

写在开篇
关于prometheus的高可用方案,经过笔者不断的研究、对比、和搜索,发现不管是官方、还是各大搜索引擎搜索出来的方案,都不符合笔者的需求。因此,笔者自己设计了一套prometheus主备的方案。该方案是一个很low的方案,但经过不断的实践、验证,最后发现还挺实用。关于本方案,笔者以后还会找机会用go或者python开发一个带UI界面的prometheus主备管理器,让它的功能更加完善,做到更自动化和智能化。Prometheus是监控领域的新启之秀,潜力非常大,K8S内置对它直接支持,直接有提供exporter,而K8S又是未来基础架构的主力军。而监控方面,prometheus成为未来的主力军是胜券在握,把它玩透了你绝对不吃亏。好了,前戏有点多了。敬请大家的关注、点赞、转发。下面的正式进入主题!!!
- DIY的prometheus主备方案架构图
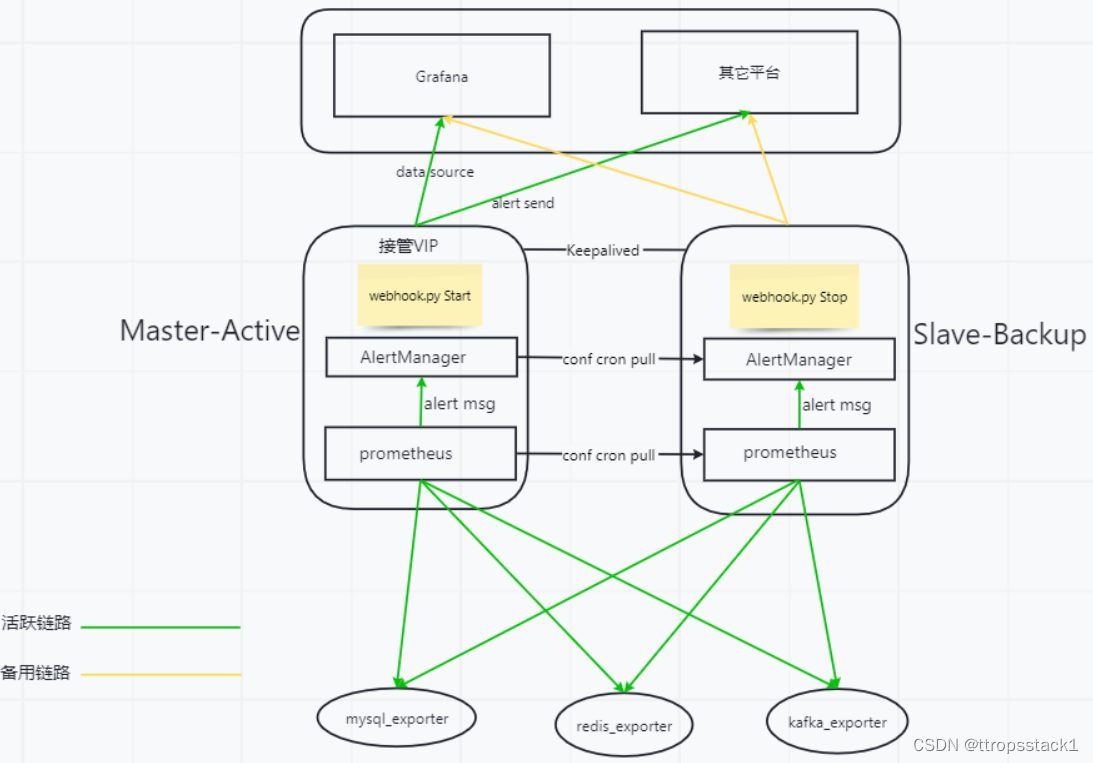

方案说明
- 两台主机(master和slave)分别部署keepalived,让master主机接管VIP,注意:keepalived建议配置成非抢占模式
-
之所以采用VIP的原因如下:
-
为了方便日常访问Prometheus页面和Alertmanager页面,在主备切换时,可无需更换访问ip。
-
上层可视化应用(如grafana)通过VIP来对接Prometheus的数据源,当主备切换时,无需在grafana上修改对应的数据源。
-
日常由master主机处于工作状态,在master中,启动Promethues和Alertmanager组件,启动webhook脚本(告警消息推送脚本,用于将告警推送到其他平台)。
- slave主机备用状态,在slave中,需要启动Promethues组件(用于拉取指标数据),启动Alertmanager组件(用于接收警报消息),这里注意,webhook脚本需处于停止状态(不进行告警推送到其他平台)。这样做是为了规避推送重复告警的问题,虽然Alertmanager有自身的去重告警功能,但这样的设计根本就没有告警重复,已经将重复扼杀在摇篮里了。
- 在接入监控对象时(部署对应的exporter), 切记,仅需要在master上做配置即可, slave定期从master拉取配置文件(包括主配置文件、警报规则文件等),定期和master保持配置同步。
- master和slave的配置保持同步,意味着两边都会拉取被监控对象的监控指标数据。监控指标的拉取、警报的触发两台均一起工作,但告警的推送只有master在负责,slave不负责告警的推送,如果master不可用了,就需要将slave上的webhook脚本手动拉起来,由slave上的webhook脚本接管告警推送的任务。
- 配置文件同步的做法是采用最原始、最简单、最粗暴的办法,master和slave的配置文件同步方案如下:
Master主机:
- master提供配置文件下载服务,由python自带的SimpleHTTPServer模块实现,且需要在prometheus或alertmanager规范安装路径下(如/usr/local/prometheus)进行SimpleHTTPServer模块的启动,拉起后,默认的监听端口是8000。
- master检测配置文件变化情况,如达到条件则触发备份和打包新的配置目录。在master上,设计了一个保存通知动作的文件notice_slave.action,配置发生变化写入1,配置没有发生变化写入0。同时,该检测脚本作为常驻进程在后台运行。
Slave主机:
- slave从master下载通知动作的文件notice_slave.action,根据状态码(1和0)来决定接下来的动作,如果是1,则:从master下载配置压缩包、备份原有配置目录、解压新下载后的配置压缩包、热重启相关组件(prometheus、alertmanger),如果是0则什么都不做。
对于配置文件的同步,也是有两种实现方式的,要么是推,要么是拉,笔者的这个方案里是后者,笔者目前之所以折腾零散的shell脚本来去做高可用的管理,是为了能快速解决需求,因此才做了这个简陋的方案,笔者的原则是:困难的事情简单做,简单的事情咱不做(开玩笑哈!!!)。 当然,笔者以后会通过Go或者Python打造一个管理Promtheus主备的工具,且是带UI的管理工具,敬请期待推出!我不造车,我只造零件。
一、规划和规范
1. 设备规划(本示例为测试环境)
角色 物理IP VIP 安装组件 告警推送方式 master 192.168.11.146 192.168.11.203(当前接管) prometheus、alertmanager(均拉起) webhook方式,脚本拉起 slave 192.168.11.147 prometheus、alertmanager(均拉起) webhook方式,脚本不拉起(备用)
2. 统一安装路径规范
master和slave主机的标准安装路径均为:/usr/local/,笔者安装组件后的环境如下:
/usr/local/keepalived (注意:建议keepalived配置成非抢占模式)
/usr/local/prometheus
/usr/local/alertmanager
至于安装路径的规范,请自行根据实际情况敲定。
3. prometheus组件配置文件和目录规范
- 所有配置文件统一标准路径:/usr/local/prometheus/conf/
- prometheus主配置文件:/usr/local/prometheus/conf/prometheus.yml
- 按业务粒度,一个业务对应一个目录,业务下不同的监控对象都放在对应的业务目录下:/usr/local/prometheus/conf/business
特别说明1:请自行在prometheus组件的安装目录下创建conf目录,并将默认的prometheus.yml配置文件移动进去
特别说明2:请自行在prometheus组件的配置文件统一标准路径(./conf)下创建业务目录business
特别说明3:业务目录下,又包含两个目录:job和rule,job用于存放监控拉取配置文件,rule用于存放警报规则配置文件
配置文件目录和业务目录规划示范,如下:
/usr/local/prometheus/ # 这是规范的安装路径
/usr/local/prometheus/conf/ # 这是规范的配置目录
/usr/local/prometheus/conf/prometheus.yml # 这是主配置文件
/usr/local/prometheus/conf/business 这是按业务粒度规划的业务根目录
如下是业务A的规划案例:
/usr/local/prometheus/conf/business/a_business/ 这是业务a的目录
/usr/local/prometheus/conf/business/a_business/job/oracle.yml 这是业务a下拉取oracle监控配置数据的yml配置文件
/usr/local/prometheus/conf/business/a_business/rule/oracle.rules 这是业务a下oracle的警报规则rules配置文件
特别说明:上述对业务A的配置文件规划案例非常重要,请务必参照此规范。
4. alertmanager组件配置文件和目录规范
关于Alertmanager组件的配置文件,相对来说没prometheus那么复杂,主要的规划还是在prometeus中
- alertmanager的主配置文件统一标准路径放在prometeheus的conf中:/usr/local/prometheus/conf/alertmanager.yml
5. 备份路径规范
在master主机上,会自动备份原有的conf配置文件目录
- Prometheus组件
统一备份路径为:/usr/local/prometheus/backup/
- Alertmanager组件
不涉及到备份
6. 日志目录规范
在master主机和slave主机上运行的脚本日志均统一存放在指定目录
- Prometheus组件
统一日志目录:/usr/local/prometheus/logs/
- AlertManager组件
统一日志目录:/usr/local/alertmanager/logs/
二、组件安装部署
注意:master和slave均需要安装如下组件
- keepalived高可用组件
- prometheus监控组件
- alertmanager警报组件
因组件的安装部署不是本文的主题,所以笔者在这里就不再撰写安装步骤,在此省略了哈,请自行安装好即可。
三、prometheus配置文件目录同步部署
说明1:均需要在master和slave上部署文件同步相关脚本
说明2:以下的每一步操作,请均进入到”/usr/local/prometheus/”目录下进行操作(此目录是之前已经定为安装规范的目录),如您的规范目录和笔者的不同,请进入到您自己的规范目录下。
说明3:以下涉及的脚本,涉及的目录:conf、backup、logs、cfmd5,请自行在规范的目录下进行创建即可。
1. master部署配置文件下载服务
- 通过python拉起简单的Http服务,默认监听端口为8000,创建脚本startPromconfSyncApi.sh
startPromconfSyncApi.sh脚本内容如下:
#!/bin/sh
nohup /usr/bin/python -m SimpleHTTPServer > /dev/null &
运行配置文件下载服务的脚本
sh startPromconfSyncApi.sh
拉起http服务脚本后查看端口
[root@prosvr-master prometheus]# netstat -tulnp | grep 8000
tcp 0 0 0.0.0.0:8000 0.0.0.0:* LISTEN 1293/python
[root@prosvr-master prometheus]#
- 创建配置文件变化检查脚本startTarPackConf.sh
注意,请在规范的安装路径/usr/local/prometheus/下面创建startTarPackConf.sh脚本,以及创建目录cfmd5
startTarPackConf.sh脚本内容:
#!/bin/sh
time_log=date "+%Y-%m-%d %H:%M:%S"
echo "${time_log} 配置检查器启动"
task_wait_sec=4
find ./conf -type f -print0 | xargs -0 md5sum > ./cfmd5/cfmd5.list
while true
do
time_bak=date "+%Y%m%d%H%M%S"
time_log=date "+%Y-%m-%d %H:%M:%S"
md5sum -c ./cfmd5/cfmd5.list > ./cfmd5/check_cfmd5.log
md5ret=cat ./cfmd5/check_cfmd5.log | grep "FAILED" | wc -l
while true
do
if [ ${md5ret} -gt 0 ]
then
echo "${time_log} 配置文件发生变化,触发备份和打包压缩"
mv ./conf.tar.gz ./backup/conf.tar.gz_bak_${time_bak}
tar -zcf conf.tar.gz conf/
echo 1 > ./notice_slave.action
curl -X POST http://127.0.0.1:9090/-/reload
break
else
echo 0 > ./notice_slave.action
break
fi
done
find ./conf -type f -print0 | xargs -0 md5sum > ./cfmd5/cfmd5.list
sleep ${task_wait_sec}
done
