

redis:
数据结构
redis的五种基本数据结构:
string、hash、set、zset、list、HyperLogLog….
补充:BloomFilter等
redis的性能:
写:11万/s 、读:80万/s
string
长度不得超过512MB
底层为SDS、动态字符串
结构:len :记录数组已经使用了字节的数量、free:数组中未使用字节的数量、buf[]:字节数组,用于保存字符串
为什么不用C的字符串?
1.获取字符串长度为O(n)级别的操作,C没有存储字符串的长度
2.不能很好的杜绝缓冲区溢出、内存泄露:拼接或者缩短字符串,由于C不记录自身的长度,所以用户在执行时,已经假设分配了足够的内存,但是一旦假设不成立,就会产生缓冲区溢出。
3.C字符串只能保存文本数据:C语言的字符串必须符合某种编码(比如:ASCII),如果字符串中间出现”\0″有可能会判断为提前结束的字符而识别不了。
常用命令:set、get、exists、delete、mget、mset、set value timeout、expire、setnx = set value timeout + expire、incr、incrby(增加指定的数)、setget(返回原值)
List
底层实现类似于Java的LinkedList,是链表而不是数组
list的插入和删除都很快,但是索引的时间复杂度为O(n)
结构:ListNode pre、ListNode next、value
常用命令:lpush、lpop、rpush、rpop、lrange(范围查询)、lindex(相当于get(xx))、
Hash
底层实现为字典,redis设置一个key- value也是放在字典里的。
结构:里面有两个数组,一般情况只会用一个数组,只有当一个数组的元素的个数等于数组的长度时就会扩容,扩容大小为数组的长度的2倍。只有当扩容的时候才会用到另一个数组,另外如果长度已经满足条件但是正在进行持久化备份(bgsave),那么就会等到第一个数组的5倍才 会强制扩容。
hash与string:
hash占据更多的数据结构的存储要高于字符串
普通状态下的字典:


通过上面这张图,我们可以看到这个结构跟Java中的HashMap是非常相似的,解决键冲突的问题也是通过数组+链表的方式,那么让我们看看扩展和收缩哈希表是怎么完成的?
rehash
步骤:
1.为字典的ht[1]分配空间,这个哈希表的空间大小取决于要执行的操作是扩容还是缩容
1.1如果是扩容,ht[1] 是第一个大于等于 ht[0].used * 2 的 2 的 n次方 即:ht[1].size = Math.max(ht[0].used * 2,2的n次方)
1.2如果是索引 ht[1]是第一个大于等于ht[0].used 的2的n次方
2.将保存到ht[0]的所有的键值对rehash到ht[1]上面:rehash指的是重新计算键的哈希值和索引值,然后将键值对防止在ht[1]的指定位置上;
3.将ht[0]的所有键值对都迁移到ht[1]之后,ht[0]变成空表,释放ht[0],将ht[1]设置为ht[0],并为ht[1]创建一个新的空哈希表。
hash表的负载因子 = ht[0].used / ht[0].size
当负载因子大于等于1时,且没有执行sgsave命令/bgrewriteAof命令;当负载因子大于等于5,正在执行 sgsave命令/bgrewriteAof命令 ;这两种情况执行扩容
当负载因子小于0.1,执行缩容。
当然,执行扩容和缩容也不是一下子就完成的;而是分批次、渐进式的完成的。-为了避免停止服务
渐进式rehash的步骤:
1.为ht[1]分配空间,让字典同时拥有ht[0] 和ht[1]两个哈希表
2.在字典中维护变量rehashidx,并将它的值设置为0,表示rehash正式开始
3.在rehash期间,字典的删除、查找、更新等操作会在两个哈希表上进行,如果ht[0]没有找到,就会继续在ht[1]里面查找。增加到字典中的键值会被保存到ht[1]里面,而ht[0]不再进行任何添加操作。同时还在进行着将ht[0]的哈希表上的键值rehash到ht[1];rehash一个索引rehashidx属性增一。
4.随着字典的不断执行,到某个时间点,ht[0]的键值对会都rehash到ht[1],这个时候将rehashidx的值设置为-1,表示rehash完成。
优点:分而治之。
常用命令:hset、hget、hgetAll、hmset
set
底层实现类似于Java的HashSet
常用命令:sadd、smembers、sismember、scard (获取长度)、spop(弹出一个)
Zset
底层实现为跳表
一方面存储了value,通过set保证value的唯一,其次为每个value赋值了score,用来代表排序的权重。
内部实现为跳表。
常用命令:zadd、zrange、zrevrange(按照score逆序)、zcard、zscore、zrangebyscore、zrem
跳表的实现
为什么zset使用跳表?
