

Django_模型ORM
Django中内嵌了ORM框架,不需要直接编写SQL语句进行数据库操作,而是通过定义模型类,操作模型类来完成对数据库中表的增删改查和创建等操作。
O是object,也就 类对象的意思。
R是relation,翻译成中文是关系,也就是关系数据库中 数据表的意思。
M是mapping,是 映射的意思。
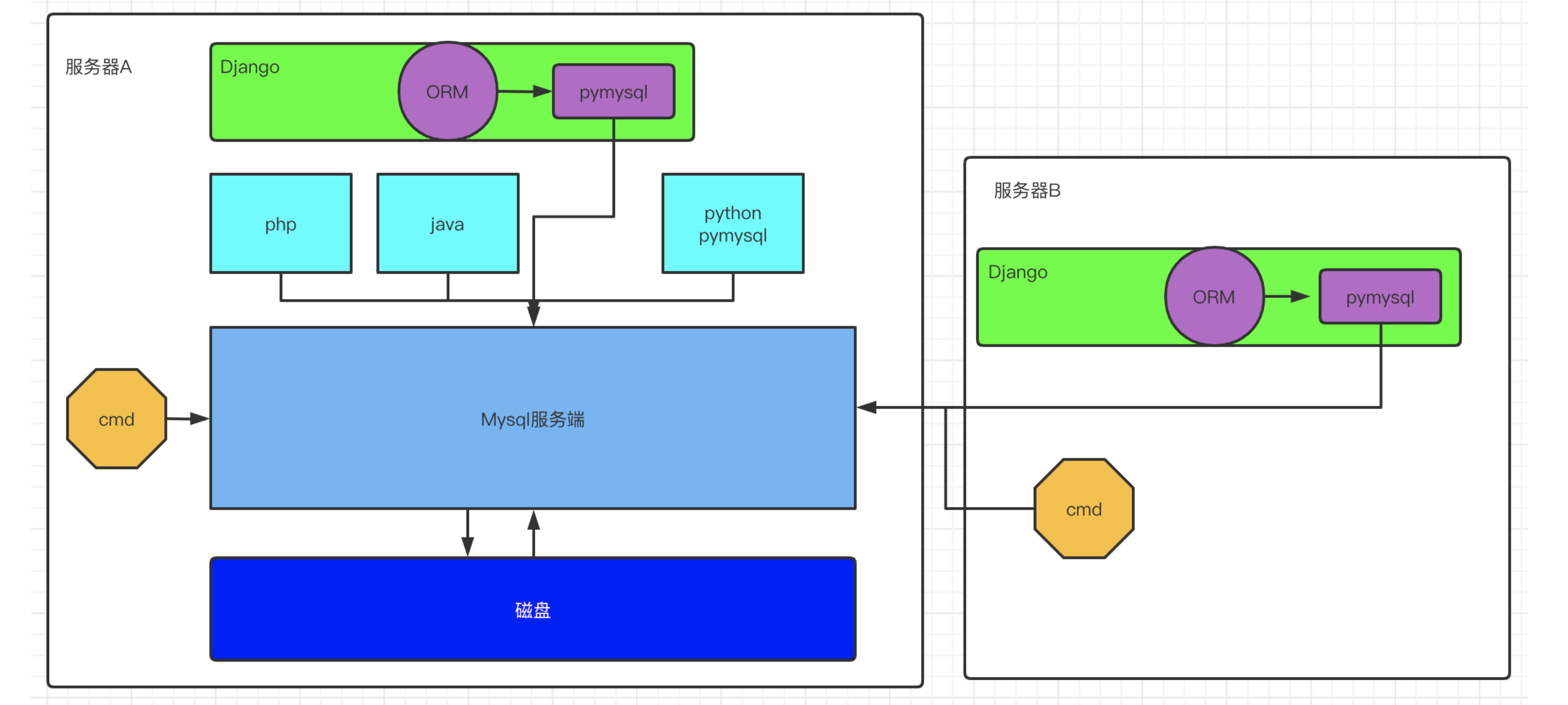

映射:
类:sql语句table表
类成员变量:table表中的字段、类型和约束
类对象:sql表的表记录
ORM的优点
- 数据模型类都在一个地方定义,更容易更新和维护,也利于重用代码。
- ORM 有现成的工具,很多功能都可以自动完成,比如数据消除、预处理、事务等等。
- 它迫使你使用 MVC 架构,ORM 就是天然的 Model,最终使代码更清晰。
- 基于 ORM 的业务代码比较简单,代码量少,语义性好,容易理解。
-
新手对于复杂业务容易写出性能不佳的 SQL,有了ORM不必编写复杂的SQL语句, 只需要通过操作模型对象即可同步修改数据表中的数据.
-
开发中应用ORM将来如果要切换数据库.只需要切换ORM底层对接数据库的驱动【修改配置文件的连接地址即可】
ORM 也有缺点
- ORM 库不是轻量级工具,需要花很多精力学习和设置,甚至不同的框架,会存在不同操作的ORM。
- 对于复杂的业务查询,ORM表达起来比原生的SQL要更加困难和复杂。
- ORM操作数据库的性能要比使用原生的SQL差。
- ORM 抽象掉了数据库层,开发者无法了解底层的数据库操作,也无法定制一些特殊的 SQL。【自己使用pymysql另外操作即可,用了ORM并不表示当前项目不能使用别的数据库操作工具了。】
我们可以通过以下步骤来使用django的数据库操作
1. 配置数据库连接信息
2. 在models.py中定义模型类
3. 生成数据库迁移文件并执行迁文件[注意:数据迁移是一个独立的功能,这个功能在其他web框架未必和ORM一块的]
4. 通过模型类对象提供的方法或属性完成数据表的增删改查操作
配置数据库信息
在settings.py中保存了数据库的连接配置信息,Django默认初始配置使用 sqlite数据库。
- 使用 MySQL数据库首先需要安装驱动程序
pip install PyMySQL
- 在Django的工程同名子目录的
__init__.py文件中添加如下语句
from pymysql import install_as_MySQLdb
install_as_MySQLdb() # 让pymysql以MySQLDB的运行模式和Django的ORM对接运行
作用是让Django的ORM能以mysqldb的方式来调用PyMySQL。

