

关于能用Spring怎样简化Web开发,想必大家已经好奇有段时间了。毕竟简化Web开发是Spring重头戏中的重头戏,也是我们学习Spring的主要目的。至于Spring是怎样简化Web开发的,让我们沿袭以往的学习方式,先用传统的Servlet实现一个项目,再用Spring对其进行改进,进而学习Spring关于简化Web开发的基础知识。
这个项目非常简单,就从数据库里查出人的信息显示在网页上。因此,我们需要一个数据库,一张数据库表,用于保存人的信息。而这,可以执行这些SQL脚本达成:
1 CREATE DATABASE sm_person_jsp DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;
2
3 USE sm_person_jsp;
4
5 CREATE TABLE person (
6 person_id INT NOT NULL AUTO_INCREMENT, # 数据库表ID
7 person_name VARCHAR(50) NOT NULL, # 名字
8 person_gender VARCHAR(50) NOT NULL, # 性别
9 PRIMARY KEY (person_id) # 添加主键
10 ) ENGINE = INNODB;
建好数据库之后,我们还需插入一些人的信息以供查询。因此,我们还需执行这些SQL脚本:
1 USE sm_person_jsp;
2 INSERT person(person_name, person_gender)
3 VALUES ('曹操', '帅哥');
4 INSERT person(person_name, person_gender)
5 VALUES ('刘备', '帅哥');
6 INSERT person(person_name, person_gender)
7 VALUES ('孙权', '帅哥');
8 INSERT person(person_name, person_gender)
9 VALUES ('貂蝉', '美女');
于是,人的信息就存在数据库里。我们需要实现一个Web应用程序,把人的信息从数据库里查询出来显示在网页上。为此,请新建Web项目如下:
01.打开IntelliJ IDEA,在欢迎界面上点击New Project按钮,打开New Project对话框。


02.选择左边面板Java那栏,并于右边面板选好JDK

03.点击Next按钮,跳到下图这个步骤。这个步骤无需填写任何信息。

04.点击Next按钮,设置Project name为person

05.点击Finish按钮,完成创建。
06.打开person目录创建libs文件夹,并把数据库驱动程序JAR包,数据源DBCP JAR包复制进去。

07.点击右上角的Add Configuration…按钮,打开Run/Debug Configurations对话框。

08.点击左上角的+按钮,在弹出的下拉菜单中点击Tomcat Server > Local,添加Tomcat Server配置。

09.设置Name为person;之后点击Configure…按钮,打开Tomcat Server对话框。

10.设置Tomcat Home为Tomcat所在的目录。比如,下载Tomcat之后把它放进E:\apache-tomcat-9.0.43\目录,则把Tomcat Home设为该值。

11.点击OK按钮关闭Tomcat Server对话框,返回Run/Debug Configurations对话框。
12.点击OK按钮关闭Run/Debug Configurations对话框。
13.右击项目person,在弹出的上下文菜单中点击Open Module Settings,打开Project Structure对话框。
14.左边面板选择Modules,右边面板选择Dependencies;之后点击+按钮,在弹出的下拉菜单中点击JARs or Directories…,打开Attach Files or Directories对话框。

15.选择libs目录,之后点击OK按钮关闭Attach Files or Directories对话框,完成JAR包的添加。

16.再次点击+按钮,在弹出的菜单中点击Library…,打开Choose Libraries对话框。

17.选择Tomcat,之后点击Add Selected按钮关闭Choose Libraries对话框,完成Tomcat JAR包的添加,返回Project Structure对话框。

18.点击+按钮,在弹出的下拉菜单中点击Web,添加Web Module

19.左边面板选择Artifacts;之后点击+按钮,在弹出的下拉菜单中点击Web Application: Archive添加Archive

20.设置Name为person;之后展开Available Elements底下的person,双击person底下的所有项把文件添加到Artifacts中。

21.点击OK按钮完成设置。可以看到,项目多了一个Web目录。

22.再次打开Run/Debug Configurations对话框,选择Deployment页签,点击+按钮,在弹出的菜单中点击Artifact…添加Artifact

