

目录
准备工作
MySQL安装和配置方法,链接:
https://blog.csdn.net/shankezh/article/details/115011889
可以直接使用sql文件导入,链接在:
https://download.csdn.net/download/shankezh/15939127
数据导入
使用命令行导入执行:
mysql -u root -p < kg_movie.sql
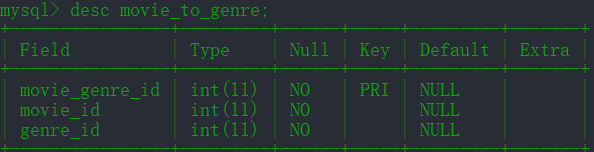
数据库中共五张表
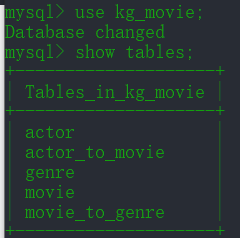

actor:
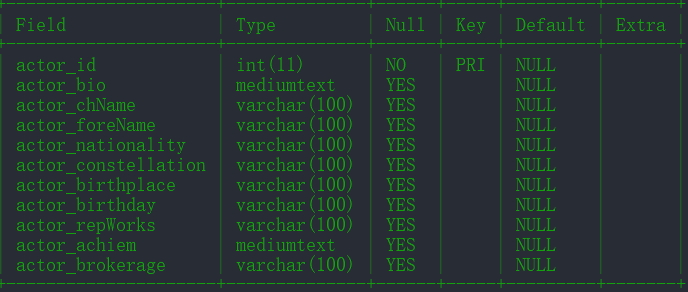
actor_to_movie:
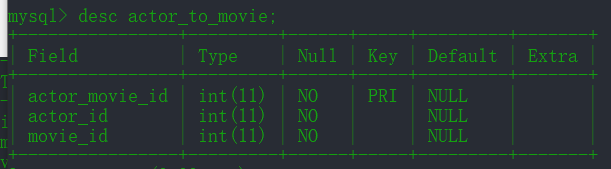
genre:
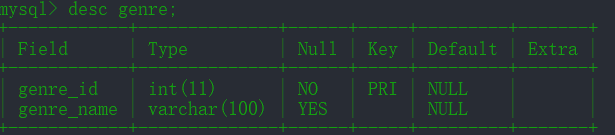
movie:
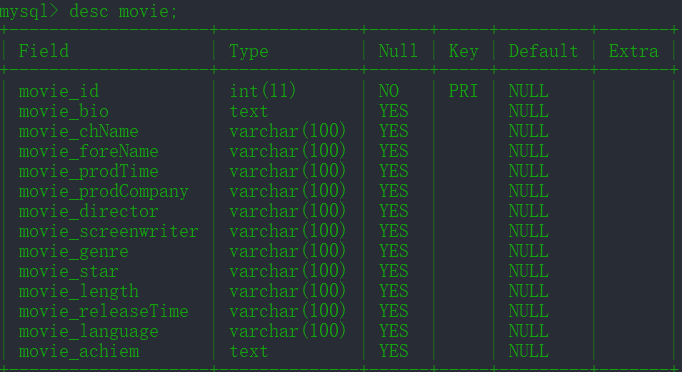
movie_to_genre:
数据修正
为什么要修正
这个数据如果直接使用的话,如果你按照网上其他教程应该到SPARQL查询会出现问题,大体出现的问题就是查询基本上没有变化或者是失败的,原因如下:
1、数据多表关联没做,例如电影到类型,演员到电影这两张表并没有真正关联引用到movie,actor,genre这三个表,当然,你可以自己做逻辑来弥补问题,但肯定无法按照网上的其他博主的教程获得其结果,目前我还不知道他们到底是怎么会出现正确结果;
2、对于movie_to_genre, actor_to_movie这两表数据也不全。
如何做
因此我们需要做如下工作:
1、关联关系表,即将actor_to_movie关联到 actor 和 movie两张表, movie_to_genre关联到 movie和genre两张表;
2、重新生成两张关联表的数据。
操作步骤
关联关系表
进入控制台,登录mysql,开始如下流程:
1、删除无用行:
在actor_to_movie中删除actor_movie_id,如下指令:
alter table actor_to_movie drop actor_movie_id;
在movie_to_genre中删除movie_genre_id,如下指令:
alter table movie_to_genre drop movie_genre_id;
变更后如下:

2、添加外键约束:
alter table actor_to_movie add constraint actor_movie_id foreign key (actor_id) references actor (actor_id) on delete no action on update no action;
上面是关联actor表,下面是关联movie表;
alter table actor_to_movie add constraint movie_actor_id foreign key (movie_id) references movie (movie_id) on delete no action on update no action;
on delete no action on update no action是添加条件,指主表如果要删除和更新数据时,如果引用了外键,则不允许被删除和更新;
添加完成后如下,查看指令在下面:
show create table actor_to_movie;
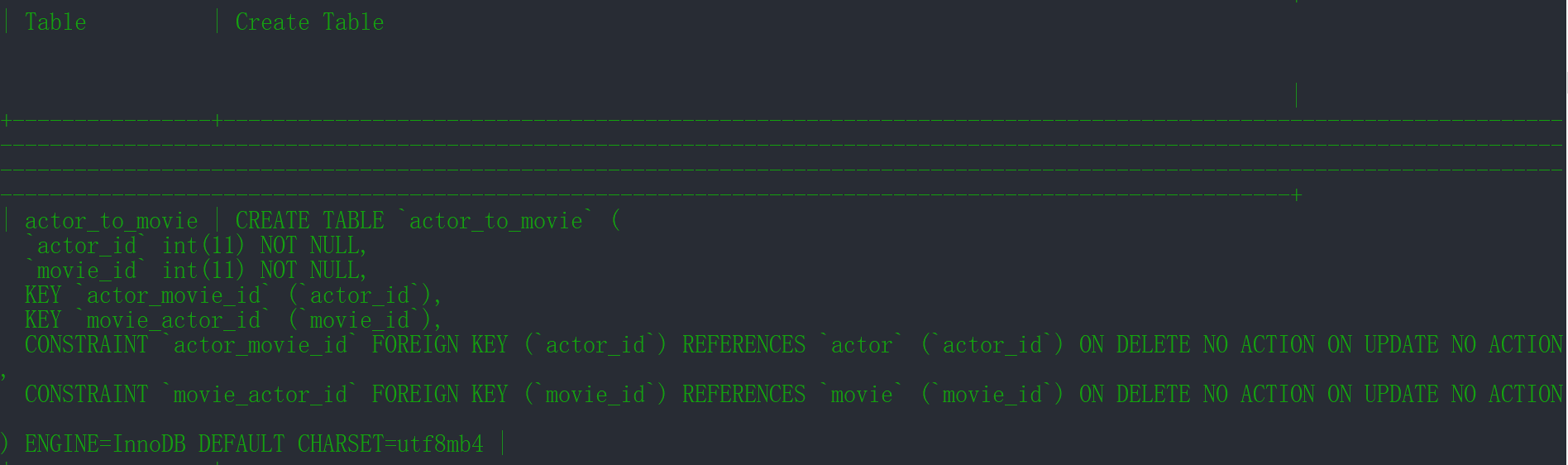
同理,对movie_to_genre表进行关联:
alter table movie_to_genre add constraint movie_genre_id foreign key (movie_id) references movie (movie_id) on delete no action on update no action;