1.zset支持随机插入和删除,数组不适合
2.性能考虑,不使用树形结构不需要rebalance,且更直观. 性能上接近于2分查找的时间复杂度log(n)
3.不要求相邻两层链表之间有严格的对应关系,而是为每次插入的节点随机生出一个层数。

事务
命令:
1.开启事务:multi
2.命令入队:除了exec、discard、watch、multi这四个命令,其余命令都会进入事务队列中,按照入队顺序依次执行(FIFO)
3.事务执行 :exec
特点:
redis支持事务,但是事务无法支持回滚。redis只保证串行执行任务,执行失败事务会继续执行下去。
持久化
两种方式:
RDB
解释:对redis中的数据进行周期型的持久化
优点:
1.生成多个数据文件,每个数据文件代表每个时刻的redis里面的数据
2.通过fork了子进程进行持久化,对redis性能影响较小,而且数据恢复时比AOF要快
缺点:
1.RDB是快照文件,默认是5分钟才会生成一次,这意味着可能丢失5分钟的数据,而AOF最多丢失1s
2.RDB在生成数据快照的时候,如果文件很大,客户端可能会暂停一段时间。
AOF(append-only-file)
解释:对每条写入命令写入日志文件中,命令只是追加,没有任何磁盘寻址的开销,所以比较快。AOF压缩采用的是减少命令的方式。
刷盘策略(fsync):
1.everysec(默认):每秒刷一次盘
2.always:每次都刷盘(性能最差,但是最安全)
3.no:让操作系统决定什么时候刷盘(性能最好,但是安全性最差)
优点:
1.最多丢失1s数据
2.日志文件写入为追加的方式,没有磁盘寻址
3.”非常可读”(写入命令能够直接可读)的方式记录,非常适合做灾难性的误删除紧急恢复 –???不太理解
缺点:
1.一样的数据,AOF要比RDB要大
推荐两种机制全都开启,Redis在重启的时候默认会使用AOF去重新构建数据,因为AOF中的数据比RDB更完整。
主从同步
当启动一个slave时,slave会发送 psync的命令给master,如果是这个slave第一次连接master,会触发一次全量复制,master启动线程生成一份RDB快照,RDB发给slave之后,就会开始数据复制,复制完成后,master会将内存中缓存的新命令发给slave。
过期键删除策略
可能有三种不同的删除策略:
1.定时删除:在设置键的过期时间的同时,创建一个定时器(timer),让定时器在键的过期时间 来临 时,立即执行对键的删除操作;
优点:对内存友好,能够通过定时器及时的释放所占有的内存。
缺点:对CPU时间不友好,在过期键较多的时候,会占据一部分CPU时间,会对服务器的响应时间和吞吐量造成影响。
2.惰性删除:放任键过期不管,但是每次从键空间中获取键时,都检查取得的键是否已经过来了,如果过期的话,就删除该键;如果没有过期,就返回该键;
优点:对CPU时间友好
缺点:对内存不友好
3.定期删除:每隔一段时间,程序就对数据库进行一次检查,删除里面的过期键。删除过期键的数量和检查多少个数据库由算法决定。
定期删除策略是定时删除和惰性删除的折中。
Redis使用的删除策略
Redis实际使用的是惰性删除和定期删除的策略
惰性删除的实现
所有读写数据库的命令(Set、LRange、Sadd、Hget、Keys)在执行前都会先调用expireIfNeed函数,如果发现过期了,就会删除key,都会执行实际的命令流程。
定期删除的实现
默认每次检查的数据库数量 = 16 、默认每个数据库检查的键数量 = 20 默认100ms
分布式锁
setnx
setex //同时设置值和时间
高可用
哨兵集群( sentinel)
哨兵+主从并不能保证数据不丢失,但是可以保证高可用。 哨兵必须要用3个实例。
假设只有两个哨兵,majority:授权进行主从切换的最少的哨兵数量
redis包含三种集群策略
- 主从复制
- 哨兵
- 集群
Mysql

并发控制(mysql有什么锁)
按照加锁的范围
1.全局锁
解释:对整个数据库实例加锁(通过Flush tables with read lock (FTWRL)命令)
典型场景:对全库数据备份。 – 比如对于myisam这种不支持事务的存储引擎,在做备份的时候,就需要这种锁,来保证备份的一致性
备份工具:mysqldump 增加参数:–single-transaction 会拿到一个一致性视图。
2.表级锁
2.1表锁
解释:对表加锁
典型场景:还不支持行级锁的存储引擎,比如MyISAM
2.2元数据锁(MDL)
解释:不需要显示的使用,在增删改查的时候会自动加上MDL读锁,在做DDL的时候,会加上MDL写锁,读读不互斥,读写、写写互斥,这个时候就要求把一些DML的长事务连接断开。支持给DDL设置超时时间。
2.3InnoDB上的表级锁:意向锁
解释:为了让InnoDB多粒度的锁能共存而设计的;代表着下一层级加什么类型的锁。
场景:取得行的共享锁和排他锁之前需要先获取表的意向共享锁(IS)和意向排他锁(IX),意向共享锁和意向排他锁是系统自动添加的
兼容:意向锁之间兼容,IX和表级X、表级S互斥,IS和表级X互斥。
意向锁之间相互兼容,意向锁跟表级锁(表的独占锁和表的共享锁)之前存在关系,具体关系如下:
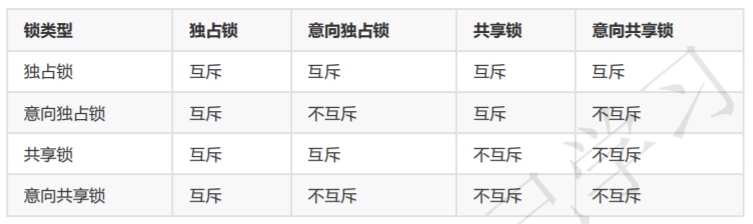
2.4自增锁
解释:自增主键,保证自增连续。
3.行锁
行级锁是在存储引擎层实现的,在mysql服务器,没有实现。
3.1InnoDB
3.1.1记录锁(record Locks)
解释:锁定的是某个具体的索引,当用主键id或者唯一键查询时,查询条件等值匹配且查询的数据是存在,这是的锁就是记录锁。 — 感觉么啥用????