脚本实现说明:很简单,就是递归搜索conf目录下的所有配置文件且生成md5值保存在./cfmd5/cfmd5.list,并使用md5sum -c实时检查./cfmd5/cfmd5.list中的文件md5值是否有变化,且将结果输出到./cfmd5/check_cfmd5.log,再通过cat ./cfmd5/check_cfmd5.log进行过滤”FAILED”并统计,只要出现有”FAILED”,就认为配置文件有发生过变化,要么是增加了,要么是现有的配置文件做了修改。统计的结果保存在md5ret变量,判断条件就是md5ret结果大于0就触发北方和打包压缩配置目录,同时master中的配置文件发生变化后,也会自动触发热重启。接着将状态码1写入到./notice_slave.action文件中,如果没有变化,将状态码就是0。notice_slave.action文件是存储状态变化的(在这里就干脆叫通知文件吧!)。
关于通知文件(notice_slave.action)设计的详细说明:对slave端来讲,由slave主动拉取这个通知文件并读取结果,如果是1就触发拉取master打包好的压缩目录并解压,且继续热重启相应的组件,如果是0就啥也不干。
关于参数task_wait_sec=4,任务等待时间,master目前配置的是4秒,也就是每隔4秒检测一次。对于slave端,也有一个pull_wait_sec=2参数(目前是2秒),也就是每隔2秒拉取一次通知文件,并做判断。这里要注意,slave的pull_wait_sec拉取时间一定要小于master的task_wait_sec时间,别问为什么,自己思考去。
拉起配置文件变化检查脚本
拉起
nohup sh ./startTarPackConf.sh >> ./logs/tar_pack.log &
查看进程
[root@prosvr-master prometheus]# ps -aux | grep tar
root 2473 0.0 0.3 113284 848 pts/1 S 09:48 0:02 sh start_tar_pack_conf.sh
拉起后会作为后台进程常驻,需要停止的话,查看pid,然后kill掉即可。
- 创建启动prometheus组件,脚本startPrometheusSvr.sh
startPrometheusSvr.sh内容:
#!/bin/sh
nohup ./prometheus --storage.tsdb.retention.time=180d --web.enable-lifecycle --config.file=./conf/prometheus.yml --log.level=warn --log.format=json >> ./logs/prometheus_run_status.log &
数据保留周期是180天,请根据实际情况调整,其他参数的意义请自行help
在上面脚本的启动参数中,也可以通过参数–storage.tsdb.path=”data/”修改本地数据存储的路径,不指定的话,时序数据默认是在prometheus的data目录下,如需修改数据的存储路径,建议存放在性能好(SSD、高端磁盘阵列)、容量大的目录中。
接着启动prometheus
拉起
[root@prosvr-master prometheus]# sh startPrometheusSvr.sh
查看进程,检查是否启动成功
[root@prosvr-master prometheus]# ps -aux | grep prometheus
root 1201 0.0 30.1 1100628 66840 pts/0 Sl 08:45 0:22 ./prometheus --web.enable-lifecycle --config.file=./conf/prometheus.yml --log.level=warn --log.format=json
- 为了方便热重启操作,创建脚本hot_restart_prometheus.sh,当修改了配置文件后,就手动执行这个脚本进行热重启
#!/bin/sh
curl -X POST http://127.0.0.1:9090/-/reload
平滑重启示例
[root@prosvr-master prometheus]# sh hot_restart_prometheus.sh
在日常维护中,当配置文件发生了变更就可以利用该脚本进行平滑重启
- 创建汇总启动脚本start_all.sh
#!/bin/sh
sh ./startPromconfSyncApi.sh
nohup sh ./startTarPackConf.sh >> ./logs/tar_pack.log &
sh ./startPrometheusSvr.sh
以后就不用一个一个脚本拉起了,直接拉起该脚本即可一并启动
- 为了增加安全性,仅允许slave主机访问配置文件拉取服务的端口(笔者这里是8000端口)
在tcp协议中禁止所有的ip访问本机的8000端口,仅允许slave主机(192.168.11.147)访问本机的8000端口(注意按顺序执行)
iptables -I INPUT -p tcp --dport 8000 -j DROP
iptables -I INPUT -s 192.168.11.147 -p tcp --dport 8000 -j ACCEPT
查看规则
[root@prosvr-master prometheus]# iptables -nvL
Chain INPUT (policy ACCEPT 9 packets, 744 bytes)
pkts bytes target prot opt in out source destination
8 552 ACCEPT tcp -- * * 192.168.11.147 0.0.0.0/0 tcp dpt:8000
0 0 DROP tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:8000
保存规则
注意:使用此命令的规则位置可以是任意的,此方式保存的规则在重启机器后无法自动生效,需要使用命令iptables-restart恢复),笔者这里是保存在了/etc/sysconfig/my-iptable-rule-script
保存
[root@prosvr-master prometheus]# iptables-save > /etc/sysconfig/my-iptable-rule-script
查看
[root@prosvr-master prometheus]# cat /etc/sysconfig/my-iptable-rule-script
Generated by iptables-save v1.4.21 on Mon May 30 10:37:12 2022
*filter
:INPUT ACCEPT [49:4408]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [27:4840]
-A INPUT -s 192.168.11.147/32 -p tcp -m tcp --dport 8000 -j ACCEPT
-A INPUT -p tcp -m tcp --dport 8000 -j DROP
COMMIT
Completed on Mon May 30 10:37:12 2022
手动清空规则,模拟规则丢失后,从文件中加载
查看
[root@prosvr-master prometheus]# iptables -nvL
Chain INPUT (policy ACCEPT 122 packets, 12944 bytes)
pkts bytes target prot opt in out source destination
0 0 ACCEPT tcp -- * * 192.168.11.147 0.0.0.0/0 tcp dpt:8000
0 0 DROP tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:8000
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 86 packets, 14400 bytes)
pkts bytes target prot opt in out source destination
[root@prosvr-master prometheus]#
手动清空
[root@prosvr-master prometheus]# iptables -F
清空后查看
[root@prosvr-master prometheus]# iptables -nvL
Chain INPUT (policy ACCEPT 12 packets, 1056 bytes)
pkts bytes target prot opt in out source destination
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 7 packets, 1080 bytes)
pkts bytes target prot opt in out source destination
[root@prosvr-master prometheus]#
使用iptables-restore命令还原iptables-save命令所备份的iptables配置
[root@prosvr-master prometheus]# iptables-restore < /etc/sysconfig/my-iptable-rule-script
还原后查看
[root@prosvr-master prometheus]# iptables -nvL
Chain INPUT (policy ACCEPT 34 packets, 2992 bytes)
pkts bytes target prot opt in out source destination
0 0 ACCEPT tcp -- * * 192.168.11.147 0.0.0.0/0 tcp dpt:8000
0 0 DROP tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:8000
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 18 packets, 2480 bytes)
pkts bytes target prot opt in out source destination
[root@prosvr-master prometheus]#
特别说明:预防规则重启后丢失的办法还有一种,就是将配置规则写入到启动文件中,如/etc/rc.local,笔者之前将规则保存在/etc/sysconfig/my-iptable-rule-script文件中,那么就可以将恢复的命令 iptables-restore < /etc/sysconfig/my-iptable-rule-script 写入到/etc/rc.local中
特别注意:如果您的环境和笔者不一样,请自行更改为您自己的IP和端口即可。
- 创建汇总停止脚本stop_all.sh
#!/bin/sh
ps -aux | grep SimpleHTTPServer | grep -v grep | awk '{print $2}' | xargs kill
ps aux | grep startTarPackConf.sh | grep -v grep | awk '{print $2}' | xargs kill
ps -aux | grep -v grep | grep prometheus | awk '{print $2}' | xargs kill
日常维护中,如有需要停止全部服务的需求,运行该脚本即可。
2. slave部署配置文件拉取服务
特别说明:在slave主机上,请在规范的目录下创建conf、logs、backup目录
- 将首次安装完成的prometheus.yml文件移动到当前的conf目录下
mv ./prometheus.yml ./conf/
之所以要移动slave本身的prometheus.yml,是因为要从master同步过来已经规划好的conf配置目录,拉取后会覆盖slave上的conf目录,以后都以master的配置为主
- 准备启动prometheus组件的脚本
脚本/usr/local/prometheus/startPrometheusSvr.sh,代码:
#!/bin/sh
nohup ./prometheus --storage.tsdb.retention.time=180d --web.enable-lifecycle --config.file=./conf/prometheus.yml --log.level=warn --log.format=json >> ./logs/prometheus_run_status.log &
