

Knowledge Transfer for Out-of-Knowledge-Base Entities: A Graph Neural Network Approach 利用图神经网络解决知识图谱外实体的知识表示
- 摘要
- 1 Introduction
- 2. 知识库完成中的OOKB实体问题
* - 2.1知识图谱
- 2.2KBC:三元组分类任务
- 2.3 OOKB实体问题
- 3.模型
* - 3.13.1图表NNs
- 3.2知识图谱上的传播模型
–
+ - 3.3输出模型:分数和目标函数
–
+ - 实验
* - 4.1实现和超参数
- 4.2标准三元组分类
- 4.3 OOKB实体实验
–
+ - 4.4堆叠和展开图NNs
- 5.结论
摘要
- 知识库一般不完整,因此需要补全。
- 知识库补全(KBC)旨在预测知识库中的缺失信息。
- 本文讨论知识库中的知识库外实体问题: 如何表示和解决新实体问题(训练时未观察到的测试实体)。
- 现有的基于嵌入知识图谱补全模型中,所有实体用于训练得到嵌入表示。
- 但新实体的出现,获得新实体的嵌入需要重新训练的昂贵代价,
- 为了解决OOKB实体问题而不需要重新训练,我们利用测试时提供的有限辅助知识,利用图神经网络(GraphNNs)计算OOKB实体的嵌入量。
- 实验结果验证了我们提出的模型在OOKB环境下的有效性。此外,在不涉及OOKB实体的标准KBC设置中,我们的模型在WordNet数据集上实现了最先进的性能。
- Github源码
1 Introduction
WordNet、Freebase、等知识图谱被用于:信息提取、问答和文本理解等任务。这些知识图谱可以看作是一组关系 三元组,即(h;r;t)形式的三元组,其中一个实体h称为头实体,一个关系r,一个实体t称为尾部实体。
尽管一个知识库包含数百万个这样的三胞胎,但它存在 不完整性。 知识库补全(KBC)的目标是预测知识库中缺失的信息。
近年来,基于嵌入的知识库模型已经成功地应用于大规模知识库中。这些模型构建训练数据中观察到的实体和关系的分布式表示(或向量嵌入),并在嵌入上使用各种向量运算来预测缺失的关系三元组。
本文针对基于嵌入的知识图谱中的 知识图谱外实体问题进行了研究。当新实体(OOKB实体)出现在训练后给系统的关系三元组中时,就会出现这个问题。
由于 新实体在训练时对系统是未知的,因此系统没有它们的嵌入,因此没有方法预测这些实体之间的关系。虽然可以通过使用包含OOKB实体的附加关系三元组对嵌入进行 重新训练来解决这个问题,但是一个避免 代价高昂的重新训练的解决方案是可取的。
这个问题具有实际的 重要性,因为每当产生新的实体(如事件和产品)时,OOKB实体就会出现,这种情况每天都会发生。
- 例如,假设我们在一个新的三元组中找到了一个OOKB实体”Blade Runner”(Blade Runner,基于AndroidsDream of Electric Sheep?)。我们想推断更多的事实。三胞胎)从我们已经掌握的知识,回答诸如”刀锋杀手是科幻小说吗?”?”如果知识库包含一个三胞胎(DoAndroids梦见电羊?它应该有助于我们估计答案是肯定的。