DATABASES = {
"default" : {
'ENGINE':'django.db.backends.mysql',
'HOST': '127.0.0.1', # 数据库主机
'PORT': 3306, # 数据库端口
'USER': 'root', # 数据库用户名
'PASSWORD': '123456', # 数据库用户密码
'NAME': 'student' # 数据库名字
}
}
- 在mysql中创建数据库
mysql> create database student default charset=utf8mb4;
Query OK, 1 row affected (0.00 sec)
如果想打印orm转换过程中的sql,需要在settings中进行如下配置:
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
定义模型类
定义模型类
- 模型类被定义在”子应用/models.py”文件中。
- 模型类必须直接或者间接继承自django.db.models.Model类。
class Information(models.Model):
choices =(
(0,"单身"),
(1,"有对象"),
(2,"已婚")
)
name = models.CharField(max_length=20, db_index=True, verbose_name="姓名")
age = models.SmallIntegerField(verbose_name="年龄")
is_married = models.SmallIntegerField(choices=choices, default=0)
profess = models.CharField(db_column="faculty", max_length=5, db_index=True,verbose_name="专业")
description = models.TextField(default="", verbose_name="个性签名")
class Meta:
db_table = 'Regina_information'
(1) 数据库表名
模型类如果未指明表名db_table,Django默认以 小写app应用名_小写模型类名 为数据库表名。
可通过 db_table 指明数据库表名。
(2) 关于主键
django会为表创建自动增长的主键列,每个模型只能有一个主键列。
如果使用选项设置某个字段的约束属性为主键列(primary_key)后,django不会再创建自动增长的主键列。
class Student(models.Model):
# django会自动在创建数据表的时候生成id主键/还设置了一个调用别名 pk
id = models.AutoField(primary_key=True, null=False, verbose_name="主键") # 设置主键
默认创建的主键列属性为id,可以使用pk代替,pk全拼为primary key。
(3) 属性命名限制
- 不能是python的保留关键字。
- 不允许使用连续的2个下划线,这是由django的查询方式决定的。__ 是关键字来的,不能使用!!!
- 定义属性时需要指定字段类型,通过字段类型的参数指定选项,语法如下:
属性名 = models.字段类型(约束选项, verbose_name="注释")
(4)字段类型
类型 说明 AutoField 自动增长的IntegerField,通常不用指定,不指定时Django会自动创建属性名为id的自动增长属性 BooleanField 布尔字段,值为True或False NullBooleanField 支持Null、True、False三种值 CharField 字符串,参数max_length表示最大字符个数,对应mysql中的varchar TextField 大文本字段,一般大段文本(超过4000个字符)才使用。 IntegerField 整数 DecimalField 十进制浮点数, 参数max_digits表示总位数, 参数decimal_places表示小数位数,常用于表示分数和价格 Decimal(max_digits=7, decimal_places=2) ==> 99999.99~ 0.00 FloatField 浮点数 DateField 日期
参数auto_now表示每次保存对象时,自动设置该字段为当前时间。
参数auto_now_add表示当对象第一次被创建时自动设置当前。
参数auto_now_add和auto_now是相互排斥的,一起使用会发生错误。 TimeField 时间,参数同DateField DateTimeField 日期时间,参数同DateField FileField 上传文件字段,django在文件字段中内置了文件上传保存类, django可以通过模型的字段存储自动保存上传文件, 但是, 在数据库中本质上保存的仅仅是文件在项目中的存储路径!! ImageField 继承于FileField,对上传的内容进行校验,确保是有效的图片
(5)约束选项
选项 说明 null 如果为True,表示允许为空,默认值是False。相当于python的None blank 如果为True,则该字段允许为空白,默认值是False。 相当于python的空字符串,”” db_column 字段的名称,如果未指定,则使用属性的名称。 db_index 若值为True, 则在表中会为此字段创建索引,默认值是False。 相当于SQL语句中的key default 默认值,当不填写数据时,使用该选项的值作为数据的默认值。 primary_key 如果为True,则该字段会成为模型的主键,默认值是False,一般不用设置,系统默认设置。 unique 如果为True,则该字段在表中必须有唯一值,默认值是False。相当于SQL语句中的unique
(6) 外键
在设置外键时,需要通过 on_delete选项指明主表删除数据时,对于外键引用表数据如何处理,在django.db.models中包含了可选常量:
- CASCADE 级联,删除主表数据时连通一起删除外键表中数据
- PROTECT 保护,通过抛出 ProtectedError异常,来阻止删除主表中被外键应用的数据
- SET_NULL 设置为NULL,仅在该字段null=True允许为null时可用
- SET_DEFAULT 设置为默认值,仅在该字段设置了默认值时可用
- SET() 设置为特定值或者调用特定方法,例如:
from django.conf import settings
from django.contrib.auth import get_user_model
from django.db import models
def get_sentinel_user():
return get_user_model().objects.get_or_create(username='deleted')[0]
class UserModel(models.Model):
user = models.ForeignKey(
settings.AUTH_USER_MODEL,
on_delete=models.SET(get_sentinel_user),
)
- DO_NOTHING 不做任何操作,如果数据库前置指明级联性,此选项会抛出 IntegrityError异常
数据迁移
将模型类定义表架构的代码转换成SQL同步到数据库中,这个过程就是数据迁移。django中的数据迁移,就是一个类,这个类提供了一系列的终端命令,帮我们完成数据迁移的工作。
(1)生成迁移文件
所谓的迁移文件, 是类似模型类的迁移类,主要是描述了数据表结构的类文件.
python manage.py makemigrations

在app目录下有一个migrations的文件夹,运行这个命令之后,可能会发生报错

这是因为在setting文件中没有添加这个子应用的配置信息,需要手动补上


这样的话,数据迁移就算成功了,同时migrations文件夹下会新生成一个文件 0001_initial.py,但注意此时的数据库是没有参加这个操作的,所以里面还是空的
Generated by Django 3.2 on 2022-09-15 11:59
from django.db import migrations, models
class Migration(migrations.Migration):
initial = True
dependencies = [
]
operations = [
migrations.CreateModel(
name='Information',
fields=[
('id', models.BigAutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('name', models.CharField(db_index=True, max_length=20, verbose_name='姓名')),
('age', models.SmallIntegerField(verbose_name='年龄')),
('is_married', models.SmallIntegerField(choices=[(0, '单身'), (1, '有对象'), (2, '已婚')], default=0)),
('profess', models.CharField(db_column='faculty', db_index=True, max_length=5, verbose_name='专业')),
('description', models.TextField(default='', verbose_name='个性签名')),
],
options={
'db_table': 'Regina_information',
},
),
]
(2)同步到数据库中
python manage.py migrate