23.点击OK按钮完成配置。
于是,Web项目搭建好了,是时候考虑如何实现它了。这里,我们采用三层架构,把整个项目划为数据访问层,业务逻辑层和表示层三层。数据访问层主要负责与数据库打交道,实现数据的存取。基于这样的架构,我们需在项目里创建com.dream.repository包,使之作为数据访问层专门存放数据存取相关的代码;业务逻辑层主要负责处理整个项目的业务逻辑。基于这样的架构,我们需在项目里创建com.dream.service包,使之作为业务逻辑层专门存放业务逻辑相关的代码;表示层主要负责用户交互。基于这样的架构,我们需在项目里创建com.dream.controller包,使之作为表示层专门存放用户交互相关的代码。于是,整个项目的架构搭好了。之后我们需要做的,就是实现数据访问层,业务逻辑层和表示层。
按照需求,我们需从数据库里查出人的信息显示在网页上。因此,数据访问层需要对外提供一个接口,使业务逻辑层调用之后能够拿到人的信息进行业务逻辑处理。另外,人的信息作为一种数据,需要保存在数据模型里。因此,我们需要定义一个数据模型QueryPersonOut类,一个数据存取QueryPerson接口,一个实现了数据存取接口的数据存取QueryPersonImpl类。代码如下:
1 package com.dream.repository;
2
3 public class QueryPersonOut {
4 private int id = 0;
5 private String name = null;
6 private String gender = null;
7
8 public int getId() {
9 return this.id;
10 }
11
12 public void setId(int id) {
13 this.id = id;
14 }
15
16 public String getName() {
17 return this.name;
18 }
19
20 public void setName(String name) {
21 this.name = name;
22 }
23
24 public String getGender() {
25 return this.gender;
26 }
27
28 public void setGender(String gender) {
29 this.gender = gender;
30 }
31 }
1 package com.dream.repository;
2
3 import java.util.*;
4
5 public interface QueryPerson {
6 List access();
7 }
1 package com.dream.repository;
2
3 import java.sql.*;
4 import java.util.*;
5 import javax.sql.*;
6 import org.apache.commons.dbcp2.*;
7
8 public class QueryPersonImpl implements QueryPerson {
9 private static final String STATEMENT;
10 private final DataSource dataSource = this.getDataSource();
11
12 @Override
13 public List access() {
14 Connection connection = null;
15 PreparedStatement statement = null;
16 SQLException sqlException = null;
17 var personList = new ArrayList();
18 try {
19 connection = this.dataSource.getConnection();
20 statement = connection.prepareStatement(STATEMENT);
21 var result = statement.executeQuery();
22 while (result.next()) {
23 var person = new QueryPersonOut();
24 person.setId(result.getInt(1));
25 person.setName(result.getString(2));
26 person.setGender(result.getString(3));
27 personList.add(person);
28 }
29 } catch (SQLException e) {
30 sqlException = e;
31 } finally {
32 if (statement != null) {
33 try {
34 statement.close();
35 } catch (SQLException e) {
36 if (sqlException == null) {
37 sqlException = e;
38 }
39 }
40 }
41 if (connection != null) {
42 try {
43 connection.close();
44 } catch (SQLException e) {
45 if (sqlException == null) {
46 sqlException = e;
47 }
48 }
49 }
50 if (sqlException != null) {
51 throw new RuntimeException(sqlException);
52 }
53 }
54 return personList;
55 }
56
57 private DataSource getDataSource() {
58 var dataSource = new BasicDataSource();
59 dataSource.setUsername("root");
60 dataSource.setPassword("123456");
61 dataSource.setUrl("jdbc:mysql://localhost:3306/sm_person_jsp");
62 dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
63 return dataSource;
64 }
65
66 static {
67 STATEMENT = ""
68 + " SELECT"
69 + " person_id, person_name, person_gender"
70 + " FROM"
71 + " person";
72 }
73 }
数据模型QueryPersonOut类具有id(数据库表ID),name(名字),gender(性别)三个属性。这与数据库表person的三个字段是一一对应的,刚好能够保存从数据库里查出的人的信息。
数据存取QueryPerson接口定义了【List
现在,让我们看看业务逻辑层是怎样调用数据访问层查出人的信息之后进行业务逻辑处理的。同数据访问层一样,业务逻辑层需要对外提供一个接口,使表示层调用之后能够拿到经过业务逻辑处理的数据进行显示。这些经过业务逻辑处理的数据同样需要保存在数据模型里。因此,我们需要定义一个数据模型ServicePersonInfoResult类,一个业务逻辑ServicePersonInfo接口,一个实现了业务逻辑接口的业务逻辑ServicePersonInfoImpl类。如下:
1 package com.dream.service;
2
3 public class ServicePersonInfoResult {
4 private int id = 0;
5 private String name = null;
6 private String gender = null;
7
8 public int getId() {
9 return this.id;
10 }
11
12 public void setId(int id) {
