

1.为什么需要分片集群?它解决了什么问题?
Redis从单个节点的架构方式演变到主从模式,提高了数据的可靠性以及相对较弱的高可用性;从主从模式到哨兵模式将高可用性提升到了一个新的高地。但是无论是主从还是哨兵模式下的集群,其实都是单个节点在处理客户端的命令,也即是说主节点拥有着所有的数据。那么如果数据量太大就必然会导致内存的暴增。内存较大的情况下,如果对主节点执行RDB全量快照就会使用fork操作,而在fork操作的时候拷贝父线程的内存页就会耗费较长的时间,从而导致父线程被阻塞。此外主节点在并发较高的情况下很容易就会因为网络IO的瓶颈而导致客户端接受较慢【Redis通常不会在CPU上成为性能瓶颈】。
要解决内存和网络IO的问题有两种比较通用的方式:纵向拓展以及横向拓展。纵向拓展意味着提升机器的硬件,如:增加内存条以及配置更高的网卡,但是这通过硬件解决是需要比较高的成本的,而且仍然能是无法解决fork操作导致主线程阻塞的问题。横向拓展指的是将数据量按照一定的分配规则分配到多个主节点中进行处理,一方面每个主节点的内存相对较小,并且可以分担各自的网络IO。这种横向拓展的方式就是Redis-Cluster也叫作分片集群。
2.如何加入或退出一个集群?
MEET消息【加入集群】:向一个节点node发送CLUSTER MEET命令,可以让node节点与ip和port所指定的节点进行握手(handshake),当握手成功时,node节点就会将ip和port所指定的节点添加到node节点当前所在的集群中(集群合并)。然后该节点通过Gossip协议将当前节点注册到集群中的其他节点上,最终形成一个完全连接图。
FORGET消息【退出集群】:向集群中的每个主节点执行CLUSTER FORGET命令,当节点接收到该命令后,会把nodeId指定的节点加入到禁用列表中,在禁用列表内的节点不再发送Gossip消息。禁用列表有效期是60秒,超过60秒节点会再次参与消息交换。(在节点下线之前必须先将节点所负责的所有槽分配到其他主节点)
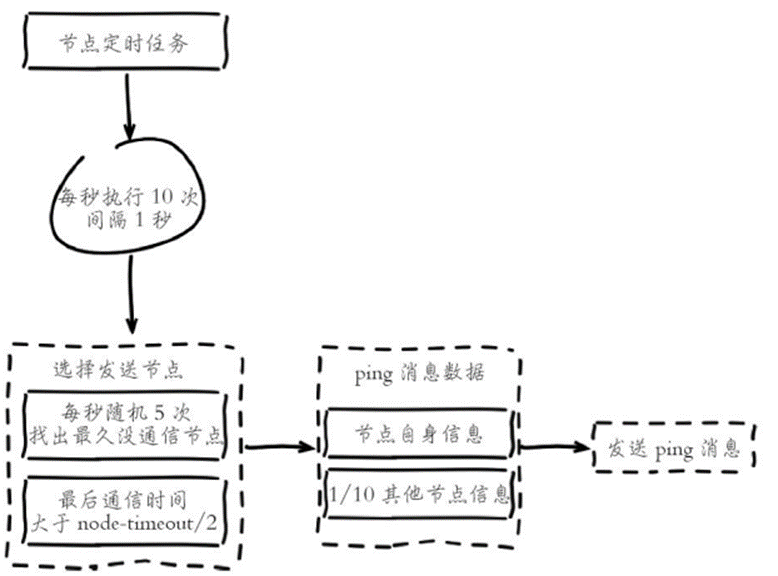
3.分片集群内部如何进行通信保持数据的一致性【Gossip】?