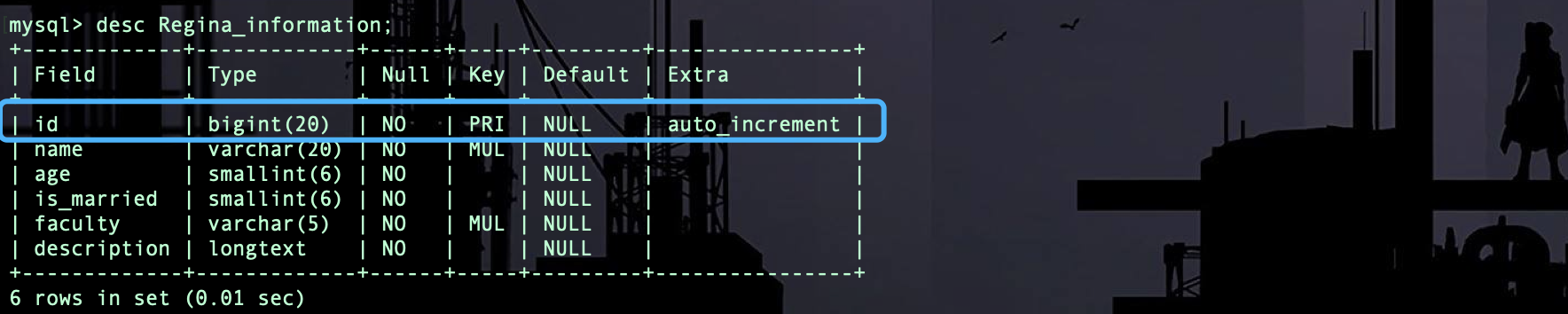
这个主键就是自动生成的,其他的和我们最开始定义的一样。
补充:在django内部提供了一系列的功能,这些功能也会使用到数据库,所以在项目搭建以后第一次数据迁移的时候,会看到django项目中其他的数据表被创建了,但除了 Regina_information,其他的并不重要。
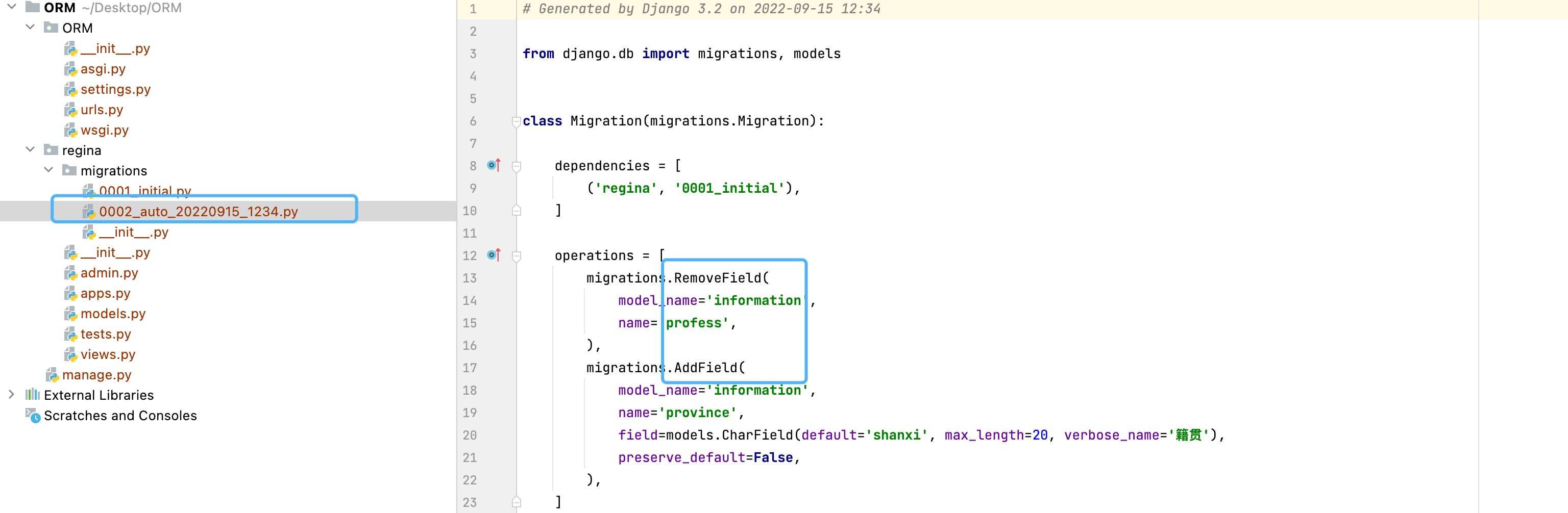
在建立好数据之后,如果我们对数据库结构有想法,比如将原有对faculty那一列删掉,再加上一个新的省份的表
#profess = models.CharField(db_column="faculty", max_length=5, db_index=True,verbose_name="专业")
province = models.CharField(max_length=20, verbose_name="籍贯")
然后我们再去运行前两个命令