图1示意性地说明了这个示例,有人尝试使用外部资源获取OOKB实体的嵌入。尽管这些方法可能有用,但它们需要对大量资源进行额外的计算,这可能并不总是可行的。实际上,上面的Blade Runner示例表明了在没有外部资源帮助的情况下推断OOKB实体的新事实的可能性。
为了解决OOKB实体问题,我们在知识图谱上使用 图神经网络(graph NNs),知识图谱是将实体表示为节点,三元组作为边得到的图。
图神经网络是定义在图结构上的神经网络结构,由两个模型组成,称为 传播模型和 输出模型。 传播模型管理信息如何在图中的节点之间传播。在传播模型中,我们首先得到给定节点(实体)e邻域的嵌入向量,然后利用一个池函数(如平均值)将这些向量转化为e的表示向量。换言之,每个节点作为一个向量嵌入到连续空间中,该向量也用于计算邻域节点的向量。这种机制使OOKB实体的向量在测试时由其邻域向量组成。 输出模型在节点向量上定义了面向任务的目标函数。这允许我们使用现有的基于嵌入的KBC模型作为输出模型。在本文中,我们使用TransE[Bordes et al.,2013]作为输出模型,但我们也可以采用其他基于嵌入的KBC方法。
我们的主要贡献如下:
1. 我们提出了KBC中OOKB实体问题的新公式。
2. 我们提出了一个适用于具有OOKB实体的知识图谱补全任务的图模型方法。
3. 我们在标准和”OOKB”实体设置中验证了模型的 有效性
; 2. 知识库完成中的OOKB实体问题
2.1知识图谱
- 设E是一组实体,R是一组关系。将事实(或关系或三元组)定义为形式(h;r;t)的三元组,其中h,t∈e和r∈r。设 Ggold⊂E×R×E是黄金事实集,即 所有关系三元组的集合,这些 三元组包含E中的实体对和r中的关系。
- 如果三元组在Ggold中,我们称它为 正三元组;否则,它是 负三元组。
- 知识补全的目标是 确定Ggold,当只有其适当的子集或不完整的知识库时
2.2KBC:三元组分类任务
- 在这个任务中,假设现有的知识库G是不完整的。由于G是不完全的,每个三元组x2h可能有两种情况;x是正的三元组(即x2ggold),或者x是负三元组。
- 确定G中不存在的三元组属于正三元组,或是负三元组的问题叫做 三元组分类。
- 三元组分类问题被看作是一个机器学习问题,它是一个给定E和R的分类器归纳任务。
- 在标准三元组分类中,E和R仅限于G中出现的实体和关系。
2.3 OOKB实体问题
- 我们在知识图谱补全(KBC)中引入了一个新任务,称为 知识图谱外实体(OOKB)问题。除了训练时观察到的知识库G外,在 测试时给出了新的三元组,我们称之为OOKB实体。
- 除了训练中的知识图谱G外,在 测试时,给定新的已知三元组Gaux, Gaux中的每个三元组 正好包含一个来自OOKB的实体和一个来自G的实体。
- 任务是正确识别包含OOKB实体EOOKB的丢失的关系三元组。因为这些实体的嵌入丢失了,它们必须从G中的实体中计算出来。
- 换句话说,我们想要设计一个模型,通过这个模型,我们已经在 G中拥有的信息可以在添加的知识 Gaux的帮助下传输到OOKB实体。
3.模型
3.13.1图表NNs
- Graph-NNs是定义在图结构上的神经网络。
- 尽管很多图神经网络将整个图编码为向量,对于知识图谱补全任务,我们关注的是提供 将节点和边编码为向量的图模型,
- 图NN由两个模型组成,传播模型和输出模型。 传播模型决定了如何在图中的节点之间传播信息。 输出模型利用向量表示的节点和边,根据给定的任务定义目标函数。本文 对传播模型进行了改进,使之适用于知识图。对于输出模型,我们使用基于嵌入的KBC模型TransE。
3.2知识图谱上的传播模型
传播模型:

- G:知识图谱
- e:实体
- Ve:实体e的d维表示向量
- Nhead(e)、Ntail(e):与实体e相连的三元组,分别从头节点、尾节点连接实体e。
- Thead,Ttail:转移函数,用于转换相邻节点的向量,根据e与相邻节点之间的边的性质,将其并入当前向量ve中。
- 池化函数:

- Shead(e)包含邻域Nhead(e)的表示向量,
- Stail(e)包含Ntail(e)的表示向量。等式2-4是使用池函数代替求和。
- 函数Thead、Ttail和P的候选函数如3.3所述
; 转移函数
- 转移函数T(包括Thead和Ttail)的目的是 修改相邻节点的向量,以 反映当前节点与相邻节点之间的关系。转换函数的示例如下:
- 其中,A是模型参数的矩阵,tanh和ReLU是元素双曲正切和校正的线性单位函数。* 此外,我们还可以使用其他神经网络技术,如批次归一化、残差连接和长短时记忆。
- 我们 也可以根据当前节点(实体)与相邻节点之间的 关系来设置转移函数,例如:

- 注意,现在 为节点e、当前邻居(h或t)的每个组合以及它们之间的关系r单独定义参数矩阵。在第4节的实验中,我们使用了以下 跃迁函数:
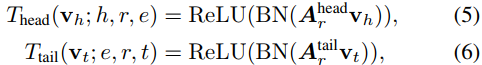
其中 *BN表示批次标准化
池化函数:
- 池函数P:将 一组向量映射到 一个向量的函数,它的 目标是从一组向量中提取共享信息。一些简单的池函数:
- 其中max是 elementwise max函数(对应元素逐个相乘)。
; 堆叠和展开
- 图神经网络如上所述,传播模型决定了如何将信息从一个节点传播到其邻域。重复应用这个传播模型,我们可以将一个节点的信息广播给更远的节点,即每个节点都可以接收到更多的信息。
传播可以有两种实现方式: 堆叠或展开。
- 在展开图中,传播模型在每次传播中使用相同的模型参数。传播过程与等式(2)-(4)中描述的相同。
- 堆叠图NN的构造方式与众所周知的堆叠技术类似。叠层图中的传播过程根据 时间步长n使用不同的模型参数.