数据保留周期是180天,请根据实际情况调整,其他参数的意义请自行help
在上面脚本的启动参数中,也可以通过参数–storage.tsdb.path=”data/”修改本地数据存储的路径,不指定的话,时序数据默认是在prometheus的data目录下,如需修改数据的存储路径,建议存放在性能好(SSD、高端磁盘阵列)、容量大的目录中。
- 接着启动prometheus,并检查是否启动成功
[root@prosvr-slave prometheus]# sh startPrometheusSvr.sh
[root@prosvr-slave prometheus]# ps -aux | grep prometheus
root 5107 3.7 16.0 768960 35456 pts/0 Sl 17:18 0:00 ./prometheus --web.enable-lifecycle --config.file=./conf/prometheus.yml --log.level=warn --log.format=json
root 5114 0.0 0.4 112812 976 pts/0 R+ 17:18 0:00 grep --color=auto prometheus
You have new mail in /var/spool/mail/root
[root@prosvr-slave prometheus]# netstat -tulnp | grep prometheus
tcp6 0 0 :::9090 :::* LISTEN 5107/./prometheus
[root@prosvr-slave prometheus]#
- 准备从master拉取配置文件目录的脚本startUpdateSyncConf.sh,代码:
#!/bin/sh
time_log=date "+%Y-%m-%d %H:%M:%S"
echo "${time_log} 配置更新器启动"
pull_wait_sec=2
while true
do
wget http://192.168.11.146:8000/notice_slave.action -O notice_slave.action > /dev/null 2>&1
status=cat ./notice_slave.action
if [ ${status} -eq 1 ]
then
time_bak=date "+%Y%m%d%H%M%S"
time_log=date "+%Y-%m-%d %H:%M:%S"
echo "${time_log} 从master下载配置压缩包文件"
wget http://192.168.11.146:8000/conf.tar.gz -O conf.tar.gz
echo "${time_log} 备份原有的配置目录"
mv ./conf ./backup/conf_bak_${time_bak}
echo "${time_log} 解压下载后的配置压缩包"
tar -zxf conf.tar.gz
echo "${time_log} 热重启prometheus服务"
curl -X POST http://127.0.0.1:9090/-/reload
fi
sleep ${pull_wait_sec}
done
pull_wait_sec参数控制每隔时间工作一次,首先会从master中拉取通知文件notice_slave.action,并读取里面的结果,如果是1,则说明master上的配置文件有变化,接着会执行一系列操作。如果是0,则什么也不做。
- 创建热重启的脚本hot_restart_prometheus.sh
#!/bin/sh
curl -X POST http://127.0.0.1:9090/-/reload
日常维护中,在slave主机上,如有必要时方便手动执行热重启
- 创建汇总启动脚本start_all.sh
#!/bin/sh
nohup sh startUpdateSyncConf.sh > ./logs/update_sync.log &
sleep 3
sh ./startPrometheusSvr.sh
日常维护中,如需一次性拉起服务,执行该脚本即可
- 创建汇总停止脚本stop_all.sh
#!/bin/sh
ps -aux | grep startUpdateSyncConf.sh | grep -v grep | awk '{print $2}' | xargs kill
ps -aux | grep -v grep | grep prometheus | awk '{print $2}' | xargs kill
日常维护中,如需一次性停止服务,执行该脚本即可
四、监控mysql案例
prometheus如何监控mysql?很简单,只需要在运行mysql的主机上安装mysqld_exporter,mysqld_exporter的用途是啥?说白了它就是用来收集mysql数据库相关指标的程序(官方就有,而且是go语言写的),mysqld_exporter启动后默认监听9104端口(当然启动时可以通过相应参数进行更改),且它连接上数据库采集相应指标,并等着prometheus服务器来拉取。所以,需要在mysql中创建一个专门用于采集监控指标的数据库账号,让mysqld_exporter通过这个账号去登录数据库采集指标,且这个账号要有相关权限(合适的权限即可)。所以的合适,请自行根据实际情况决定要给什么权限,如果是生产环境,一般的原则是:最小原则、够用就好。
-
mysql测试环境信息
-
以下是笔者的mysql测试环境
数据库 操作系统 IP mysql8.0 centos7 192.168.11.150
说明:本篇只讲解如何使用Prometheus监控MySQL,MySQL本身的安装过程不在本篇范围内,请自行将MySQL安装好。
- 下载mysqld_exporter
wget https://github.com/prometheus/mysqld_exporter/releases/download/v0.14.0/mysqld_exporter-0.14.0.linux-amd64.tar.gz
- 登录mysql创建用于采集指标数据的专有账户
创建账号
mysql> create user 'exporter_user'@'localhost' identified by 'Root.123456' with max_user_connections 3;
Query OK, 0 rows affected (0.06 sec)
授权
mysql> grant process, replication client, select on *.* to 'exporter_user'@'localhost';
Query OK, 0 rows affected (0.00 sec)
刷新权限
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
查看权限
mysql> show grants for exporter_user@localhost\G;
*************************** 1. row ***************************
Grants for exporter_user@localhost: GRANT SELECT, PROCESS, REPLICATION CLIENT ON *.* TO exporter_user@localhost
1 row in set (0.00 sec)
ERROR:
No query specified
查看账号
mysql> select user,host from mysql.user;
+------------------+-----------+
| user | host |
+------------------+-----------+
| exporter | localhost | # 这个,笔者曾经创建过的,不管它了
| exporter_user | localhost | # 这个是刚刚创建好的,就用这个啦!
| mysql.infoschema | localhost |
| mysql.session | localhost |
| mysql.sys | localhost |
| root | localhost |
| ttr1 | localhost |
+------------------+-----------+
7 rows in set (0.00 sec)
mysql>
关于mysql的数据库账号权限的授权和回收的知识,笔者以后会出一个专题,专门深入浅出的剖析,敬请大家的关注!
- 部署mysqld_exporter
下载完成后,解压,并移动到规定的目录下(目录可自定义哈)
tar -zxf mysqld_exporter-0.14.0.linux-amd64.tar.gz
[root@mysql8db ~]# mkdir /usr/local/exporter/
[root@mysql8db ~]# mv mysqld_exporter-0.14.0.linux-amd64 /usr/local/exporter/mysqld_exporter
[root@mysql8db ~]# cd /usr/local/exporter/mysqld_exporter/
[root@mysql8db mysqld_exporter]# ll
total 14824
-rw-r--r-- 1 3434 3434 11357 Mar 5 00:30 LICENSE
-rwxr-xr-x 1 3434 3434 15163162 Mar 5 00:25 mysqld_exporter # 这个就是可执行程序
-rw-r--r-- 1 3434 3434 65 Mar 5 00:30 NOTICE
- 创建连接mysql的配置文件并启动mysqld_exporter
创建连接mysql的配置文件
[root@mysql8db mysqld_exporter]# cat > exporter_conn_mysql.conf < [client]
> user=exporter_user
> password=Root.123456
> EOF
查看创建好的配置文件
[root@mysql8db mysqld_exporter]# cat exporter_conn_mysql.conf
[client]
user=exporter_user
password=Root.123456
[root@mysql8db mysqld_exporter]#
- 启动mysqld_exporter
为了方便启动,创建一个启动脚本
[root@mysql8db mysqld_exporter]# cat > start_mysqld_exporter.sh < nohup ./mysqld_exporter --config.my-cnf=./exporter_conn_mysql.conf &
> EOF
[root@mysql8db mysqld_exporter]#
查看创建好的启动脚本
[root@mysql8db mysqld_exporter]# cat start_mysqld_exporter.sh
nohup ./mysqld_exporter --config.my-cnf=./exporter_conn_mysql.conf &
[root@mysql8db mysqld_exporter]#
开始启动
[root@mysql8db mysqld_exporter]# sh start_mysqld_exporter.sh
启动后查看相关端口(默认的端口为9104)
[root@mysql8db mysqld_exporter]# netstat -tulnp | grep mysql
tcp6 0 0 :::33060 :::* LISTEN 1916/mysqld
tcp6 0 0 :::3306 :::* LISTEN 1916/mysqld
tcp6 0 0 :::9104 :::* LISTEN 2073/./mysqld_expor # 这个就是啦!