会发生这样一个问题:新的province列需要添加一个默认值,这里还给出了两个修改的方法,一个是直接在命令行里添加,一个是退出运行在文件里添加

然后再迁移到数据库里

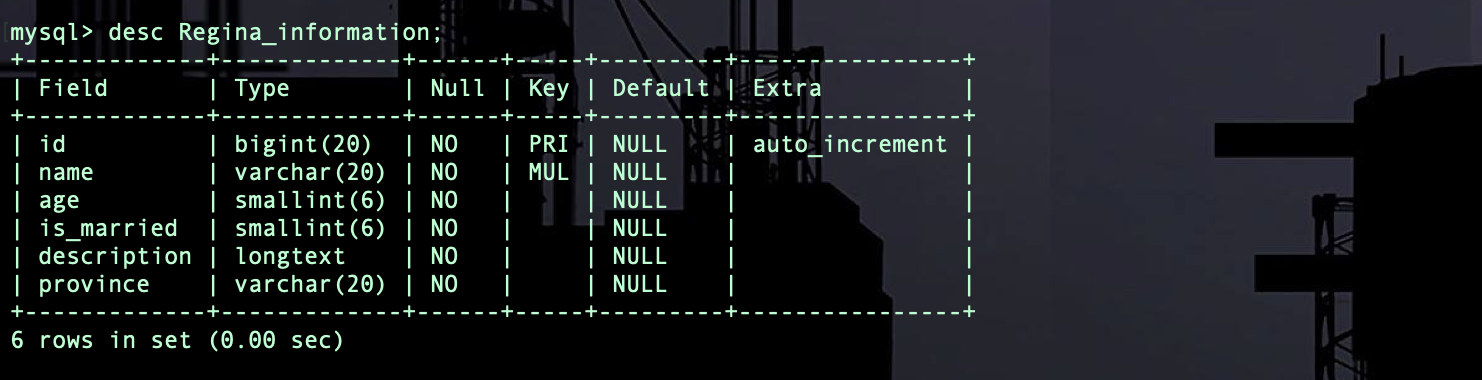
(3)添加记录
首先建立好路由,然后视图函数需要添加一个Information的类对象
def add(request):
stu = Information("ivanlee",23,1,"nothing","shanxi")
stu.save()
return HttpResponse("success")
本身id值是自动产生的,但是如果类对象里不添加这个值,并且不写清楚具体对应的参数名称,就会造成找不到id值
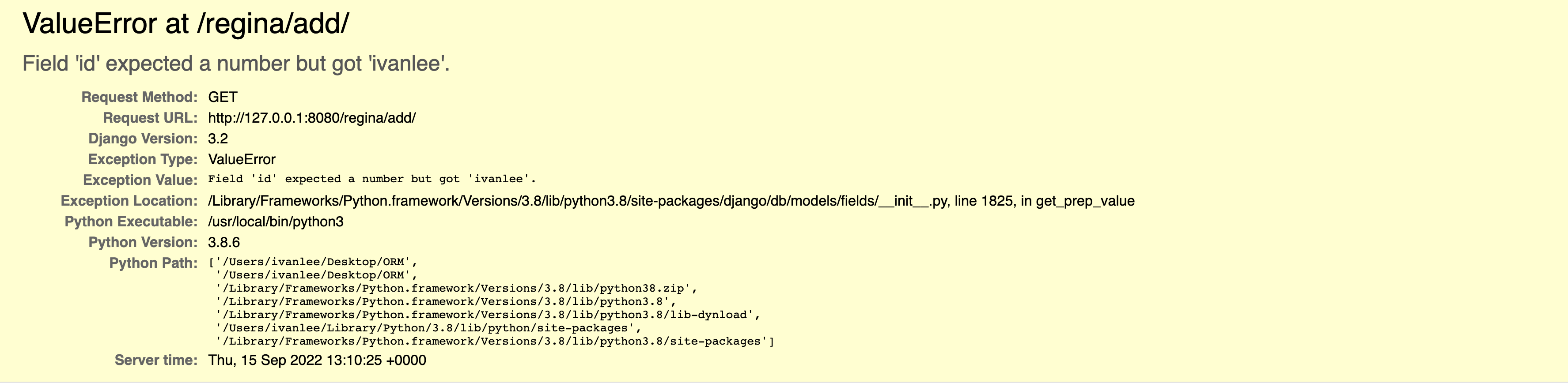
所以要把参数写全
stu = Information(name="ivanlee", age=23,is_married = 1,description = "nothing",province = "shanxi")

此时再去数据库查看

此时代码中也可以进行打印,说明这些内容数据可以进行调用。
查询数据
1. 基础查询
ORM中针对查询结果的限制,提供了一个查询集 [QuerySet].这个QuerySet,是ORM中针对查询结果进行保存数据的一个类型,我们可以通过了解这个QuerySet进行使用,达到查询优化,或者限制查询结果数量的作用。
1)all()
查询所有对象,返回queryset对象。查询集,也称查询结果集、QuerySet,表示从数据库中获取的对象集合。
# 1. all(): 返回一个queryset对象
res = Test.objects.all()
return HttpResponse(res)

此时返回了100个类对象,这种对象的名字叫做 <class 'django.db.models.query.queryset'></class>,此时看不到所有内容和信息,所以在models文件里添加
def __str__(self):
return str(self.id)+": "+self.name + " "+str(self.age)+"\n"
这个内容是自定义的,方便返回值
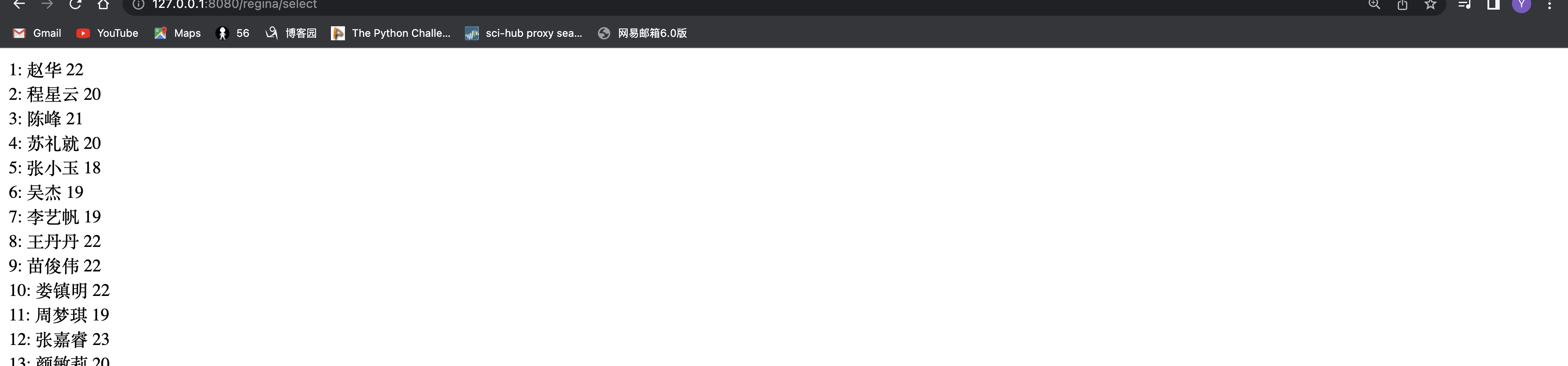
2) first()&&last()
stu1 = Test.objects.first()
print(stu1.name)
stu2 = Test.objects.last()
print(stu2.age)
3) filter()
这个函数等同于SQL语句中的where函数,括号中添加条件
stu = Test.objects.filter( id =12)
print(stu)
>>>
(0.001) SELECT db_student.id, db_student.name, db_student.sex, db_student.class, db_student.age, db_student.description, db_student.create_time, db_student.update_time FROM db_student WHERE db_student.id = 12 LIMIT 21; args=(12,)
>]>
虽然这里只返回了一个数据,但返回类型依然是queryset对象
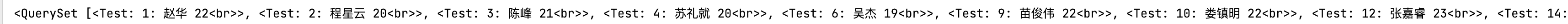
这里过滤还有一个逻辑与的操作,不允许使用大于小于号或者逻辑或操作。例如
stu = Test.objects.filter(id = 7, name="李艺帆")
print(stu)