T(n)head和Ttail(n)是依赖于头/尾和时间的转换函数。
3.3输出模型:分数和目标函数
- 我们使用基于TransE的函数作为输出模型。
- TransE是KBC的一种基于嵌入的基本模型,我们使用它是因为它的简单和易于训练。但输出模型不仅限于TransE,而且为输出模型采用其他基于嵌入的模型也是同样简单的。
- 我们将解释TransE的评分函数及其常用的 pairwise-margin成对边界目标函数。然后我们描述我们在实验中使用的修正目标函数,称为 *absolute-margin绝对边缘目标
score function
(不真实性)评分函数F评估三元组(h;r;t)的不真实性; 分数越小,表示三元组越可能成立。

- Vh、Vr和Vt分别是头、关系和尾部的嵌入向量。
- 该分数函数指出,首向量和关系向量vh+vr的和必须接近尾向量vt即vh+vr∼vt
; Pairwise-Margin Objective Function两两边际目标函数
- 目标(损失)函数定义通过优化使数量最小化。
- 以下成对边界目标函数通常用于知识图谱补全,

- 其中[x]+是铰链函数 [x]+=max(0,x)。
- τ是阈值(边距)
- (hi;ri;ti)表示正三元组
- (h0 i;ri;t0 i)表示负三元组。
- 这个目标函数要求f(h0i;ri;t0i)至少比f(hi;ri;ti)大τ。如果差值小于τ,则优化改变参数以满足要求。相反,如果差值大于τ,则不更新参数。因此,成对边缘的目标关注的是正负三联体对之间分数的差异。
Absolute-Margin Objective Function绝对目标函数
在本文中,我们采用了以下目标函数来代替成对的边际目标,我们称之为 绝对边际目标

- τ是一个超参数,又称为裕度。
- 这个目标函数在第一项和第二项中分别考虑正三胞胎和负三胞胎,而不是像成对边际目标那样同时考虑。正三胞胎的分数将优化为零,而负三胞胎的分数至少为τ。
- 该目标函数不仅易于优化,而且在初步实验中取得了良好的效果。因此,我们在第4节的实验中使用了这个目标函数
; 实验
4.1实现和超参数
- 我们使用 神经网络库chainer实现了我们的模型。
- 所有网络均采用 随机梯度下降法和 反向传播法进行训练;
- 具体而言,我们使用了 Adam优化方法。Adam的步长为α1=(α2·k+1:0),其中k表示执行的周期数,α1=0:01,α2=0:0001。
- 每个实验的最小批量为5000个,训练周期为300个。
- 此外,在标准三元组分类中嵌入空间的维数为200,在其他设置下为100。在初步的实验中,我们尝试了几种激活函数和池函数,并根据计算时间和性能发现了以下超参数设置。我们用了等式(5)-(6)在标准KB和OOKB设置中都作为传输功能。
- 池函数,我们使用了标准三元组分类中的 max pooling函数,并尝试了三个池函数 max,sum,average,在OOKB设置中。初步实验的结果反映在我们选择 绝对边缘目标函数而不是成对边缘目标函数上。
- 绝对裕度目标函数(式(8))。绝对边缘目标函数比两两边缘目标函数收敛更快。
- 由于任务是将三元组分成正(即,必须存在于知识库中的关系)和负三元组(不能存在的关系)的二元分类,因此我们 使用验证数据确定了这些类之间 输出分数的阈值。
- 为了处理有限的可用计算资源(如GPU内存), 当一个实体拥有太多的相邻实体时,我们随机抽取它们。事实上,有一些实体出现在大量的三胞胎中,因此有许多邻居;当邻域大小 超过64时,我们从邻居中随机选择64个实体。
4.2标准三元组分类
- 在标准补全任务中,我们将我们的模型与以前的KBC模型进行了比较,其中没有涉及OOKB实体。
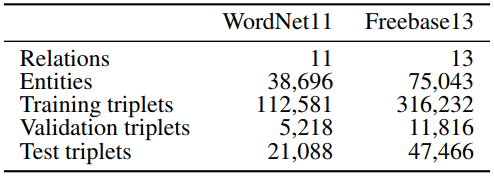
- 两个数据集都包含训练集、验证集和测试集。验证和测试集包括阳性和阴性三元组。相反,训练集不包含负三元组。与通常情况下,负三元组不可用的情况一样,由正三元组生成的损坏三元组被用作负三元组的替代品。
- 通过将从E(G)中取样的随机实体替换为h或t来生成损坏的三元组。具体而言,为了生成损坏的三元组,我们使用了”Bernoulli”技巧。结果见表2。
我们的模型在WordNet11数据集上显示了最先进的性能。在Freebase13数据集上,它的性能不如最先进的KBC方法,但也好于TransE方法。