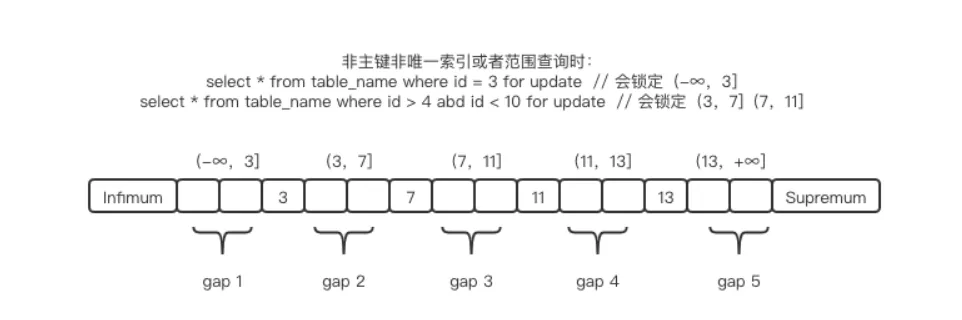
3.1.2间隙锁(gap Locks)
解释:锁住的是索引之间的间隙,是一个左开右开的区间。防止其他事务在间隔中插入数据。间隙锁之间可以共存,间隙锁的目的是为了防止幻读(幻行)

3.1.3临键锁(next-key Locks)
解释:锁住的是索引本身及索引之前的之前的间隙;是一个左开右闭的区间,当查询非唯一索引时,会给匹配的行加上临键锁。
3.1.4插入意向锁(insert intention locks)
解释:插入意向锁是一张特殊的间隙锁,在真正执行insert操作之前设置;配合间隙锁和临键锁一起防止幻读操作。在插入前判断行将要插入的间隙是否会有冲突。
事务
事务的四大特性ACID
A(Atomicity):原子性:一个事务必须被视为不可分割的一个单元。
C(Consistency):一致性:数据库总是从一个一致性状态转换到另一个一致性状态。
I(Isonlation):隔离性:一个事务所做的修改在最终提交之前,对其他事务不可见。
D(Durability):持久性:一旦事务提交,其做的修改会被永久保存到数据库。
事务的隔离级别?
1.读取未提交(Read UnCommited)RU :一个事务还没有提交,他的改变就能被其他事务看到;会导致 脏读,脏读的定义就是一个事务能读取到另一个事务还未提交的内容
2.读取已提交(Read Commited)RC:一个事务提交之后,他的改变才能被其他事务看到;会导致 不可重复读,一个事务开始读取到的内容可能跟执行过程中读取到的内容不一致。
3.可重复读(REPEATABLE Read)RR:一个事务执行中看到的数据,跟事务开启时看到的数据是一致的;会导致 幻读,幻读的定义:如果事务A根据条件查询出来一些数据,同时事务B插入了满足条件的数据,那么事务A再次按照条件查询,可以查询到B新插入的数据。
4.串行化(SERIALIZABLE):读加读锁,写加写锁,读写锁冲突,必须一个执行完之后才能执行另外一个。
mysql的默认事务隔离级别是可重复读

InnoDB是怎么支持RC(读取已提交)和RR(可重复读)的呢?– MVCC
MVCC使用的是 一致性读视图(Consistent Read View)用于支持RR和RC
InnoDB每个事务都有一个唯一的事务ID,transaction id,它是在事务开始的时候向InnoDB的事务系统申请的,按照顺序严格递增。每次事务更新数据的数据的时候,都会生成一个新的事务版本,都会生成一个新的数据版本,并且把这个transaction id复制给这个数据版本的事务id,称为row trx_id。同时旧的数据版本要保留,并且在新的数据版本中,能有信息直接拿到它。
数据表的一行记录可能有多个版本,每个版本都有自己的row trx_id.
InnoDB为每个事务构造了一个数组,用来保存这个事务启动瞬间,当前正在”活跃”(启动了,但是还没有提交)的事务id
低水位:活跃事务id的最小值
高水位:当前系统已经创建过的事务id的最大值
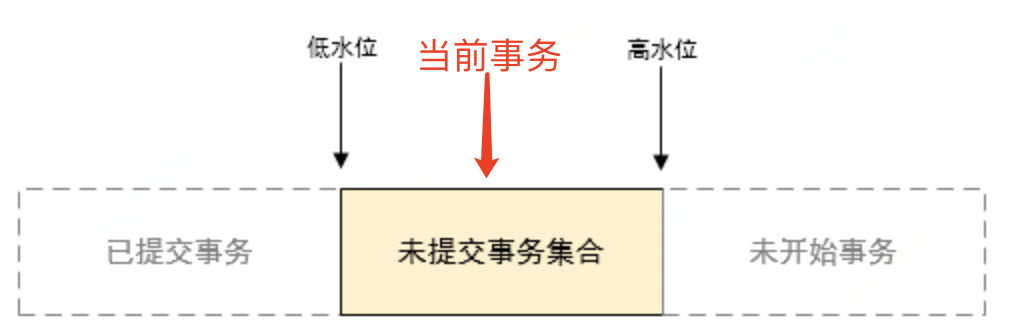
- 如果row trx_id小于低水位,那说明是已经提交的事务,肯定是可见的
2.如果row trx_id高于高水位,说明是还未开始的事务,肯定是不可见的
3.如果row trx_id在低水位,高水位之间:
3.1如果row trx_id不再数组中,说明这个版本是已经提交的事务产生的,肯定是可见的
3.2如果row trx_id在数组中, 说明这个版本是已经创建还没有提交的事务,肯定是不可见的
MVCC总结:
可重复读的核心就是一致性读;而事务更新数据的时候只能用当前读(更新数据都是先读后写,而这个读,只能读当前的值,所以称为”当前读”);如果当前记录的行锁被其他事务占据了,那就只能阻塞等待锁释放。
可重复读和读取已提交的区别是:
可重复读:一致性读视图是在事务创建时的,事务中的sql公用这个视图。
读取已提交:一致性视图是在每条sql执行前的创建的。
for update:为数据库的行设置一个排他锁
索引
Mysql为什么选用B+树?(索引的常见模型)
1.哈希表:以键 – 值为存储结构;适用于等值查询的场景
2.有序数组:等值查询和范围查询中性能都很优秀,但是增删数据成本太高;适用于静态存储引擎
3.搜索树:使用N叉树,相对二叉树而言,能够减少同磁盘的交互,提升读写的性能。
B树:
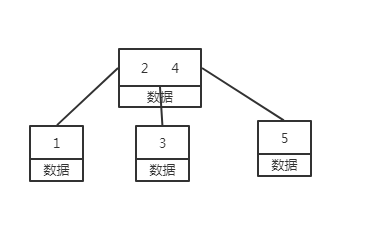
B+树:

1.B+树增加了叶子节点跟相邻叶子的指针,适用于范围查询
2.叶子节点冗余了所有非叶子节点的key
2.B+树的非叶子节点不存储数据,使得其存储的键值大大增加。
InnoDB的索引模型 – B+树
索引类型:
主键索引(聚簇索引):主键索引中的叶子节点存储的是页,页里可以包含多行数据;存储的是页,就会涉及到页分裂(申请新数据页,挪动部分数据过去),反之为页合并
非主键索引(二级索引):非主键索引的叶子节点存储的是主键id;查询非主键索引需要回表。
每一个索引都是一个B+树
覆盖索引:索引已经覆盖了查询需求,称为覆盖索引 – 避免回表
联合索引:多个字段共同建立索引 – 最左匹配原则 – 进行了索引下推优化,在回表前直接过滤掉不满足条件的记录,减少回表次数。
索引失效的场景
1.不满足最左前缀匹配原则
2.在索引列上做计算
3.使用!= 或者<>
- 使用is null 或者 not null
5.字符串不加单引号索引失效
6.使用or 查询其中一个字段不是索引
