

摘要
关系抽取旨在识别命名实体之间的语义关系.作为自然语言处理中信息抽取的重要子任务,是构建知识图谱,实现语义搜索,建立智能问答系统等应用领域必不可少的关键技术,具有极其重要的研究价值.关系抽取研究的热点经历了知识工程,传统机器学习,深度学习三个不同阶段.本文研究了卷积神经网络应用于实体关系抽取的应用,采用了SemEval-2010 Task 8数据集作为实验测试数据,使用GloVe对句子进行词向量表示,接着获取两个实体之间的距离特征共同作为Embedding层输入,通过拼接的方式将两种特征融合,最后用softmax分类器得出所属关系的类型。实验结果可得其宏F值为64%。
数据集描述
示例数据


句子:The inside WTC was caused by exploding .
关系:Cause-Effect(e2,e1)
训练集:共含8000条数据
typenumberrateOther141017.63%Cause-Effect100312.54%Component-Whole94111.76%Entity-Destination84510.56%Product-Producer7178.96%Entity-Origin7168.95%Member-Collection6908.63%Message-Topic6347.92%Content-Container5406.75%Instrument-Agency5046.30%
测试集:共含2717条数据
typenumberrateOther45416.71%Cause-Effect32812.07%Component-Whole31211.48%Entity-Destination29210.75%Message-Topic2619.61%Entity-Origin2589.50%Member-Collection2338.58%Product-Producer2318.50%Content-Container1927.07%Instrument-Agency1565.74%
由于两个实体具有方向性,可以认为(e1,e2)和(e2,e1)不相同,因此,对此数据集进行细致划分可以分为2*9+1=19类。
模型设计与实现
模型设计:
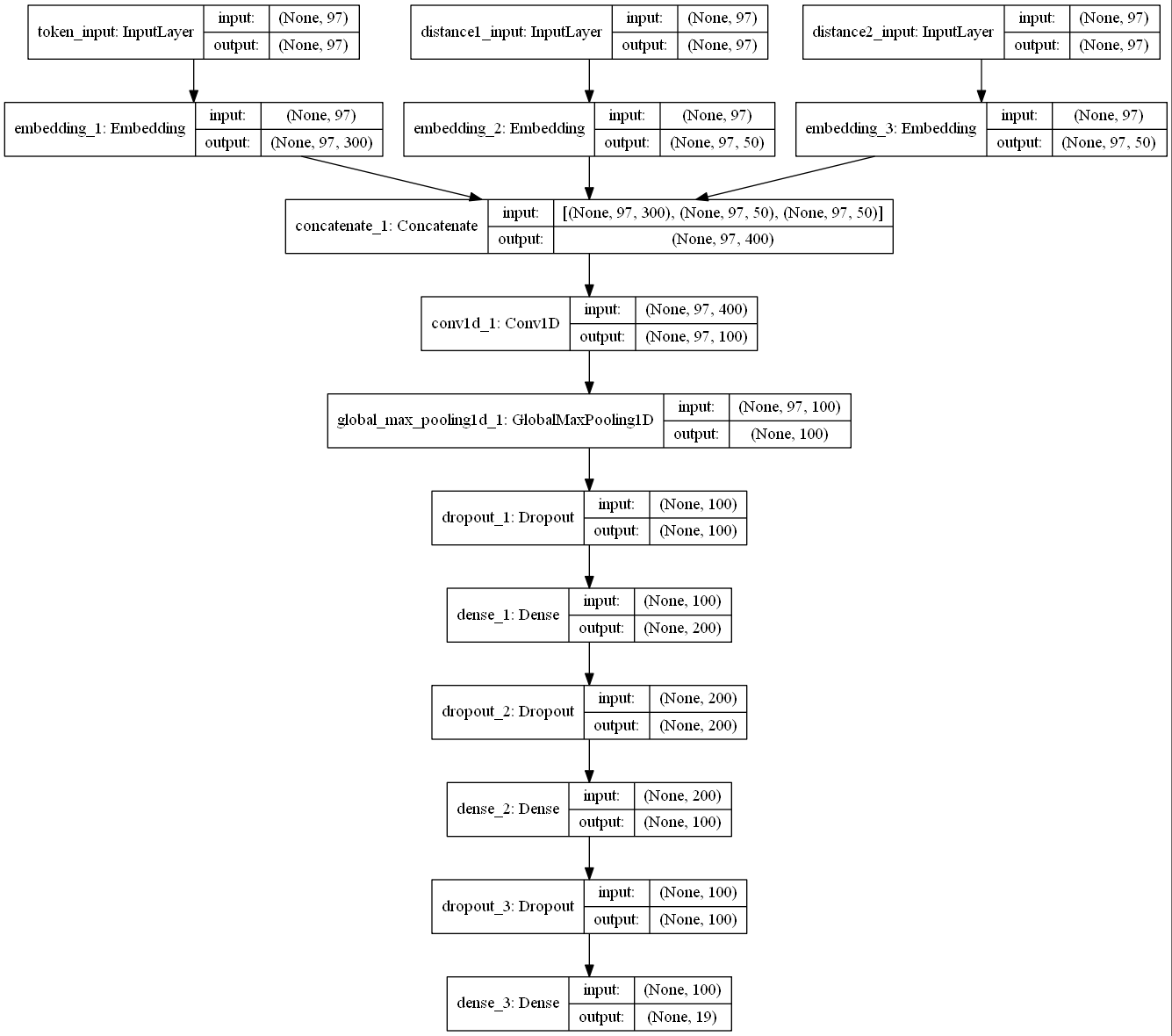
代码实现:
token_input = Input(shape=(config.MAX_TOKEN_LENGTH,), dtype='int32', name="token_input")
tokens = Embedding(embeddings.shape[0], embeddings.shape[1], weights=[embeddings], trainable=False)(token_input)
distance1_input = Input(shape=(config.MAX_TOKEN_LENGTH,), dtype='int32', name='distance1_input')
distance1 = Embedding(config.MAX_TOKEN_LENGTH, config.POSITION_DIM)(distance1_input)
distance2_input = Input(shape=(config.MAX_TOKEN_LENGTH,), dtype='int32', name='distance2_input')
distance2 = Embedding(config.MAX_TOKEN_LENGTH, config.POSITION_DIM)(distance2_input)
