

MySQL采用B+树作为索引的原因
1、MySQL的索引结构是如何查询的
在MySQL中,存储的数据记录都是持久化到磁盘中的,数据包含索引和记录,当MySQL查询数据时,由于索引也是持久化在磁盘上面的,首先会从磁盘上读取索引到缓存中,然后再通过索引从磁盘上面检索数据读取待内存中,在这期间会进去内存与磁盘之间的IO交互,而磁盘IO次数越多的话,所消耗的时间就会从多,所以当从磁盘检索的IO次数越少时,查询速率就会越快,而MySQL是可以范围查询的,所以MySQL索引的数据结构选取就会减少IO次数,并能支持范围查找
2、二叉查找树
二叉查找树是一种经典的数据结构,在二叉查找树中,左子树的键值总是小于根的键值,右子树的键值总是大于根的键值,因此可以通过中序遍历来查询键值的顺序输出,二叉树节点中存储了键(key)和数据(data),如下图所示,


对于上图的二叉查找树,当我们需要查找键值为5的记录时,先通过根进行比较,其键值是6,6大于5,接着查询6的左子树,而找到3,5大于3,再找到其右子树,一共进行了3次查找,若如果构造的二叉查找树逐渐退化为链表结构的话, 查询的效率就趋向于链表查询了,故而引出了平衡二叉树,又称之为AVL树
3、平衡二叉树
平衡二叉树定义如下,首先符合二叉查找树的概念,其次必须满足任何节点的两个子树的高度差最大差为1
平衡二叉树保证了树的构造是平衡的,当我们插入或删除数据导致不满足平衡二叉树不平衡时,平衡二叉树会进行调整树上的节点来保持平衡
平衡二叉树相比于二叉查找树来说,查找效率更稳定,总体的查找速度也更快
4、B树
我们知道,在数据库存储时,数据和索引都会存储在磁盘这种外围设备中去,但是和内存相比,磁盘读取的效率会很低下,所以需要尽量避免磁盘IO操作
在进行磁盘读取时,读取数据都是按照磁盘块来进行读取的,并不是一条一条地从数据库进行读取的,而在磁盘中,磁盘读取数据的最小单位为扇区,一个扇区的大小为512B,而操作系统最小读取的块大小为4KB,所以一次磁盘IO会从一次性地读取8个扇区
在二叉查找树和平衡二叉树中,每个节点存储的数据都只是一个键值和对应的数据的,那么实际读取的磁盘块就只会存储一个节点信息,当我们需要读取的数据量非常大时,那么树的高度就会非常高,就会进行多次磁盘IO操作,查询效率就会非常低下
而B树(BaLance Tree),即为平衡树的意思,在B树中,每个节点被称之为页,在MySQL中数据读取的基本单位都是页,B树相对于平衡二叉树,每个节点存储了更多的键值(key)和数据(data),并且每个节点拥有更多的子节点,子节点的个数一般称为阶,高度也会很低
基于这个特性,B树查找数据读取磁盘的次数将会很少,数据的查找效率也会比平衡二叉树高很多

5、B+树
B+树和二叉树、平衡二叉树一样,都是经典的数据结构,B+树是由B树和索引顺序访问方法演化而来的,B+树是基于B树的进一步优化而来,与B树相比
- B+树的非叶子节点是不存储键值,只是存储键值(key),而B树节点不仅存储键值(key)还会存储数据(data),MySQL在使用InnoDB引擎的时候页大小默认是16KB,当页中不存储数据时,存储的键值就会更多,相应的树就会显得’更矮更胖’,这样在进行数据查询时,磁盘IO的次数就会越少
- B+树的索引数据都是存放在叶子节点的,并且叶子节点是双向链表有序排列的,那么B+树进行范围查找,顺序查找的效率就会更快,而在非叶子节点中,各个页之间都是双向链表进行连接的,
B+树是为磁盘或其他直接存取辅助设备设计的一种平衡查找树,在B+树中,所有记录节点都是按照键值的大小顺序存放在同一层的叶子节点上的,由各叶子节点指针进行连接,先来看一个B+树,其高度为2,每页可以存放4条记录,扇出(fan out)为5,如下图所示
从图中可以看出,所有记录都是存放在叶子节点上的,并且是顺序存放的,如果用户从最左边的叶子节点开始顺序遍历,可以得到所有键值的顺序排序:
5,10,15,20,25,30,50,55,60,65,75,80,85,90
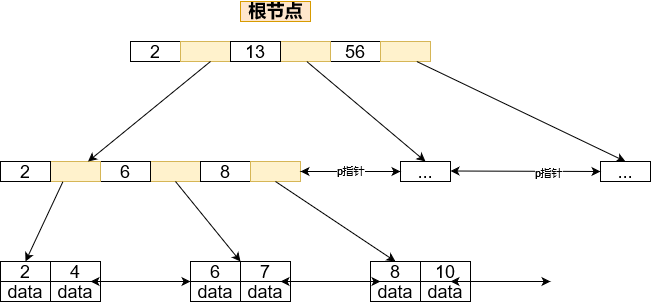
在数据库中,B+树的高度一般都是在24层,这就是说查找某一键值的行记录时最多只需要2到4次IO,因为当前一般的机器磁盘每秒可以做100次IO,24次的IO意味着查询时间只需要0.02~0.04秒
数据库中的B+树索引可以分为聚集索引(clustered index)和辅助索引(secondary index),但是不管是聚集还是辅助索引,其内部都是B+树的,即高度平衡的
6、聚集索引与辅助索引
- 聚集索引: 以InnoDB作为存储引擎的表,表中的数据都会有一个主键,InnoDB是把数据存放在B+树的,同时叶子节点存放的即为整张表的行记录数据,也将聚集索引的叶子节点称为数据页,同B+树数据结构一样,每个数据页都通过一个双向链表来进行链接,由于实际的数据页只能按照一棵B+树来进行排序,因此每张表中只能有一个聚集索引,在多数情况下,查询优化器倾向于采用聚集索引,因为聚集索引能够在B+树索引的叶子节点直接找到数据,此外,由于定义了数据的逻辑顺序,聚集索引能够特别快地访问指定范围内的查询,查询优化器能够快速发现某一段范围的数据页需要扫描
- 非聚集索引:以主键以外的列值作为键值构建的B+树索引,我们称之为非聚集索引,与聚集索引相比,非聚集索引的叶子节点不存储表中的数据,而是存储该列对应的主键,想要查找数据我们还需要根据主键再去聚集索引中进行查找,这个再根据聚集索引查找数据的过程,这种操作称为回表
聚集索引叶子节点存放在所有数据,聚集索引与辅助索引不同的是,叶子节点存放的是否是一整行的信息
在InnoDB中,聚集索引中叶子节点存放的是数据行的所有信息,而在非聚集索引中,叶子节点存放的是该列数据对应的主键,在里面存储了一个书签(bookmark),该书签用来告诉InnoDB存储引擎哪里可以找到与索引相对于的行数,InnoDB存储引擎的辅助索引的书签就是相应行数据的聚集索引键,然后在根据聚集索引去查询数据,在MyISAM存储引擎中,聚集索引和非聚集索引中叶子节点存储的是都是数据的文件地址
Original: https://www.cnblogs.com/yangblogFamily/p/16384993.html
Author: 龙空白白
Title: MySQL采用B+树作为索引的原因
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/589619/
转载文章受原作者版权保护。转载请注明原作者出处!