日志系统
两阶段提交
1.Server层发起事务请求到InnoDB,InnoDB写入redolog,状态为prepare;注意这也会同时写入undolog
2.Server写入binlog;binlog上会带有同redolog相关的xid
3.Server层提交事务,redolog状态变更为commit
崩溃恢复

时刻A:binlog还没有写,redolog还没有提交,事务会回滚
时刻B: binlog已经写完,redolo还没有提交,崩溃恢复时,会拿redolog中的xid查找对应的binlog,如果能够找到完整(binlog有commit标识)的binlog,那么事务恢复,反之则回滚。
binlog:server层的日志,格式:statement和row、MIX statement存储的是sql语句,row存储的是行的内容,更新前更新后都有
redolog:InnoDB的日志,记录的是物理页的修改。
undolog:记录是当前事务id,用回滚段的形式记录,用于MVCC。
explain 查询计划

id:顺序,id越大优先级越高,id相同则分组,也是id打的先执行。
select_type:查询类型,simple:普通查询;primary:包含子查询的外层;subquery:子查询;union:union连接的两个查询语句,第一个是select,第二个查询时union;dependents union 和 dependents subquery 是受外部表查询影响,derived from语句中出现的子查询,也叫派生表。
table:表名或者临时表名
partitions:查询的分区信息
type: system(不与磁盘交互) > const(唯一、主键索引或常量) > eq_ref (联表查询使用唯一或者主键索引)> ref (使用非唯一性索引) > ref_or_null(包含null值) > index_merge(使用两个以上的索引) > unique_subquery (子查询里使用唯一索引)> index_subquery (子查询里使用非唯一索引)> range(条件查询) > index(遍历索引树读全表) > ALL(读取磁盘全表)
possible_keys:查询语句哪些字段有索引
key:实际使用的索引
key_len:索引长度,越短越好
ref:使用常量等值查询 显示 const;使用表达式显示func;存在联表字段:字段名;null
rows:影响行数,越小越好
filtered:存储引擎返回的数据再经过过滤之后所占据的百分比
extra:额外信息,using index、using where …等等
并发和多线程
AQS(AbstractQueuedSynchronizer)

概念:
排他锁:只有一个线程可以访问共享变量
共享锁 :允许多个线程同时访问
AbstractQueuedSynchronizer的内部数据结构:
state:代表共享的资源;使用volidate能够让其他工作内存及时可见。
FIFO的同步等待队列

等待队列中的Node节点中存在waitstatus属性,标识当前节点处于什么等待是状态
Canceled(1):取消了等待,有可能是获取锁的时候发生了异常,超时等等.
Singal(-1):标识后续节点需要被唤醒
Condition(-2):当前节点在条件等待队列中
Propagate(-3):共享模式下,无条件传播无条件传播releaseShared状态。
0:初始状态
synchronized
锁升级过程
https://www.cnblogs.com/fengtingxin/p/12019544.html
https://www.cnblogs.com/fengtingxin/p/12164762.html
谈谈 synchronized和ReentrantLock 的区别

https://mp.weixin.qq.com/s?__biz=MzAwNDA2OTM1Ng==&mid=2453141018&idx=1&sn=d9241ddc0a9d253c0a061da3aadc2abf&scene=21#wechat_redirect
相同点:
1.都是可重复锁
差异点:
1.lock支持等待机制和中断机制
2.lock支持公平和非公平,synchronized只支持非公平
3.1.6之前syn只有重量级锁,现在性能上差不多了
为什么ConcurrentHashMap用的synchronized而不是用ReentrantLock?
解释:
1.synchronized和ReentrantLock在1.6优化之后性能上差不多,其次,ReentrantLock的诸多特性,ConcurrentHashMap没有应用上。
2.1.7及之前加锁是在segment上,比如说数组的长度为16,那么就有16个segment,锁的维度也是在每个segment上的,相当于把并发/16了
1.8时,把锁放在每个node节点上,如果两个线程同时操作一个node节点,才会存在锁竞争的关系,这样就把锁的粒度细化了,同时出现锁竞争的几率就低了。
那么synchronized自旋多次就可以拿到锁,不需要像ReentranLock那样自旋一次,然后放入队列,相比较而言,使用synchronized能够线程上下文切换。
https://www.cnblogs.com/shihaiming/p/11399472.html
JVM
为什么使用G1,G1有什么新的特性
1.Region
2.记忆集(实现方式为卡表)
3.三色标记法(增量更新还是原始快照)?
