

该论文可直接在网上下载。
1. Abstract & Introduction部分
1 QA(question answering)的主要目的是generalize to unseen questions. 使得系统能够泛化到回答没有见过的问题。通俗一点的理解就是,机器可以根据自己的理解,回答一些未知问题,从而获得一定程度的”智能”。
2 一个可能的问题是:annotation 会导致unintended annotator bias 无意识地标记偏见。这个其实是个很常见的套话,反正是人标记都会有bias,导致模型过度专注于bias而不是任务本身。
3 本文就提出了KTL(Knowledge Triplet Learning), 一个关于知识图谱(Knowledge Graphs)的自监督任务。对于一些常识和科学知识的人工合成图,提供了启发(propose heuristics to create synthetic graphs for commonsense and scientific knowledge)
4 为了研究QA的各种方面,业界提供了很多数据集:
抽取式的(Extractive): SQuaD, HotpotQA, Natural Questions
答案可选择式的(choose the correct answer from given set): SocialIQA, CommonsenseQA, Winogrande.
最近的很多模型表现的也挺好: BERT,XLNET,Roberta等
5 这里的Winogrande数据集需要经过carefully designed crowdsourcing procedure 仔细设计的多人作业流程的unbiases label 无偏标记。所以非常耗费人力。(因为crowdsourcing就是要让一堆人来标记)。
6 通常类型的annotation可能会导致Clever Hans Effect (观察者期望效应),这会导致实验设计者无意识地影响实验步骤和结果,或者是错误地按照自己的意识将实验结果解释成了他们想要的答案。题外话:所以需要双盲实验来抵消这种效应。
其中一个解决办法就是如1.5那样,另一种是忽视label,使用无监督学习QA,同时也是本文要注重的方式。
7 Recent works:有些研究利用如维基百科之类的语料库(text corpus) 来建立synthetic data(合成的数据)来解决Extractive QA。其他的人利用大规模pre-train预训练,如GPT-2,来生成知识,问题,答案,并且和已知答案做对比。
8 本文会利用到知识图谱中的information present(信息展示?), 比如 ATOMIC模型,并且定义了KTL中的新任务。该文没有使用合适的知识图谱,而是使用人工合成的方式(synthetic)实现自己的图谱。
9 KTL有点像Knowledge Representation Learning 和 Knowledge Graph Completion,但不局限于此。其中前者用来学习–> 知识图谱中定义的实体(Entities) 和 关系的 低维映射(low-dimensional projected)和分布表示(distributed representation)。后者用来发现新的实体和关系,从而扩展未完成的知识图谱。
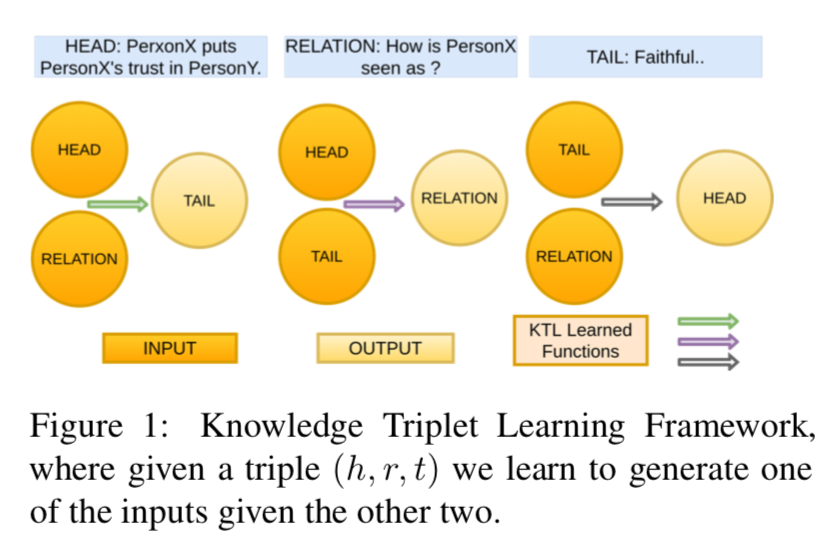

10 KTL中定义了三元组triplet, 如上图所示,知其二可以推三。这种三元关系(tri-directional)可以使得所有可能的关系都被学到,比如AB-C,AC-B,BC-A。然后把context, question, answer 映射成KTL三元组(h, r, t)。
11 定义两种不同的方式来实现自监督KTL。其中一种是表示生成任务(representation generation),另一种是masked language modeling(应该叫带掩码的语言建模?)
