

今天 DBA 同事问了一个问题,MySQL在半同步复制的场景下,当关闭从节点时使得从节点的数量 < rpl_semi_sync_master_wait_for_slave_count时,show full processlist 的结果不同,具体表现如下:
AFTER_SYNC表现如下:
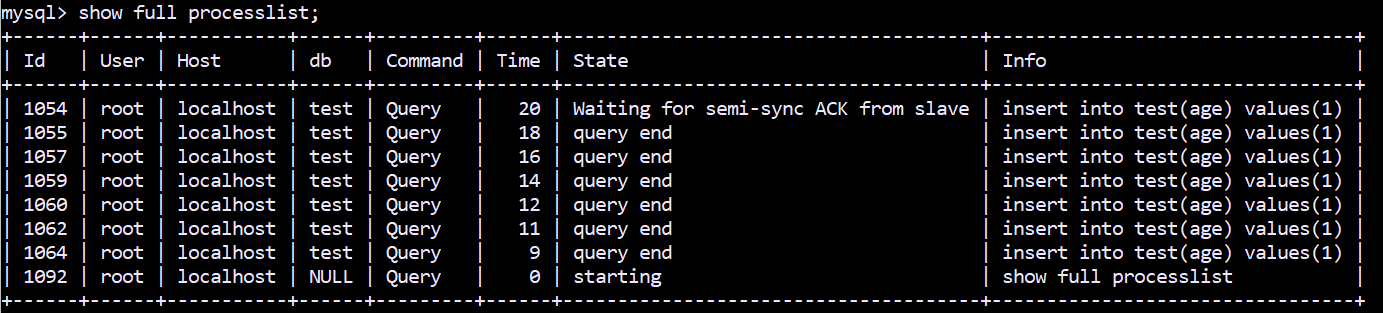

可以发现,只有一个查询线程处于 Waiting for semi-sync ACK from slave 状态,其他查询线程处于 query end 状态。
AFTER_COMMIT 表现如下:
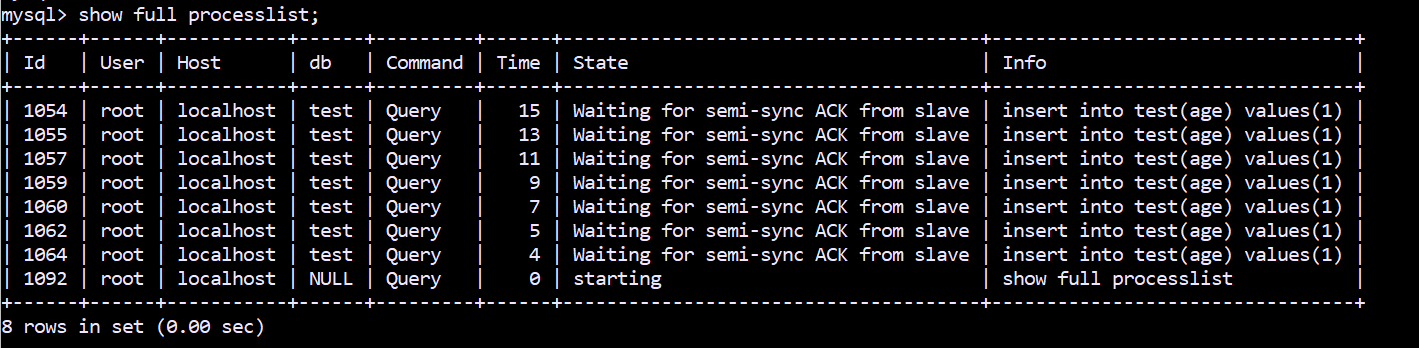
和 AFTER_SYNC 不同, 所有的查询线程处于 Waiting for semi-sync ACK from slave 状态;
之前已经了解过 MySQL半同步复制,这次从源码的角度来解析MySQL半同步复制到底是如何进行的,同时分析原因。
首先看事务的提交过程,整体的提交流程过长,切之前已经研究过源码,这里仅对关于半同步复制相关的部分做深入分析:
int MYSQL_BIN_LOG::ordered_commit(THD *thd, bool all, bool skip_commit)
{ ....
