

1 优化算法
https://tangshusen.me/Dive-into-DL-PyTorch/#/chapter07_optimization/7.4_momentum
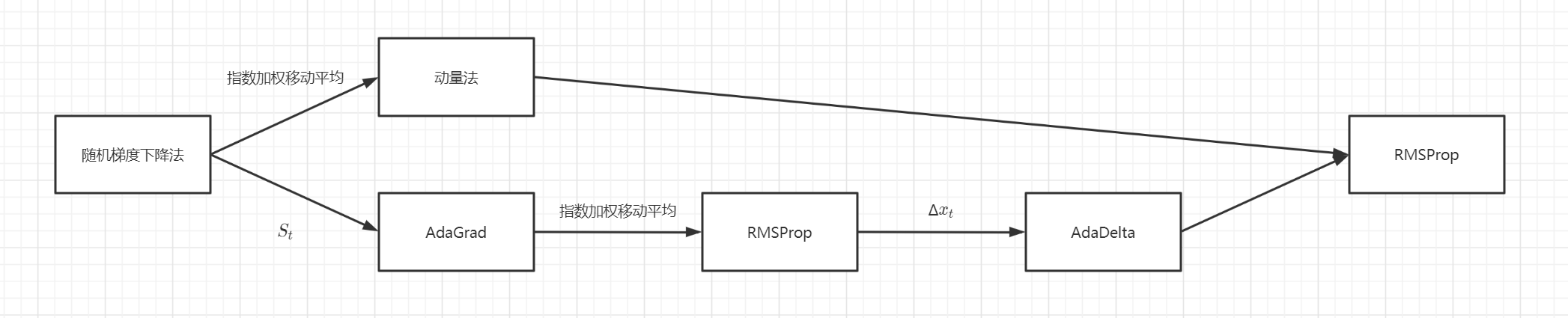
1.1 动量法
动量法是梯度下降法的改进。梯度下降法的自变量的迭代方向仅仅取决于自变量当前位置,这会带来问题。
动量法对之前 1 / (1 − γ)个时间步进行利用指数加权移动平均,使得自变量的更新方向更加一致,从而降低发散的可能。
1.2 AdaGrad算法
AdaGrad 同样是梯度下降法的改进。梯度下降法中目标函数自变量的每一个元素在相同时间步都使用同一个学习率来自我迭代,当存在梯度值相差较大的元素存在问题。
AdaGrad 通过维护 S t 变量对学习率 _η_进行调整,实现根据不同元素应用不同的学习率。具体作用表现为:如果目标函数有关自变量中某个元素的偏导数一直都较大,那么该元素的学习率将下降较快;反之,如果目标函数有关自变量中某个元素的偏导数一直都较小,那么该元素的学习率将下降较慢。
AdaGrad 存在缺点,由于 S t 一直在累加按元素平方的梯度,自变量中每个元素的学习率在迭代过程中一直在降低(或不变)。所以,当学习率在迭代早期降得较快且当前解依然不佳时,AdaGrad 算法在迭代后期由于学习率过小,可能较难找到一个有用的解。
1.3 RMSProp算法
RMSProp 是 AdaGrad 的改进。如上文所言,当学习率在迭代早期降得较快且当前解依然不佳时,AdaGrad算法在迭代后期由于学习率过小,AdaGrad 可能较难找到一个有用的解。
RMSProp 利用动量法中的指数加权移动平均思想对 AdaGrad 中维护的 S t 变量做指数加权移动平均,其可以看作是最近 1 / (1 − γ)个时间步的小批量随机梯度平方项的加权平均。如此一来,自变量每个元素的学习率在迭代过程中就不再一直降低(或不变)。
1.4 AdaDelta算法
AdaDelta 是 RMSProp 的改进。RMSProp 需要设定超参数学习率,AdaDelta 不需要。
AdaDelta 维护一个 Δx t 变量,代表有关自变量更新量平方的指数加权移动平均的项,使其代替学习率。
1.5 Adam算法
Adam 是 RMSProp 算法与动量法的结合。
Adam 可以看作是在 RMSProp 算法的基础上对 1 / (1 − γ) 个时间步内的小批量随机梯度也做了指数加权移动平均。
2 优化算法之间的关系

Original: https://www.cnblogs.com/tangzj/p/15602722.html
Author: MoSalah
Title: 优化算法之间的关系及各自特点的简单分析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/576693/
转载文章受原作者版权保护。转载请注明原作者出处!