

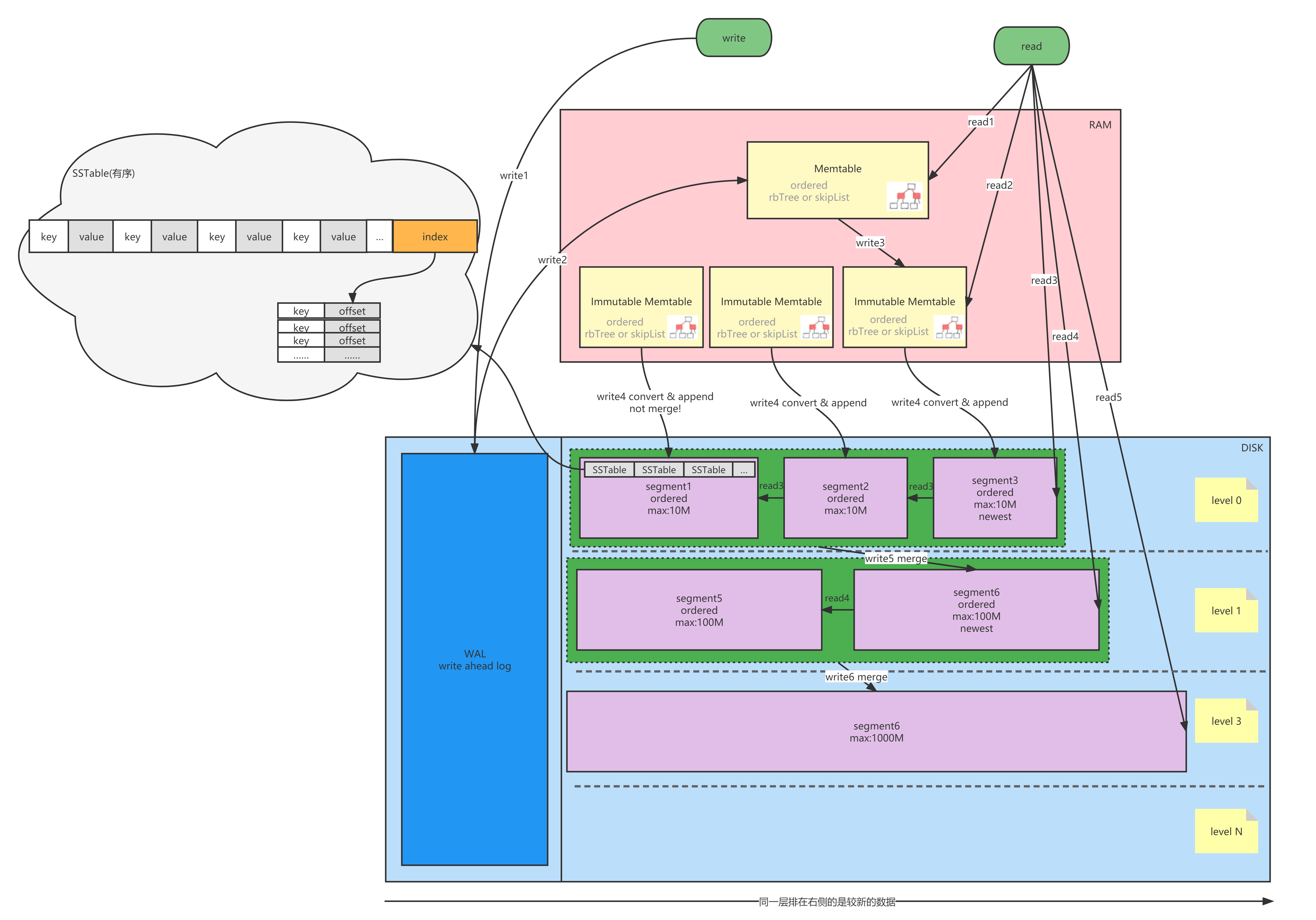

写操作
write1:WAL
把操作同步到磁盘中WAL做备份(追加写、性能极高)
write2:Memtable
完成WAL后将(k,v)数据写入内存中的Memtable,Memtable的数据结构一般是跳表或者红黑树
内存内采用这种数据结构一方面支持内存内高速增删改查(时间复杂度O(logM)),另一方面可以保持有序,为写入磁盘中的SSTable打基础
write3:Immutable Memtable
Memtable存储的元素达到一定数量后,就会把它拷贝一份出来成为Immutable Memtable (不可变的Memtable)并且不能对其修改了,新增的数据都写入新的Memtable,这么做的好处是当需要将Memtable转化为Immutable Memtable时无需暂停工作,至于为什么要拷贝一个Immutable Memtable ,这主要是为了后续落盘时做准备
write4:Minor Compaction
内存中的数据不可能无线的扩张下去,需要把内存里面Immutable Memtable 定期dump到到硬盘上的SSTable level 0层中,此步骤也称为Minor Compaction
SSTable的数据结构是LSM-Tree设计的精髓,他一方面可以保持有序,一方面又能利用磁盘追加写的高性能
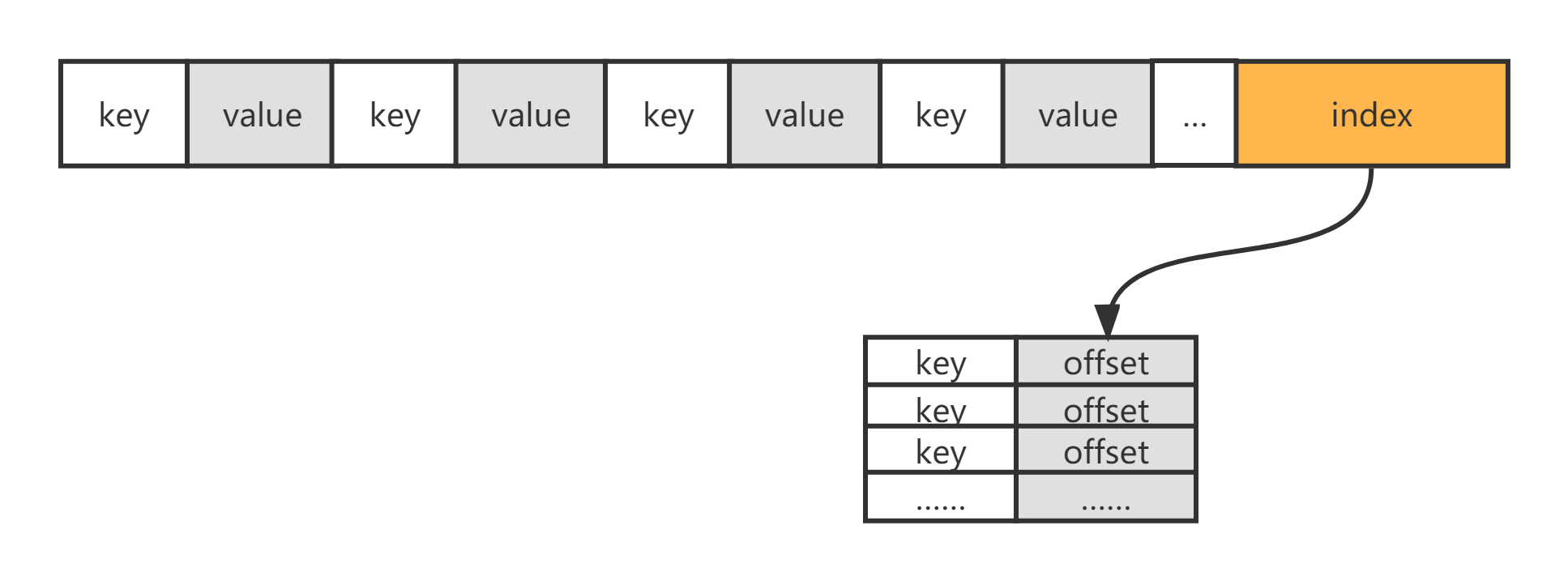
SSTable的数据结构为两部分,前半部分是key与value成对的数据连续存储,这部分数据的key是有序的,后半部分是前半部分的索引,值存储的是key所对应的offset,也是有序的,每次打开这个SSTable需要把索引加载到内存并利用二分搜索可以很快查找出要访问的key的值
dump的过程中每个Immutable Memtable会对应一个SSTable的segment且不会对多个Immutable Memtable进行合并,而是直接将Immutable Memtable中有序的跳表或者红黑树遍历并追加写入到segment,这个过程速度很快。由于不会合并level 0层中的SSTable可能会出现相同的key。
write5、write6:Major Compaction merge
当level 0中的segment越来越多,查询需要遍历的segment也就会越来越多,并且随着时间的推移,重复的key也会越来越多,在后面的步骤就需要对level 0层的segment进行合并merge
合并的过程中是吧多个有序的segment进行归并合并,所以性能不会很差,多个老的segment会合并成一个更长的同样有序的segment并设置到下一层
