

Flume最早是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。
Flume特性
1.提供上下文路由特征
2.Flume的管道是基于事务,保证了数据在传送和接收时的一致性
3.Flume是可靠的,容错性高的,可升级的,易管理的,并且可定制的
4.Flume可用将应用产生的数据存储到任何集中存储器中,比如HDFS,HBase
5.可以被水平扩展
6.当收集数据的速度超过将写入数据的时候,也就是当收集信息遇到峰值时,这时候收集的信息非常大,甚至超过了系统的写入数据能力,这时候,Flume会在数据生产者和数据收容器间做出调整,保证其能够在两者之间提供平稳的数据
Flume核心概念
- agent
flume最核心的角色就是agent。flume日志采集系统是由一个个agent连接起来的数据传输通道
对于每个agent来说就是一个独立的守护进程(JVM)。它负责从数据源接收数据,并发送到下一个目的地。
agent内部有三个重要的组件:source、channel、sink - source
从数据发生器接收数据,并将接收的数据以Event的形式传递给一个或多个channel,Flume提供多种数据接收方式,比如Avro,Thrift等。 - channel
channel是一种短暂的存储容器,它从source处接收到event格式数据后进行缓存,直到被消费掉。
它在source和sink之间起到了桥梁作用,channel是一个完整的事务,这一点保障了数据在收发时的一致性,并且可以和任意数量的source和sink连接。
支持的类型有:JDBC channel,FileSystem Channel, Memory channel等。 - sink
sink将数据存储到集中存储器比如Hbase和HDFS,它从channels消费数据(events)并将其传递给目标地,目标地可能是另一个sink,也可能HDFS,HBase - Event
数据在flume内部是以Event封装的形式存在的。因此source组件在获取到原始数据后,需要封装成Event后发送到channel中,然后sink从channel取出Event后,根据配置要求再转成其他的形式进行数据输出。
Event封装的对象主要有两部分:Headers和Body
Headers是一个集合Map类型,用于存储元数据(如标志、描述等)
Body就是一个字节数组,装载具体的数据内容 - transaction
Flume的事务机制,类似于数据库的事务机制
Flume使用独立的事务分别从source到channel,以及从channel到sink的event传递。
注意:在任何时刻,Event至少在一个Channel是完整有效的 - Interceptor
拦截器,拦截工作在source组件之后,source产生的event会被传入的拦截器根据需要进行拦截处理。
拦截器可以组成拦截器链。
Flume组件详解
Source
Source Desc Avor Source 通过监听一个网络端口来接受数据,而且接受的数据必须是使用Avor序列化框架序列化后的数据。 Thrift Source 监听Thrift端口并从外部Thrift客户端流接收事件 Exec Source 启动一个用户所指定的linux shell命令,采集这个Linux shell命令的标准输出,作出收集到的数据,转为event写入channel JMS Source 从JMS目标(例如队列或主题)读取消息;作为JMS应用程序,它应可与任何JMS提供程序一起使用,但仅经过ActiveMQ的测试;注意,应该使用plugins.d目录(首选),命令行上的-classpath或通过flume-env.sh中的FLUME_CLASSPATH变量将提供的JMS jar包含在Flume类路径中。 Spooling Directory Source 监视一个指定的文件夹,如果文件夹下有没采集过的新文件,则将这些新文件中的数据采集,并转成event写入channel。