// 执行 flush 阶段操作。
/*
* 1. 对 flush 队列进行 fetch, 本次处理的flush队列就固定了
2. 在 innodb 存储引擎中 flush redo log, 做 innodb 层 redo 持久化。
3. 为 flush 队列中每个事务生成 gtid。
4. 将 flush队列中每个线程的 binlog cache flush 到 binlog 日志文件中。这里包含两步:
1. 将事务的 GTID event直接写入 binlog 磁盘文件中
2. 将事务生成的别的 event 写入 binlog file cache 中
*/
flush_error = process_flush_stage_queue(&total_bytes, &do_rotate,
&wait_queue);
// 将 binary log cache(IO cache) flush到文件中
if (flush_error == 0 && total_bytes > 0) // 这里获取到 flush 队列中最后一个事务在 binlog 中的 end_pos
flush_error = flush_cache_to_file(&flush_end_pos);
DBUG_EXECUTE_IF("crash_after_flush_binlog", DBUG_SUICIDE(););
// sync_binlog 是否等于 1
update_binlog_end_pos_after_sync = (get_sync_period() == 1);
/*
If the flush finished successfully, we can call the after_flush
hook. Being invoked here, we have the guarantee that the hook is
executed before the before/after_send_hooks on the dump thread
preventing race conditions among these plug-ins.
如果 flush 操作成功, 则调用 after_flush hook。
*/
if (flush_error == 0)
{
const char *file_name_ptr = log_file_name + dirname_length(log_file_name);
assert(flush_end_pos != 0);
// 观察者模式,调用 Binlog_storage_observer 里面的repl_semi_report_binlog_update函数,将当前的 binlog 文件和最新的 pos 点记录到 active_tranxs_ 列表中
// file_name_ptr 当前写入的binlog文件
// flush_end_pos 组提交flush链表里面所有binlog最后的pos点
if (RUN_HOOK(binlog_storage, after_flush,
(thd, file_name_ptr, flush_end_pos)))
{
sql_print_error("Failed to run 'after_flush' hooks");
flush_error = ER_ERROR_ON_WRITE;
}
// 不等于 1, 通知 dump 线程
if (!update_binlog_end_pos_after_sync) // 更新 binlog end pos, 通知 binlog sender 线程向从库发送 event
update_binlog_end_pos();
DBUG_EXECUTE_IF("crash_commit_after_log", DBUG_SUICIDE(););
}
......
DEBUG_SYNC(thd, "bgc_after_flush_stage_before_sync_stage");
/*
Stage #2: Syncing binary log file to disk
*/
/** 释放 Lock_log mutex, 获取 Lock_sync mutex
-
第一个进入的 flush 队列的 leader 为本阶段的 leader, 其他 flush 队列加入 sync 队列, 其他 flush 队列的
-
leader会被阻塞, 直到 commit 阶段被 leader 线程唤醒。
-
*/
if (change_stage(thd, Stage_manager::SYNC_STAGE, wait_queue, &LOCK_log, &LOCK_sync))
{
DBUG_RETURN(finish_commit(thd));
}
/*
根据 delay 的设置来决定是否延迟一段时间, 如果 delay 的时间越久, 那么加入 sync 队列的
事务就越多【last commit 是在 binlog prepare 时生成的, 尚未更改, 因此加入 sync 队列的
事务是同一组事务】, 提高了从库 mts 的效率。
*/
if (!flush_error && (sync_counter + 1 >= get_sync_period()))
stage_manager.wait_count_or_timeout(opt_binlog_group_commit_sync_no_delay_count,
opt_binlog_group_commit_sync_delay,
Stage_manager::SYNC_STAGE);
// fetch sync 队列, 对 sync 队列进行固化.
final_queue = stage_manager.fetch_queue_for(Stage_manager::SYNC_STAGE);
// 这里 sync_binlog file到磁盘中
if (flush_error == 0 && total_bytes > 0)
{
// 根据 sync_binlog 的设置决定是否刷盘
std::pair<bool, bool> result = sync_binlog_file(false); }
// 在这里 sync_binlog = 1, 更新 binlog end_pos, 通知 dump 线程发送 event
if (update_binlog_end_pos_after_sync)
{
THD *tmp_thd = final_queue;
const char *binlog_file = NULL;
my_off_t pos = 0;
while (tmp_thd->next_to_commit != NULL)
tmp_thd = tmp_thd->next_to_commit;
if (flush_error == 0 && sync_error == 0)
{
tmp_thd->get_trans_fixed_pos(&binlog_file, &pos);
// 更新 binlog end pos, 通知 dump 线程
update_binlog_end_pos(binlog_file, pos);
}
}
DEBUG_SYNC(thd, "bgc_after_sync_stage_before_commit_stage");
leave_mutex_before_commit_stage = &LOCK_sync;
/*
Stage #3: Commit all transactions in order.