alter table movie_to_genre add constraint genre_movie_id foreign key (genre_id) references genre (genre_id) on delete no action on update no action;
查看结果:
show create table movie_to_genre;

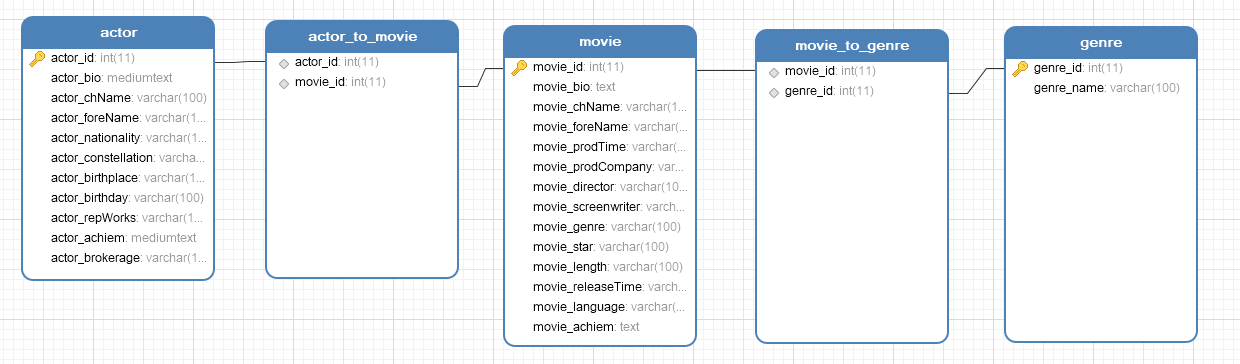
也可以使用Navcat来看ER图看关联关系:
更新关联表数据
先删除actor_to_movie和movie_to_genre两个表里的数据:
delete from actor_to_movie;
delete from movie_to_genre;
然后关联表单:
关联更新的思路无非就是查询actor在movie表中的参演列,movie中类型和genre类型匹配关系,由于sql语句查询不专业,所以直接用python执行逻辑插入,代码如下:
import MySQLdb
from pprint import pprint
class SQL_OP():
def __init__(self,ip,user,psd,db,charset):
self.ip = ip
self.user = user
self.password = psd
self.db = db
self.charset = charset
def open(self):
# 打开数据库连接
self.db = MySQLdb.connect(self.ip, self.user, self.password, self.db, charset = self.charset)
# 使用cursor()方法获取操作游标
self.cursor = self.db.cursor()
print("数据库打开")
def get_execute(self, sentence):
self.cursor.execute(sentence)
print("数据获取完成")
return self.cursor.fetchall()
def set_execute(self, sentence):
try:
self.cursor.execute(sentence)
self.db.commit()
except:
self.db.rollback()
print("指令执行异常")
print("指令执行完成")
def close(self):
self.db.close()
print("数据库关闭")
def sql_generate_relation():
data_movie = None # 电影数据
data_actor = None # 演员数据
data_genre = None # 类型数据
data_actor_to_movie = None # 关联 m 与 a
data_movie_to_genre = None # 关联 m 与 g
data_actor_to_movie = list()
data_movie_to_genre = list()
sql_op = SQL_OP(ip="localhost", user="root", psd=".root", db="kg_movie", charset='utf8')
sql_op.open()
data_movie = sql_op.get_execute("select * from movie")
data_actor = sql_op.get_execute("select * from actor")
data_genre = sql_op.get_execute("select * from genre")
for actor in data_actor:
for movie in data_movie:
if actor[2] in movie[9]:
data_actor_to_movie.append((actor[0], movie[0]))
for genre in data_genre:
for movie in data_movie:
if genre[1] in movie[8]:
data_movie_to_genre.append((movie[0], genre[0]))
# pprint(data_actor_to_movie)
# print(len(data_actor_to_movie)) # 9711
# pprint(data_movie_to_genre)
# print(len(data_movie_to_genre)) # 14370
count = 0
# insert data to movie
sql = r'insert into actor_to_movie(actor_id,movie_id) values'
for actor_movie in data_actor_to_movie:
sql_actor_movie = sql + str(actor_movie)
sql_op.set_execute(sql_actor_movie)
count += 1
print("actor_movie progress :" ,str(count) , ' / ' , str(len(data_actor_to_movie)))
print("actor_movie 执行完成")
count = 0
sql = r'insert into movie_to_genre(movie_id,genre_id) values'
for movie_genre in data_movie_to_genre:
sql_movie_genre = sql + str(movie_genre)
sql_op.set_execute(sql_movie_genre)
count += 1
print("movie_genre progress :", str(count), ' / ', str(len(data_actor_to_movie)))
print("movie_genre 执行完成")
print("执行完成")
sql_op.close()
def sql_data_clean():
sql_op = SQL_OP(ip="localhost", user="root", psd=".root", db="kg_movie", charset='utf8')
sql_op.open()
data_movie = sql_op.get_execute("select * from movie")
# movie_bio 清洗掉 "
count = 0
for movie in data_movie:
if r'"' in movie[1]:
count += 1
print(r'find id : ', str(movie[0]) ,"... progress : " , str(count), " / ", len(data_movie))
movie_bio = movie[1].replace(r'"',r'')
sql = r"update movie set movie_bio ='%s' where movie_id = '%d' "%(movie_bio,movie[0])
sql_op.set_execute(sql)
print("movie_bio符号替换完成")
sql_op.close()
if __name__ == '__main__':
sql_generate_relation()
# sql_data_clean()
代码不解释了,很基础,不要多次执行。
数据清洗
数据中存在一些特殊符号,这一步如果不清晰,会在以后的导入neo4j可视化时出现问题,如果你不需要可视化,可以忽略这一步骤。
我们这里使用代码进行清洗,目的是替换掉其中的引号” .