output = concatenate([tokens, distance1, distance2])
output = Convolution1D(filters=config.FILTER_NUMBER,
kernel_size=config.FILTER_SIZE,
padding='same',
activation='tanh',
strides=1)(output)
output = GlobalMaxPooling1D()(output)
output = Dropout(config.DROP_VAL)(output)
output = Dense(config.HIDDEN_LAYER1, activation='tanh')(output)
output = Dropout(config.DROP_VAL)(output)
output = Dense(config.HIDDEN_LAYER2, activation='tanh')(output)
output = Dropout(config.DROP_VAL)(output)
output = Dense(out_number, activation='softmax')(output)
model = Model(inputs=[token_input, distance1_input, distance2_input], outputs=[output])
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['acc'])
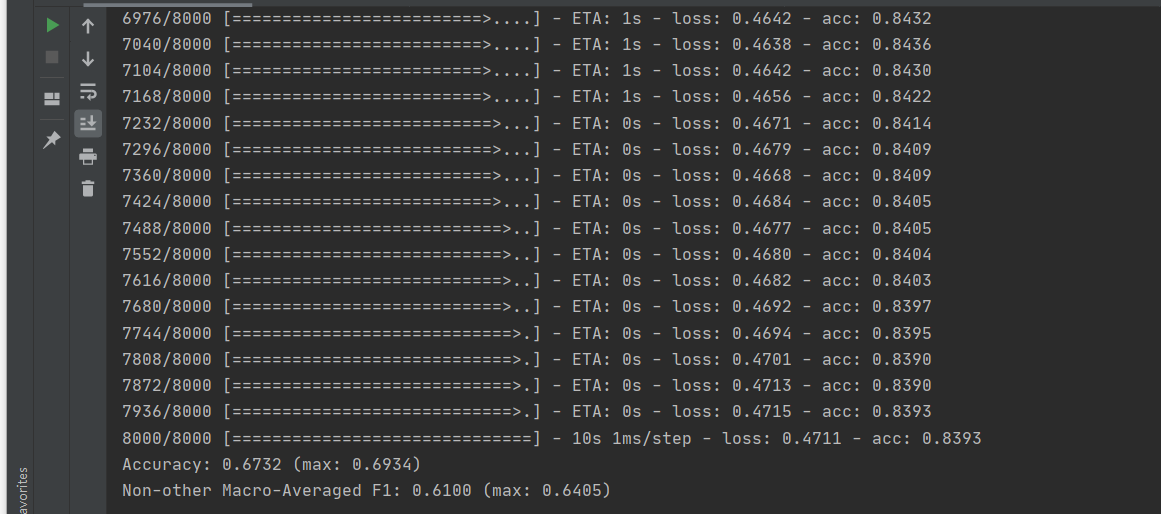
结论
我们的实验结果表明:(1)采用卷积神经网络和GloVe词嵌入特征可以获得不错的关系分类准确率;(2)使用位置特征可以增强实体关系抽取的准确率。下一步将测试多种模型在该数据集上的表现性能。
参考文献
-
Zeng D, Liu K, Lai S, et al. Relation Classification via Convolutional Deep Neural Network[C]. international conference on computational linguistics, 2014: 2335-2344.
-
Zeng D, Liu K, Chen Y, et al. Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks[C]. empirical methods in natural language processing, 2015: 1753-1762.
-
Santos C N, Xiang B, Zhou B, et al. Classifying Relations by Ranking with Convolutional Neural Networks[J]. international joint conference on natural language processing, 2015: 626-634.
Original: https://blog.csdn.net/weixin_40651515/article/details/112456125
Author: 就是求关注
Title: 基于卷积神经网络的实体关系抽取(SemEval-2010 Task-8数据集)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/595240/
转载文章受原作者版权保护。转载请注明原作者出处!