每一层的segment的数量和大小都会有限制,每当超出限制后,就会做合并操作
虽然定期合并可以有效的清除无效数据,缩短读取路径提升查询效率,提高磁盘利用空间。但Compaction操作是非常消耗CPU和磁盘IO的,尤其是在业务高峰期,如果发生了Major Compaction,则会降低整个系统的吞吐量,这也是一些NoSQL数据库,比如Hbase里面常常会禁用Major Compaction,并在凌晨业务低峰期进行合并的原因。
修改流程
write1:WAL
write2:找到key直接修改或新增key
write3:Immutable Memtable
write4:Minor Compaction
write5、write6…:较新的key(有序可以识别)会替代较老的key
删除流程
write1:WAL
write2:找到key设置状态为tombstone或新增key设置状态为tombstone
write3:Immutable Memtable
write4:Minor Compaction
write5、write6…:因为不确定下层是否有被删除的key,到最后一层merge时才真正删除
读操作
一、按照Memtable(内存)、Immutable Memtable(内存)、level 0 segments(磁盘)、level 1 segments(磁盘)、level 1 segments(磁盘)的顺序查询
二、每层先查新生成的segment
三、每个segment从后向前查
为什么LSM不直接顺序写入磁盘,而是需要在内存中缓冲一下?
单条写的性能没有批量写快,很多中间件比如elasticsearch、kafka、mysql都有类似的内存缓冲设计
在磁盘缓冲的另一个好处是,针对新增的数据,可以直接查询返回,能够避免一定的IO操作
LSM-Tree和B+Tree的比较
LSM-Tree的优点是支持高吞吐的写O1,这个特点在分布式系统上更为看重
针对读取普通的LSM-Tree结构,读取是On的复杂度
在使用索引或者缓存优化后的也可以达到O(logN)的复杂度。
适用于写多读少
B+tree的优点是支持高效的读(稳定的O(logN))
但是在大规模的写请求下(O(LogN)),效率会变得比较低,因为随着insert的操作,为了维护B+树结构,节点会不断的分裂和合并。操作磁盘的随机读写概率会变大,故导致性能降低。
适用于写少读多或写读平衡
Original: https://www.cnblogs.com/zxporz/p/16021373.html
Author: 乂墨EMO
Title: 一文搞懂LSM-Tree
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/583550/
转载文章受原作者版权保护。转载请注明原作者出处!