4.可预测模型
5.G1的执行过程。
https://www.cnblogs.com/fengtingxin/p/14058734.html
之前的CMS,现在为什么使用G1
1.CMS采用的回收算法是标记-清除算法,G1宏观上采用的是标记-整理算法,从每个Region上看又是标记-复制算法,G1在运作期间不会产生内存碎片,垃圾收集之后能提供规整的可用内存。
2.CMS增量更新、G1是原始快照(STAB)
3.实践经验中:小内存CMS要优于G1,中间范围6-8G,大内存G1优于CMS
线上的GC日志?G1进行Full GC有什么特点
https://www.cnblogs.com/fengtingxin/p/13966982.html
还是要看一下真实的日志 https://blog.csdn.net/zyzzxycj/article/details/101380660
线程池
使用过哪些线程池?
举个线程池设置这些参数的场景,各个参数设置的原因。
线程池的执行策略
线程池的线程回收策略
https://blog.csdn.net/l_dongyang/article/details/102689295?spm=1001.2014.3001.5501
Mysql
mysql的底层的数据结构,为什么不使用B树或者红黑树
https://blog.csdn.net/weixin_31304817/article/details/113233840
mysql的索引不生效的场景
事务隔离级别含义 – 安全性从低到高,各自会存在什么问题
间隙锁是什么,间隙锁解决了什么问题?
间隙锁和mvcc什么关系
mvcc解决了什么问题?是怎么解决可重复读的问题的?
项目:
微服务解决了什么问题?为什么要做微服务?
两套系统是如何整合的?订单数据量是多少?
配置优化是怎么做的?配置化中主要的难点是什么?配置化的难点?
配置化是如何保证数据一致性的?
简单的配置放在zk,复杂的配置放在配置表
自己完成了什么功能?为什么要完成这个功能?在做功能的时候遇到了什么问题?
平时是怎么学习的?
学习了什么新技术?讲一下ZGC?
架构升级是怎么做的?
什么是可见性?
volidat
单线程情况下:通过指令重排序,优化了运行速度,不会影响最终结果 ,多线程可能无法保证最终结果
JMM规范了一些按需禁止指令重排序来达到的命令,比如说syn\volidate
增加了内存屏障,保证执行顺序
什么是原子性?
原子性: java中执行的一个指令是原子性的
如果是共享锁?
阻塞队列 中的阻塞是什么问题?如果队列满了,再向队列中增加会有什么情况?
mysql中的索引
什么是主键索引,-回表
什么是聚簇索引,
覆盖索引 – 查询条件跟索引字段一致
联合索引 – 联合索引中的数据结构是什么样的?
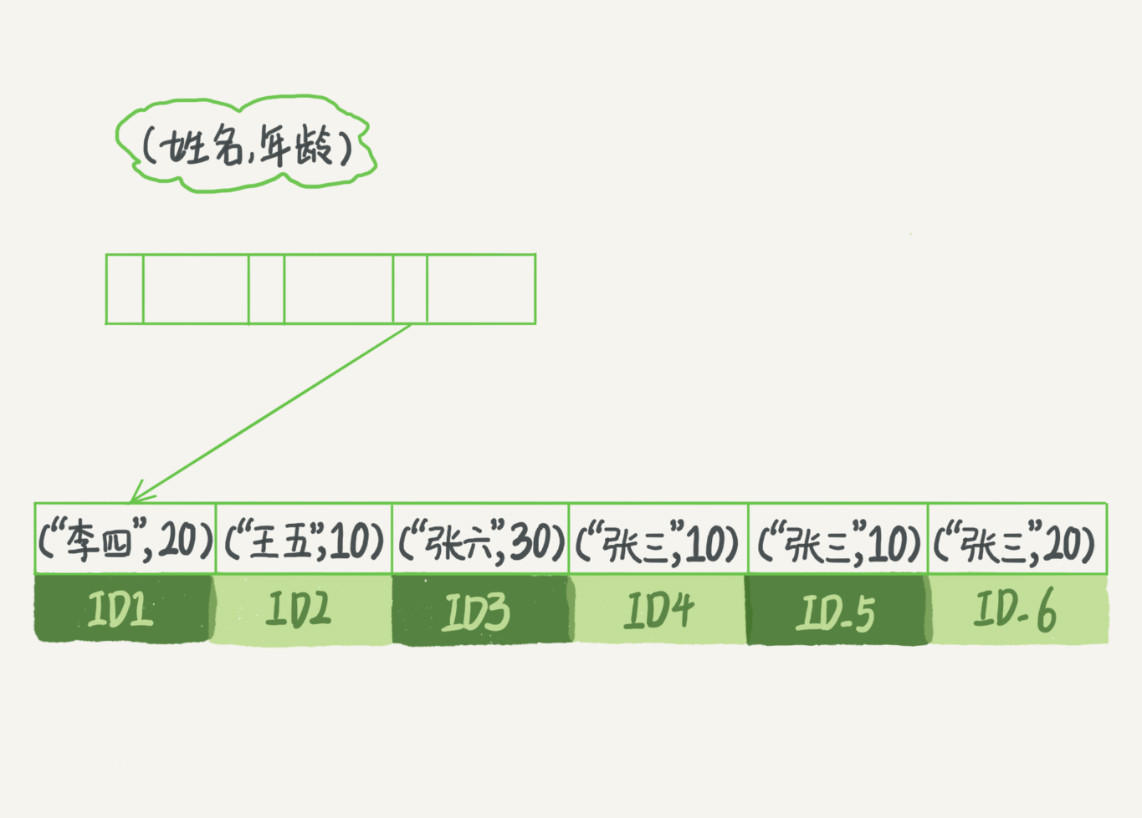
mysql的mvcc
mysql的锁
共享锁 – 怎么声明
share mode
排他锁 – 怎么声明 、 共享锁与排他锁的关系,
意向共享锁
意向排他锁
redis
缓存雪崩 – 问题是什么,
缓存击穿 – 怎么处理热key? 缓存击穿的话,设置热点数据永远不过期。或者加上互斥锁(加缓存设置被动缓存同步缓存中的数据的时候,只能有一个线程在访问)就能搞定了
缓存穿透 –
库存扣减是如何处理的?