13 this.id = id;
14 }
15
16 public String getName() {
17 return this.name;
18 }
19
20 public void setName(String name) {
21 this.name = name;
22 }
23
24 public String getGender() {
25 return this.gender;
26 }
27
28 public void setGender(String gender) {
29 this.gender = gender;
30 }
31 }
1 package com.dream.service;
2
3 import java.util.*;
4
5 public interface ServicePersonInfo {
6 List process();
7 }
1 package com.dream.service;
2
3 import java.util.*;
4 import com.dream.repository.*;
5
6 public class ServicePersonInfoImpl implements ServicePersonInfo {
7 @Override
8 public List process() {
9 var personInfoResultList = new ArrayList();
10 var queryPerson = new QueryPersonImpl();
11 var queryPersonOutList = queryPerson.access();
12 if (queryPersonOutList != null) {
13 for (var queryPersonOut : queryPersonOutList) {
14 var personInfoResult = new ServicePersonInfoResult();
15 personInfoResult.setId(queryPersonOut.getId());
16 personInfoResult.setName(queryPersonOut.getName());
17 personInfoResult.setGender(queryPersonOut.getGender());
18 personInfoResultList.add(personInfoResult);
19 }
20 }
21 return personInfoResultList;
22 }
23 }
业务逻辑层并没有做太多业务逻辑处理。只是简单调用一下数据访问层查出人的信息,把人的信息保存到业务逻辑层自己的数据模型列表里返回给调用者而已,其它事情一件也没有做。非常简单,甚至非常多余。这是因为这里实现的功能实在太过简单了,根本没有什么业务逻辑需要处理,以至于连数据模型都和数据访问层的数据模型一模一样。但是,就应用程序的可扩展性而言,如此简单,甚至如此多余的业务逻辑层依然是必要的。
于是,业务逻辑层实现完成。是时侯实现表示层,把人的信息显示在网页上了。表示层的实现方式分为两种:一种是直接新建一个JSP,在JSP里调用业务逻辑层拿到人的信息之后解析生成HTML响应请求;一种是采用MVC(Model-View-Controller)模式进行实现。这种方式需要我们新建一个Servlet,一个JSP。Servlet作为控制器用于接收请求,处理请求。处理请求时需做两件事:一件是调用业务逻辑层拿到人的信息;一件是把人的信息作为数据模型放进请求属性中,把请求转发给JSP。也就是说,数据模型是通过请求属性转给JSP的。JSP作为视图拿到数据模型之后将对数据模型进行解析,解析之后生成HTML响应请求。这样,浏览器收到响应之后就能以网页的形式显示人的信息了。
非常明显,无论从程序的可维护性还是从程序的可扩展性来看,MVC模式都是一种比较好的方式。而这,正是我们的项目采用的方式。因此,我们需往表示层里添加一个Servlet如下:
1 package com.dream.controller;
2
3 import java.io.*;
4 import javax.servlet.*;
5 import javax.servlet.http.*;
6 import javax.servlet.annotation.*;
7 import com.dream.service.*;
8
9 @WebServlet(value="/person_info")
10 public class ControlPersonInfo extends HttpServlet {
11 @Override
12 protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
13 var personInfo = new ServicePersonInfoImpl();
14 var personList = personInfo.process();
15 if (personList != null) {
16 request.setAttribute("personList", personList);
17 }
18 request.getRequestDispatcher("/WEB-INF/views/index.jsp").forward(request, response);
19 }
20 }
该Servlet作为控制器收到http://localhost:8080/person/person_info请求之后将做这些处理:
1.调用【var personList = personInfo.process()】方法拿到所有人的信息。
2.调用【request.setAttribute(“personList”, personList)】方法把人的信息加进请求属性中。
3.调用【request.getRequestDispatcher(“/WEB-INF/views/index.jsp”).forward(request, response)】方法把请求转发给index.jsp
由此可见,我们的项目还少了个index.jsp文件。请在person > web > WEB-INF目录里新建views文件夹。之后右击views文件夹,在弹出的上下文菜单中点击New > JSP/JSPX,打开Create JSP/JSPX Page对话框;选择JSP file,输入index.jsp,按回车键完成创建之后修改如下:
1 @ page import="java.util.List" %> 2 @ page import="com.dream.service.ServicePersonInfoResult" %> 3 @ page contentType="text/html;charset=UTF-8" %> 4 <html> 5 <head> 6 <title>人的信息title> 7 head> 8 <body> 9 10 List<ServicePersonInfoResult> personList = (List<ServicePersonInfoResult>)request.getAttribute("personList"); 11 for(ServicePersonInfoResult person: personList) { 12 out.print("您好!我是
" + person.getName() + ",是个" + person.getGender() + "!"); 13 } 14 %> 15 body> 16 html>
这里写了段Scriptlet。Scriptlet取出请求属性personList的值,将其强制转换为人的信息列表,遍历之后生成HTML响应请求。于是我们的项目完成了,可以运行了。为此,请点击运行按钮,等待IntelliJ IDEA完成网站的编译,部署,运行和浏览器的启动之后往地址栏里输入http://localhost:8080/person/person_info按下回车键,那些曾在三国时期叱咤风云的帅哥美女随即穿越千年跑进网页问候我们:

很酷,对吧?重点在于如果改用Spring进行实现的话,能使这个项目更酷一些吗?为了寻找答案,让我们从实践中来到实践中去,改用Spring重新实现一下这个项目。之后两相对比,孰优孰劣自然一清二楚。而这,需要用到Spring提供的Spring MVC这一重要模块。毫无疑问,这一重要模块提供了些美妙的支持,使开发人员能用MVC这种架构更好地构建Web应用程序。为此,我们需要做的第一件事就是添加Spring JAR包,如下:
1.复制Spring JAR包到libs文件夹。
2.右击person项目,在弹出的上下文菜单中点击Open Module Settings,打开Project Structure对话框。
3.左边面板选择Artifacts;之后选择person.war下面的所有项,点击-按钮把它们删掉。

4.展开Available Elements底下的person,双击person底下的所有项把文件添加到Artifacts中。
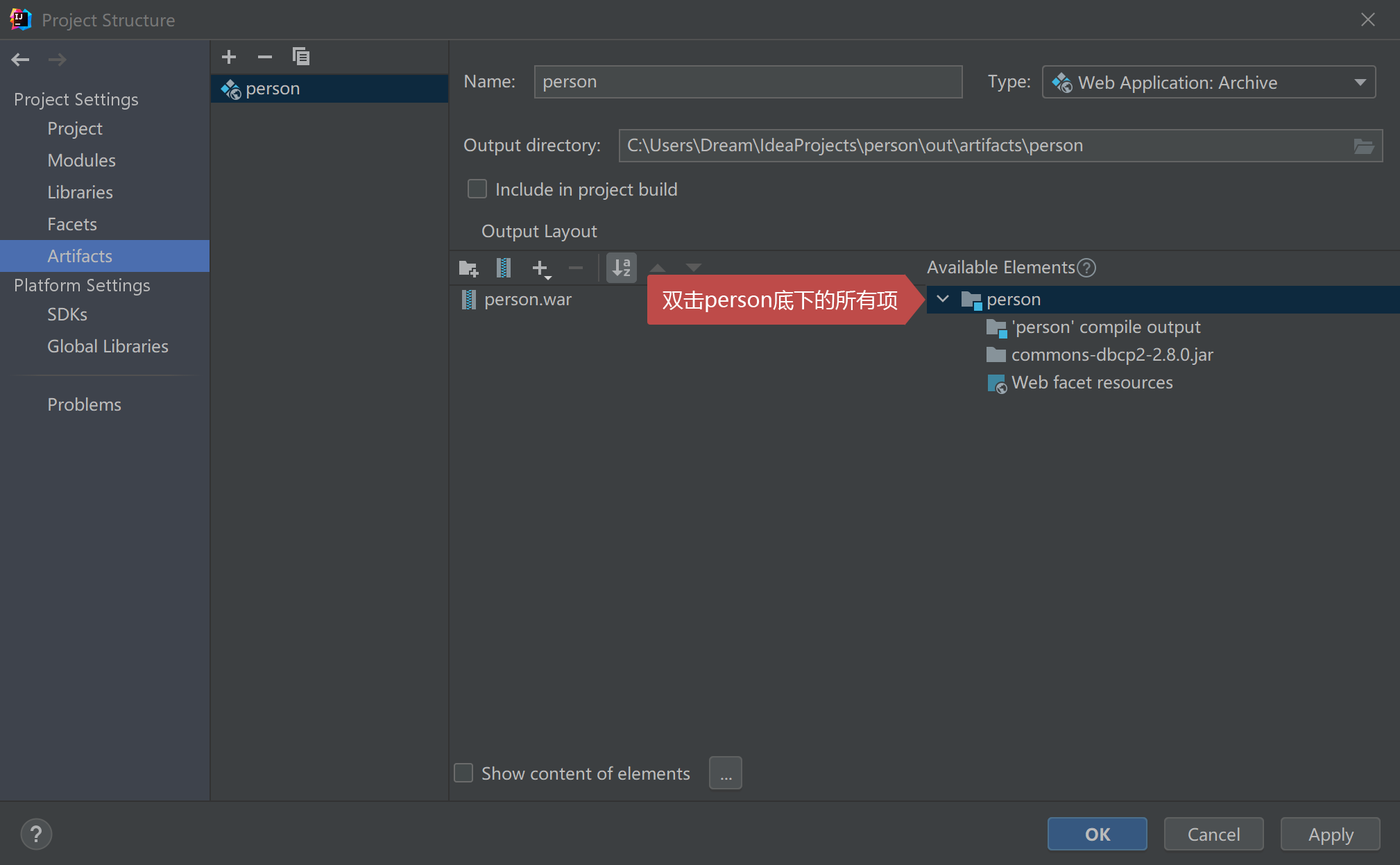
5.点击OK按钮完成配置。
现在,准备工作完成了,可以开始修改代码了。作为开始,让我们展开person > web > WEB-INF目录,打开部署描述文件web.xml修改如下:
1 xml version="1.0" encoding="UTF-8"?> 2 <web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee" 3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 4 xsi:schemaLocation=" 5 http://xmlns.jcp.org/xml/ns/javaee 6 http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd" 7 version="4.0"> 8 9 <servlet> 10 <servlet-name>dispatcherServletservlet-name> 11 <servlet-class>org.springframework.web.servlet.DispatcherServletservlet-class> 12 <init-param> 13 <param-name>contextConfigLocationparam-name> 14 <param-value>/WEB-INF/config/servlet-config.xmlparam-value> 15 init-param> 16 <load-on-startup>1load-on-startup> 17 servlet> 18 <servlet-mapping> 19 <servlet-name>dispatcherServletservlet-name> 20 <url-pattern>/url-pattern> 21 servlet-mapping> 22 23 web-app>
这里配置了个Servlet。这个Servlet具有这些特点:
1.Servlet的名称是dispatcherServlet
2.Servlet是org.springframework.web.servlet.DispatcherServlet类型的。
3.Servlet具有contextConfigLocation参数,值为/WEB-INF/config/servlet-config.xml
4.Servlet是在Web应用程序启动的时候加载和初始化的。
5.Servlet映射到的URL是”/”,能够接收和处理所有请求。
于是问题来了,DispatcherServlet是什么?为什么需要配置一个能够映射所有请求,处理所有请求的Servlet呢?
简单来说,DispatcherServlet就是Spring MVC实现的一个Servlet,和普通的Servlet并无差别。不同的是,普通的Servlet通常只是实现了某种功能,使之能够处理用户的某种请求,比如登录,注册,等等。DispatcherServlet虽然也是Servlet,却从不进行某种请求的处理。而是像个调配器,能把收到的请求重新映射给某个合适的控制器进行处理。因此,DispatcherServlet的主要任务不是处理请求,而是调配请求。正因如此,我们配置DispatcherServlet时总把URL置为”/”,使之能够收到所有请求并进行调配。而像DispatcherServlet这样能够映射所有请求,处理所有请求的Servlet通常称为前端控制器(Front Controller)
问题在于,控制器在哪?DispatcherServlet又是根据什么重新映射请求的呢?
这就涉及contextConfigLocation参数了。contextConfigLocation参数指定的是Spring应用上下文XML配置文件所在的位置。其值默认以【/WEB-INF/+前端控制器Servlet的名字+-servlet.xml】这样的方式拼接而成。在我们的配置中,前端控制器Servlet的名字是dispatcherServlet。因此,XML配置文件默认位于/WEB-INF/dispatcherServlet-servlet.xml
DispatcherServlet初始化时会根据contextConfigLocation参数指定的XML配置文件创建Spring应用上下文。Spring应用上下文是XmlWebApplicationContext类型的,是Spring针对Web应用程序提供的一种Spring应用上下文实现。于是,Spring应用上下文就存在Web应用程序里,管理着那些根据XML配置文件创建出来的Bean。当有请求到来时,DispatcherServlet将会重新映射请求,把请求交给Spring应用上下文里的某个Bean进行处理。由此可见,Spring应用上下文里的Bean就充当着控制器的角色,能够处理DispatcherServlet分配过来的请求。
在我们的配置中,我们指给contextConfigLocation参数的值是/WEB-INF/config/servlet-config.xml。因此,我们需在person > web > WEB-INF目录里新建config文件夹,再在config文件夹里新建XML配置文件servlet-config.xml,填写那些用作控制器的Bean的配置信息如下:
1 xml version="1.0" encoding="UTF-8"?> 2 <beans xmlns="http://www.springframework.org/schema/beans" 3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 4 xmlns:context="http://www.springframework.org/schema/context" 5 xsi:schemaLocation=" 6 http://www.springframework.org/schema/beans 7 http://www.springframework.org/schema/beans/spring-beans.xsd 8 http://www.springframework.org/schema/context 9 http://www.springframework.org/schema/context/spring-context-4.0.xsd> 10 11/> 12 13 beans>
