

最近这段时间开始了一个新项目,项目使用rabbitMQ存储采集数据,通过storm对rabbitMQ中的数据进行实时计算,将结果存入到rabbitMQ的另一个队列中,再由另外一个storm服务将结果保存到elasticsearch中进行存储,以此实现大数据的实时计算存储。
在项目首次部署阶段,一切正常。在storm服务部署完成并启动后,开启采集服务,成功实现了数据的实时计算与存储。设置的单批次最大消费数为10000,rabbit的incoming与diliver为400-500/s。运行结果一切正常,没有出现数据丢失或数据积压的情况。
然而好景不长,没过几天后的一次更新,将storm服务kill掉重启后,rabbit的数据在重启过程中有了一定量的堆积,此时重启storm后出现了OOM异常。


WHAT???为啥之前本地测试积压了十几万条数据,每秒1000-1200条数据都能成功消费,而生产不过每秒400-500条的数据却出现了OOM内存不足的情况呢?

错误复现
首先在本地模拟数据,模拟数据总计20000条,存入rabbitMQ中。

为了测试数据堆积场景下的数据消费情况,分别开启Storm服务,对rabbit数据进行计算与存储。
第一阶段:数据的实时计算

第二阶段:数据的存储

可以看到storm的数据是能够成功计算与存储的。即使出现积压也没有出现数据丢失或OOM异常。
此刻, 模拟数据总计条数不变,将每条消息的大小扩大为以前的10倍左右
原数据大小:

修改后的数据大小:

重新开启storm服务
第一阶段:


第二阶段:

可以看到数据出现了很明显的丢失情况,后台日志也打印出了OOM异常

问题分析
Storm对每个Topology默认的大小分配是768M,在生产环境,数据通过analyse服务时没超过这个内存阈值,所以当时analyse服务在生产没有出现OOM异常,而通过计算处理后放入另外一个队列中的数据,单批次数据的大小超过了内存大小阈值,所以在save服务出现了OOM异常。
在测试条件下,saveTopology的内存占用就已经超过了768M,所以在analyse服务下也出现了OOM异常,
到了Save服务下甚至只有600条不到数据成功写入ES。
问题解决
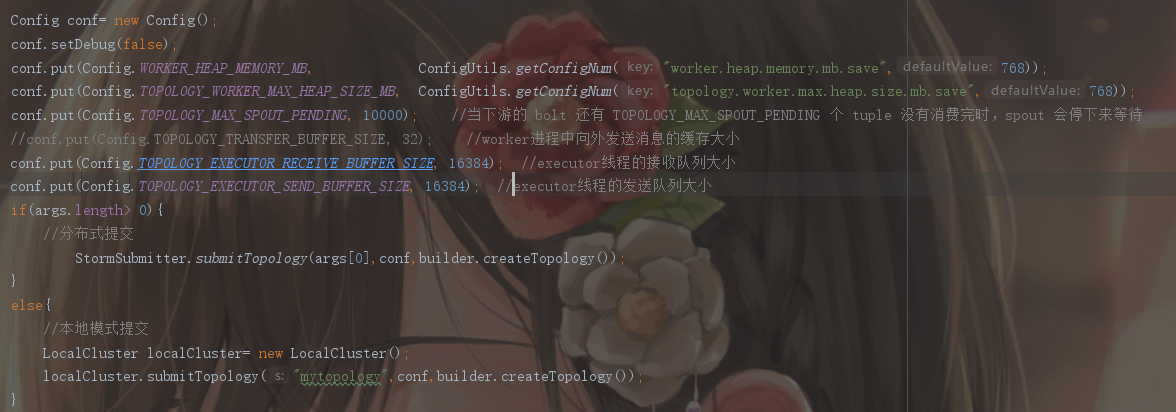
在项目中,添加配置
worker.heap.memory.mb
topology.worker.max.heap.size.mb
配置从Zookeeper中读取,不同的环境下配置不同的内存大小。

Assigned Mem(MB) 为配置的内存大小(默认条件下是768M)+LogWriter的64M

此时再重新进行数据模拟及积压数据的计算与存储
第一阶段

第二阶段

可以看到这次不再出现OOM异常,数据成功进行了计算与存储。
总结
在一般流式计算的场景下,数据进入队列立刻被消费时,很多问题不会出现。但这并不代表系统就是没有问题的。在某个时间点,突然有大批量的数据写入,或当Storm服务中断掉等一系列场景使得消息队列中有大量数据积压时,内存、线程、队列等一系列因素会导致很多在开发时没有注意的细节问题,如何保证数据能加速消费的同时不出现数据的丢失,也是一个需要开发者思考的问题。
Original: https://www.cnblogs.com/winter0730/p/15251836.html
Author: cos晓风残月
Title: 记一次stormOOM异常的产生与解决
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/576276/
转载文章受原作者版权保护。转载请注明原作者出处!