按顺序在 Innodb 层提交所有事务。
如果我们不需要对提交顺序进行排序, 并且每个线程必须执行 handlerton 提交, 那么这个阶段可以跳过。
然而, 由于我们保留了前一阶段的锁, 如果我们跳过这个阶段, 则必须进行解锁。
*/
commit_stage:
// 如果需要顺序提交
if (opt_binlog_order_commits &&
(sync_error == 0 || binlog_error_action != ABORT_SERVER))
{
// SYNC队列加入 COMMIT 队列, 第一个进入的 SYNC 队列的 leader 为本阶段的 leader。其他 sync 队列
// 加入 commit 队列的 leade 会被阻塞, 直到 COMMIT 阶段后被 leader 线程唤醒。
// 释放 lock_sync mutex, 持有 lock_commit mutex.
if (change_stage(thd, Stage_manager::COMMIT_STAGE,
final_queue, leave_mutex_before_commit_stage,
&LOCK_commit))
{
DBUG_PRINT("return", ("Thread ID: %u, commit_error: %d",
thd->thread_id(), thd->commit_error));
DBUG_RETURN(finish_commit(thd));
}
THD *commit_queue = stage_manager.fetch_queue_for(Stage_manager::COMMIT_STAGE);
DBUG_EXECUTE_IF("semi_sync_3-way_deadlock",
DEBUG_SYNC(thd, "before_process_commit_stage_queue"););
if (flush_error == 0 && sync_error == 0)
// 调用 after_sync hook.注意:对于after_sync, 这里将等待binlog dump 线程收到slave节点关于队列中事务最新的 binlog_file和 binlog_pos的ACK。
sync_error = call_after_sync_hook(commit_queue);
/* process_commit_stage_queue 将为队列中每个 thd 持有的 GTID
调用 update_on_commit 或 update_on_rollback。
这样做的目的是确保 gtid 按照顺序添加到 GTIDs中, 避免出现不必要的间隙
如果我们只允许每个线程在完成提交时调用 update_on_commit, 则无法保证 GTID
顺序, 并且 gtid_executed 之间可能出现空隙。发生这种情况, server必须从
Gtid_set 中添加和删除间隔, 添加或删除间隔需要一个互斥锁, 这会降低性能。
*/
// 在这里, 进入存储引擎中提交
process_commit_stage_queue(thd, commit_queue);
// 退出 Lock_commit 锁
mysql_mutex_unlock(&LOCK_commit);
/* 在 LOCK_commit 释放之后处理 after_commit 来避免 user thread, rotate thread 和 dump thread的
3路死锁。
*/
// 处理 after_commit HOOK
process_after_commit_stage_queue(thd, commit_queue);
}
else
{
// 释放锁, 调用 after_sync hook.
if (leave_mutex_before_commit_stage)
mysql_mutex_unlock(leave_mutex_before_commit_stage);
if (flush_error == 0 && sync_error == 0)
sync_error = call_after_sync_hook(final_queue);
} ....../*
Finish the commit before executing a rotate, or run the risk of a
deadlock. We don't need the return value here since it is in
thd->commit_error, which is returned below.
*/
(void)finish_commit(thd);
......