怎么扣减库存 –待讨论
跳表:
什么情况下增加level?增加层级的算法 — 幂次定律(power law,越大的层级出现的概率越小)
分布式:
什么是脑裂?- 为什么会出现有一半
什么是cap:
C:一致性
A:可用性
P:脑裂就是分区容错性导致的 – 系统能够容忍节点之间的网络通信的故障。系统中任意信息的丢失或失败不会影响系统的继续运作.
线上系统应该保证哪个呢?由于分区容错性P在分布式系统中必须要保证的(因为正常的网络硬件在网络传输的过程中,肯定会存在丢包或者网络传输的问题),因此我们只能在A和C之间进行权衡。
ZK是怎么解决脑裂:
Quorums(ˈkwôrəm 法定人数) :比如3个节点的集群,Quorums = 2, 也就是说集群可以容忍1个节点失效,这时候还能选举出1个lead,集群还可用。
比如4个节点的集群,它的Quorums = 3,Quorums要超过3,相当于集群的容忍度还是1,如果2个节点失效,那么整个集群还是无效的
ZooKeeper默认采用了Quorums这种方式,即只有集群中超过半数节点投票才能选举出Leader。这样的方式可以确保leader的唯一性,要么选出唯一的一个leader,要么选举失败。在ZooKeeper中Quorums有2个作用:
集群中最少的节点数用来选举Leader保证集群可用:通知客户端数据已经安全保存前集群中最少数量的节点数已经保存了该数据。一旦这些节点保存了该数据,客户端将被通知已经安全保存了,可以继续其他任务。而集群中剩余的节点将会最终也保存了该数据。
假设某个leader假死,其余的followers选举出了一个新的leader。这时,旧的leader复活并且仍然认为自己是leader,这个时候它向其他followers发出写请求也是会被拒绝的。因为每当新leader产生时,会生成一个epoch,这个epoch是递增的,followers如果确认了新的leader存在,知道其epoch,就会拒绝epoch小于现任leader epoch的所有请求。那有没有follower不知道新的leader存在呢,有可能,但肯定不是大多数,否则新leader无法产生。Zookeeper的写也遵循quorum机制,因此,得不到大多数支持的写是无效的,旧leader即使各种认为自己是leader,依然没有什么作用。
什么是2pc;如何提交失败应该怎么处理?
什么是柔性事务?
遵循base理论(基本可用、柔性状态(允许系统中数据存在中间状态)、最终一致性)
柔性事务的例子
什么是刚性事务:基于ACID特性,例如:mysql的事务
什么是TCC:是2pc还是3pc
https://blog.csdn.net/bjweimengshu/article/details/86698036
Java创建对象过程:
1.若是类没有加载,需要先执行类加载的过程 这里要先基于双亲委派模型原则类加载器,选择之后在执行如下过程
1.加载 将字节码文件加载为class对象,加载到内存
2.验证 -验证字节码文件的格式上的正确性
3.准备-给静态变量赋值初始值,比如static int a; final修饰的变量在编译期已经赋值了
4.解析-将符号引用(符号引用是个字符串,标示被引用的信息)变更为直接引用
5.初始化 – 执行static方法 、类的代码块,再执行构造函数
2.类已经加载,则直接:
1.申请堆内存空间
2.给成员变量赋初始值,比如0值,false等等
3.填充对象头等信息
4.给成员变量赋值,执行代码块、最后执行构造方法
ConcurrentModificationException的原理 –
比如说使用ArrayList , 使用迭代器遍历list,调用迭代器中的next或者remove的时候,同时操作原有list的remove/add等修改方法,就会导致这个报错。建议使用迭代器的remove,若是多线程情况,使用线程安全的list,比如:CopyOnWriteArrayList

List testList = new ArrayList<>();
testList.add(1);
testList.add(2);
testList.add(3);
Iterator it = testList.iterator();
while(it.hasNext()){
System.out.println(it.next());
testList.remove(0);
// it.remove();
}
View Code
InterruptedException的产生原理和解决方法
当线程sleep的时候,被调用了interrupedException方法,就会抛出这个异常。
