

需求是利用爬虫抓取店铺所有商品并下载商品详细页所有图片,随机挑选店铺链接分析。
但是在实现的过程中遇到各种困难,用selenium,requests利用多种方式都没有绕过。最后使用淘宝开发者API来实现调取店铺所有宝贝列表,但是API是付费的,所以在详细页使用requests来实现,但是requests仅在抓取天猫商品的时候没问题,而且我在天猫的详细页面抓取的时候使用手机页面抓取。如:
天猫店铺所有宝贝清单,也可以用爬虫实现,以此店铺链接为例:


所以天猫店铺的爬虫实现已经不是问题,代码也简单。
1 def get_tmall_taobao_detail(self,iid,category):
2 if category == "tmall":
3 url = "https://detail.m.tmall.com/item.htm?id=%s" % (str(iid))
4 response = requests.get(url)
5 data = response.content.decode('gbk')
6 re_img_url = re.compile('(https://img.alicdn.com.*?jpg)" src=\"data:image/')
7 alicdn_jpg_list = re_img_url.findall(data)
8 re_title = re.compile(' (.*)')
9 title = re_title.findall(data)[0].replace(".", "-").replace(".", "-")
10 if os.path.isdir("%s%s" % (self.image_path, title)):
11 pass
12 else:
13 os.mkdir("%s%s" % (self.image_path, title))
14 sum = 1
15 for img in alicdn_jpg_list:
16 jpgname = "详细页%s.jpg" %(sum)
17 self.urllib_download(img, title, jpgname)
18 sum = sum + 1
现在问题主要在C店的爬取,C店不管是店铺信息还是宝贝信息,数据爬取都比较困难。在分析过程中,所有页面都使用手机终端的请求头来访问,并分析相关js和json文件。
找到数据的关键链接


链接在response中看到宝贝的id、title、店铺宝贝数量等信息,但是链接有时效性。

而且C店详细页的数据也是一样,只要突破这个请求,就能实现整个爬虫,分析URL参数。

经过多次对比分析得到appkey是固定的,t是实时时间戳,sign这个需要计算得到,data中包含了关键参数page,shopid,sellerid,所以只要计算sign就可以构建整个url。
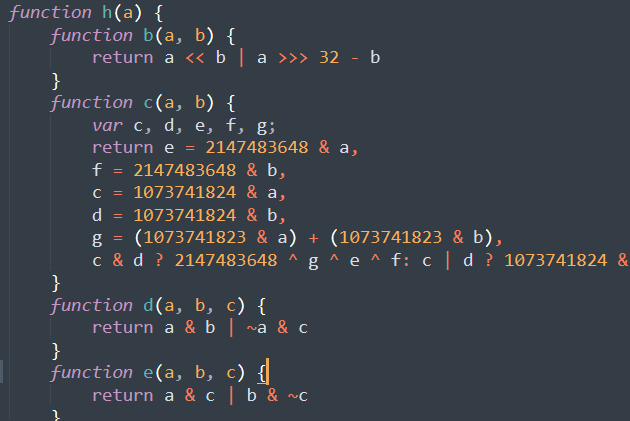
在js文件中找到相关计算代码,其中i是时间戳,g是appkey,c.data是data,d.token需要再寻找
可以看到j需要通过把参数带入h()函数进行计算返回,j就是sign。sign计算参数只有token未知。

而token来源于cookie中_m_h5_tk前半部分。


现在h()函数中的参数都齐了,单独摘出h()函数带入参数计算比对,验证最后计算与实际sign一致,并且发现这段代码实际就是md5的计算。
那么组合各个参数就可以得到sign,然后重组URL就能得到合法请求。
sign_data = self.cookies_m_h5_tk_split + "&" + self.t_now + "&" + self.appkey + "&" + self.get_data
self.sign_md5 = hashlib.md5(sign_data.encode(encoding='UTF-8')).hexdigest()
但是,sign会有时间周期,还需要在下一次提示”令牌过期”后重新获取cookie中的token,然后重新计算sign来提交第二次请求,实现爬虫,所有宝贝的列表代码实现如下,同理再实现详细页爬虫部分。
undefined
class Get_taobao_detail: def __init__(self): self.cookies_m_h5_tk_split = "" self.appkey = "12574478" self.get_data = '' self.headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36" } self.cookies = "你的cookie" self.cookies_dict = {} for i in self.cookies.split("; "): self.cookies_dict[i.split("=")[0]] = i.split("=")[1] self.page_number = 0 self.image_path = "./image/" self.iid_list = [] self.t_now = str(int(round(time.time() * 1000))) self.sign_md5 = "" def response_m_taobao_list(self,shopid,userid,page_number_i): self.get_data = '{"m":"shopitemsearch","vm":"nw","sversion":"4.6","shopId":"%s","sellerId":"%s","style":"wf","page":%s,"sort":"_coefp","catmap":"","wirelessShopCategoryList":""}' % (shopid,userid,page_number_i) def get_sign_md5(): sign_data = self.cookies_m_h5_tk_split + "&" + self.t_now + "&" + self.appkey + "&" + self.get_data self.sign_md5 = hashlib.md5(sign_data.encode(encoding='UTF-8')).hexdigest() url = "https://h5api.m.taobao.com/h5/mtop.taobao.wsearch.appsearch/1.0/?jsv=2.5.1&appKey=%s&t=%s&sign=%s&api=mtop.taobao.wsearch.appSearch&v=1.0&H5Request=true&AntiCreep=true&type=jsonp&timeout=3000&dataType=jsonp&callback=mtopjsonp8&data=%s" % ( self.appkey, self.t_now, self.sign_md5,self.get_data) response = requests.get(url, headers=self.headers, cookies=self.cookies_dict) page_data = response.content.decode('utf-8') new_cookies = requests.utils.dict_from_cookiejar(response.cookies) page_number_re = re.compile('pageSize":"(\d+)') page_number = page_number_re.findall(page_data) if page_number != []: self.page_number = int(page_number[0]) return new_cookies, page_data cookies_pagedata = get_sign_md5() new_cookies = cookies_pagedata[0] page_data = cookies_pagedata[1] if "令牌过期" not in page_data: return self._re_get_iid(page_data,"taobao") else: self.cookies_m_h5_tk_split = new_cookies["_m_h5_tk"].split("_")[0] self.cookies_dict['_m_h5_tk'] = new_cookies["_m_h5_tk"] self.cookies_dict['_m_h5_tk_enc'] = new_cookies["_m_h5_tk_enc"] self.response_m_taobao_list(shopid,userid,page_number_i)
最后效果,可爬取天猫淘宝所有内容:

Original: https://www.cnblogs.com/vpandaxjl/p/13640433.html
Author: 功夫小熊猫
Title: 绕过淘宝反爬虫,爬取店铺信息和宝贝信息
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/571702/
转载文章受原作者版权保护。转载请注明原作者出处!