这里启用了组件扫描,扫描了com.dream.controller包,包里存放着那些用作控制器的Bean。我们的项目需要的是一个能够获取人的信息的控制器。因此,原先用作控制器的ControlPersonInfo这个Servlet已经不合时宜了,需要修改如下:
1 package com.dream.controller;
2
3 import org.springframework.stereotype.*;
4 import org.springframework.beans.factory.annotation.*;
5 import org.springframework.web.bind.annotation.*;
6 import org.springframework.web.context.request.*;
7 import org.springframework.web.servlet.*;
8 import com.dream.service.*;
9
10 @Controller
11 public class ControlPersonInfo {
12 private ServicePersonInfo servicePersonInfo = null;
13
14 @Autowired
15 public void setServicePersonInfo(ServicePersonInfo servicePersonInfo) {
16 this.servicePersonInfo = servicePersonInfo;
17 }
18
19 @RequestMapping(value = "/person_info", method = RequestMethod.GET)
20 public ModelAndView visit(WebRequest request) {
21 var modelAndView = new ModelAndView("index");
22 var personList = this.servicePersonInfo.process();
23 if (personList != null) {
24 modelAndView.addObject("personList", personList);
25 }
26 return modelAndView;
27 }
28 }
修改之后,ControlPersonInfo已经不是一个Servlet,而是一个普通的类,一个简单的POJO。值得注意的是,该类带有@Controller注解。@Controller注解和@Component注解是一样的,只是名称不同而已。Spring引入@Controller注解只是为了提高代码的可读性,让人一看就知道带有@Controller注解的类不仅是个组件,而且是个用作控制器的组件,能被组件扫描发现之后自动进行Bean的创建。
另外,ControlPersonInfo类定义了两个方法。方法【public void setServicePersonInfo(ServicePersonInfo servicePersonInfo) 】带有@Autowired注解,能被组件扫描发现之后自动把实现了ServicePersonInfo接口的Bean装配进去;方法【public ModelAndView visit(WebRequest request)】是个用作控制器的方法,也是我们重点关注,重点学习的方法。
可以看到,visit方法带有一个神秘的@RequestMapping(value = “/person_info”, method = RequestMethod.GET)注解,能够提供处理器映射相关的信息。遗憾的是,按照现有的配置,Spring MVC是无法读懂该注解的。因此,我们需要启用注解驱动的Spring MVC,告诉Spring MVC创建一些基础Bean用于解析@RequestMapping注解。而这,需要我们修改XML配置文件如下:
1 xml version="1.0" encoding="UTF-8"?> 2 <beans xmlns="http://www.springframework.org/schema/beans" 3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 4 xmlns:context="http://www.springframework.org/schema/context" 5 xmlns:mvc="http://www.springframework.org/schema/mvc" 6 xsi:schemaLocation=" 7 http://www.springframework.org/schema/beans 8 http://www.springframework.org/schema/beans/spring-beans.xsd 9 http://www.springframework.org/schema/context 10 http://www.springframework.org/schema/context/spring-context-4.0.xsd 11 http://www.springframework.org/schema/mvc 12 http://www.springframework.org/schema/mvc/spring-mvc.xsd"> 13 14 <mvc:annotation-driven /> 15 <context:component-scan base-package="com.dream.controller" /> 16 17 beans>
这里作了两处改动:一是添加http://www.springframework.org/schema/mvc/spring-mvc.xsd模式文件,定义了哪些XML元素可以用于配置注解驱动的Spring MVC;二是使用spring-mvc.xsd模式文件定义的