public class TestThread extends Thread {
@Override
public void run() {
try{
Thread.sleep(3000);
}catch (Exception e){
//线程会在sleep的时候被直接打断
System.out.println(e);
}
System.out.println(getClass().getSimpleName() + " test " + Thread.currentThread().getName());
}
public static void main(String[] args) {
TestThread testThread = new TestThread();
try{
testThread.start();
Thread.sleep(1000);
}catch (Exception e){
}
testThread.interrupt();
}
}
View Code
如何实现序列化,它的作用是什么,有哪些好用的序列化工具
json
hession
msgpack
protocolbuf
xml
线程的状态有哪些,扭转过程是怎样的
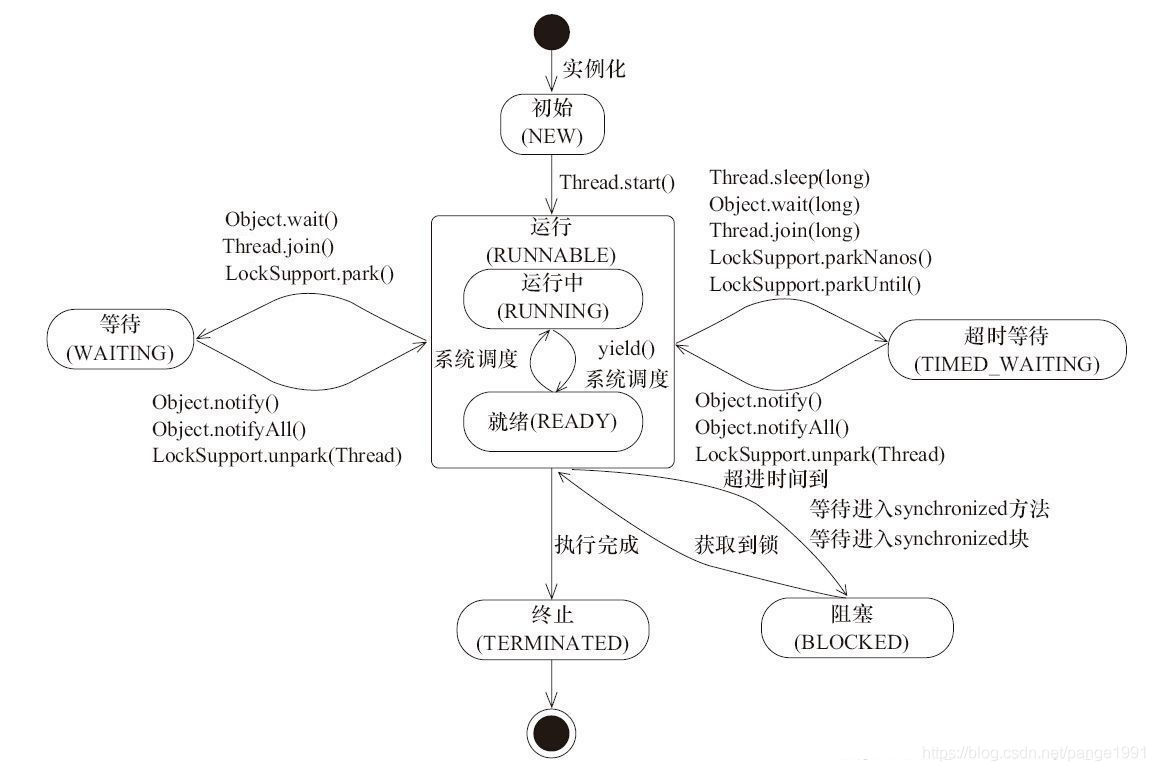
wait()和Sleep()的区别,各自的实现原理
wait:
来自与Object
syncronized代码块中使用
会释放已占有的锁资源
sleep:
来自于Thread
任意地方都可以使用
只是线程阻塞,并不会释放持有资源
ThreadPool参数设置:
1.核心线程数:
cpu密集型:理论为cpu核数+1
io密集型:理论为cpu核数*2 但是实际工作中需要按照调用量,以及每个任务所需要的时间,1秒钟可以执行多少个任务,来计算核心线程数
混合型:计算的时候需要结合cpu时间和io时间来计算。
2.阻塞队列
需要看每个任务可允许的最大等待时间,在根据每个任务所需时间来计算最大等待的队列个数
ThreadPoolExecutor提供四种基础阻塞队列:顶层是BlockingQueue接口
1.ArrayBlockingQueue:有界阻塞队列,底层为数组;
2.LinkedBlockingQueue:无界或有界阻塞队列,底层为链表;
3.SynchronousQueue:不存储元素,一个线程执行元素插入,需等待另一个线程执行移除元素,否则阻塞插入操作;
4.PriorityBlockingQueue:无界的,带有优先级的阻塞队列;
3.最大线程数
按照压测或者调用量预估峰值来计算。
4.拒绝策略
直接拒绝
直接拒绝抛出异常 – 默认
使用主线程执行
丢弃老任务,执行该新任务
自定义拒绝策略等等
有哪些常用的中间件使用了线程池的设计思想
mysql连接池
redis连接池
rpc中间件
es
NIO/AIO/BIO的区别
Cglib比JDK
cjlb:MethodInterceptor
jdk:InvocationHandler ,必须要是一个接口
Spring AOP的切点经常使用的是execution,指定报名
spring的事务的传播属性
事务的第一个方面是传播行为。传播行为定义关于客户端和被调用方法的事务边界。Spring定义了7中传播行为。
传播行为意义 PROPAGATION_MANDATORY 表示该方法必须运行在一个事务中。如果当前没有事务正在发生,将抛出一个异常 PROPAGATION_NESTED 表示如果当前正有一个事务在进行中,则该方法应当运行在一个嵌套式事务中。被嵌套的事务可以独立于封装事务进行提交或回滚。如果封装事务不存在,行为就像PROPAGATION_REQUIRES一样。 PROPAGATION_NEVER 表示当前的方法不应该在一个事务中运行。如果一个事务正在进行,则会抛出一个异常。 PROPAGATION_NOT_SUPPORTED 表示该方法不应该在一个事务中运行。如果一个现有事务正在进行中,它将在该方法的运行期间被挂起。 PROPAGATION_SUPPORTS 表示当前方法不需要事务性上下文,但是如果有一个事务已经在运行的话,它也可以在这个事务里运行。 PROPAGATION_REQUIRES_NEW 表示当前方法必须在它自己的事务里运行。一个新的事务将被启动,而且如果有一个现有事务在运行的话,则将在这个方法运行期间被挂起。 PROPAGATION_REQUIRES 表示当前方法必须在一个事务中运行。如果一个现有事务正在进行中,该方法将在那个事务中运行,否则就要开始一个新事务。
Spring MVC和前端的交互扭转过程


mvcc中的delete的时候是怎么处理的?
