

©NLP论文解读 |杨健
论文标题:
ERNIE:Enhanced Language Representation with Informative Entities
收录会议:ACL
论文链接:
https://arxiv.org/abs/1905.07129
项目地址:
https://github.com/thunlp/ERNIE


问题
论文作者认为尽管预训练语言模型能够从大规模文本语料中学习到词法、语法等信息,然而这些预训练模型却忽略了知识图谱提供的知识。
这些知识能够为预训练模型提供实体的语义以及实体间的关联,从而提高预训练模型的理解能力。
我们以下面这一句子为例解释知识图谱如何提高预训练模型的理解能力。
Bob Dylan wrote Blowin’ in the Wind in 1962, and wrote Chronicles: Volume One in 2004.
如果我们不知道Blowin’ in the Wind是一首歌,而Chronicles: Volume One是一本书,那么模型在实体分类任务上将难以推理出Bob Dylan是一名歌手和作家。在关系分类任务上也无法推断出Bob Dylan和Blowin’ in the Wind是创作者的关系。
此外,由于预训练模型使用经过分词的子词(token)作为最小的语义单元,针对句子中的歌曲和书名短语,由于出现频率过低,模型可能无法将其识别为一个完整的语义单元,从而只能模糊的学习到UNK wrote UNK in UNK。
为预训练模型注入知识图谱中的实体信息和三元组知识,能够让预训练模型识别出实体,并习得实体间的关联。
然而知识的注入面临着两个问题,一个是给定文本,如何提取出其中的相关实体并对其编码。二是知识表示学习使用和文本编码不同的编码方式,这会生成语义向量空间异构的表示向量,如何融合异构向量成为了关键的问题。

解决方案
为了解决上述的两个问题,作者提出了下面的解决方案。针对第一个问题,作者首先抽取出文本中的实体。
这一步骤在工程上是通过获取维基百科的页面,并将其中带有超链接的名词或者短语作为实体。在此基础上,通过字符串比对的方式对齐抽取出的实体和知识图谱中的实体。
而为了编码实体信息,作者使用了TransE对知识图谱中的三元组建模,从而生成表示向量。为了更好的区分文本中的实体和知识图谱中的实体,笔者使用指称项表示文本中出现的实体,而用实体表示知识图谱中的实体。
对于第二个问题,作者在BERT原有的预训练任务基础上引入实体预测任务,也即作者所指的去噪实体自编码(dEA)。具体而言,模型在数据准备阶段会构建文本序列和对应的实体序列,文本指称项向量会和实体向量融合,该融合向量将用于判断它在图谱中所代表的实体。
已有的预训练模型仅仅利用文本预测掩码子词,而这一任务则需要预训练模型同时利用实体信息和文本信息预测,促使了预训练模型融合实体知识。
2.1 模型结构
模型的结构由文本编码器(T-encoder)和知识编码器(K-encoder)所组成。文本编码器部分采用BERT模型所使用的Transformer编码层,在具体实现上作者使用了5层编码层来构成文本编码器。
知识编码器则由7层作者自定义的聚合层所构成,主要负责实体信息和文本信息的融合以及编码。模型结构如下图所示:
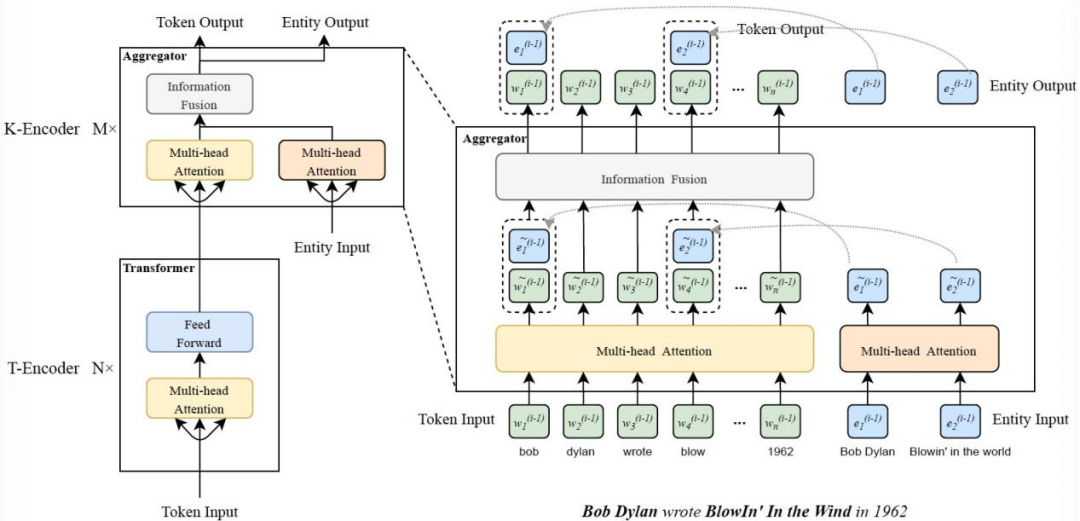
给定文本输入序列,模型首先使用文本编码器编码文本,生成表示向量:
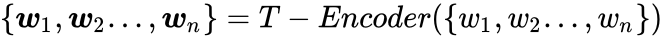
该文本向量w将和经过TransE编码的实体向量e共同传入聚合层,聚合层使用两个多头自注意力层MH-ATT分别对文本和知识向量编码:
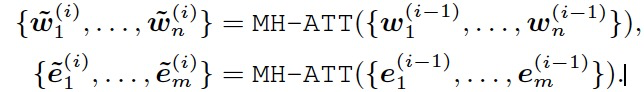
针对编码后的第i层第j个文本向量和第k个实体向量分别进行矩阵相乘,将其对应向量相加并经过非线性变化,生成融合向量h :
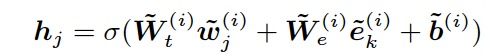
该融合向量h将分别经过两个转换矩阵,重新生成携带文本信息和图谱信息的实体向量和文本向量ek:

这两个向量将在输出层经过归一化和残差连接。事实上,知识编码器中包含了两种不同类型的编码器,一种仅仅对文本向量进行自注意力操作,主要负责的是文本向量和实体向量的求和。另一种才如上文所述,对两类向量都进行自注意力操作。具体的过程详见代码解读。
2.2 模型的预训练
除了BERT的两个预训练任务,作者还引入了针对掩码实体的预测任务。考虑到文本指称项和图谱中的实体在对齐过程中可能会存在错误,作者针对5%的指称项随机挑选一个实体与其融合,让模型在融合错误实体的情况下预测正确实体,以训练模型的纠错能力。
针对15%的文本指称项,作者对融合实体信息的文本指称项进行掩码,并让模型对其预测,以训练模型在没有获得所有对齐实体信息的情况下,也能正确预测实体。
针对剩余85%的文本指称项,作者不做任何改变,让模型从实体序列和文本序列中学习语义,根据融合后的向量预测正确实体。
笔者发现,作者在工程实现上并没有做这部分的实现,而是沿用BERT模型训练数据构建部分的代码。
这也让笔者猜测,实体序列的掩码以及随机选择可能没有必要,只不过为了工程实现的便捷,赋予这部分操作一个合理的理论依据。
考虑到知识图谱中的实体数量巨大,如果针对所有的实体进行预测将会大大降低模型的效率。因此,作者仅使用实体序列中的实体,利用如下概率分布公式,计算正确的实体。
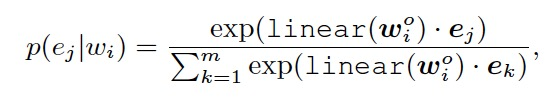
这样的做法由于缩小了模型的选择空间,在一定程度上降低了预测的难度,但提高了预训练的效率。是一种模型能力与训练时长的折中。
2.3模型的微调
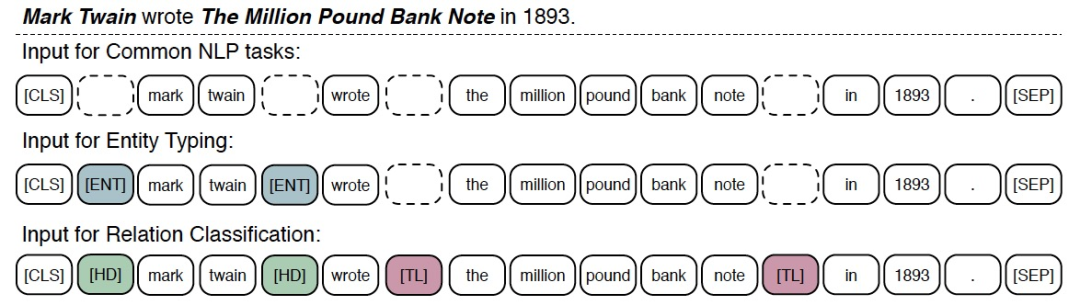
作者选择了实体分类和关系分类这两类知识密集型任务用于模型的微调。关系分类(relation classification)任务是指给定文本序列和其中的两个实体,模型需要判断出两个实体间的关系。
实体分类(entity typing)是指给定实体,模型需要预测出正确的实体类型。对于关系分类任务,作者为了能够标识出实体的位置,引入了特殊标识符[HD]和[LD],置于实体的前后。
同理,为了标识出实体的位置,引入[ENT]这一符号,置于实体的前后。最后,使用[CLS]这一分类符号用于分类。