Gossip协议工作原理就是节点彼此不断通信交换信息,一段时间后所有的节点都会知道集群完整的信息,这种方式类似流言传播,本质上是最终一致性协议。Gossip消息内容可分为:
ping消息:封装自身节点和部分其他节点的状态数据,用于检测节点是否在线并交互彼此状态数据;
pong消息:响应ping/meet消息,封装自己的节点状态数据(心跳检测);
meet消息:用于通知新节点加入,加入后进行周期性的ping/pong消息交互;
fail消息:当节点判定集群内另一个节点下线时,会向集群内广播一个fail消息,其他节点接收到fail消息之后把对应节点更新为下线状态。

集群的整个数据库被分为16384个槽,数据库中的每个键都分布在这些槽中的其中一个,集群内的每个主节点可以负责处理0到16384个任意槽数。如果有一到任意多个槽没有被指派给主节点,此时集群处于下线(fail)状态,无法处理任何客户端的命令。在主节点上通过cluster addslots命令可以指派任意个槽给当前的主节点;
Redis采用的是CRC16算法做hash取模,从而可以在O(1)的时间内可以快速定位任意的key到哪个槽。而如果不采用hash的方式实现而采用表或是内存的话,主要还是维护成本的问题。这个成本主要体现在:1.数据量大,内存耗费较高;2.如果是基于单个表的话就有并发安全的消耗,如果是各自维护的话,内存成本也会上去。
Redis采用CRC16算法做hash得到的结果是一个16位的结果,理论上来说可以支持最大的槽数应该是2^16[65536]个。但是如果按照最大的取值来进行计算的话,那么当集群每个节点进行通信的时候,由于每个节点需要把自己所负责的槽告诉其他节点。假设最大的槽数是2^16,那么在内存中记录就需要消耗8KB的内存,那么每次PING和PONG消息就仅仅只是传播自己的槽分配信息就需要8KB的内存,那这个代价就比较大了,难以忍受,因为PING/PONG消息还有节点当前的状态节点个数等其他信息需要携带同步给其他节点。另外,从另一个角度看如果Redis的主节点越多,那么PING/PONG的消息体就越大,就会很容易导致网络拥塞,这也是为什么Redis作者不建议redis cluster节点数量超过1000个,对于1000个节点的集群16384个槽本身也是足够使用的。所以在综合考虑的情况下作者将8K(65536)个槽改为了2K(16384)个槽。
Redis提供了hashtag的方式可以将带有该标签的key强制分配到同一个槽,从而保证带有该标签的所有key分布在同一个节点中,从而可以使用事务或管道等机制完成某些业务操作。带有hashtag的key的样式为:”keyname{tagname}”,这里的”{tagname}”就是hashtag,Redis在进行CRC16计算的时候只会通过tagname计算而忽略keyname,所以计算出的结果就能保证带hashtag的所有计算结果是一致的。但是如果滥用hashtag的话就很容易导致某些槽的数据量比较大,容易造成数据的倾斜。
5.如果在一个主节点上直接执行一个命令会发生什么?
