



这篇文章通过提出了一种注意力机制对齐的方法,为预训练语言模型在 fine-tuning阶段引入了多源分词信息外部知识,从而提升了预训练语言模型在各个子任务上的效果。本文收录于 2020 年 ACL。
问题背景
BERT 出现后,预训练语言模型统治了大多数的NLP应用任务,预训练-微调这一2-stage 模式成为了主流。随着预训练语言模型的不断发展,预训练任务和模型结构被不断改进,以让模型适配更大量的数据的数据,以及从更多途径获取各种外部知识。
对于中文预训练语言模型来说,最实用、直接的方法便是引入词汇级别的知识了。例如,baidu-ERNIE1.0、BERTwwm 尝试融入实体级别/词级别的信息、 thu-ERNIE 尝试将知识图谱融入语言模型并对齐、ZEN 尝试使用 n-gram 导入词信息等。

(上图为阅读中文时人眼动的注意力分布,基本在单个词间均匀分布)
如 Is Word Segmentation Necessaryfor Deep Learning of Chinese Representations 一文所描述,字级别的建模对于中文自然语言处理来说更加合适。同时已有大量工作证明,通过在字级别的模型之上引入词汇特征可以提升模型效果(尤其对于注重区分词汇边界的任务更是如此,如NER、Span-MRC 等)。而目前在字模型中融入词模型的方法普遍存在一些问题,例如:主流采用 Gazetteer 等形式的词表进行引入(如 LatticeLSTM 及其变体模型),泛用性不够高;前人工作全部使用的是单个来源的词汇信息,当出现词表错误、分词错误等情况时,反而会造成反效果。
因此,作者试图构建一种能直接获取分词这种通用的词汇信息的方法,并整合多种来源的分词结果,以提高模型的泛用性,并降低单个词表和分词工具中误差对模型造成的影响。
方法原理
作者使用BERT及其针对中文改进并二次微调的ERNIE 1.0、BERTwwm作为基线模型。这几个模型皆为字级别的模型,因此输出可视为字级别的编码器。在字编码器输出的字表示之上接入 Self-Attention 层,如下图所示:
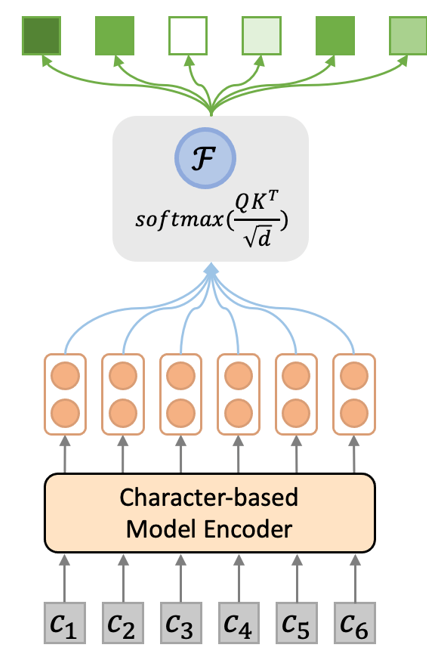


对字表示的 Self-Attention 的权重应用此划分 π,可以得到按词组合的字到字的Attention 权重矩阵:
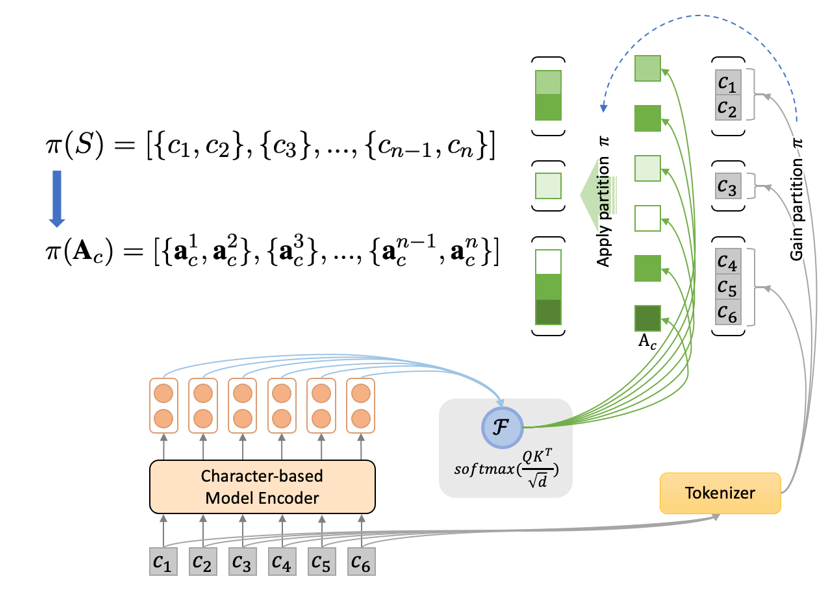

将此步的 Attention 权重进行可视化,可以得到与前文眼动注意力示意图类似的结果。作者在情感分类任务模型中对”今天的云非常好看”句子进行了可视化,在此步得到的字-词 Attention 权重矩阵的可视化结果如下图所示:

可以看到对句子情感极性影响较大的”好看”一词在 Attention矩阵中成分占比更大,可能在下游的分类中产生更多的贡献。
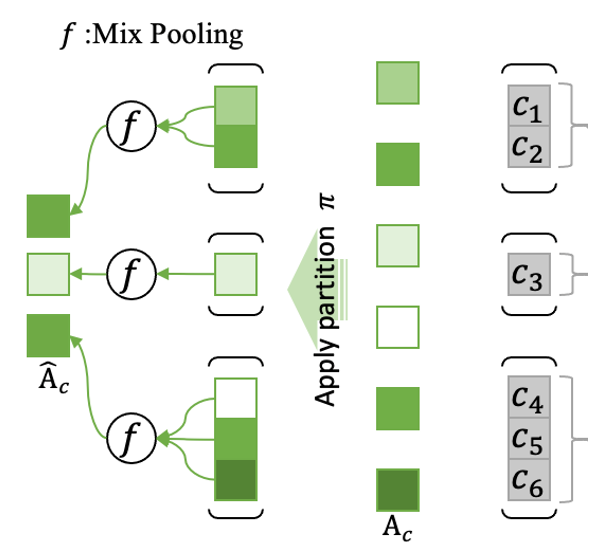
最后,作者使用 upsampling 的方式将上述 字-词级别Self-Attention 的权重矩阵按照分词划分的逆操作重新上采样至字级别,如图所示:
由此,就得到了融入一种分词信息之后的字级别 Self-Attention权重矩阵了。将此权重乘回字级别编码器得到的字表示上,即可得到与原模型完全对齐的、引入了分词信息的增强后的表示了。将上述步骤结合起来,整个模型结构如下图所示:

此时,模型获取的是单独一种分词方式 π 得到的增强字级别表示。然而,在更多情况下,单个分词工具得到的结果不一定准确,或是分词的粒度不一定符合任务的预期。下表展示了使用三种流行的分词工具对同一个句子进行分词得到了三个不同的结果:
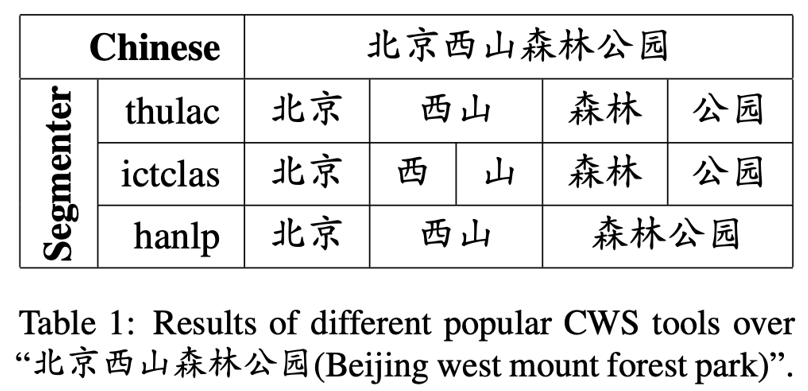
在本例子中,这几个分词器得到的结果都是对的,但是其粒度不同。为了减少分词错误,以及用上不同粒度级别的特征,作者使用了一种简单的方法,同时用上多个分词工具的分词结果:


实验
由于这篇文章是在中文预训练语言模型上进行的拓展工作,因此作者对常用的中文预训练语言模型任务都进行了实验。

其中,任务具体包括了情感分类(ChnSentiCorp 与 weibo-100k两个数据集)、命名实体识别(ontonotes 数据集)、句子对匹配(LCQMC 数据集)、自然语言推断任务(XNLI 数据集)、中文阅读理解(DRCD 数据集)。
在这些任务上,作者以 BERT、baidu-ERNIE 1.0、BERTwwm三个模型分别作为基础模型进行增强,并同时也做为基线模型进行对比,得到的实验结果如下表所示:

可以看到,融入多源分词信息后,各个中文预训练语言模型都在各个任务上得到了普遍的提升。其中,MRC阅读理解任务提升比较明显,经过 Case Study 作者发现融入分词信息后,发现模型预测出的答案相比原始模型更加准确,部分原始模型正确预测了大多部分文本,却在词边界出现问题的情况减少了。

同时,作者进行了消融实验,对比了使用单个分词工具与使用多源分词工具以及随机分词工具的效果:
与前文一致,使用多种分词工具的结果比使用单个分词工具得到的结果要好。
总结
本文提出了一种新颖的融入外部知识的方法,可以通过融入多种分词工具增强中文预训练语言模型的效果,实验证明在多种下游中均有效果。并且这种方法虽然引入了大量的外部知识,但在空间占用上并没有提升多少:

参数量基本与原始模型持平。
然而,在时间消耗上这个模型仍然有不少的进步空间。首先,由于改变了 Self-Attention的矩阵运算,变成了一个样本一个样本各自计算其不同的组合方式,因此无法借助 cudnn 原语加速,且把时间复杂度 O(n2) 增加了常数倍 O(dn2),d 是平均样本长度,因此增加了模型在训练与推断时的速度。此外,由于模型需要预先处理好分词结果,因此增加了不少预处理时间与预处理难度。如果能对此模型进行性能改进、适配GPU 加速,才能真正用于生产环境中提高模型效果。


Original: https://blog.csdn.net/weixin_48167662/article/details/109463240
Author: PKUMOD
Title: 论文导读 | 基于注意力机制对齐增强预训练语言模型
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/595412/
转载文章受原作者版权保护。转载请注明原作者出处!