(注意:spooling目录中的文件必须是不可变的,而且是不能重名的!否则,source会loudly fail !) Taildir Source 监视指定目录下的一批文件,只要某个文件中有新写入的行,则会被tail到;它会记录每一个文件所tail到的位置,记录到一个指定的positionfile保存目录中,格式为json(如果需要的时候,可以人为修改,就可以让source从任意指定的位置开始读取数据);它对采集完成的文件,不会做任何修改。(公司项目采用的Taildir Source) Kafka Source 就是用Kafka Consumer连接Kafka,读取数据,然后转换成event,写入channel NetCat Source 启动一个socket服务,监听一个端口,将端口上收到的数据,转成event写入channel Sequence Generator Source 一个简单的序列生成器,它使用从0开始,递增1并在totalEvents处停止的计数器连续生成事件;当无法发送event到channel时会进行重试。通常用于测试。 Syslog Sources 读取系统日志数据生成event Http Source 通过http post/get来接收数据,通常get用于测试,该source基于Jetty9.4,并提供了设置其他特定于Jetty的参数的功能,这些参数将直接传递给Jetty组件 Stress Source 主要用于压测,用于可以配置要发生的event总数以及要发送成功event的最大数 Custom Source 自定义Source taildir Source 监听指定目录的一批文件,只要某个文件被写入,那么就会被tail到。这里原理其实就是source会记录每个文件所读取到的位置,然后记录到一个指定的positionfile目录文件中,通常为json格式,而且是可见的,因此可以人为修改。由于该种机制,可以实现从任意指定位置读取数据,所以这个source是可以保障可靠性的。但是会有数据重复的问题。
Channel
Channel Desc Memory Channel event存储在内存中,且可以配置最大值。对于需要高吞吐而且可以容忍数据丢失的情况下,可以选择该channel JDBC Channel event被持久到数据库中,目前支持derby.适用于可恢复的场景 Kafka Channel agent利用Kafka作为channel数据缓存,Kafka Channel要跟Kafka Source,Kafka sink区别开来,Kafka Cannel在应用时,可以没有source File Channel event被缓存在本地磁盘文件中,可靠性高,不会丢失;但在极端情况下可能会重复数据 Spillable Memory Channel event存储在内存和磁盘上。内存充当主存储,磁盘充当溢出
Sink
Sink Desc HDFS Sink 数据最终被发往hdfs,可以生成text文件或sequence文件,而且支持压缩;支持生成文件的周期性roll机制;基于文件size,或者时间间隔,或者event数量;目标路径,可以使用动态通配符替换,比如用%D代表当前日期;当然,它也能从event的header中,取到一些标记来作为通配符替换 Hive Sink 可将text或json数据直接存储到hive分区表 Logger Sink 数据输出到日志中,通常用于debug Avro Sink avro sink用来向avro source 发送avro序列化数据,这样就可以实现agent之间的级联 Thrift Sink 同avro sink IRC Sink 同avro sink File Roll Sink 数据存储到本地文件系统 Null Sink 直接丢弃 Hbase Sink 数据存储到hbase中 Hbase2 Sink 等同于hbase 2版本的HBaseSink AsyncHBaseSink 异步模式写入hbase MorphlineSolrSink 该接收器从Flume事件中提取数据,对其进行转换,并将其几乎实时地加载到Apache Solr服务器中,后者再为最终用户或搜索应用程序提供查询 ElasticSearchSink 直接存储到es中 Kite Dataset Sink 将事件写入Kite数据集。