4) exclude()
这个方法与filter方法相反
stu = Test.objects.exclude( age = 20)
取到的值均为年龄不是20岁的信息

5)get()
返回与所给筛选条件相匹配的对象,返回结果有且只有一个, 如果符合筛选条件的对象超过一个或者没有都会抛出错误。
student = Student.objects.get(pk=1)
print(student)
print(student.description)
get使用过程中的注意点:get是根据条件返回多个结果或者没有结果,都会报错
try:
student = Student.objects.get(name="刘德华")
print(student)
print(student.description)
except Student.MultipleObjectsReturned:
print("查询得到多个结果!")
except Student.DoesNotExist:
print("查询结果不存在!")
6) order_by()
order_by(“字段”) # 按指定字段正序显示,相当于asc从小到大
stu = Test.objects.all()
return HttpResponse(stu.order_by("age"))
order_by(“-字段”) # 按字段倒序排列,相当于 desc 从大到小
stu = Test.objects.all()
return HttpResponse(stu.order_by("-id"))
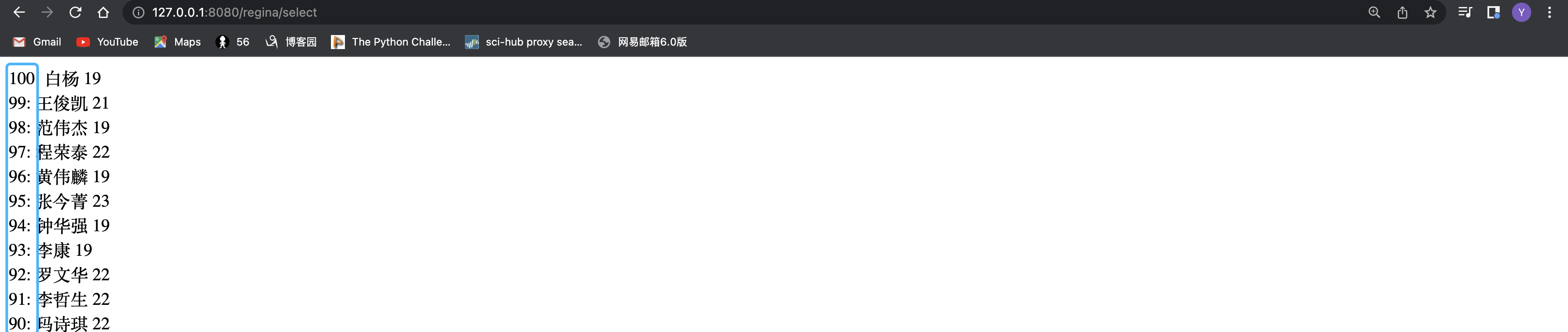
order_by(“第一排序”,”第二排序”,…)
stu = Test.objects.all()
return HttpResponse(stu.order_by("id","-clas"))
7)count()
查询集中对象的个数,返回一个个数
count = Student.objects.filter(sex=1).count()
print(count)
8)exists()
判断查询集中是否有数据,如果有则返回True,没有则返回False
查询Student表中是否存在学生
print(Student.objects.exists())
9)values()、values_list()
value()把结果集中的模型对象转换成 字典,并可以设置转换的字段列表,达到减少内存损耗,提高性能values_list(): 把结果集中的模型对象转换成 列表,并可以设置转换的字段列表(元祖),达到减少内存损耗,提高性能
values 把查询结果中模型对象转换成字典
stu = Test.objects.filter(age = 23)
print(stu.values())
print(stu.values("name","clas"))

这里返回的全部都是queryset集合,但是得到这个字典集合就可以进行序列化
print(json.dumps(list(stu.values("name","clas")),ensure_ascii=False))
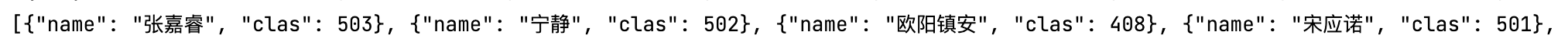
stu = Test.objects.filter(age = 23)
print(stu.values_list("name","clas"))

10) distinct()
如果查询到的数据里有重复的值,使用这个方法可以进行去重,最简单的来说,我们用1和2来区分性别,一共100条信息,那么就会有100个数据,运用去重就得到了两个值
stu = Test.objects.values("sex")
print(stu)
print(stu.distinct())

2. 模糊查询
在基础查询中,我们只能使用 age = 23或者 id = 7这种全等匹配,导致我们无法去条件查询获取更多的数据。模糊查询就可以弥补这一点
1)包含
说明:如果要包含%无需转义,直接写即可。这个和SQL语句中的like关键字功能一致
使用filter方法完成这一功能
stu = Test.objects.filter(name__startswith = "张")
stu = Test.objects.filter(name__endswith="帆")
stu = Test.objects.filter(name__contains = "嘉")
WHERE db_student.name LIKE BINARY '张%' LIMIT 21; args=('张%',)
WHERE db_student.name LIKE BINARY '%帆' LIMIT 21; args=('%帆',)
WHERE db_student.name LIKE BINARY '%嘉%' LIMIT 21; args=('%嘉%',)

2)isnull()
判断所选项是否为空
stu = Test.objects.filter(description__isnull = False)
3) 比较查询
- gt 大于 (greater then)
- gte 大于等于 (greater then equal)
- lt 小于 (less then)
- lte 小于等于 (less then equal)
stu = Test.objects.filter(id__gte = 7, id__lte = 12)
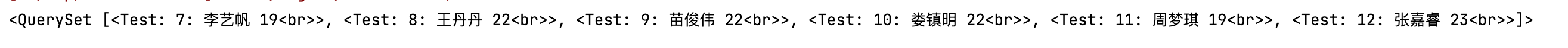
stu = Test.objects.filter(age__gt = 22).order_by("id")
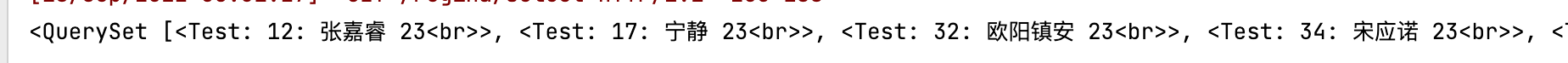
上述的区域查询也可以通过另一个参数 range完成
stu = Test.objects.filter(id__range = (7,12)) #这里都是闭区间
4)in()
表示一个或的关系,满足一个就会获取
stu = Test.objects.filter(id__in = [7,12])