12 本文将尝试用在该任务上训练的模型(models trained on this task) 去实现zero shot QA,不加任何额外的监督。同样也会展示在该任务上预训练之后的模型(models pre-trained on this task),表现地非常好的那种,和在few-shot learning强预训练的模型(strongly pre-trained language models)
13 本文贡献:
a) 基于知识图谱定义了KTL,并且展示如何用来zero-shot QA.
b) 对上面的任务定义了两种策略
c) 提供了一些构建synthetic knowledge graphs的启发
d) 在之前提到的数据集上进行了实验
e) 在zero-shot上达到了state-of-the-art 很好的结果,为few-shot QA提供了强baseline。
; 2. KTL(Knowledge Triplet Learning)
14 定义G=(V,E)为知识图谱,V是定点,E是边。V包含了entities(可以是phrases和named-entities, 基于知识图谱) 。S是一系列的facts, S ⊆ V × E × V S\subseteq V \times E \times V S ⊆V ×E ×V,基于(h, r, t)的格式。其中h, t属于V,r属于E。更详细地说就是,h和t就是之前图片中的head和tail,而r是这些实体之间的relation。

这里原文给了个例子,PersonX信任Person Y, 问Person X是怎么被看作的的,答案是有信念的(faithful)。这里Head就是’PersonX信任Person Y’, tail 就是faithful, relation就是’How is PersonX sees as?’.
16 基于此定义的三元组(h, r, t), 可以获得三种function, f t ( h , r ) = > t , f r ( h , t ) = > r , f h ( r , t ) = > h ( 1 ) f_t(h, r)=> t, f_r(h, t) => r, f_h(r, t) => h \ (1)f t (h ,r )=>t ,f r (h ,t )=>r ,f h (r ,t )=>h (1 )
17 对于同样的context, 两个不同的问题可能都是对的,对于两个不同的问题,两个不同的答案可能都是对的,等等。学习这些function允许我们给context,question和answer之间不同的关系进行打分。
2.1 Using KTL to perform QA
18 基于自监督学习,学习了这些function之后,可以用来实现QA。给定一个三元组(h, r, t), 定义了以下的评分function:
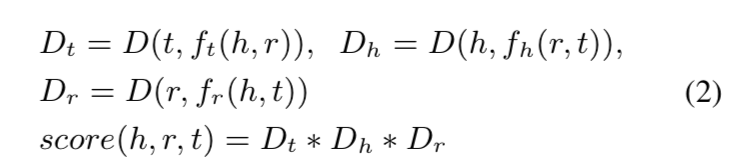
其中h是context,r是question,t是答案的其中一个选项。D是距离函数(distance function),用来测量预测的结果和给定结果的差距。
19 距离函数会根据framework的实例化而变化,最终定义为:
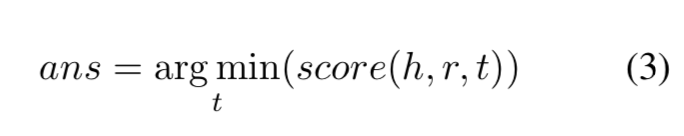
拥有最小分数的会被选中。
; 2.2 Knowledge Representation Learning(KRL)
20 原文:As our triples (h, r, t) can have a many to many relations between each pair, we first project the two inputs from input encoding space to a different space similar to the work of TransD
由于triplet (h, r, t) 在每一对中 可以有多对多的关系。首先把两个inputs从encoding空间映射到另一个和TransD相似的空间(TransD来自另一篇文章)。
然后通过Encoder 把三元组转换到encoding space。
需要学习两个映射函数projection functions M i 1 M_{i1}M i 1 和M i 2 M_{i2}M i 2 , 然后用第三个映射函数M 0 M_0 M 0 来映射生成的entity。
利用一个函数C来合并两个映射过的inputs。
这些函数都可以通过前向传播网络实现,
具体过程如下:
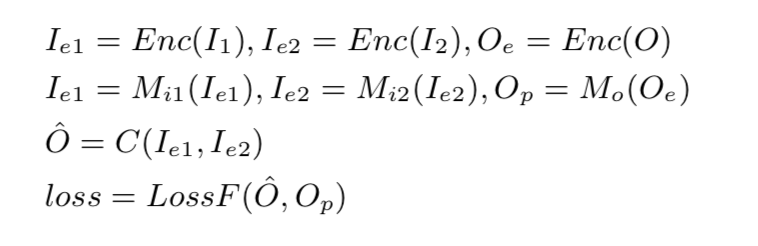
其中,I i I_i I i 是input,O ^ \hat{O}O ^是生成的输出向量,O p O_p O p 是映射向量。 函数M和C是通过全联接网络学习的。实现过程中,transfomer是利用的RoBERTa, [CLS] token 是phrase表示。
21 这个模型通过两种Loss训练。L2 loss (通过减小L2 norm的方式)和基于Noise Constrastive Estimation(混有k个噪音样本的ground-truth, 这些噪音样本是从其他三元组中选择的)的NCELoss。
NCELoss 被定义为:
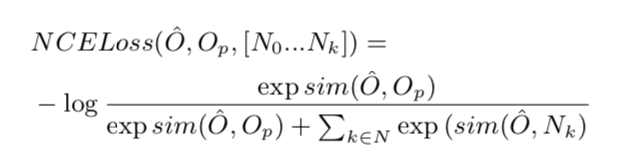
其中N k N_k N k 是映射的噪音样本,sim是相似度函数(L2 norm 或者余弦相似度), O ^ \hat{O}O ^是生成输出向量,O p O_p O p 是映射向量。
距离函数视情况而变化,对于L2Loss,它就是L2 norm,对于NCELoss们他就是1-sim
2.3 Span Masked Language Modeling(SMLM)
22 这个方法中,会把公式一(f t ( h , r ) = > t , f r ( h , t ) = > r , f h ( r , t ) = > h ( 1 ) f_t(h, r)=> t, f_r(h, t) => r, f_h(r, t) => h \ (1)f t (h ,r )=>t ,f r (h ,t )=>r ,f h (r ,t )=>h (1 ))进行建模。用一个分割token对(h, r, t) tokenize和concatenate,变成这样–>[cls][h][sep][r][sep][t][sep]。