该接收器将反序列化每个传入事件的主体,并将结果记录存储在Kite数据集中。它通过按URI加载数据集来确定目标数据集 Kafka Sink 存储到Kafka中 HTTP Sink 将接收到的数据通过post请求发送到远程服务,event内容作为请求体发送 Custom Sink 自定义Sink
Interceptor
拦截器,就是工作在source之后,可以从source获得event,做一个逻辑处理,然后再返回处理之后的event。这也就可以让用户不需要改动source代码的情况下,插入一些处理逻辑。
Interceptor Desc host 往event的header中插入主机名信息 timestamp 向event中,写入一个kv到header里;key的名称可以随意配置,value就是当前时间戳 static 让用户往event中添加一个自定义header,key-value形式的,当然这个kv在配置文件中是写死的 regex_filter 将event中的body内容和指定的正则表达式进行匹配 custom type as FQCN 自定义实现拦截器 uuid 用于在每个event header中生成一个uuid字符串 search_replace 该拦截器基于Java正则表达式提供简单的基于字符串的搜索和替换功能,类似于Java中的Matcher.replaceAll方法 RegexExtractorInterceptorMillisSerializer 该拦截器使用指定的正则表达式提取正则表达式匹 配组,并将匹配组附加到事件的header里
Selector
一个source可以对接多个channel,那么问题来了,source的数据是怎么在多个channel之间进行传递的呢?这就是selector的功能了,通过selector选择器根据策略可以将event从source传递到指定的channel中去。
Selector DESC replication selector 默认的选择器,将event进行复制分发给下游所有的节点 Multiplexing selector 多路选择器,可以根据event中的一个指定key对应的value来决定这条消息会被写入到哪个channel中 Custom Selector 自定义选择器
Processor
一个agent中,多个sink可以被组装到一个组中,而数据在组内多个sink之间发送。接收处理器可以在组内提供负载均衡的功能,或者是在临时故障的情况下实现从一个接收器转移到另一个接收器上。
Processor DESC default 默认的接收处理器仅接受一个sink,当然用户也没有必要为了一个sink去创建processor Failover 故障转移模式,即一个组内只有优先级高的sink在工作,而其他的sink处于等待中 load_balance 负载均衡模式,允许channel中的数据在一组sink中的多个sink之间进行轮转,具体的策略有:round-robin(轮流发送);random(随机发送) Custom processor 自定义处理器
Flume安装部署与使用
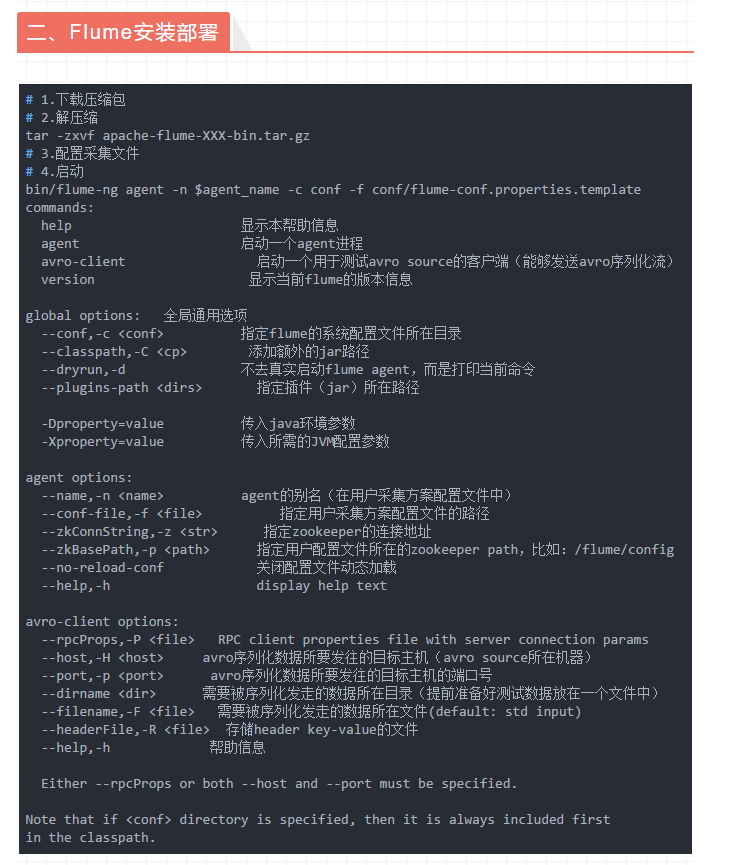

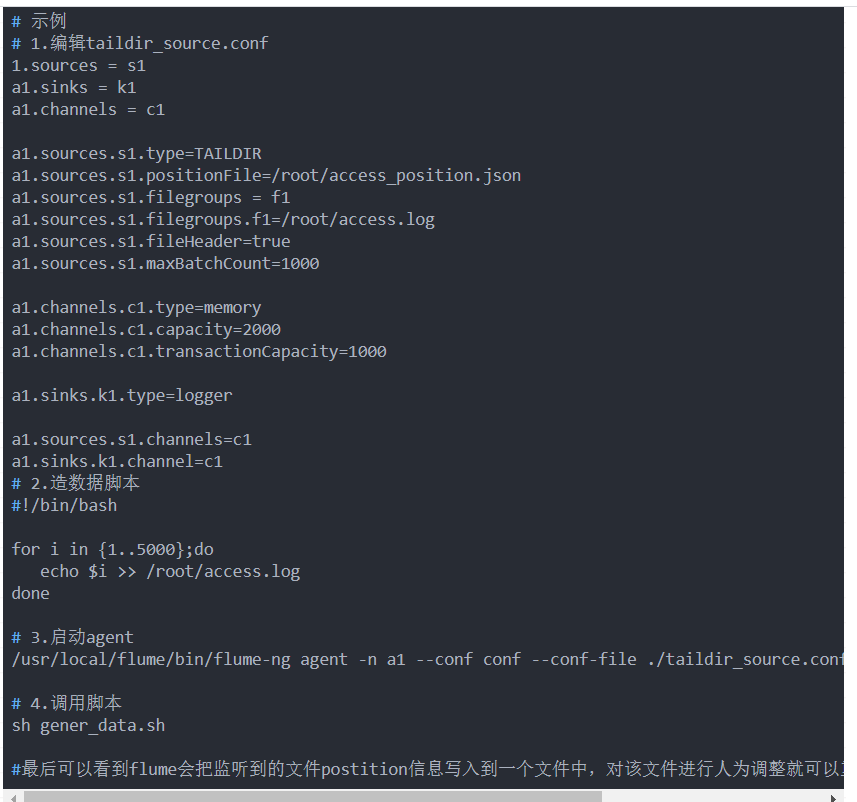
Original: https://www.cnblogs.com/winter0730/p/15404099.html
Author: cos晓风残月
Title: 实时流计算—数据采集工具Flume
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/576256/
转载文章受原作者版权保护。转载请注明原作者出处!