}
在以上过程中,可以看到,在 flush 节点之后会执行 AFTER_FLUSH hook, 这个 hook 会将当前的 binlog 文件和最新的 pos 点位记录到 active_tranxs_ 链表中,这个链表在半同步复制等待 slave 节点 apply 中使用:
AFTER_FLUSH:
static inline int call_after_sync_hook(THD *queue_head)
{
const char *log_file = NULL;
my_off_t pos = 0;
if (NO_HOOK(binlog_storage))
return 0;
assert(queue_head != NULL);
for (THD *thd = queue_head; thd != NULL; thd = thd->next_to_commit)
if (likely(thd->commit_error == THD::CE_NONE)) // 可以看到,这里获取了固化后的 commit 队列中的最新的事务的 binlog filename & pos
thd->get_trans_fixed_pos(&log_file, &pos);
// 使用最新的 binlog filename & pos 调用 after_sync hook
if (DBUG_EVALUATE_IF("simulate_after_sync_hook_error", 1, 0) ||
RUN_HOOK(binlog_storage, after_sync, (queue_head, log_file, pos)))
{
sql_print_error("Failed to run 'after_sync' hooks");
return ER_ERROR_ON_WRITE;
}
return 0;
}
// after_sync 函数定义
int Binlog_storage_delegate::after_sync(THD *thd,
const char *log_file,
my_off_t log_pos)
{
DBUG_ENTER("Binlog_storage_delegate::after_sync");
DBUG_PRINT("enter", ("log_file: %s, log_pos: %llu",
log_file, (ulonglong) log_pos));
Binlog_storage_param param;
param.server_id= thd->server_id;
assert(log_pos != 0);
int ret= 0;
FOREACH_OBSERVER(ret, after_sync, thd, (¶m, log_file, log_pos)); // 找到观察器调用, 这是是观察者模式
DEBUG_SYNC(thd, "after_call_after_sync_observer");
DBUG_RETURN(ret);
}
AFTER_SYNC:----------------------------------------------------------------------------------------------------------
// after_sync() 接口的具体实现
int repl_semi_report_binlog_sync(Binlog_storage_param *param,
const char *log_file,
my_off_t log_pos)
{
// 是否是 after_sync 模式
if (rpl_semi_sync_master_wait_point == WAIT_AFTER_SYNC)
// 执行事务的线程等待从库的回复, 即等待 ACK 的实现函数
return repl_semisync.commitTrx(log_file, log_pos);
return 0;
}
AFTER_COMMIT:
// after_commit 实际调用函数
int repl_semi_report_commit(Trans_param *param)
{
bool is_real_trans= param->flags & TRANS_IS_REAL_TRANS;
// semi_sync 是 AFTER_COMMIT && 是真正的事务
if (rpl_semi_sync_master_wait_point == WAIT_AFTER_COMMIT &&
is_real_trans && param->log_pos)
{
const char *binlog_name= param->log_file;
// 执行事务的线程等待从库的回复, 即等待 ACK 的实现函数
return repl_semisync.commitTrx(binlog_name, param->log_pos);
}
return 0;
}
// 执行事务的线程等待从库的回复, 即等待 ACK 的实现函数 int ReplSemiSyncMaster::commitTrx(const char* trx_wait_binlog_name, my_off_t trx_wait_binlog_pos) { const char *kWho = "ReplSemiSyncMaster::commitTrx"; function_enter(kWho); PSI_stage_info old_stage; #if defined(ENABLED_DEBUG_SYNC) /* debug sync may not be initialized for a master */ if (current_thd->debug_sync_control) DEBUG_SYNC(current_thd, "rpl_semisync_master_commit_trx_before_lock"); #endif /* Acquire the mutex. 获取 LOCK_binlog_ 互斥锁 */ lock(); TranxNode* entry= NULL; mysql_cond_t* thd_cond= NULL; bool is_semi_sync_trans= true; // active_transx_ 为当前活跃的事务链表,在 after_flush HOOK 中会将 flush 队列中最新的事务的 binlog filename & pos 添加到该链表中 // trx_wait_binlog_name 为固化的 commit 队列中最新的事务的 binlog filename if (active_tranxs_ != NULL && trx_wait_binlog_name) { // 遍历 active_tranxs_ 活跃的事务链表, 找到大于等于 trx_wait_binlog_name 和 trx_wait_binlog_pos // 的第一个事务 entry= active_tranxs_->find_active_tranx_node(trx_wait_binlog_name, trx_wait_binlog_pos); // 如果找到了第一个事务 if (entry) thd_cond= &entry->cond; } /* This must be called after acquired the lock */ // 当前线程进入 thd_cond THD_ENTER_COND(NULL, thd_cond, &LOCK_binlog_, & stage_waiting_for_semi_sync_ack_from_slave, & old_stage); // 如果主库启用了半同步 if (getMasterEnabled() && trx_wait_binlog_name) { struct timespec start_ts; struct timespec abstime; int wait_result; // 设置当前时间 start_ts set_timespec(&start_ts, 0); /* This is the real check inside the mutex. */ // 