[root@mysql8db mysqld_exporter]#
[root@mysql8db mysqld_exporter]#
说明:咦!–config.my-cnf这个参数我咋知道的?当然是可以使用help啦!这样 ./mysqld_exporter –help 就可以知道有哪些选项啦!
还有一个奇怪的问题,怎么只有ipv6在监听?没有IPV4?其实不是啦!centos7以上,都是ipv6优先的原则,对ipv6的支持默认是开启的,ipv4其实也是有在监听的啦!
-
启动后,通过浏览器访问指标页面
-
暴露的HTTP服务地址(http://192.168.11.150:9104/metrics)
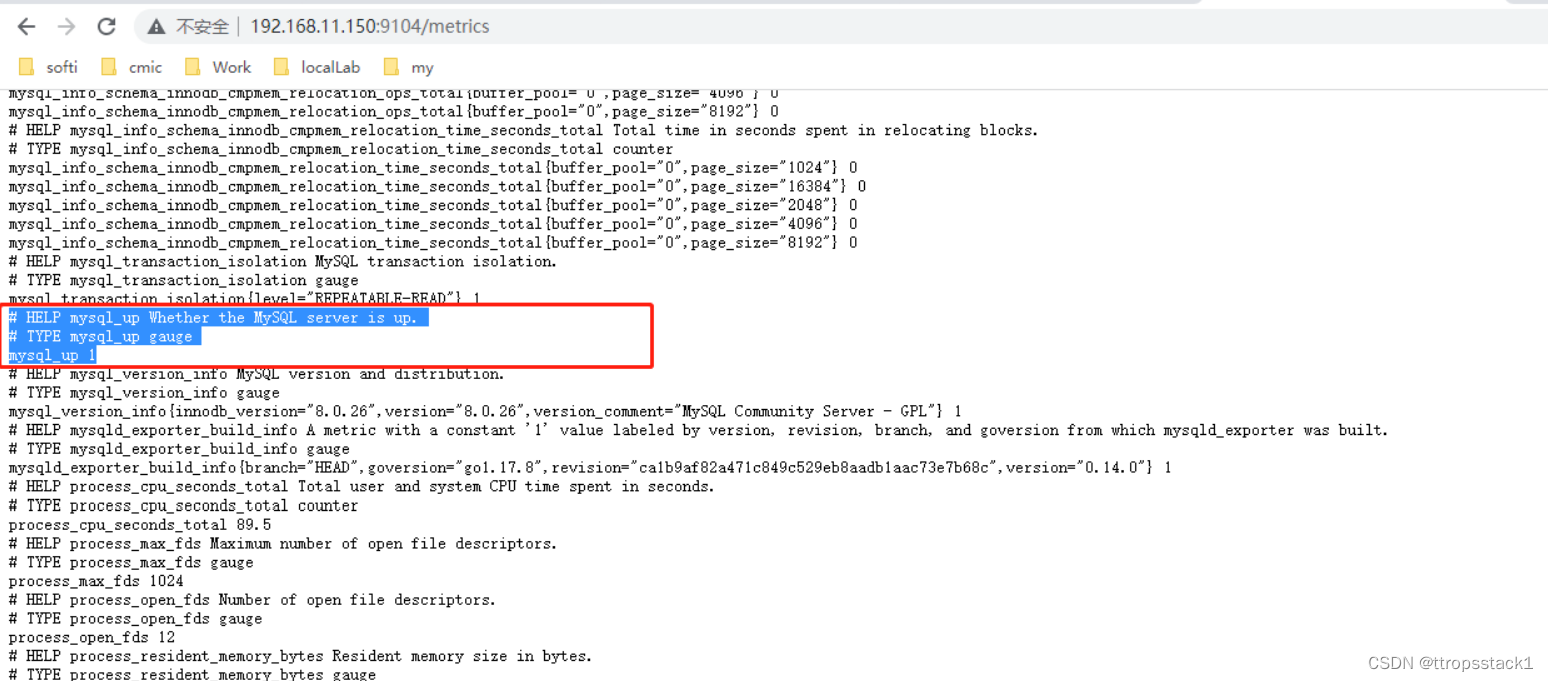
看到这些指标了吗?Prometheus服务端会周期性的从Exporter暴露的HTTP服务地址(通常是/metrics)拉取监控样本数据。
指标内容简单说明:
- HELP:用于解释当前指标的含义
- TYPE:说明当前指标的数据类型
比如下面的一个指标
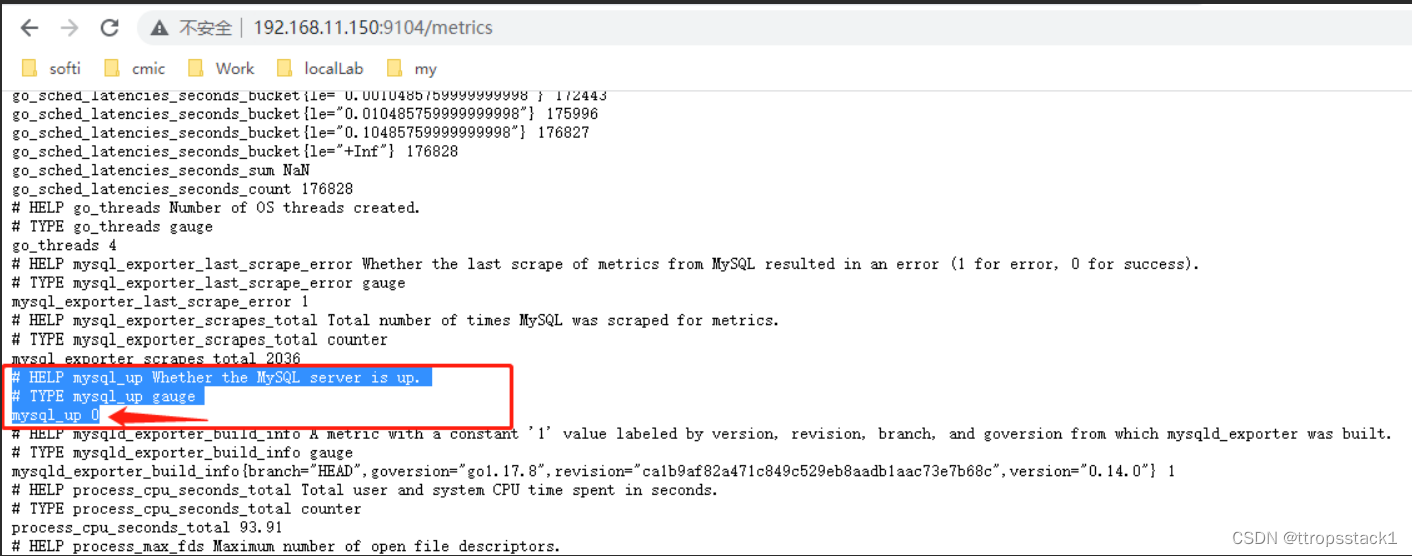
HELP mysql_up Whether the MySQL server is up. # MySQL服务器是否启动
TYPE mysql_up gauge # 指标的数据类型是gauge,测量、检测的意思,也有仪表盘的意思?
mysql_up 1 # mysql_up反应当前的状态,当前的值为1,说明是启动的,也可能为0(停止状态)
笔者去把Mysql给停止了,再次刷新指标页面,查看这个指标,发现确实变成了0
- 查看采集过程输出的相关信息
刚刚是通过nohup将mysqld_exporter程序丢入到后台启动的,所以相关的输出信息默认是会写入nohup.out文件中
[root@mysql8db mysqld_exporter]# tailf nohup.out
ts=2022-05-21T13:40:01.735Z caller=mysqld_exporter.go:277 level=info msg="Starting mysqld_exporter" version="(version=0.14.0, branch=HEAD, revision=ca1b9af82a471c849c529eb8aadb1aac73e7b68c)"
ts=2022-05-21T13:40:01.735Z caller=mysqld_exporter.go:278 level=info msg="Build context" (gogo1.17.8,userroot@401d370ca42e
...
...