因此,我们看到@RequestMapping具有value和method两个属性。value属性用于指定请求URL;method属性是RequestMethod枚举类型的,用于指定HTTP请求方法,比如GET,POST,PUT,DELETE,等等。RequestMappingHandlerMapping看见@RequestMapping注解之后,就从value属性获取请求URL,从method属性获取HTTP请求方法。之后把请求URL,HTTP请求方法和与之关联的方法写进请求映射表中。当有请求到来时,RequestMappingHandlerAdapter就以请求URL,HTTP请求方法作为条件查找请求映射表,看看能把请求映射给哪个控制器方法。如能找到,则把请求映射给相应的控制器方法进行处理;如果找不到,则响应一个找不到页面的404错误。visit方法带有的@RequestMapping注解的value属性的值是/person_info,method属性的值是RequestMethod.GET。因此,DispatcherServlet处理请求的时候将调用RequestMappingHandlerAdapter类型的Bean把请求URL是/person_info,HTTP请求方法是GET的请求重新映射给visit方法进行处理。
除此之外,visit方法还接受一个WebRequest类型的参数。WebRequest是Spring MVC提供的类,封装着关于请求的所有信息,包括请求参数,请求会话,等等。RequestMappingHandlerAdapter重新映射请求之前会用反射技术检查一下控制器需要哪些类型的参数,随后以相应类型的值作为参数调用控制器,把请求交给控制器处理。因此,RequestMappingHandlerAdapter把请求重新映射给visit方法时,会把关于请求的所有信息封装成WebRequest对象传递进去。这样,我们就能在visit方法里访问WebRequest对象获取请求信息了。当然,除了WebRequest类型之外,我们也能根据需要指定其它类型的参数。至于具体能够指定哪些类型的参数,由于篇幅较大,我们将在”细说Spring MVC”时进行讨论。现在只需知道,我们可在控制器里指定WebRequest类型的参数就行。
于是,方法【public ModelAndView visit(WebRequest request)】收到WebRequest类型的参数之后开始执行代码,做了这些事情:
1.执行【var modelAndView = new ModelAndView(“index”)】语句创建ModelAndView对象。
2.调用【var personList = this.servicePersonInfo.process()】方法拿到人的信息。
3.调用【modelAndView.addObject(“personList”, personList)】方法把人的信息放进ModelAndView对象。
4.返回ModelAndView对象。
毫无疑问,事情的关键在于visit方法返回的ModelAndView对象。我们知道,控制器该做的事情通常只有两件:一件是调用业务逻层生成数据模型;一件是把生成的数据模型交给视图。ModelAndView正是Spring MVC因此定义的一个类,能够提供关于数据模型和视图的信息。该类的构造函数带有一个字符串类型的参数,用于传入视图名。另外提供了addObject方法,用于设置数据模型。addObject方法接受两个参数,第一个参数是字符串类型的,用于传入数据模型的键;第二个参数是Object类型的,用于传入数据模型的值。visit方法创建ModelAndView对象时传入的是index这个字符串;调用addObject方法时传入的键是personList,传入的值是人的信息列表。于是,ModelAndView对象已经存有关于数据模型和视图的信息。现在的问题在于visit方法返回ModelAndView对象之后,视图是怎样产生的呢?
这又关乎前端控制器DispatcherServlet了。DispatcherServlet收到visit方法返回的ModelAndView对象之后会把它交给视图解析器。视图解析器解析视图之后即能生成HTML响应请求。这样,浏览器收到响应之后就能漂亮地显示人的信息了。那么,视图解析器在哪?DispatcherServlet到底把ModelAndView对象交给了哪个视图解析器?
回答这些问题之前,让我们修改servlet-config.xml配置文件如下:
xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:mvc="http://www.springframework.org/schema/mvc" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.0.xsd http://www.springframework.org/schema/mvc http://www.springframework.org/schema/mvc/spring-mvc.xsd"> <mvc:annotation-driven /> <context:component-scan base-package="com.dream.controller" /> <bean class="org.springframework.web.servlet.view.InternalResourceViewResolver"> <property name="prefix" value="/WEB-INF/views/" /> <property name="suffix" value=".jsp" /> bean> beans>
这里新配置了个org.springframework.web.servlet.view.InternalResourceViewResolver类型的Bean。该Bean是Spring MVC实现的其中一种视图解析器,能够解析JSP类型的视图,具有prefix和suffix两个属性:prefix属性用于指定视图名前缀;suffix属性用于指定视图名后缀。InternalResourceViewResolver拿到控制器返回的视图名之后,会以【视图名前缀+视图名+视图名后缀】的方式拼接视图的文件路径,再以拼接完成的文件路径找到视图文件之后结合控制器转来的数据模型解析视图。这里,prefix的值是/WEB-INF/views/,suffix的值是.jsp,控制器返回的ModelAndView对象里的视图名是index。因此,视图的文件路径是/WEB-INF/views/index.jsp。于是,InternalResourceViewResolver把ModelAndView对象里的数据模型放进请求属性中,把请求转发给index.jsp,由index.jsp生成HTML响应请求。
这时大家可能会问:”现有的视图技术种类繁多,常见的有Thymeleaf,FreeMarker,Apache Tile,等等。诸如这样的视图InternalResourceViewResolver也能解析吗?”
当然不能。除了InternalResourceViewResolver之外,Spring MVC还实现了其它类型的视图解析器。不同类型的视图应当使用不同的视图解析器进行解析。而这,通常只需修改XML配置文件,把相应的视图解析器添加进去即可。至于其它类型的视图解析器是怎样的,由于篇幅较大,我们将在”细说Spring MVC”的时候进行讨论。现在只需知道InternalResourceViewResolver能够解析JSP就行。
