

k-近邻,通过离你最近的来判断你的类别
例子:
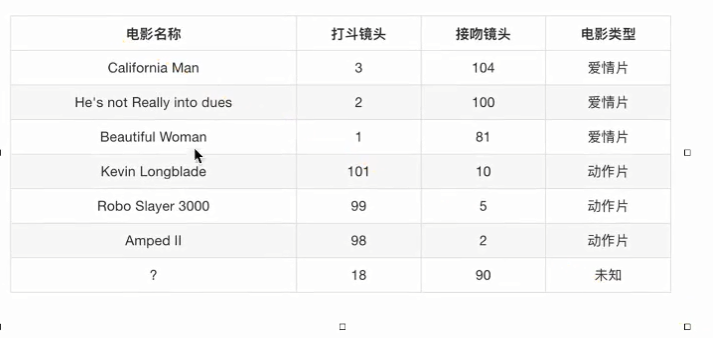

定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近的样本中大多数属于某一类别),则该样本属于这个类别

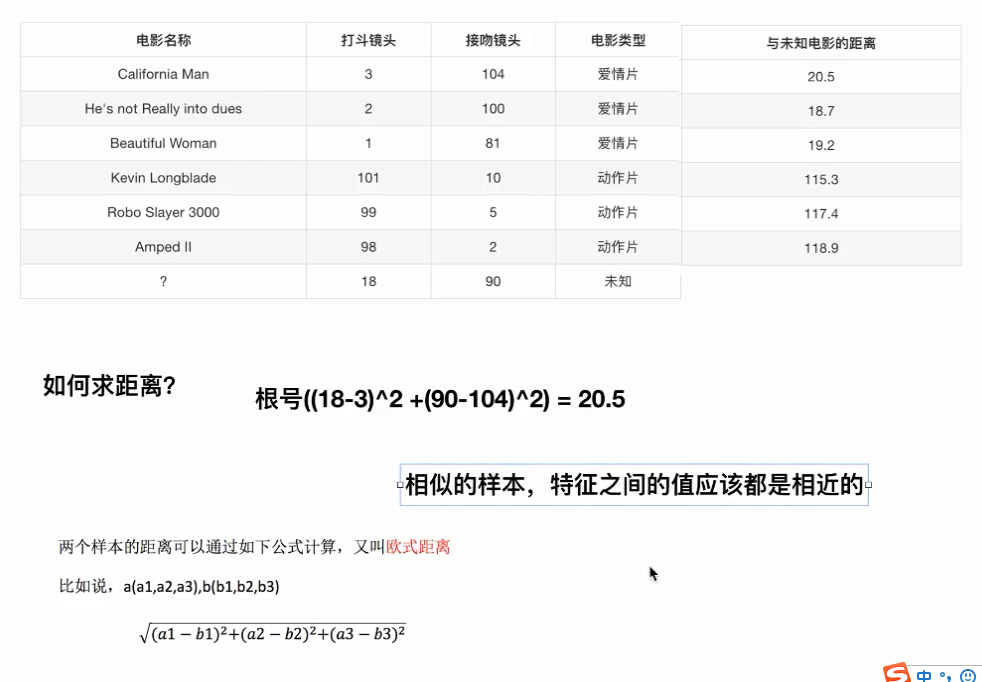
K近邻需要做标准化处理

例如:
import numpy as npimport pandas as pdfrom matplotlib import pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.neighbors import KNeighborsClassifierdef knn(): ''' k近邻预测消费花费 :return: ''' #读取数据 data=pd.read_csv('data.csv') # print(data.info()) data=data[['age','ageg','num','cost']] # print(data) #对数据的处理 y=data[['cost']] x=data.drop('cost',axis=1) #划分训练集合测试集 x_train,x_text,y_train,y_text=train_test_split(x,y,test_size=0.25) #标准化 ss=StandardScaler() x_train=ss.fit_transform(x_train) x_text=ss.transform(x_text) #训练和预测 y_train=y_train.astype(int) kn=KNeighborsClassifier(n_neighbors=5) kn.fit(x_train,y_train) y_predict=kn.predict(x_text) print('预测值',y_predict) print("++" * 100) x_text=np.array(x_text) print('原本的测试值',x_text) print('得分:',kn.score(x_text,y_text.astype(int)))#训练,预测 kn=KNeighborsClassifier() # data=data['id',''] #数据处理 #特征工程if __name__ == '__main__': knn()



undefined
Original: https://www.cnblogs.com/cgy1995/p/9996129.html
Author: spiderMan1-1
Title: 机器学习(6)K近邻算法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/589793/
转载文章受原作者版权保护。转载请注明原作者出处!