到此为止,在Mysql服务器主机上部署mysqld_exporter的任务算是大功告成。
接下来回到Prometheus Master中继续以下的操作
- 在Prometheus Master中配置从mysqld_exporter收集监控数据
在Master中的prometheus主配置文件中的scrape_configs配置项添加基于文件的自动发现job
一定要注意:只需在master上做相关配置,slave主机会定时拉取master的配置目录和master保持同步,且slave的配置发生变更还会自动热重启使其生效,也就是说slave不用你操心,你只需管理好你的master就好。
再罗嗦一次: 以下操作仅在master上操作。
在主配置文件/usr/local/prometheus/conf/prometheus.yml中添加测试业务A的job
说明:下面的job_name为prometheus_server是拉取prometheus本身的指标数据(也就是监控其本身),IP地址是指向VIP:192.168.11.203,指向VIP这是建议的做法。
scrape_configs:
- job_name: 'prometheus_server'
static_configs:
- targets: ['192.168.11.203:9090']
- job_name: '测试业务A'
file_sd_configs:
- files:
- './business/test_bus_a/job/*.yml'
refresh_interval: 1s
参数说明:
- ‘测试业务A’的job_name:定义自发现的采集任务名称,按业务的维度进行定义名称,笔者这里叫”测试业务A”
- file_sd_configs:这是基于文件的自动发现,即
file_sd_configs: # 指定这是基于文件的自动发现
- files:
- './business/test_bus_a/job/*.yml' # 指定自动发现配置文件的路径,这里表示在该路径下发现所有.yml格式的配置文件
refresh_interval: 1s # 自动发现间隔,时间默认是5秒,笔者这里设置了1秒。
-
在规划好的业务目录(business)下创建对应的业务文件夹:test_bus_a,以及在业务目录test_bus_a下面创建job目录,并进入job目录创建mysql.yml(该名称可自定义,也可叫mon_mysql.yml或者其他,主要你喜欢就好!)在mysql.yml中定义拉取mysql的监控指标数据
-
./conf/business/test_bus_a/job/mysql.yml的内容如下:
- targets:
- '192.168.11.150:9104'
labels:
ip: '192.168.11.150'
monitype: 'mysql'
project: '测试业务A'
business: '测试业务A'
参数说明:
- targets:拉取目标,这里指向mysql服务器的IP地址,mysqld_exporter的端口是9104
- labels:这是标签,标签的主要作用是可以通过指定的标签查询指定的数据。
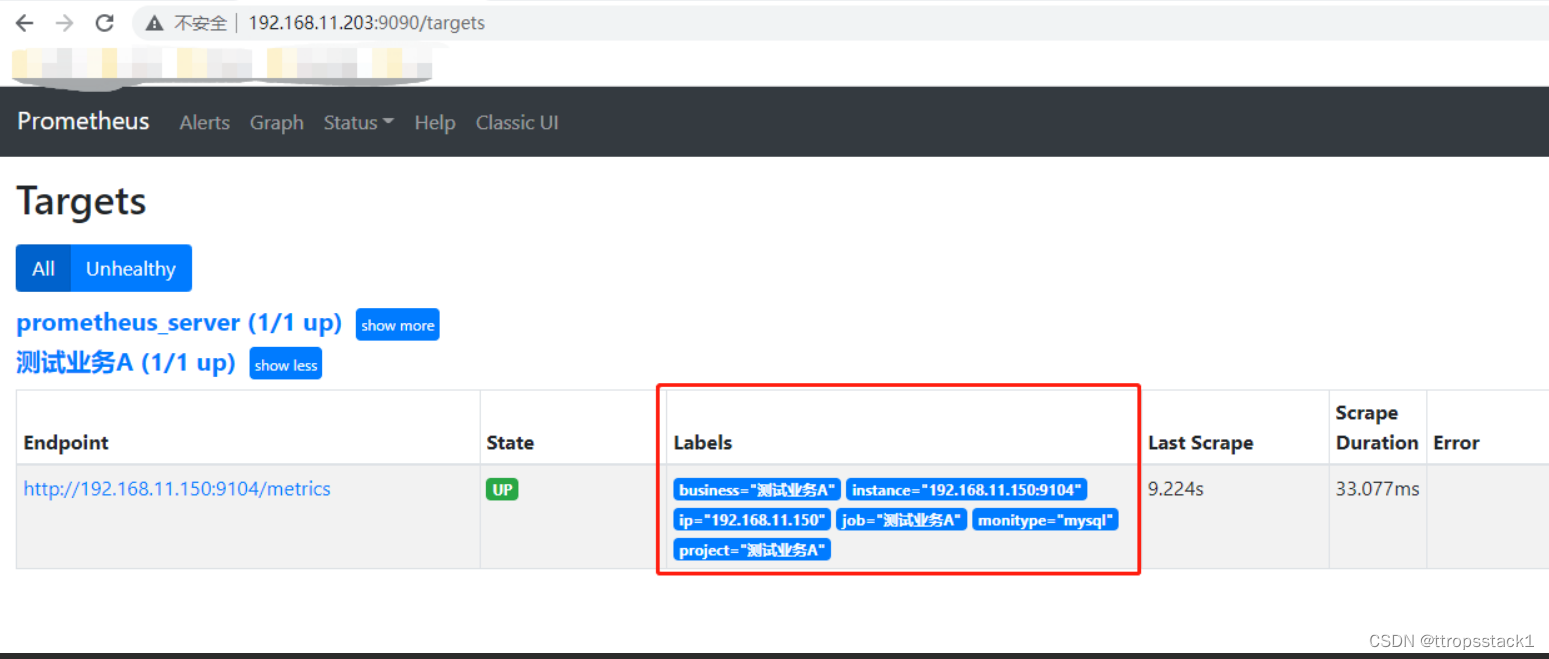
标签的作用:Prometheus中存储的数据为时间序列,是由Metric的名字和一系列的标签(键值对)唯一标识的, 不同的标签代表不同的时间序列,即通过指定标签查询指定数据。不同的标签代表不同的时间序列,即通过指定标签查询指定数据。指标+标签实现了查询条件的作用,可以指定不同的标签过滤不同的数据。
在Prometheus UI中对应的Labels信息如下图可见:
假设有个需求,需要知道被监控的mysql服务器所在的机房位置,那么就可以增加一个自定义标签,如下:
- ./conf/business/test_bus_a/job/mysql.yml
- targets:
- '192.168.11.150:9104'
labels:
ip: '192.168.11.150'
monitype: 'mysql'
project: '测试业务A'
business: '测试业务A'
region: '广州机房'
在Prometheus UI中可以看到:
- 不管你是用VIP、还是master、slave的物理IP去访问UI,结果都一样的,不信你试试。
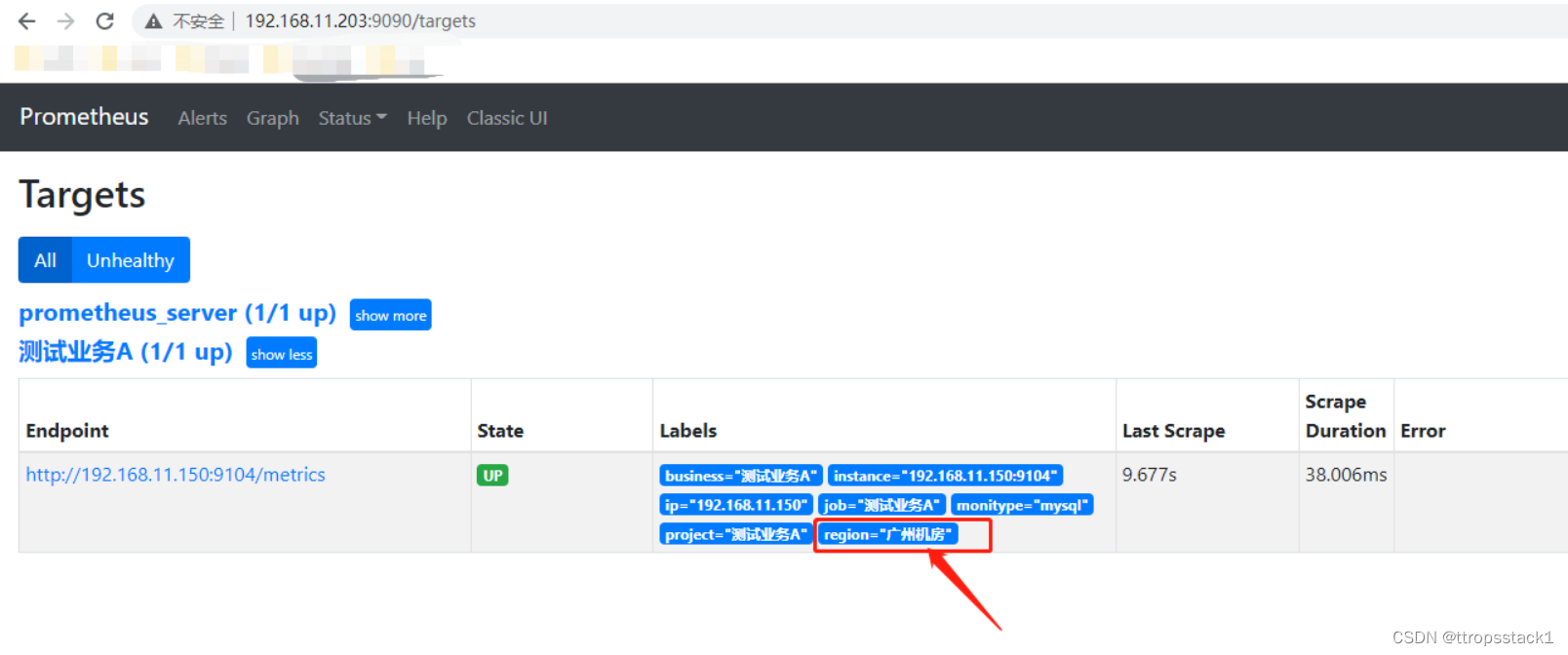
自定义标签的主要应用场景:有了这些标签可以针对特定的标签去查询,比如笔者在上面的假设需求中,需要定义一个根据自定义标签region作为标识机房位置。总而言之,添加的标签越多,查询的维度就会越细。
在UI界面中的Graph面板中使用PromQL表达式查询特定监控指标的监控数据,如下查询”mysql_up”指标,如下图:
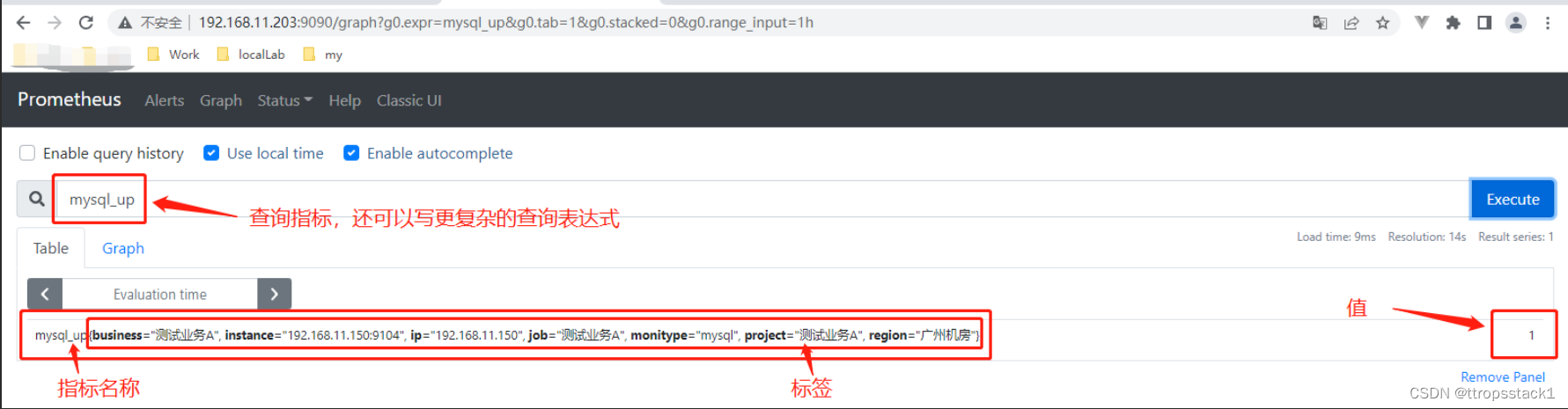
PromQL是Prometheus自定义的一套强大的数据查询语言,除了使用监控指标作为查询关键字以为,还内置了大量的函数,帮助用户进一步对时序数据进行处理。例如使用rate()函数,可以计算在单位时间内样本数据的变化情况即增长率,通过PromQL我们可以非常方便的对数据进行查询,过滤,以及聚合,计算等操作。通过这些丰富的表达式语句,监控指标不再是一个单独存在的个体,而是一个个能够表达出正式业务含义的语言。当然,关于更多的PromQL知识,以后笔者会慢慢分享,本篇的重点是主备架构,可别跑题了呢!
五、监控主机案例
为了能够采集到主机的运行指标如CPU, 内存,磁盘等信息。可以使用Node Exporter。Node Exporter同样采用Golang编写,并且不存在任何的第三方依赖,只需要下载,解压即可运行。
- 下载node_exporter并解压以及部署到指定目录
wget https://github.com/prometheus/node_exporter/releases/download/v1.3.1/node_exporter-1.3.1.linux-amd64.tar.gz
tar -zxf node_exporter-1.3.1.linux-amd64.tar.gz
mv node_exporter-1.3.1.linux-amd64 /usr/local/exporter/node_exporter
cd /usr/local/exporter/node_exporter/
- 可通过help查看一堆启动参数
[root@mysql8db node_exporter]# ./node_exporter --help
usage: node_exporter []
Flags:
-h, --help Show context-sensitive help (also try --help-long and --help-man).
--collector.bcache.priorityStats
Expose expensive priority stats.
--collector.cpu.guest Enables metric node_cpu_guest_seconds_total
--collector.cpu.info Enables metric cpu_info
...
...
- 启动node_exporter
丢入后台运行
[root@mysql8db node_exporter]# nohup ./node_exporter &
查看监听的端口
[root@mysql8db node_exporter]# netstat -tulnp | grep node_exporte
tcp6 0 0 :::9100 :::* LISTEN 1935/./node_exporte
[root@mysql8db node_exporter]#
通过nohup丢入后台运行,相关的输出会追加到nohup.out文件中,必要时可查看该文件诊断相关问题
[root@mysql8db node_exporter]# tailf nohup.out
ts=2022-06-04T00:45:58.822Z caller=node_exporter.go:115 level=info collector=thermal_zone
ts=2022-06-04T00:45:58.822Z caller=node_exporter.go:115 level=info collector=time
ts=2022-06-04T00:45:58.822Z caller=node_exporter.go:115 level=info collector=timex
ts=2022-06-04T00:45:58.822Z caller=node_exporter.go:115 level=info collector=udp_queues
...
...
笔者没啥特殊的需求,所以无需额外在给定启动参数,直接丢入后台运行即可,默认的监听端口是9100
- 通过浏览器查看node_exporter暴露的指标
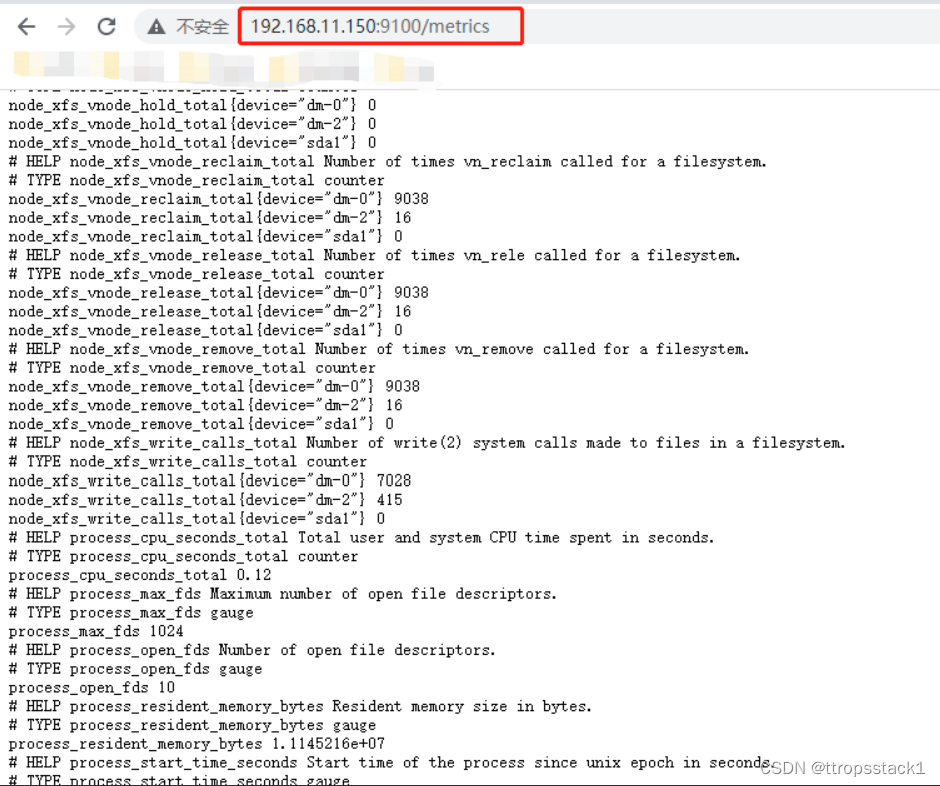
- 在prometheus的master服务器中配置从node_exporter收集监控数据
假设笔者的这台主机是测试业务b(test_bus_b)的一台主机,请按照之前的业务目录规范,在规范的业务目录(conf/business)下创建业务文件夹test_bus_b。
再次罗嗦一次:仅需在master上做配置即可,slave会定时拉取masetr的配置目录,不要去管slave,OK?一个大男人那么罗嗦,真的很惹人讨厌啊!