于是,采用Spring MVC改写的表示层完成了,是时候修改业务逻辑层和数据访问层,看看引入Spring之后能够怎么实现了。为此,请打开部署描述文件web.xml,添加一些配置信息如下:
1 xml version="1.0" encoding="UTF-8"?> 2 <web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee" 3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 4 xsi:schemaLocation=" 5 http://xmlns.jcp.org/xml/ns/javaee 6 http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd" 7 version="4.0"> 8 9 <context-param> 10 <param-name>contextConfigLocationparam-name> 11 <param-value>/WEB-INF/config/root-config.xmlparam-value> 12 context-param> 13 <listener> 14 <listener-class>org.springframework.web.context.ContextLoaderListenerlistener-class> 15 listener> 16 17 <servlet> 18 <servlet-name>dispatcherServletservlet-name> 19 <servlet-class>org.springframework.web.servlet.DispatcherServletservlet-class> 20 <init-param> 21 <param-name>contextConfigLocationparam-name> 22 <param-value>/WEB-INF/config/servlet-config.xmlparam-value> 23 init-param> 24 <load-on-startup>1load-on-startup> 25 servlet> 26 <servlet-mapping> 27 <servlet-name>dispatcherServletservlet-name> 28 <url-pattern>/url-pattern> 29 servlet-mapping> 30 31 web-app>
这里新添了个Servlet上下文监听器。Servlet上下文监听器org.springframework.web.context.ContextLoaderListener是Spring MVC提供的,同样具有contextConfigLocation参数。于是大家猜到了,Web应用程序启动时将触发ContextLoaderListener监听器。之后,ContextLoaderListener监听器读取contextConfigLocation参数的值。如果读取不到,也就是开发人员没有配置contextConfigLocation参数,则用默认的【/WEB-INF/applicationContext.xml】XML配置文件创建Spring应用上下文;如果读取得到,则用contextConfigLocation参数指定的XML配置文件创建Spring应用上下文。这个Spring应用上下文同样也是XmlWebApplicationContext类型的。
于是我们知道了,Web应用程序启动的时候总共创建了两个Spring应用上下文。一个Spring应用上下文由ContextLoaderListener创建,通常称为根应用上下文;一个Spring应用上下文由DispatcherServlet创建,通常称为Servlet应用上下文。根应用上下文是父容器,Servlet应用上下文是子容器。父容器和子容器之间有个差别,就是父容器的Bean可以注入到子容器的Bean中,子容器的Bean不能注入到父容器的Bean中。也就是说,根应用上下文的Bean可以注入到Servlet应用上下文的Bean中,Servlet应用上下文的Bean不能注入到根应用上下文的Bean中。之所以引入父容器子容器这样的设计,是因为Spring MVC是支持三层架构的。它希望数据访问层和业务逻辑层的Bean放在根应用上下文里;表示层的Bean,也就是那些用作控制器,用作处理器映射,用作视图解析器的Bean放在Servlet应用上下文里。这样可以把表示层独立开来,避免开发人员把控制器注入到数据访问层或业务逻辑层中,使整个项目的架构更加清晰,更加整洁。
这里,我们指给contextConfigLocation参数的值是/WEB-INF/config/root-config.xml。因此,我们需在person > web > WEB-INF > config目录里新建配置文件root-config.xml,填上那些关于业务逻辑层和数据访问层的Bean的配置信息如下:
xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.0.xsd"> <context:component-scan base-package="com.dream.repository,com.dream.service" /> <bean class="org.apache.commons.dbcp2.BasicDataSource"> <property name="username" value="root" /> <property name="password" value="123456" /> <property name="url" value="jdbc:mysql://localhost:3306/sm_person_spring" /> <property name="driverClassName" value="com.mysql.cj.jdbc.Driver" /> bean> beans>
这里配置了两件东西:一件是启用组件扫描;一件是添加一个关于数据源的Bean。组件扫描是通过
1 package com.dream.service;
2
3 import java.util.*;
4 import org.springframework.stereotype.*;
5 import org.springframework.beans.factory.annotation.*;
6 import com.dream.repository.*;
7
8 @Service
9 public class ServicePersonInfoImpl implements ServicePersonInfo {
10 private QueryPerson queryPerson = null;
11
12 @Autowired
13 public void setQueryPerson(QueryPerson queryPerson) {
