

前言
事件图谱大家听的比较多了,多模态相信大家也听到不少,尤其是各种多模态模型,如大家对多模态预训练模型感兴趣可以看看笔者之前写过的一篇:
多模态预训练模型综述 – 知乎前言2021年诺贝尔生理学、医学奖揭晓,获奖者是戴维·朱利叶斯(DavidJulius)和阿代姆·帕塔博蒂安(Ardem Patapoutian),表彰他们在”发现温度和触觉感受器”方面作出的贡献。那作为算法从业者,我们该思考些什…![]()
 https://zhuanlan.zhihu.com/p/435697429 ;那把事件图谱和多模态结合起来即多模态事件图谱是不是更有意思呢?今天就给大家介绍一篇相关paper,其贡献了一个相关的数据集和一些挖掘方法,一起来看看吧~
https://zhuanlan.zhihu.com/p/435697429 ;那把事件图谱和多模态结合起来即多模态事件图谱是不是更有意思呢?今天就给大家介绍一篇相关paper,其贡献了一个相关的数据集和一些挖掘方法,一起来看看吧~
论文链接:https://arxiv.org/pdf/2206.07207.pdf
任务 & 数据集
(1) 任务

通过事件以及事件之间的关系来表示真实世界是很多研究课题的手段即通过图谱来表示,之前大多数图谱要么单独是文本要不单独是图像(视频),如果能同时把这两种模态用起来岂不更好?要达到这个目的至少需要两个环节,第一就是各自模态的事件抽取,第二就是事件之间的关系建立。
于是作者这里提出了一个叫做M2E2R的任务,其主要聚焦于上述第二个环节的任务即关系预测。至于第一个环节作者这里直接借鉴了当前的SOTA模型,具体见paper中给出的文献[48, 49]。
具体的对于文本事件的定义之前有很多相关的工作了大体上就是一个本体的状态发生了改变。对于视频事件的定义这里比较困难,因为粒度很多,之前有研究是将视频持续2s作为一个事件,但是这很容易割裂事件本身且本身也不准确,作者这里将镜头转化定义为一个事件。对于事件之间的关系定义这里作者定义了两种:一种是Hierarchical具有层次的即假设A事件完全包含B事件,另外一种是Identical即A和B完完全全是同一个事件。
关于图谱边的方向性作者这里主要看的是从文本到视频的边,之所以这么设计是因为文本表达的信息通常是概括性的抽象性的而视频通常是具体的更细粒度的,比如文本通常说战争等等而视频里面会出现战斗的画面。
同时作者这里还自己答疑了一下提出的M2E2R任务和Video Grounding Task有啥区别,因为后者也是识别文本到具体视频的segments中,主要区别就是后者只包含了Identical关系,而不具备Hierarchical的预测。
(2)数据集
作者首先在allsides.com网站中选了九家比较不错的新闻媒体id,然后在Youtube上下载了相关的视频,一共下载了100.5K。
对于每一个视频,作者都会收集对应的描述和字幕,如果视频时长大于14分钟或者是描述小于10个字的就直接过滤掉了,因为前者预处理起来成本太高后者文本太短有可能对事件描述不清楚。然后将数据集划分了两种,一种是通过弱监督得到train训练集共100K条,另外一份是人工标注的共526条其中包含249个validation和277个test。
具体的作者还介绍了标注的工具等等,可见附录B中的数据细节等等
多模态事件关系抽取
作者这里提出了一个弱监督方法,大体思路就是分别用NLP和Vision技术去先得到伪标签,然后基于伪标签再训练,总体框架如下:

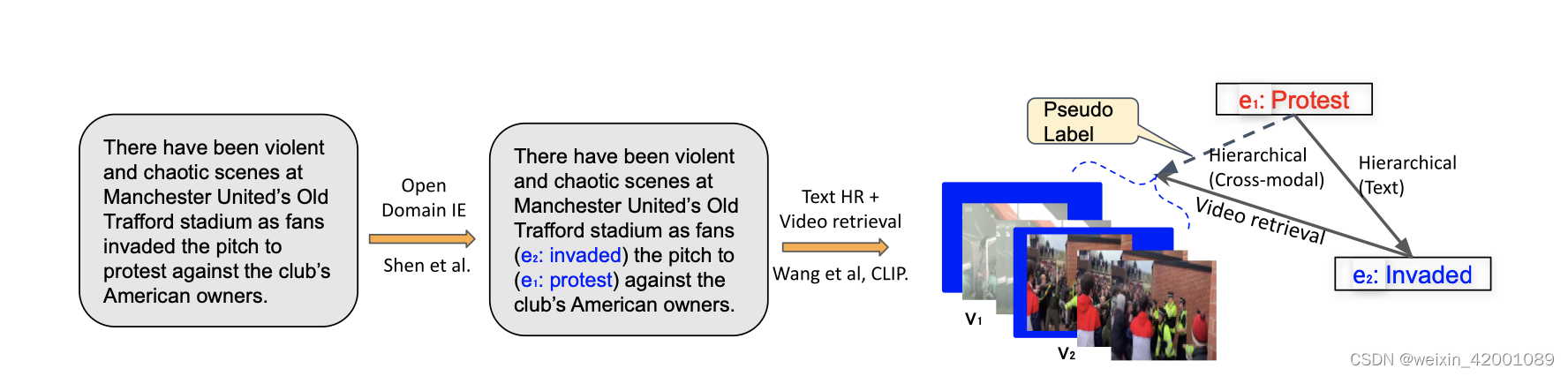
(1)伪标签获取
作者先分别抽取文本和视频事件,用的方法分别是Open Domain IE和PySceneDetect。接着是预测文本和文本之间的Hierarchical关系,具体方法见文献[56],然后作者用CLIP模型(最近一个比较牛的多模态预训练模型)去做文本检索视频,假设文本事件A包含文本事件B,文本事件B检索了视频事件C,那由于A和B是Hierarchical关系,那大概率文本事件A和视频事件C也是Hierarchical关系且文本事件B和视频事件C是Identical关系,同时作者还用两个视频的描述去做相似性即文本检索文本(用的也是CLIP模型),进一步填充了伪标签数据。
(2)训练模型
模型的总体框架如下:
首先可以看到不论是提取文本特征还是视频特征用的backbone都是CLIP。其中视频特征这里上面又套了个contextual transformer其实就是个多层transformer再进行视频上下文交互。
然后在融合特征的时候,作者这里设计了5种,前两种就是红色和黄色小方框都是各自模态的表征,然后接下来两个是交叉特征一个是相乘一个是相减也是常用的套路了,还有一个作者称之为Commonsense Features,说的简单点就是作者先用一个外部常见的知识库即ConceptNet(用了其中三种关系)训练了一个简单的特征提取器,然后在训练自己模型的时候freeze住仅仅作为一个特征提取器。
把上面的融合的特征过三个MLP层后做一个三分类(Hierarchical、Identical、没有关系)任务就可以啦
实验效果
这里给一个消融实验的结果吧,”CT” 就是contextual transformer、”CS” 就代表Commonsense Features、”EI” 就代表相减和相乘的交叉特征。

总结
(1) 在今天数据确实是越来越多,尤其短视频等等的崛起,使得我们在关注数据模态的方向上确实应该思考思考,尤其是视频数据包括视频理解等等会越来越重要。
(2) 无监督的方法的探索也是很重要,这里所说的无监督其实是说不花费人力去标注,其实有很多天然的对齐数据可以供我们挖掘,就比如视频和其描述就是一对天然对齐数据等等。
关注
欢迎关注,下期再见啦~
欢迎关注笔者微信公众号:

github:
Mryangkaitong · GitHubhttps://github.com/Mryangkaitong
知乎:
Original: https://blog.csdn.net/weixin_42001089/article/details/125345490
Author: weixin_42001089
Title: 多模态事件图谱
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/595888/
转载文章受原作者版权保护。转载请注明原作者出处!