在主配置文件中添加业务B的job
- 主配置文件:/usr/local/prometheus/conf/prometheus.yml
scrape_configs:
- job_name: 'prometheus_server'
static_configs:
- targets: ['192.168.11.203:9090']
- job_name: '测试业务A'
file_sd_configs:
- files:
- './business/test_bus_a/job/*.yml'
refresh_interval: 1s
- job_name: '测试业务B' # 这是新增加的测试业务B
file_sd_configs:
- files:
- './business/test_bus_b/job/*.yml'
refresh_interval: 1s
在规范的业务目录(conf/business)下创建业务文件夹test_bus_b,然后创建host.yml,增加targets(拉取目标)的配置
[root@prosvr-master business]# cd /usr/local/prometheus/conf/business/
[root@prosvr-master business]# mkdir test_bus_b
[root@prosvr-master business]# cd test_bus_b/
[root@prosvr-master business]# mkdir job
[root@prosvr-master business]# cd job/
[root@prosvr-master job]# cat host.yml
- targets:
- '192.168.11.150:9100'
labels:
ip: '192.168.11.150'
monitype: 'linux-centos7'
project: '测试业务B'
business: '测试业务B'
region: '深圳机房'
在Prometheus UI中查看新增的测试业务B
- 不管你是用VIP、还是master、slave的物理IP去访问UI,结果都一样的,不信你试试。
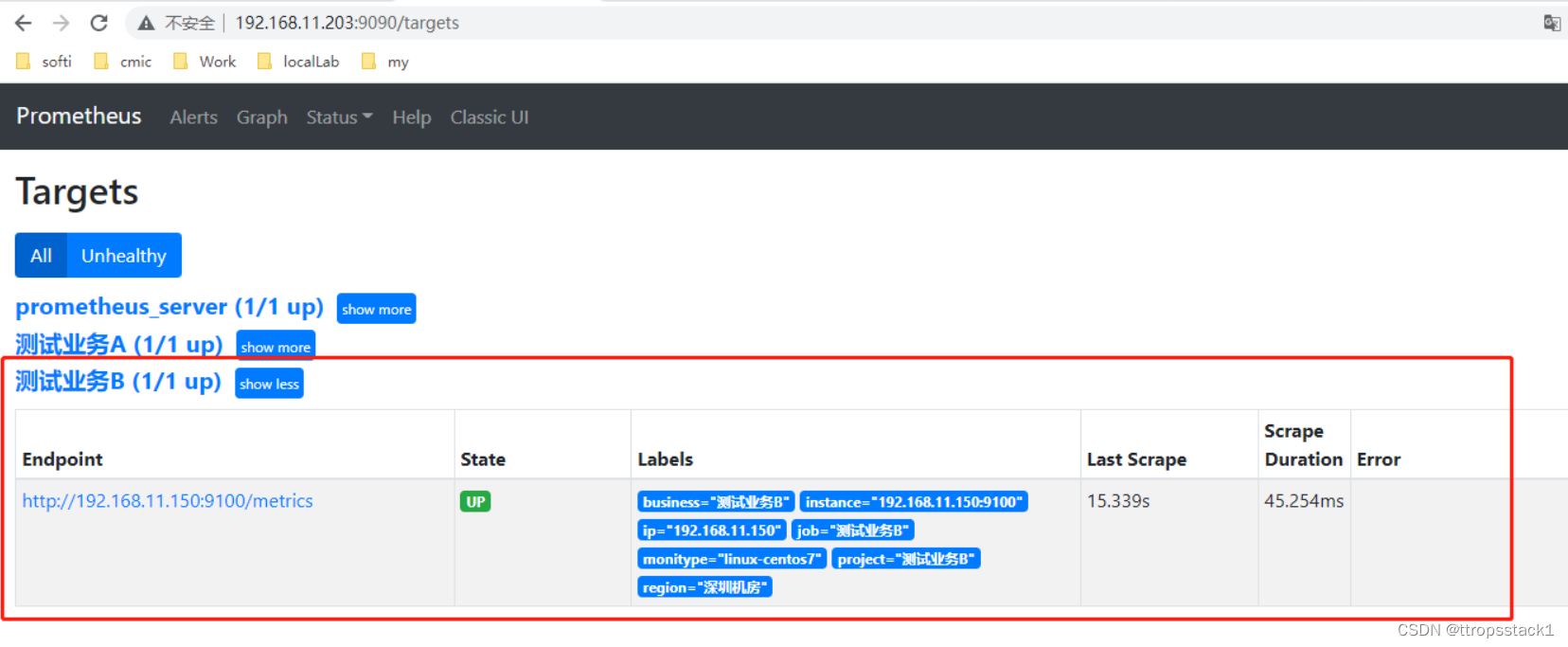
非常不错,只要检测到配置文件发生变化,master会自动热重启,slave也会自动拉取配置目录然后热重启,非常的省心、省力。自我感觉这个DIY的主备方案几乎接近完美,虽然没有用很高大上的语言、工具去实现,但笔者的这个思路自我感觉是非常的不错,这难道就是传说中的自我感觉良好?当然,笔者以后会通过Go或者Python打造一个管理Promtheus主备的工具,且是带UI的管理工具,敬请期待推出!我不造车,我只造零件。
六、AlertManager警报组件配置
说明:基于二进制包的alertmanager组件请自行在master和slave中安装部署到规范的目录,之后继续下面的步骤。
-
移动master和slave上的警报组件的主配置文件alertmanager.yml
-
在master和slave服务器上,alertmanager组件的二进制包解压到规范的目录后,将警报的主配置文件”alertmanager.yml”移动到prometheus组件的conf目录下
移动后(也就是用mv命令移动),查看如下:
[root@prosvr-master conf]# pwd
/usr/local/prometheus/conf
[root@prosvr-master conf]# ll
total 12
-rw-r--r-- 1 3434 3434 348 Jun 4 13:26 alertmanager.yml # 警报组件的主配置文件已经也在prometheus组件下的conf目录
drwxr-xr-x 4 root root 42 Jun 4 09:18 business
-rw-r--r-- 1 3434 3434 1033 Jun 4 12:27 prometheus.yml
[root@prosvr-master conf]#
特别注意:上述操作,在master和slave上都要操作,且在slave服务器移动alertmanager.yml配置文件后,往后就可以不用去管slave上的alertmanager.yml配置文件了,主要的配置变更都在master上进行就好,如果有变更,slave会自动拉取配置目录。通常警报组件的alertmanager.yml配置文件一旦配置好后,改动的频率比较少。
特别说明:之所以这么设计,有两个好处:1)配置的变更都在同一个目录下进行;2)利用了现有master和slave的配置目录同步能力
-
在master上配置警报的主配置文件/usr/local/prometheus/conf/alertmanager.yml
-
在警报组件中配置告警消息发往的接口地址, 让其可以调用接口,配置方式很简单,只需要指定一下接口地址即可
global:
resolve_timeout: 5m
route:
group_by: [...]
group_wait: 1s
group_interval: 1s
repeat_interval: 1000d
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:5001/webhook'
send_resolved: true
上述配置中,主要包含两大部分,路由(route)和接收器(receivers),所有的告警信息都会从配置中的顶级路由(route)进入路由树,根据路由规则将告警信息发送给相应的接收器。本篇主要是配置接收器,使用webhook的方式,假设是将告警消息推送到第三方平台。当然,在本篇仅为示例,打印出来而已。
-
在master和slave上创建Alertmanager组件启动脚本
-
注意:该步骤一定要进入到/usr/local/alertmanager/目录下进行操作
- 创建脚本,名称:startAlertManagerSvr.sh
#!/bin/sh
nohup ./alertmanager --config.file=/usr/local/prometheus/conf/alertmanager.yml >> ./logs/alert.log &
[root@prosvr-master alertmanager]#
注意:startAlertManagerSvr.sh脚本在masetr和slave中都要创建,且–config.file使用绝对路径指向alertmanager.yml
通过该脚本拉起alertmanager组件
sh startAlertManagerSvr.sh
注意:master和slave都要拉起
启动后,通过VIP或master和slave的物理IP都可以访问到警报的页面,笔者这里是使用VIP进行访问,如下图:
在这里插入图片描述
- 关联Prometheus与Alertmanager
注意:仅在master上配置即可,因为slave会从master上拉取
- /usr/local/prometheus/conf/prometheus.yml