实验
在实验部分,作者使用实体分类、关系分类任务,以及语言理解任务GLUE数据集测试模型的性能。在实体分类任务上的结果表明,ERNIE远超其他基线模型,并且比BERT在召回率和准确率上都提高了2%。
在关系分类任务上的结果表明,BERT比传统的基于RNN和CNN的模型在F1值上高出15%以上,而ERNIE比BERT在1值上提高了3.4%,这说明了预训练模型能够比传统基于RNN和CNN的模型学习到更多的语义信息,以及知识注入的有效性。
值得一提的是,作者使用TACRED和FewRel数据集进行测试,后者的数据量比前者小的多,而ERNIE却在FewRel数据集上获得了更大幅度的性能提升,这也说明了知识的注入能够帮助预训练模型更好的利用小规模训练数据,这对于缺乏大规模标注数据的NLP应用场景而言意义重大。
除此以外,模型还在GLUE数据集上进行评测,结果表明模型和BERT在总体上取得了相差无几的成绩,这也说明了知识的注入并没有影响模型原有的文本编码能力。

所想所获
4.1分词方法
模型在训练之前,需要对输入文本进行切分,BERT采用的分词法是WordPiece,这种方法根据子词出现的词频高低来作为切分词语的依据。
这样会使得高频的子词作为一个基本的语义单元,其对应的词向量将习得某个语义。然而我们在现实生活中往往会使用一个完整的单词或者短语来表示某个语义,这就造成模型无法理解这些单词。
百度团队所提出的ERNIE[1]通过采用全词掩码的策略之所以能够提升预训练模型的性能,原因也在于此。
本文针对文本指称项经过分词后的第一个子词注入实体信息,虽然能够通过自注意力层实现信息的传递,但分词的结果和实体的边界仍然存在鸿沟,笔者认为更好的对齐方式也许能进一步提高知识注入的效果。
4.2知识注入
本文通过对知识图谱中的三元组表示学习,搭建了融合符号知识和文本向量的桥梁。然而TransE仅针对三元组建模,虽然能够学习到两个实体间的关联,但是无法同时建模多个实体的关联。
此外,实体所在的上下文能为实体提供更多的语义信息,而TransE无法利用实体文本信息。与之对比,预训练模型则能够捕捉到丰富的文本信息。
那么是否可能将二者的结合起来呢,论文[2]就结合了两者的优点,具体的结合思路笔者将在后续文章中进行解读。
另一方面,图神经网络擅长捕获拓扑结构的实体关联信息,而知识图谱正是一种不规则的异构图,使用图神经网络对知识图谱进行表示学习,能够进一步编码知识图谱的拓扑结构,从而学习多个实体的关联信息,进一步丰富实体向量的语义。
此外,知识的注入依赖于实体的对齐,尽管注入的实体知识经过表示学习后也携带实体的关联信息,但如果能使用如关系等更多的注入载体,那么就能够为预训练模型注入关系向量,增加注入知识的密度。
以上就是笔者对论文的解读,具体的代码将会在下篇文章中解读。
参考文献:
[1]ERNIE:Enhanced Representation through Knowledge Integration
https://arxiv.org/abs/1904.09223
[2]KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation
https://direct.mit.edu/tacl/article/doi/10.1162/tacl_a_00360/98089/
Original: https://blog.csdn.net/NLPlunwenjiedu/article/details/122247553
Author: NLP论文解读
Title: 知识增强的预训练语言模型系列之ERNIE:如何为预训练语言模型注入知识
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/595068/
转载文章受原作者版权保护。转载请注明原作者出处!