接将其拼接:
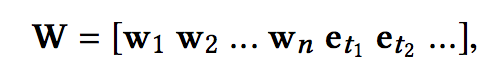
但这样做存在几方面的限制:
连接策略打破了单词和相关实体之间的联系,并且不知道它们的对齐方式。
单词的embedding和对应实体的embedding是通过不同的方法学习的,这意味着它们不适合在单个向量空间中将它们一起进行卷积操作。
连接策略需要单词的embedding和实体的embedding具有相同的维度,这在实际设置中可能不是最优的,因为词和实体embedding的最佳维度可能彼此不同。
因此本文使用的是multi-channel和word-entity-aligned KCNN。具体做法是先把实体的embedding和实体上下文embedding映射到一个空间里,映射的方式可以选择线性方式g(e) = Me,也可以选择非线性方式g(e) = tanh(Me + b),这样我们就可以拼接三部分作为KCNN的输入:
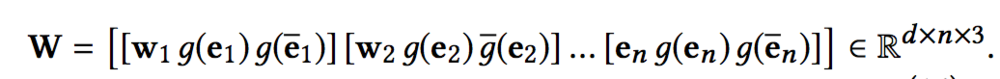
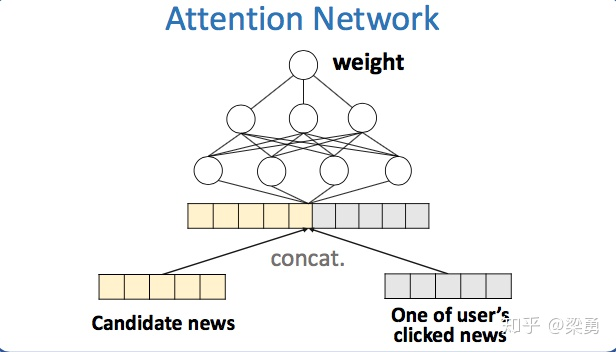
基于注意力机制的用户兴趣预测
获取到用户点击过的每篇新闻的向量表示以后,作者并没有简单地作加和来代表该用户,而是计算候选文档对于用户每篇点击文档的attention,再做加权求和,计算attention:
Original: https://blog.csdn.net/qq_35222729/article/details/119757452
Author: 追赶早晨
Title: 知识图谱论文阅读(八)【转】推荐系统遇上深度学习(二十六)–知识图谱与推荐系统结合之DKN模型原理及实现
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/596058/
转载文章受原作者版权保护。转载请注明原作者出处!