5) 日期
stu = Test.objects.filter(create_time__year = 2020)
stu = Test.objects.filter(create_time__month = 11)
3. 高阶查询
1) F查询
之前的查询都是对象的属性与常量值比较,两个属性怎么比较呢? 答:使用F对象,被定义在django.db.models中。
查询登记时间和更新时间不同的数据
stu = Test.objects.exclude(create_time = F("update_time"))

发现这两个数据不一样
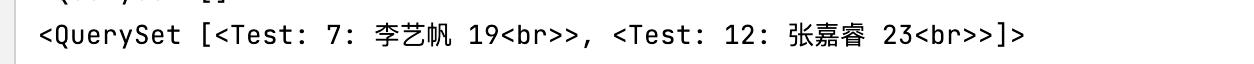
2)Q查询
多个过滤器逐个调用表示逻辑与关系,同sql语句中where部分的and关键字。
与:&
或:|
非:~
stu = Test.objects.filter(Q(id__gt = 10) | Q(age__gt = 20)) 年龄大于20或者序号大于10
stu = Test.objects.filter(~Q(id__gt = 10) ) 序号不大于10
3)聚合查询
使用aggregate()过滤器调用聚合函数。聚合函数包括: Avg 平均, Count 数量, Max 最大, Min 最小, Sum 求和,被定义在django.db.models中。
res = Test.objects.aggregate(Avg("age"))
>>>{'age__avg': 20.47}
原生SQL语句为:SELECT AVG(db_student.age) AS age__avg FROM db_student; args=();
如果我们想按照自己的需求来起名,也可以修改为:
res = Test.objects.aggregate(DIY_avg = Avg("age"))

查看最大的年龄和最小年龄
stu = Test.objects.aggregate(MAxage = Max("age"))
stu = Test.objects.aggregate(minage=Min("age"))
4) 分组查询
QuerySet对象.annotate()
annotate() 进行分组统计,按前面select 的字段进行 group by
annotate() 返回值依然是 queryset对象,增加了分组统计后的键值对
模型对象.objects.values("id").annotate(course=Count('course__sid')).values('id','course')
查询指定模型, 按id分组 , 将course下的sid字段计数,返回结果是 name字段 和 course计数结果
SQL原生语句中分组之后可以使用having过滤,在django中并没有提供having对应的方法,但是可以使用filter对分组结果进行过滤
所以filter在annotate之前,表示where,在annotate之后代表having
同理,values在annotate之前,代表分组的字段,在annotate之后代表数据查询结果返回的字段
stu = Test.objects.values("sex").annotate(avg_age = Avg("age"))

5)原生SQl
执行原生SQL语句,也可以直接跳过模型,才通用原生pymysql.
ret = Student.objects.raw("SELECT id,name,age FROM db_student") # student 可以是任意一个模型
# 这样执行获取的结果无法通过QuerySet进行操作读取,只能循环提取
stu = Test.objects.raw("select id,name,class from db_student where id > 6 and id < 13")
print(stu)
for item in stu:
print(item,type(item))

4. 修改记录
1.基于模型类对象操作save
stu = Test.objects.get(id = 12)
print(stu.name, stu.age)
stu.age = 22
stu.save()
这种方法确实可以达到效果,但是根据sql语句来看,他会更新所有的数据,这样会导致效率很慢

UPDATE db_student SET name = '张嘉睿', sex = 1, class = 503, age = 22, description = '春去秋来,又一年。What did you get ?', create_time = '2020-11-20 10:00:00', update_time = '2020-12-20 10:00:00' WHERE db_student.id = 12; args=('张嘉睿', 1, 503, 22, '春去秋来,又一年。What did you get ?', '2020-11-20 10:00:00', '2020-12-20 10:00:00', 12); alias=default
2.queryset的update方法
Test.objects.filter(id = 7).update(age = 22, description = "我爱张嘉睿")
UPDATE db_student SET age = 22, description = '我爱张嘉睿' WHERE db_student.id = 7; args=(22, '我爱张嘉睿', 7); alias=default
这样sql语句的效率会很高
现在如果将选中的所有的人的年龄都家三岁,并且修改掉个性签名,这里就用到之前所说的F函数和Q函数
Test.objects.filter(~Q(id = 7) & ~Q(id = 12)).update(age = F('age')+3, description = "张嘉睿嫁给李艺帆")
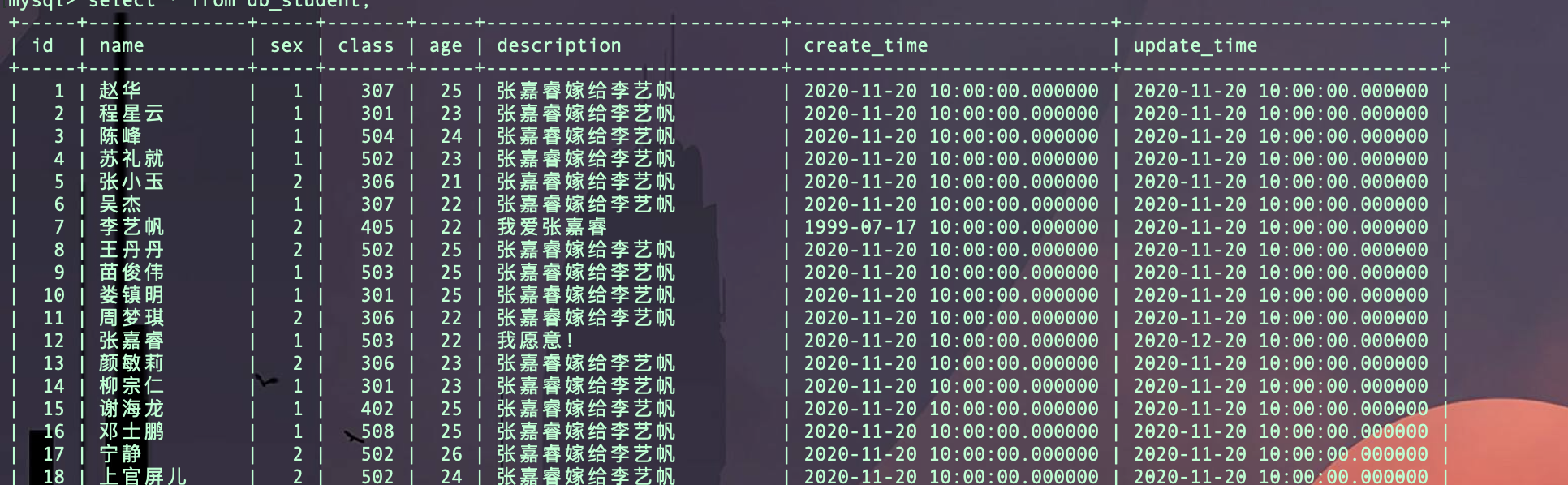
5. 删除记录
1. 基于模型类删除
Test.objects.get(pk = 100).delete()
2. 基于queryset删除
Test.objects.filter(id = 99).delete()
创建关联模型
先创建好几张表
from django.db import models
Create your models here.
class Clas(models.Model):
name = models.CharField(max_length=32, verbose_name="班级名称")
class Course(models.Model):
title = models.CharField(max_length=32, verbose_name="班级名称")
class Student(models.Model):
sex_choices = (
(0, "女"),
(1, "男"),
(2, "保密"),
)
name = models.CharField(max_length=32, unique=True, verbose_name="姓名")
age = models.SmallIntegerField(verbose_name="年龄", default=18) # 年龄
sex = models.SmallIntegerField(choices=sex_choices)
birthday = models.DateField()
#建立一对多的关系: 在数据库中自动创建一个clas_id字段
clas = models.ForeignKey(to="Clas", on_delete=models.CASCADE, db_constraint=False)
#多对多的关系:
stu_course = models.ManyToManyField("Course",db_table="DIY_stu_course")
#一对一关系: 建立关联字段
stu_detail = models.OneToOneField("StudentDetail", on_delete=models.CASCADE)
class StudentDetail(models.Model):
tel = models.CharField(max_length=11)
email = models.CharField(max_length=20)
一定记得要在setting文件同目录下的init文件里添加字段,不然就会报错