broker事务回调机制的原理
RocketMQ 增加broker 是如何动态扩容的?
binlog的刷盘策略
0:由系统决定什么时候刷盘 – 默认
1:每次都刷盘
n:n个事务提交之后刷盘
redolog的刷盘策略:
1:每次都刷盘 – 默认
0:每隔1秒刷盘
2:由系统决定什么时候刷盘
rocketmq事务的回调机制的原理是什么?
rocketmq 集群的设计,如何动态扩容的,如何散列到新的broker中的
https://blog.csdn.net/tony_wzx/article/details/110919737
mvcc是怎么处理delete的,跟insert和delete的区别
当使用MVCC SELECT数据时(主要用于RR隔离):
1.如果行未被删除,则只查找事务ID版本小于该事务ID的记录
2.如果行被删除,则版本号必须是未定义的或者大于当前事务的版本号,确定了当前事务开始之前,行没有被删除。
微服务的设计模式
微服务框架?
怎么设计的微服务的?
springboot是怎么动态集成start的源码
spring的三级缓存,二级缓存会怎么样?
1.完整的对象
2.早期暴露的对象
3.早期暴露的对象的工厂
A在实例化的时候,调用构造方法,实例化之后就把包装成对象工厂,把A放在3级缓存,A再进行属性注入,A依赖B
开始B的生命周期,B实例化,把B放在三级缓存,然后再执行属性注入,因为B依赖了A,通过三级缓存查询到了A,调用A的对象工厂的getObject(),这个方法会判断是否存在AOP,方法内部会创建AOP的代理对象,这个时候B把A放在了二级缓存里,AOP对象就是最终申请的内容,B属性注入完,B再执行初始化方法,然后把B放在一级缓存。B的生命周期结束
A属性注入B,属性注入完成,之后再执行初始化 ,从二级拿掉,放在一级。
三级的对象是没有创建过AOP代理的。
jdk的锁
AQS是怎么阻塞的?
LockSupport.park的原理
每个线程都有一个许可(permit),permit只有两个值1和0,默认是0。
- 当调用unpark(thread)方法,就会将thread线程的许可permit设置成1(注意多次调用unpark方法,不会累加,permit值还是1)。
- 当调用park()方法,如果当前线程的permit是1,那么将permit设置为0,并立即返回。如果当前线程的permit是0,那么当前线程就会阻塞,直到别的线程将当前线程的permit设置为1.park方法会将permit再次设置为0,并返回。
注意:因为permit默认是0,所以一开始调用park()方法,线程必定会被阻塞。调用unpark(thread)方法后,会自动唤醒thread线程,即park方法立即返回。
共享锁保证原子性吗?
公平锁和非公平锁
zk watch机制的回调是怎么的
- zk客户端向zk服务器注册watcher的同时,会将watcher对象存储在客户端的watchManager。
- Zk服务器触发watcher事件后,会向客户端发送通知,客户端线程从watchManager中回调watcher执行相应的功能。(监听对应的path,如果对应的path有改变)
watcher机制是一次触发的,在监听器到某个事件,处理完之后会重新监听
多个线程并发处理,如何保证通知的顺序性呢?
异步线程,如何保证处理的顺序性呢?
tomcat为什么破坏双亲委派模型?
redis
集群 – 一致性hash策略
哨兵
主从
kafka发送消息,如果消息id相同,broker是怎么处理的?
参考:https://www.cnblogs.com/wangzhuxing/p/10124308.html#_label0
启动kafka的幂等性
要启动kafka的幂等性,无需修改代码,默认为关闭,需要修改配置文件:enable.idempotence=true 同时要求 ack=all 且 retries>1。
幂等原理:
每个producer有一个producer id,服务端会通过这个id关联记录每个producer的状态,每个producer的每条消息会带上一个递增的sequence,服务端会记录每个producer对应的当前最大sequence,producerId + sequence ,如果新的消息带上的sequence不大于当前的最大sequence就拒绝这条消息,如果消息落盘会同时更新最大sequence,这个时候重发的消息会被服务端拒掉从而避免消息重复。该配置同样应用于kafka事务中。
分布式锁加锁的方式:
zookeeper
spring事务的实现原理,是如何回滚的?
ack原理
setnx
setex
rocket或者kafka是怎么快速定位到offset的
Mybatis中#{}和${}的区别
1.#{}是占位符,在sql预编译时候处理、${}是字符串替换,只是进行字符串拼接
2.#{}修饰的变量会自动加上” ,${}不会
3.#{}可以防止sql注入,${}不能;原因:传入的参数会以 ? 形式显示,因为sql的输入只有在sql编译的时候起作用,当sql预编译完后,传入的参数就仅仅是参数,不会参与sql语句的生成
4.使用mybatis order by 动态参数的时候,要用${}而不是#{}
rocketmq
kafka是如何实现顺序性消费的
kafka的rebalance
rocketmq的消费者机器数是如何确定的呢?
如果消费的慢了,存在积压应该如何解决?
redis的hash槽
redis的集群的扩容机制是如何实现的
redis的高可用
mysql的意向锁和表锁、为什么要有意向锁
悲观锁和乐观锁
算法题:
合并有序链表
删除有序链表中重复出现的元素
Original: https://www.cnblogs.com/fengtingxin/p/14588941.html
Author: 冯廷鑫
Title: 20年5月面试汇总
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/589254/
转载文章受原作者版权保护。转载请注明原作者出处!