主库没有启动半同步 || 没有启动半同步复制, l_end if (!getMasterEnabled() || !is_on()) goto l_end; if (trace_level_ & kTraceDetail) { sql_print_information("%s: wait pos (%s, %lu), repl(%d)\n", kWho, trx_wait_binlog_name, (unsigned long)trx_wait_binlog_pos, (int)is_on()); } /* Calcuate the waiting period. */ #ifndef HAVE_STRUCT_TIMESPEC abstime.tv.i64 = start_ts.tv.i64 + (__int64)wait_timeout_ * TIME_THOUSAND * 10; abstime.max_timeout_msec= (long)wait_timeout_; #else // wait_timeout 时间 abstime.tv_sec = start_ts.tv_sec + wait_timeout_ / TIME_THOUSAND; abstime.tv_nsec = start_ts.tv_nsec + (wait_timeout_ % TIME_THOUSAND) * TIME_MILLION; if (abstime.tv_nsec >= TIME_BILLION) { abstime.tv_sec++; abstime.tv_nsec -= TIME_BILLION; } #endif /* _WIN32 */ // 打开了半同步 while (is_on()) { // 如果有从库回复 if (reply_file_name_inited_) { // 比较从库回复的日志坐标(filename & fileops)和固化的 commit 队列中最新的事务的 binlog filename & pos int cmp = ActiveTranx::compare(reply_file_name_, reply_file_pos_, trx_wait_binlog_name, trx_wait_binlog_pos); // 如果回复的日志坐标大于当前的日志坐标 if (cmp >= 0) { /* We have already sent the relevant binlog to the slave: no need to * wait here. 我们已经确认将相应的 binlog 发送给了从库: 无需在此等待。 */ if (trace_level_ & kTraceDetail) sql_print_information("%s: Binlog reply is ahead (%s, %lu),", kWho, reply_file_name_, (unsigned long)reply_file_pos_); // 退出循环 break; } } /* When code reaches here an Entry object may not be present in the following scenario. 当代码到了这里, 在一下场景中可能不存在 entry。 Semi sync was not enabled when transaction entered into ordered_commit process. During flush stage, semi sync was not enabled and there was no 'Entry' object created for the transaction being committed and at a later stage it was enabled. In this case trx_wait_binlog_name and trx_wait_binlog_pos are set but the 'Entry' object is not present. Hence dump thread will not wait for reply from slave and it will not update reply_file_name. In such case the committing transaction should not wait for an ack from slave and it should be considered as an async transaction. 事务进入 ordered_commit 时未启用半同步。 在 flush 阶段, 没有启用半同步, 没有为提交的事务创建 entry 对象, 但是在之后的节点启用了半同步。 在这种情况下, 设置了 trx_wait_binlog_name 和 trx_wait_binlog_pos, 但是 entry 对象并不存在。 此时, dump 线程将不会等待 slave 节点的 reply, 并且不会更新 reply_file_name。 在这种情况下, 提交的事务不应等待来自 slave 节点的 ack, 而应被视为异步事务。 */ if (!entry) { is_semi_sync_trans= false; goto l_end; } /* Let us update the info about the minimum binlog position of waiting * threads. * 这里更新等待线程等待的 minimum binlog pos 。 */ if (wait_file_name_inited_) { // 对比当前 commit 队列最后的binlog点位 和 wait_file_name_ & wait_file_pos_ 大小 int cmp = ActiveTranx::compare(trx_wait_binlog_name, trx_wait_binlog_pos, wait_file_name_, wait_file_pos_); if (cmp 0) { /* This thd has a lower position, let's update the minimum info. 这里更新 wait_file_name_ & wait_file_pos_。 */ strncpy(wait_file_name_, trx_wait_binlog_name, sizeof(wait_file_name_) - 1); wait_file_name_[sizeof(wait_file_name_) - 1]= '\0'; wait_file_pos_ = trx_wait_binlog_pos; rpl_semi_sync_master_wait_pos_backtraverse++; if (trace_level_ & kTraceDetail) sql_print_information("%s: move back wait position (%s, %lu),", kWho, wait_file_name_, (unsigned long)wait_file_pos_); } } else { strncpy(wait_file_name_, trx_wait_binlog_name, sizeof(wait_file_name_) - 1); wait_file_name_[sizeof(wait_file_name_) - 1]= '\0'; wait_file_pos_ = trx_wait_binlog_pos; wait_file_name_inited_ = true; if (trace_level_ & kTraceDetail) sql_print_information("%s: init wait position (%s, %lu),", kWho, wait_file_name_, (unsigned long)wait_file_pos_); } /* In semi-synchronous replication, we wait until the binlog-dump * thread has received the reply on the relevant binlog segment from the * replication slave. * 在半同步复制中, 我们等待直到 binlog dump 线程收到相关 binlog 的 reply 信息。 * * Let us suspend this thread to wait on the condition; * when replication has progressed far enough, we will release * these waiting threads. * 让我们暂停这个线程以等待这个条件; * 当复制进展足够时, 我们将释放等待的线程。 */ // 判断 slave 个数和半同步是否正常 // 当前 slave 节点的数量 == rpl_semi_sync_master_wait_for_slave_count -1 && 半同步复制正开启 if (abort_loop && (rpl_semi_sync_master_clients == rpl_semi_sync_master_wait_for_slave_count - 1) && is_on()) { sql_print_warning("SEMISYNC: Forced shutdown. Some updates might " "not be replicated."); // 关闭半同步, 中断循环 switch_off(); break; } //正式进入等待binlog同步的步骤,将rpl_semi_sync_master_wait_sessions+1 //然后发起等待信号,进入信号等待后,只有2种情况可以退出等待。1是被其他线程唤醒(binlog dump) //2是等待超时时间。如果是被唤醒则返回值是0,否则是其他值 rpl_semi_sync_master_wait_sessions++; if (trace_level_ & kTraceDetail) sql_print_information("%s: wait %lu ms for binlog sent (%s, %lu)", kWho, wait_timeout_, wait_file_name_, (unsigned long)wait_file_pos_); /* wait for the position to be ACK'ed back 实现 ACK 等待 */ assert(entry); entry->n_waiters++; // 第一个参数为条件量,第二个为等待之后释放LOCK_binlog_互斥锁,第三个为未来的超时绝对时间 wait_result= mysql_cond_timedwait(&entry->cond, &LOCK_binlog_, &abstime); entry->n_waiters--; /* After we release LOCK_binlog_ above while waiting for the condition, it can happen that some other parallel client session executed RESET MASTER. That can set rpl_semi_sync_master_wait_sessions to zero. Hence check the value before decrementing it and decrement it only if it is non-zero value. 在等待之后释放 LOCK_binlog_互斥锁, 有可能其他客户端执行 RESET MASTER 命令, 这将把 rpl_semi_sync_master_wait_sessions 重置为 0。 因此, 在递减前需要检查该值。 */ if (rpl_semi_sync_master_wait_sessions > 0) rpl_semi_sync_master_wait_sessions--; // wait_result != 0, 这里表示等待超时 if (wait_result != 0) { /* This is a real wait timeout. */ sql_print_warning("Timeout waiting for reply of binlog (file: %s, pos: %lu), " "semi-sync up to file %s, position %lu.", trx_wait_binlog_name, (unsigned long)trx_wait_binlog_pos, reply_file_name_, (unsigned long)reply_file_pos_); rpl_semi_sync_master_wait_timeouts++; /* switch semi-sync off ; 关闭 semi sync */ switch_off(); } else // 等待 ACK 成功 { int wait_time; wait_time = getWaitTime(start_ts); // wait_time < 0, 时钟错误 if (wait_time < 0) { if (trace_level_ & kTraceGeneral) { sql_print_information("Assessment of waiting time for commitTrx " "failed at wait position (%s, %lu)", trx_wait_binlog_name, (unsigned long)trx_wait_binlog_pos); } rpl_semi_sync_master_timefunc_fails++; } else { //将等待事件与该等待计入总数 rpl_semi_sync_master_trx_wait_num++; rpl_semi_sync_master_trx_wait_time += wait_time; } } } l_end: /* Update the status counter. 更新状态计数 */ if (is_on() && is_semi_sync_trans) rpl_semi_sync_master_yes_transactions++; else rpl_semi_sync_master_no_transactions++; } /* Last waiter removes the TranxNode 移除 active_tranxs_ 链表中 trx_wait_binlog_name & trx_wait_binlog_pos 之前的所有事务。 */ if (trx_wait_binlog_name && active_tranxs_ && entry && entry->n_waiters == 0) active_tranxs_->clear_active_tranx_nodes(trx_wait_binlog_name, trx_wait_binlog_pos); unlock(); THD_EXIT_COND(NULL, & old_stage); return function_exit(kWho, 0); }
通过以上源码分析,可以看到在 after_sync hook 之后会释放 Lock_commit 锁,而后调用 after_commit hook。
因此当 AFTER_SYNC 时,会发现只有一个查询线程处于 Waiting for semi-sync ACK from slave 状态,其他查询线程处于 query end 状态。
而 AFTER_COMMIT 时,所有的查询线程都处于 Waiting for semi-sync ACK from slave 状态。
Original: https://www.cnblogs.com/juanmaofeifei/p/16650464.html
Author: 卷毛狒狒
Title: MySQL半同步复制源码解析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/590927/
转载文章受原作者版权保护。转载请注明原作者出处!