我们使用python进行快速清洗
import MySQLdb
from pprint import pprint
class SQL_OP():
def __init__(self,ip,user,psd,db,charset):
self.ip = ip
self.user = user
self.password = psd
self.db = db
self.charset = charset
def open(self):
# 打开数据库连接
self.db = MySQLdb.connect(self.ip, self.user, self.password, self.db, charset = self.charset)
# 使用cursor()方法获取操作游标
self.cursor = self.db.cursor()
print("数据库打开")
def get_execute(self, sentence):
self.cursor.execute(sentence)
print("数据获取完成")
return self.cursor.fetchall()
def set_execute(self, sentence):
try:
self.cursor.execute(sentence)
self.db.commit()
except:
self.db.rollback()
print("指令执行异常")
print("指令执行完成")
def close(self):
self.db.close()
print("数据库关闭")
def sql_generate_relation():
data_movie = None # 电影数据
data_actor = None # 演员数据
data_genre = None # 类型数据
data_actor_to_movie = None # 关联 m 与 a
data_movie_to_genre = None # 关联 m 与 g
data_actor_to_movie = list()
data_movie_to_genre = list()
sql_op = SQL_OP(ip="localhost", user="root", psd=".root", db="kg_movie", charset='utf8')
sql_op.open()
data_movie = sql_op.get_execute("select * from movie")
data_actor = sql_op.get_execute("select * from actor")
data_genre = sql_op.get_execute("select * from genre")
for actor in data_actor:
for movie in data_movie:
if actor[2] in movie[9]:
data_actor_to_movie.append((actor[0], movie[0]))
for genre in data_genre:
for movie in data_movie:
if genre[1] in movie[8]:
data_movie_to_genre.append((movie[0], genre[0]))
# pprint(data_actor_to_movie)
# print(len(data_actor_to_movie)) # 9711
# pprint(data_movie_to_genre)
# print(len(data_movie_to_genre)) # 14370
count = 0
# insert data to movie
sql = r'insert into actor_to_movie(actor_id,movie_id) values'
for actor_movie in data_actor_to_movie:
sql_actor_movie = sql + str(actor_movie)
sql_op.set_execute(sql_actor_movie)
count += 1
print("actor_movie progress :" ,str(count) , ' / ' , str(len(data_actor_to_movie)))
print("actor_movie 执行完成")
count = 0
sql = r'insert into movie_to_genre(movie_id,genre_id) values'
for movie_genre in data_movie_to_genre:
sql_movie_genre = sql + str(movie_genre)
sql_op.set_execute(sql_movie_genre)
count += 1
print("movie_genre progress :", str(count), ' / ', str(len(data_actor_to_movie)))
print("movie_genre 执行完成")
print("执行完成")
sql_op.close()
def sql_data_clean():
sql_op = SQL_OP(ip="localhost", user="root", psd=".root", db="kg_movie", charset='utf8')
sql_op.open()
data_movie = sql_op.get_execute("select * from movie")
# movie_bio 清洗掉 "
count = 0
for movie in data_movie:
if r'"' in movie[1]:
count += 1
print(r'find id : ', str(movie[0]) ,"... progress : " , str(count), " / ", len(data_movie))
movie_bio = movie[1].replace(r'"',r'')
sql = r"update movie set movie_bio ='%s' where movie_id = '%d' "%(movie_bio,movie[0])
sql_op.set_execute(sql)
print("movie_bio符号替换完成")
sql_op.close()
if __name__ == '__main__':
#sql_generate_relation()
sql_data_clean()
完成。
Original: https://blog.csdn.net/shankezh/article/details/115014660
Author: 飘散风中
Title: 【知识图谱】02数据准备
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/595234/
转载文章受原作者版权保护。转载请注明原作者出处!