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.11.203:9093
笔者这里通过VIP跟Alertmanager组件通信,当prometheus中的警报规则触发了告警后,告警消息就会发送到警报组件监听的9093端口,由alertmanager组件进行处理
- 配置警报规则文件的自动发现
注意:仅在master上配置即可
- /usr/local/prometheus/conf/prometheus.yml
rule_files:
- "./business/test_bus_a/rule/*.rules"
- "./business/test_bus_b/rule/*.rules"
- 配置mysql的警报规则,当mysql挂掉后,使其触发警报
注意:仅在master上配置即可
- /usr/local/prometheus/conf/business/test_bus_a/rule/mysql.rules
groups:
- name: mysql-alert
rules:
- alert: "MysqlDown"
expr: mysql_up{job="测试业务A"}==0
for: 1m
labels:
annotations:
summary: "MySQL数据库服务:{{ $labels.ip }}发生停止告警"
description: "测试业务A的环境MySQL数据库服务:{{ $labels.ip }}已停止,当前UP状态值为:{{ $value }},已触发告警条件:mysql_up = 0,持续时间:1m。"
alertLevel: 5
上面的案例很简单,expr是表达式,该表达式是说:如果mysql_up指标的值等于0那么就触发该警报
可以通过promtool工具检查警报规则配置文件是否有误
[root@prosvr-master prometheus]# ./promtool check rules ./conf/business/test_bus_a/rule/mysql.rules
Checking ./conf/business/test_bus_a/rule/mysql.rules
SUCCESS: 1 rules found
配置文件发生了变更后,master会自动热重启,slave会自动拉取配置并热重启,直接在UI界面上可以查看到该规则
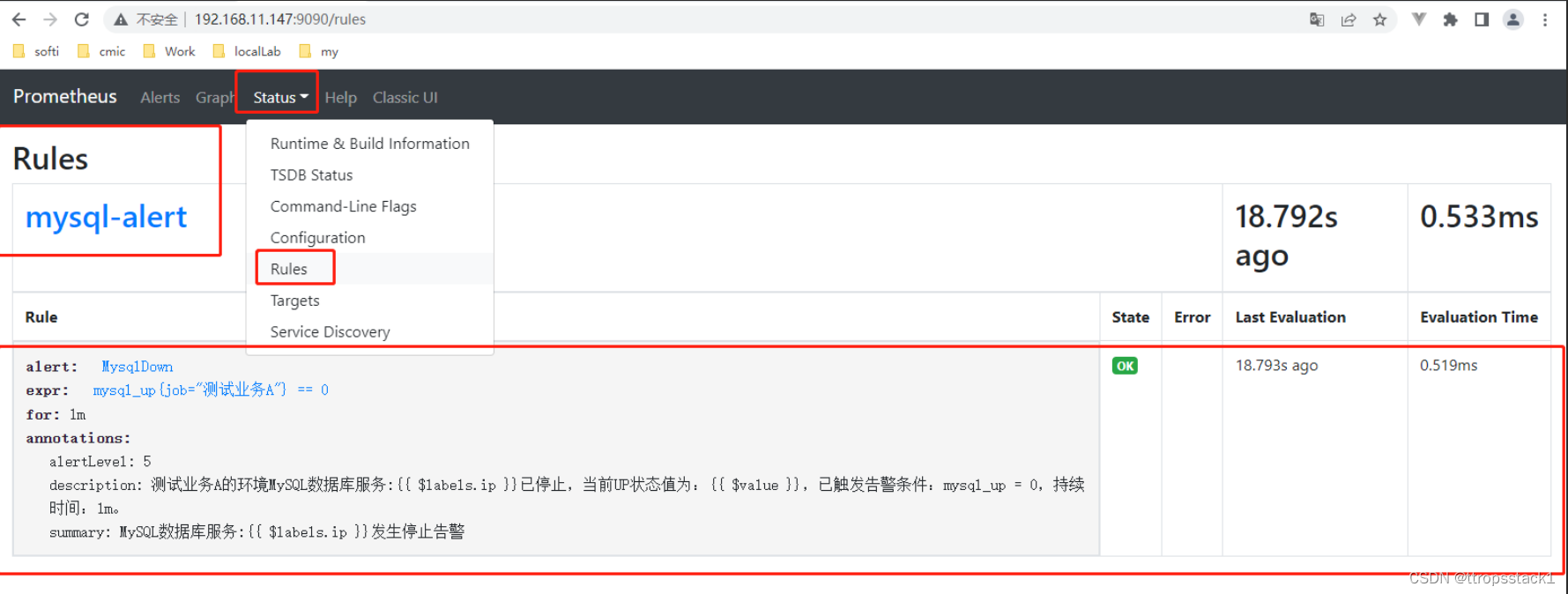
- 笔者在这里假设用python编写了一个最简单的webhook接口,让其可以接收来自alertmanager的警报消息,然后打印出来
特别说明:只需在master上编写的webhook接口脚本,并且也放在规范的conf目录下:/usr/local/prometheus/conf/webhook.py,该API脚本会被slave拉取到
- webhook.py简单的API代码如下:
import json
from flask import Flask, request
app = Flask(__name__)
@app.route('/webhook', methods=['POST'])
def webhook():
data = json.loads(request.data)
print(data)
if __name__ == '__main__':
app.run('0.0.0.0', 5001)
特别说明1:此示例API只是演示使用,请根据实际情况编写相关代码,本实例仅仅只是打印出来,并没有将告警推送到其他平台,如钉钉、邮件、或其他告警收敛平台。
特别说明2:如果您也想在您的测试环境将笔者的这个webhook.py跑起来,请自行安装python的flask库,笔者不在本篇讲解python的相关知识。python编程笔者后续会专门抽时间作为专题给大家分享,敬请您的关注。
- 创建webhook API的启动脚本
说明:在master和slave都要创建startWebHook.sh脚本
#!/bin/sh
nohup python ./conf/webhook.py >> ./logs/webhook.log &
- 仅在master上启动webhook API
[root@prosvr-master prometheus]# sh startWebHook.sh
特别注意:千万不要在slave上启动webhook API,具体原因在本篇的最前面已经有过解释(避免告警重复推送),只有当master不可用了,slave才拉起webhook API脚本进行承担告警推送的任务。
-
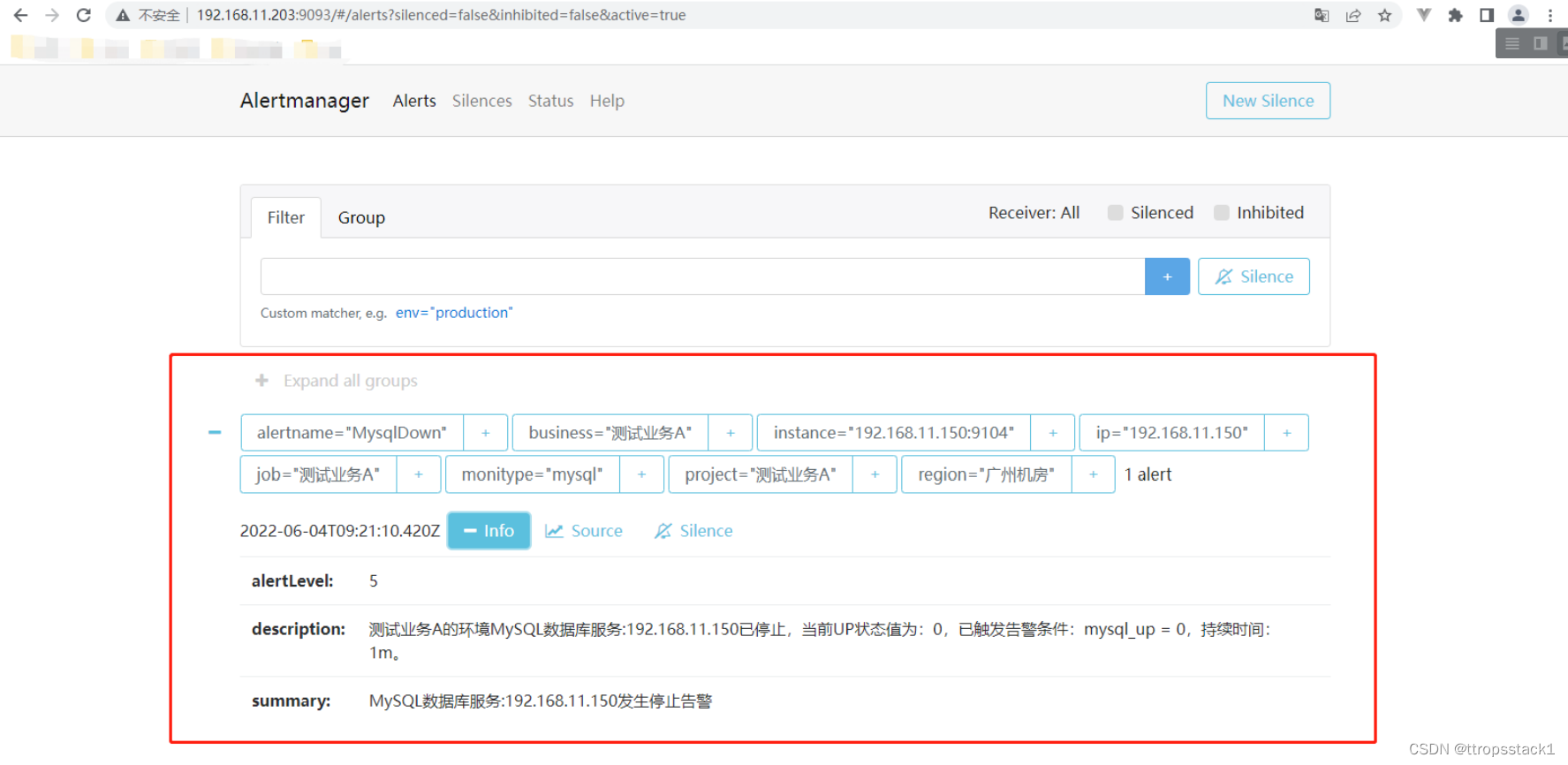
模拟mysql故障,验证告警是否可以正常触发,验证由webhook是否可以正常接收
-
在master上用tailf命令实时监测./logs/webhook.log
[root@prosvr-master prometheus]# tailf ./logs/webhook.log
* Serving Flask app "webhook" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://0.0.0.0:5001/ (Press CTRL+C to quit)
登录Mysql主机,停掉mysql
[root@mysql8db ~]# cat stop_mysql.sh
#!/bin/bash
/usr/local/mysql8/bin/mysqladmin -S /usr/local/mysql8/mysql.sock -uroot -pRoot.123456 shutdown
[root@mysql8db ~]#
[root@mysql8db ~]# sh stop_mysql.sh
mysqladmin: [Warning] Using a password on the command line interface can be insecure.
[root@mysql8db ~]#
没过多久,webhook api就接收到了告警消息

同样,在Alertmanager告警页面中,也能看到告警消息
写在最后
到目前为止,该DIY的prometheus主备方案的全程搭建过程就已经完结了,期间涉及到很多知识点都还没有去深入的剖析,比如:PromQL,Metric类型,告警的分组、抑制、静默等等知识点。本篇的核心主题是把这个DIY的方案给搞起来,后续笔者会逐一分享更多关于prometheus的技能点,敬请大家的关注。谢谢!感谢您的关注,望多多转发、点赞。谢谢!
Original: https://www.cnblogs.com/ttropsstack/p/16462256.html
Author: 不背锅运维
Title: 全网唯一的、DIY的Prometheus高可用方案,生产未上,测试先行。
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/582316/
转载文章受原作者版权保护。转载请注明原作者出处!