对于f r ( h , t ) = > r f_r(h,t) => r f r (h ,t )=>r 会把所有r中的tokens都mask掉。比如这样, [cls][h][sep][mask][sep][t][sep]。
把他们都放到transformer中并用前向传播网络来揭开(unmask)token序列。相似的,在学习f h f_h f h 时就要mask h,学习f t f_t f t 时就要mask t。
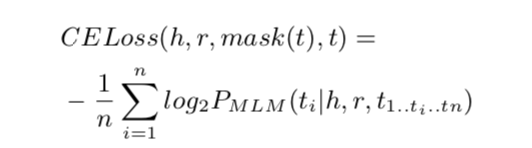
其中P M L M P_{MLM}P M L M 是token t i t_i t i 的masked语言建模的概率。给定一个没有掩盖的(unmasked)token h和r,以及t中的其他masked token。 注意这里并不使用progressive unmasking,就所有的masked tokens 都是联合预测的(jointly predicted)。
这里的距离函数和之前的一样。
3 Synthetic Graph Construction
人工图谱构建
23 并不是所有的知识都是以结构化知识图谱的方式呈现的,比如ATOMIC。这一段大概说了一下每个数据集的一些区别。比如QASC数据集中的问题需要一些关于科技概念的知识。为了通过知识和KTL实现QA,创造了以下两个graphs: Common Concept Graph, Directed Story Graph。
3.1 Common Concept Graph
24 为了创造这个,需要用Spacy Part-of-Speech Tagger 从每个句子中 提取noun-chunks 和 verb-chunks。所有提取的chunks都被分成graph的顶点。
25 为了生成KTL的训练样本,把每一个triplet(h, R, t)分配成(e 1 , e 2 , v i e_1, e_2, v_i e 1 ,e 2 ,v i )其中v i v_i v i 是两个句子e 1 e_1 e 1 和e 2 e_2 e 2 的common concept present(共有概念表示)。
本文基于QASC science 语料库和OMCS concept 语料库 创建两种 synthetic graphs。
26 hypothesis是graph和KTL框架可以使得模型理解两个facts中共有的概念(concepts common in two facts),从而允许QA
3.2 Directed Story Graph
27 这个graph是通过使用来自RoCStories和Story Cloze Test 中的short stories 创建的。该graph和3.1提到的graph是不同的,因为这个graph含有方向属性(directional property),并且每个独立story graph都是不相连的。