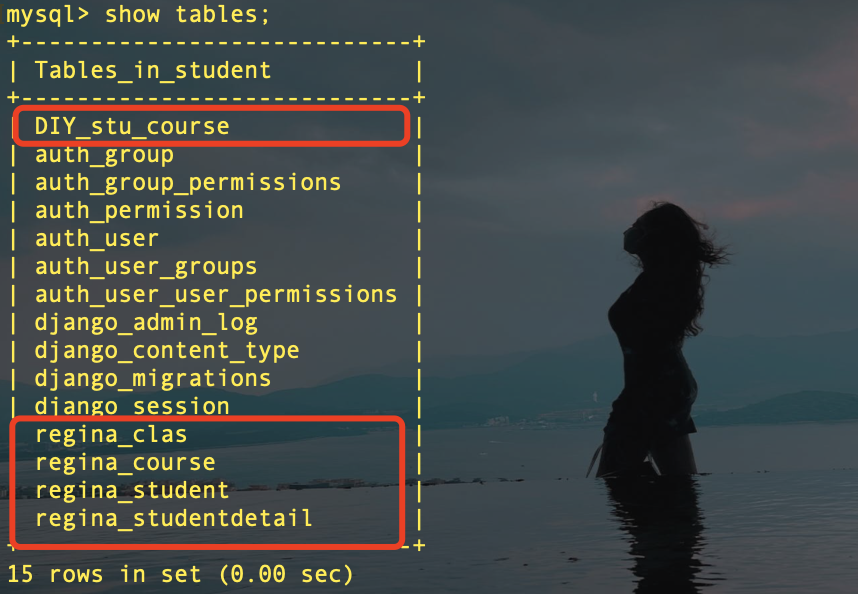
由于多对多关系会建立一个新的表,所以一共有5张表,
mysql> desc DIY_stu_course;
+------------+------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+------------+------+-----+---------+----------------+
| id | bigint(20) | NO | PRI | NULL | auto_increment |
| student_id | bigint(20) | NO | MUL | NULL | |
| course_id | bigint(20) | NO | MUL | NULL | |
+------------+------------+------+-----+---------+----------------+
mysql> desc regina_student;
+---------------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------------+-------------+------+-----+---------+----------------+
| id | bigint(20) | NO | PRI | NULL | auto_increment |
| name | varchar(32) | NO | UNI | NULL | |
| age | smallint(6) | NO | | NULL | |
| sex | smallint(6) | NO | | NULL | |
| birthday | date | NO | | NULL | |
| clas_id | bigint(20) | NO | MUL | NULL | |
| stu_detail_id | bigint(20) | NO | UNI | NULL | |
+---------------+-------------+------+-----+---------+----------------+
关联添加
1)一对一和一对多
因为课程,班级都是独立的数据,所以可以简单手动创建,但是学生表需要关联添加
stu = Student.objects.create(name="regina",age=22,sex=0, birthday="2000-01-27", clas_id = 1, stu_detail_id=1)
print(stu)
print(stu.name)
# stu.clas是一个模型类
print(stu.clas)
#所以想获取学生的班级信息直接调用stu.clas
print(stu.clas.name)
>>>
Student object (1)
regina
Clas object (1)
python127

2) 多对多关系
# 多对多关联记录的增删改查
stu = Student.objects.create(name="ivanlee",age=22,sex=1, birthday="1999-07-17", clas_id = 1, stu_detail_id=2)
c1 = Course.objects.get(title="basketball")
c2 = Course.objects.get(title="math")
stu.stu_course.add(c1,c2)
stu2 = Student.objects.get(name="regina")
c3 = Course.objects.get(title="valleyball")
stu2.stu_course.add(c2,c3)
因为学生与课程是多对多的关系,所以一个学生可以选择多门课程,一个课程也可以被多名学生选中,因此c2可以被反复添加

多对多关系会单独生成一张表,我给他起了名字叫做 DIY_Stu_course

其实添加方式也可以通过添加课程id值直接添加,或者是通过列表传参的方式
stu2.stu_course.add(4)
stu.stu_course.add(*[3,4])
删除
删除操作
stu = Student.objects.get(name="regina")
stu.stu_course.remove()
如果想要删除某个同学的全部选课,可以使用clear函数
stu.stu_course.clear()
如果想要清空并且重新选新的课,可以直接使用set函数,相当于 set = clear + add
stu.stu_course.set(1,2)
查找
想要查询学生课程的名称使用all函数
stu = Student.objects.get(name="regina")
course = stu.stu_course.all()
print(course)
all函数所对应的sql语句为:
SELECT regina_course.id, regina_course.title FROM regina_course INNER JOIN DIY_stu_course ON (regina_course.id = DIY_stu_course.course_id) WHERE DIY_stu_course.student_id = 1 LIMIT 21;