在集群模式下,Redis接收到任何键相关的命令时首先计算键对应的槽,再根据槽找出该槽所对应的主节点,如果节点是自身,则处理该命令。否则会回复MOVED重定向错误,通知客户端将改键的请求在MOVED错误中指定的节点执行。Redis-cli客户端在捕获到MOVED错误时,会再次将该命令转发,即再次向MOVED错误中的指定的节点发起请求。所以现在Redis的客户端一般都会将该错捕获,然后在向正确的节点发送命令,这个过程类似于重定向。
6.Redis分片集群中主节点的高可用实现
Redis分片集群主节点的高可用也是通过主从架构的方式来进行实现的。在节点上执行cluster replication
Redis集群内节点通过ping/pong消息实现节点通信,消息不但可以传播节点槽信息,还可以传播其他状态如:主从状态节点故障等。因此故障发现也是通过消息传播机制实现的,主要环节包括: 主观下线(pfail)和客观下线(fail)。
主观下线:一个节点向节点X发送PING消息,在规定的时间内未获得PONG消息,则会认为节点X可能已下线(PFAIL),此时会向其他节点发送PING消息时,表明节点X已下线,其他节点会再次向节点X发送PING消息再次确认其状态。
客观下线:如果半数以上负责处理槽的主节点认为同一个节点可能下线,此时该节点就会被标记为已下线(FALI),并将该节点客观下线的消息进行广播。
当从节点接收到主节点客观下线的消息后,就会开始对主节点进行故障转移。步骤如下:
1.从节点选举:从节点向集群广播CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUES消息,当负责处理槽的主节点接受到该消息后会对其进行纪元内先到先得的一票选择,从节点收到过半数的票时就会成为新的主节点。选举过程与哨兵模式下的Leader选举类似。
2.从节点晋升为主节点:从节点执行slaveof on one,从而晋升为新的主节点
3.槽指派修改:新主节点会撤销旧主节点所负责的槽指派,并将槽指派为自己
4.广播故障转移完成:新主节点向集群广播PONG消息,告诉其他节点集群的最新状态,表示故障转移已完成
5.集群恢复:新主节点接收来自客户端的相关命令处理。旧主节点的所有从节点重新变更为新主节点的从节点
注意:当主节点客关下线时,默认情况下集群状态在完成故障转移前会变为不可用状态,可以修改cluster-require-full-coverage=no来避免影响其他主节点
7.集群的扩缩容,以及数据迁移
由于Redis中所有的数据都是以槽为单位进行控制,所以Redis-Cluster中的数据迁移本质上就是槽被分配到哪个节点进行处理,Reids-Cluster的集群伸缩等于槽和数据在主节点之间的移动。
槽与主节点的关系的变更主要发生在三个时机: 1.新主节点加入集群且为其分配槽(扩容);2.主节点从集群中下线(包括该主节点下的所有从节点,缩容);3.从节点晋升为主节点(故障转移)。
槽和数据的迁移过程:
1.对目标节点发送cluster setslot {slot} importing {sourceNodeId} 命令,让目标节点准备导入槽的数据。
2.对源节点发送cluster setslot {slot} migrating {targetNodeId} 命令,让源节点准备迁出槽的数据。
3.源节点循环执行cluster getkeysinslot {slot} {count} 命令,获取count个属于槽{slot}的键。
4.在源节点上执行migrate {targetIp} {targetPort} “” 0 {timeout} keys {keys…} 命令,把获取的键通过流水线机制批量迁移到目标节点。
5.重复执行步骤3)和步骤4)直到槽下所有的键值数据迁移到目标节点。
6.向集群内所有主节点发送cluster setslot {slot} node {targetNodeId}命令,通知槽分配给目标节点。
备注:另外如果需要对集群中的任意部分的槽进行进行重新指派,即:重新分片。可以使用在线的方式进行,在重新分片的过程中,集群不需要下线,并且源节点和目标节点都可以继续处理命令请求。
8.如果客户端访问的key所在的槽正处于迁移状态,会不会发生阻塞?
当客户端向源节点发送一个与数据库键有关的命令,并且命令要处理的数据库键恰好就属于正在被迁移的槽时。源节点会现在自己的库里查找指定键,健存在则直接执行命令;不存在则说明这个键可能已经被迁移到目标节点,此时源节点会向客户端返回一个ASK错误,指引客户端转向正在导入槽的目标节点,并先发送一个ASKING命令,再次发送之前想要执行的命令。所以并不会导致主节点或客户端的阻塞,而是会与客户端接收到MOVED指令类似发生重定向来完成命令的执行。
参考资料
1.极客时间专栏课-redis核心技术与实战
2.<
3.<
4.<
Original: https://www.cnblogs.com/zhenjungan/p/16527075.html
Author: zhenjungan
Title: Redis集群-Cluster模式
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/581872/
转载文章受原作者版权保护。转载请注明原作者出处!