28 为了创建graph,把每个story分成k个句子,于是有[s 1 , s 2 , s 3 , s 4 . . . , s k s_1, s_2, s_3, s_4 …, s_k s 1 ,s 2 ,s 3 ,s 4 …,s k ] 并且创建一个有向图(directed graph), 所有的句子都是顶点,每个句子由一条有向边(directed edge) 指向它之后出现的句子(s1指向了s2,s2就不能指向s1)。
29 生成三元组(h, R, t)通过在顶点(s_i, s_j, s_k)中抽样 ,以此句子s i s_i s i 和s j s_j s j 之间就会有有向路径。
这种graph是用来理解story 和 abductive reasoning(溯因推理) , 在基于KTL的框架上
3.3 Random Samping&Curriculum Filtering
30 由于数据量太大,随机采样最多1百万的样本
31 从QA数据集呈现的context,question,answer选项中提取noun和verb chunks。这里有一个过滤规则,三元组中,至少一个entity是提取的noun和verb chunks的才能被选中。这个方式,和现实世界中人类的考试设置是一样的,其中老师会依据一些要问的问题提供一系列概念,然后学生就能学到很多概念。
32 这两个策略(sampling&filtering)只会在基于QASC和OMCS语料库生成的Common Concept Graph中使用
4 Datasets
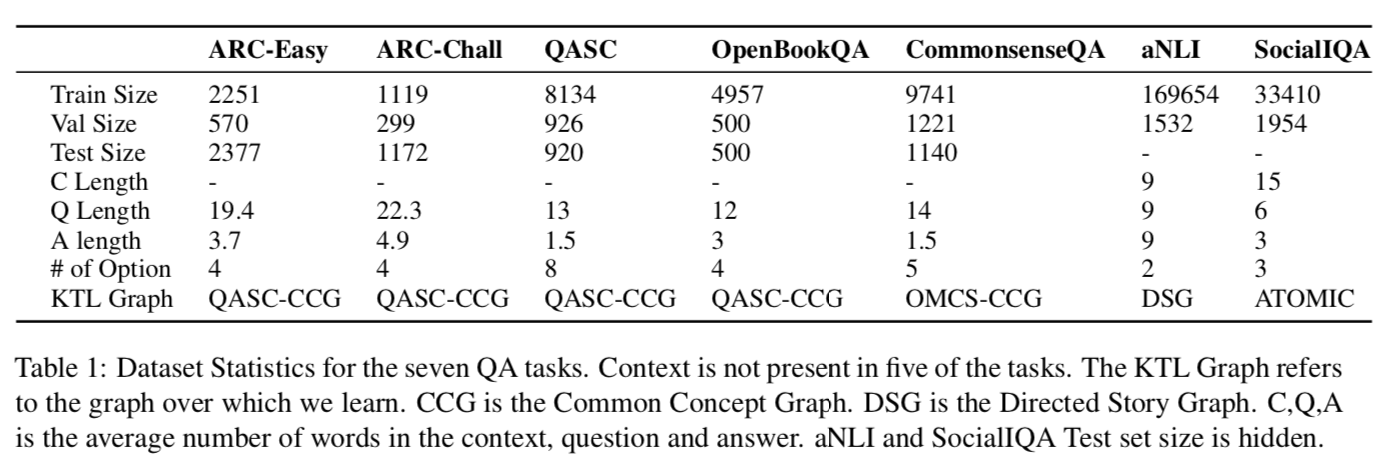
Table 1显示的是dataset的一些统计信息
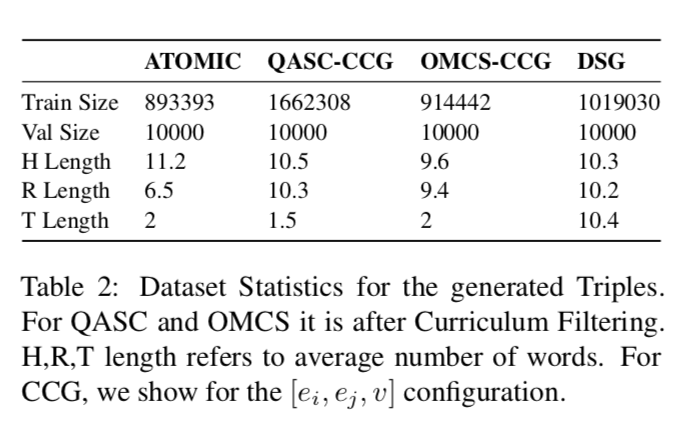
Table 2显示的是一些关于从graph中提取的triple的统计信息。
从以上两个table可以发现,和其他大型QA任务相比,KTL triple拥有不同数量的词。特别是当遇到如SocialIQA中内容非常大的时候并且有人类标注的情况时,无监督学习的难度提升了很多。
; 4.1 Question to Hypothesis Conversion and Context Creation
34
35 对于像QASC和CommonsenseQA中没有context的情况,本文提取top5 句子,通过question and answer options作为query的方式,并且展示了从依次的源资源知识句子语料库中提取(perform retrieval from respective source knowledge sentence corpus)。对于每个提取的context,我们使用公示(2)来验证answer option分数,并且取均值。
5 Experiments
5.1 Baselines
35 几个Baselines:GPT-Large,Pre-trained RoBerta-large,RoBerta-large,IR Solver 具体就不介绍了
5.2 KTL training
36 训练Knowledge Representation Learning任务时,L2 Loss 和NCE Loss都要考虑,对于NCE Loss,用L2 norm和余弦相似度训练它。KRL模型和SMLM模型都用RoBERTa-large 作为encoder。所有从训练graph中出来的triplet都是正样本。其他一些实验设置细节不再描述。