关联查询
一对多
'''
基于对象的关联查询(子查询)
'''
# 查询学生的课程名称
# 正向查询:通过学生表的关联属性去查到关联的表字段
stu = Student.objects.get(name = "regina")
print(stu.clas.name)
# 反向查询方法1:查看某个班的学生有哪些
# 要依赖一个表名的小写和_set的组合,表示这是一个集合的形式
class_ = Clas.objects.get(name = "python127")
name_ = class_.student_set.all()
print(name_) #, ]
上述反向查询使用的名字是系统默认的命名方式,如果想要根据自己的要求写名字,需要修改models文件
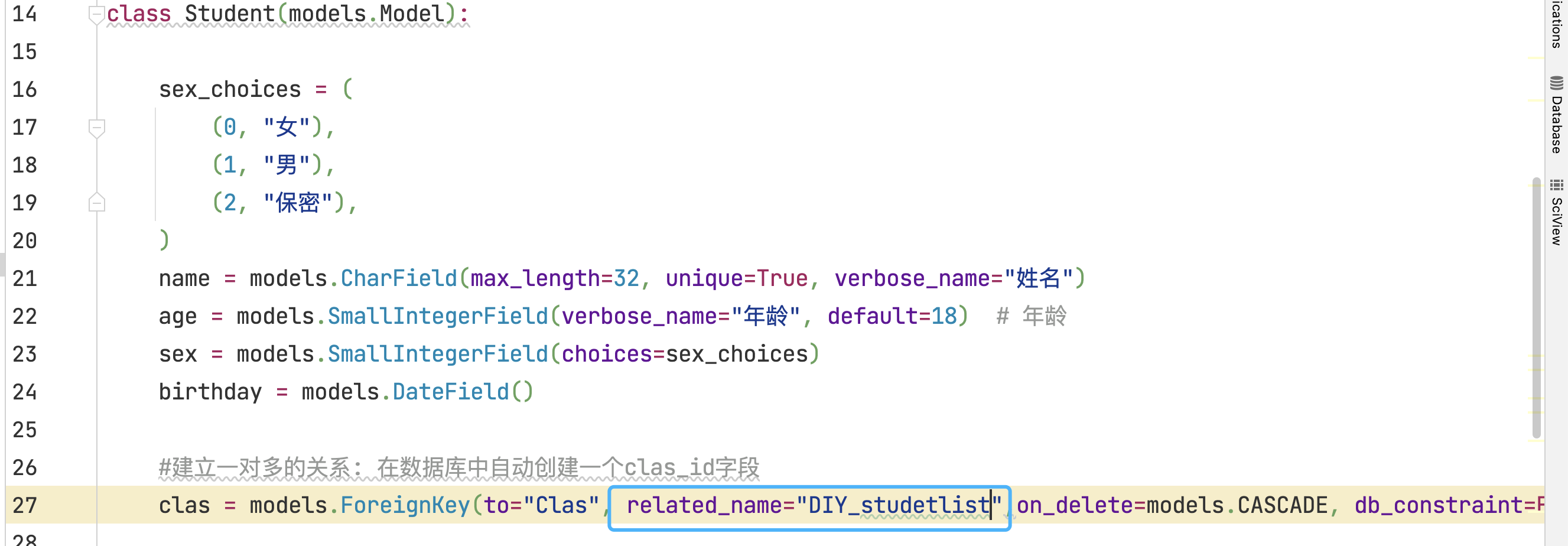
最初就是在建立关系时使用的参数里没有添加related_name字段,现在设置为自己定义的可以直接进行查询
class_ = Clas.objects.get(name = "python127")
name_ = class_.DIY_studetlist.all()
一对一
一对一的关联查询
stu = Student.objects.get(name="regina")
print(stu.stu_detail.email)
email_ = StudentDetail.objects.get(tel=155)
print(email_.student.name)
这里的反向查询直接输入小写的原表明即可,因为这是一对一关系,只会搜索到一个对象,但同样可以使用related_name进行改写
多对多
多对多的关联查询
stu = Student.objects.get(name="regina")
print(stu.stu_course.all())
course_name = Course.objects.get(title="math")
ret = course_name.student_set.all()
print(ret)
多对多的方式基本上和一对多一样

现在把数据库改一下
stu_course = models.ManyToManyField("Course",related_name="DIY_studentcourse",db_table="DIY_stu_course")
ret = course_name.DIY_studentcourse.all()
print(ret.values("name","age"))
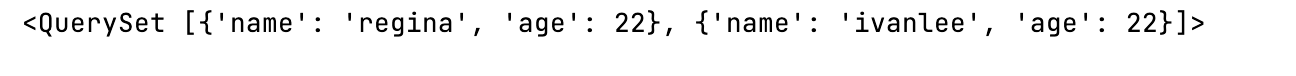
join 查询
首先复习一下sql语句中的join用法
-- 查询学生的姓名和所在班级的名称
select regina_student.name, regina_clas.name from regina_student inner join regina_clas on regina_student.clas_id = regina_clas.id;

如果通过多对多关联表进行join
-- 查询学生的姓名和选修的课程
select * from regina_student left join DIY_stu_course Dsc on regina_student.id = Dsc.student_id;

这里面并没有出现课程的名称,所以继续连接另外一个表
select name, course_id, regina_course.title from regina_student left join DIY_stu_course on regina_student.id = DIY_stu_course.student_id inner join regina_course on regina_course.id = DIY_stu_course.course_id;
基于双下划线查询
正向查询
ret1 = Student.objects.filter(age__gt=20).values("name" , "clas__name")
print(ret1)
# 反向查询
ret2 = Clas.objects.filter(DIY_studetlist__age__gt=20).values("DIY_studetlist__name","name")
print(ret2)
多对多
stu = Student.objects.filter(name = "regina").values("name","stu_course__title")
print(stu)
#查询选了数学的学生姓名
cou = Course.objects.filter(title="math").values("DIY_studentcourse__name")
#查询所有学生的姓名和手机号
stu = Student.objects.filter().values("name", "stu_detail__tel")
这些都是有相关联的表都查询,如果两个表之间没有直接关系,就需要借助一个中间表进行联系
`python
查询手机号为110的学生姓名以及班级名称
stu = StudentDetail.objects.filter(tel="155").values("student__name","student__clas__name")
Original: https://www.cnblogs.com/ivanlee717/p/16716534.html
Author: ivanlee717
Title: Django_模型详解
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/582552/
转载文章受原作者版权保护。转载请注明原作者出处!