; 4.3 OOKB实体实验
数据集
- 我们处理WordNet11数据集,为OOKB实体实验构建多个数据集:
- 从测试集中抽取的OOKB实体的数目和位置不同,共构建了9个数据集。该过程包括两个步骤: 选择OOKB实体和过滤并拆分三元组。
1.选择OOKB实体。
- 我们首先从WordNet11测试文件中选择N=1000、3000和5000的三元组。
- 对于这三个集合中的每一个,我们用三种不同的方式选择OOKB实的初始候选对象(因此总共产生九个数据集);这些设置称为Head、Tail和Both。在Head设置中,N个三元组中的所有Head实体都被视为候选OOKB实体。Tail设置类似,但尾部实体被视为候选对象。在”Both”设置中,所有显示为头部或尾部的实体都是候选对象。
- 最后的OOKB实体是出现在WordNet11训练集中的三元组(e;r;e’)或(e’;r;e)中的实体e,其中e’包含在已有的知识库中,而不是OOKB实体中。
- 最后一个过程筛选出与训练实体没有任何连接的候选OOKB实体。
2.过滤和分裂三元组。
- 使用所选的OOKB实体,将原始训练数据集分割为训练数据集和OOKB实体问题的辅助数据集。也就是说,不包含OOKB实体的三元组放在OOKB训练集中,而包含一个OOKB实体和一个非OOKB实体的三元组放在辅助集中。包含两个OOKB实体的三元组被丢弃。
- 对于测试三元组,我们使用了与步骤1中相同的WordNet11测试文件中的前N个三元组,只是删除了不包含任何OOKB实体的三元组。
- 对于验证三元组,我们只需从WordNet11验证集中删除包含OOKB实体的三元组。生成的OOKB数据集的详细信息如表3所示。
表3:OOKB数据集中的实体和三元组的数量。适三元组的数目包括负三元组。

我们用{Head;Tail;Both}-{1000;3000;5000}分别表示九个数据集中的每一个,其中第一部分表示OOKB实体的位置,第二部分表示用于生成OOKB实体的三元组数。
; 结果
- 利用WordNet11生成的九个数据集,我们验证了我们提出的模型的有效性。
- 我们使用以下简单的方法作为本实验的 基线。给定一个OOKB实体u,我们首先使用TransE获得邻域的嵌入向量(由辅助知识中的三元组确定),然后使用池函数sum、max或average将这些向量转换为u的表示向量。注意,由于u的所有邻域实体都在训练知识库中,因此可以使用标准KBC方法计算它们的向量。我们遵循了TransE的原始论文,对超参数和其他设置进行了研究。

表4:OOKB实验的结果:简单基线和论文模型的准确性。粗体和带下划线的数字分别是每个数据集的最佳和次优分数。
结果见表4。标记为”pooling”的列指示使用了哪个池函数。 - 如表所示,我们的模型大大优于基线。特别是在所有数据集上,具有 平均池化的图神经网络的性能优于其他方法。带有最大池的图NN也显示出很好的准确性,但是在一些设置中,例如Tail-3000,它比使用平均池的基线模型表现得更好。
4.4堆叠和展开图NNs
- 对我们来说,重要的是对节点进行堆叠和展开。
- 在这个实验中,我们说明了堆叠和展开在标准三元组分类任务中的效果。
- 数据集是WordNet11,用于标准三元组分类。精度比较表5显示了堆叠和展开图NNs的性能。

参数”depth” 指示迭代应用传播模型的次数。请注意,当depth=1时,这两个模型将简化为香草图NN,其结果为87:8%,
如表2所示。这些结果意味着 堆叠和展开技术并不能改善性能*。
我们相信这是因为嵌入模型的强大功能,也就是说,我们可以将有关遥远节点的信息嵌入到连续的空间中。
5.结论
本文提出了一种新的KBC任务,其中包含训练时未观测到的实体。为此,我们提出了一种适合KBC的图NN。我们进行了两个三元组分类任务来验证我们提出的模型的有效性。在OOKB实体问题中,我们的模型大大优于基线。我们的模型还显示了在标准KBC设置下WordNet11的最新性能。
Original: https://blog.csdn.net/minggelin1997/article/details/111083152
Author: 大铭昕
Title: 【论文】Knowledge Transfer for Out-of-Knowledge-Base Entities: A Graph Neural Network Approach
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/595616/
转载文章受原作者版权保护。转载请注明原作者出处!