6 Results and Discussion
6.1 Unsupervised QA
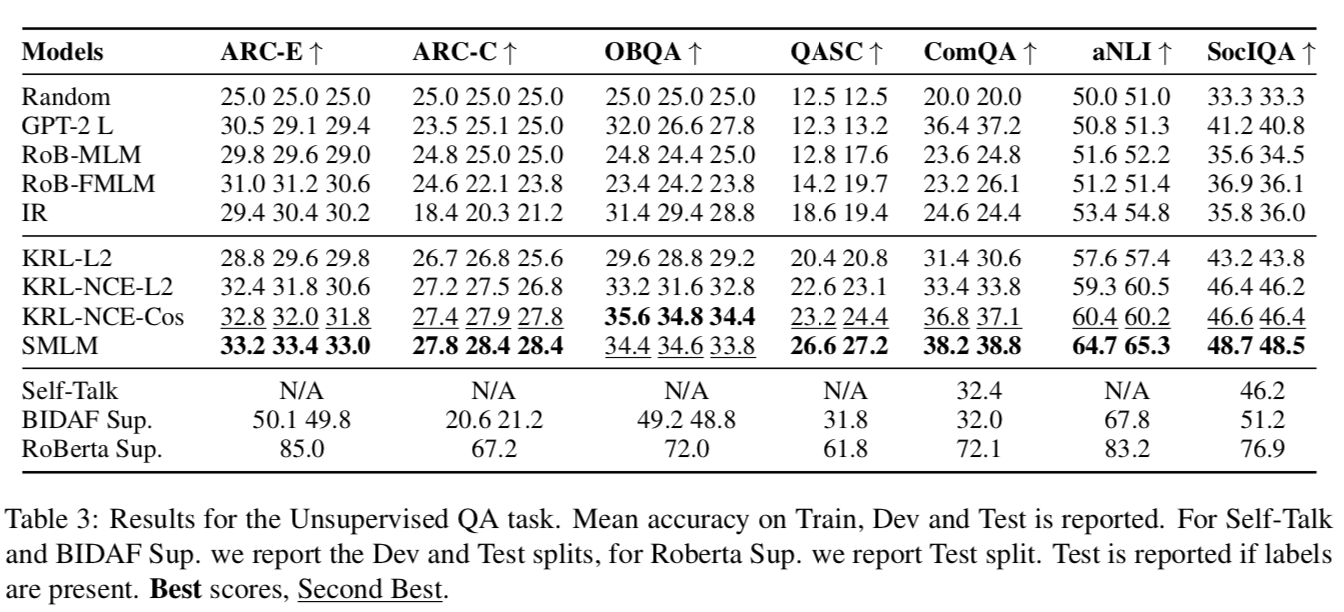
37 上面的Table 3比较了不同的KTL方法在4个baseline和6个QA数据集上的zero-shot QA任务,对ARC,QASC,OBQA等数据集利用了Hypothesis Conversion,Curriculum Filtering和Context Creation。
38 一些发现:我们的KTL比其他的好blabla。。当比较不同的KRL任务时,带有余弦相似度的NCE Loss表现最好。可能原因是负样本提供的额外的监督,因为L2 Loss模型只会尝试减小生成的输出和目标映射之间的距离。 当比较不同的KTL实例化时,SMLM基本上都是表现最好的。
Transformer中的多层attention使得SMLM模型能更好地区分true和false声明。
KRL中,尽管正负样本都学习了,但模型仍然是表现不佳的,通过分析发现,随机负采样可能会导致KRL训练任务有偏差(biased)。未来任务可能会注重于利用交替负采样(alternative negative sampling), 比如选择更接近于上下文向量空间(contextual vector space)的样本。
在ARC-Challenge 任务里的提升是非常小的,他们发现尽管QASC包含大量科学事实,但仍然没有包含足够的知识去回答ARC问题。
SocialIQA,aNLI, QASC 和 CommonsenseQA中有大幅度提升,因为他们的KTL knowledge 语料库包含足够的知识来回答问题。
一个有趣的现象时,对于QASC,可以将problem从8分类变成4分类(4-way classification),因为QASC的top-4 准确度高达92%。
; 6.2 Few-shot QA

39 Table 4 比较了KTL预训练transformer encoder在few-shot QA上的表现。这些encoder都是被一个简单的前向传播网络,基于n分类fine-tune过的。 可以发现KTL预训练encoder比其他baselines表现的好。
后面还有一些ablation study和related work就不再过多讲述。
模型代码可以在这里获得
Original: https://blog.csdn.net/OldDriver1995/article/details/113886133
Author: FrenchOldDriver
Title: 论文导读: Self-Supervised Knowledge Triplet Learning for Zero-shot Question Answering
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/595226/
转载文章受原作者版权保护。转载请注明原作者出处!