14 this.queryPerson = queryPerson;
15 }
16
17 @Override
18 public List process() {
19 var personInfoResultList = new ArrayList();
20 var queryPersonOutList = this.queryPerson.access();
21 if (queryPersonOutList != null) {
22 for (var queryPersonOut : queryPersonOutList) {
23 var personInfoResult = new ServicePersonInfoResult();
24 personInfoResult.setId(queryPersonOut.getId());
25 personInfoResult.setName(queryPersonOut.getName());
26 personInfoResult.setGender(queryPersonOut.getGender());
27 personInfoResultList.add(personInfoResult);
28 }
29 }
30 return personInfoResultList;
31 }
32 }
这里作了两处改动:一处是往ServicePersonInfoImpl类上添加@Service注解;一处是往setQueryPerson方法上添加@Autowired注解。@Service注解用于把业务逻辑层的类标为组件,以供组件扫描发现。Spring引入@Service注解的目的和引入@Controller注解的目的是一样的,这里不再赘述。@Autowired注解启用了自动装配,让Spring应用上下文自动把实现了QueryPerson接口的Bean装配进去。这是大家熟知的知识,不作更多介绍。
于是,业务逻辑层改好了,开始修改数据访问层的QueryPersonImpl类如下:
1 package com.dream.repository;
2
3 import java.util.*;
4 import javax.sql.*;
5 import org.springframework.jdbc.core.*;
6 import org.springframework.stereotype.*;
7 import org.springframework.beans.factory.annotation.*;
8
9 @Repository
10 public class QueryPersonImpl implements QueryPerson {
11 private static final String STATEMENT;
12 private JdbcTemplate jdbcTemplate = null;
13
14 @Autowired
15 public void setJdbcTemplate(DataSource dataSource) {
16 this.jdbcTemplate = new JdbcTemplate(dataSource);
17 }
18
19 @Override
20 public List access() {
21 return this.jdbcTemplate.query(STATEMENT, (resultSet, i) ->{
22 var person = new QueryPersonOut();
23 person.setId(resultSet.getInt(1));
24 person.setName(resultSet.getString(2));
25 person.setGender(resultSet.getString(3));
26 return person;
27 });
28 }
29
30 static {
31 STATEMENT = ""
32 + " SELECT"
33 + " person_id, person_name, person_gender"
34 + " FROM"
35 + " person";
36 }
37 }
这里作了三处改动:一处是往QueryPersonImpl类上添加@Repository注解;一处是添加一个带有@Autowired注解的【public void setJdbcTemplate(DataSource dataSource)】方法;一处是改用Spring JDBC简化【public List
@Repository注解用于把数据访问层的类标为组件,以供组件扫描发现。Spring引入@Repository注解的目的和引入@Controller注解的目的是一样的,这里不再赘述。
setJdbcTemplate方法带有@Autowired注解,能被组件扫描发现之后自动把实现了DataSource接口的Bean装配进去。我们在root-config.xml配置文件里配置的数据源Bean就是为此准备的。
于是,最后的数据访问层也改完了。这意味着我们的修改工作已经完成,可以运行程序了。程序的运行结果和先前的是一样的。只是引入Spring MVC之后,Web应用程序的启动过程变成这样了:
1.启动Web容器。
2.启动Web应用程序。
3.触发ContextLoaderListener监听器,创建根应用上下文,生成业务逻辑层和数据访问层的Bean
4.加载和初始化DispatcherServlet,创建Servlet应用上下文,生成控制器,处理器映射,视图解析器,等等。
5.Web应用程序完成启动,等待客户端发来请求。
客户端发来请求之后,Web应用程序处理请求的过程变成这样:
1.Web容器收到请求之后把请求交给Web应用程序。
2.Web应用程序收到请求之后把请求统一交给DispatcherServlet处理。
3.DispatcherServlet调用处理器映射把请求重新映射给某个符合请求条件的控制器进行处理。
4.控制器完成请求的处理之后,把生成的数据模型和视图名这些信息返回给DispatcherServlet
5.DispatcherServlet拿到控制器返回的数据模型和视图名之后,把数据模型和视图名交给视图解析器。
6.视图解析器解析视图,生成HTML响应请求。
至于Spring对整个项目作的改进,则主要体现在这些方面:
1.提倡面向接口编程。
2.控制器原本是用Servlet实现的。引入Spring之后,控制器变成普通的类,简单的POJO
3.引入面向接口编程和Spring应用上下文之后,数据访问层,业务逻辑层和表示层之间是通过接口联系起来的。更为重要的是,我们的代码并不需要创建那些Bean,那些Bean是由Spring应用上下文创建的。之后,Spring应用上下文通过接口进行Bean的注入,把数据访问层,业务逻辑层和表示层的Bean联系起来。这样,数据访问层,业务逻辑层和表示层之间的关系就变得非常松散了。从而大大降低了对象之间的耦合,降低了软件开发的复杂度。
4.引入Spring JDBC之后,那些访问数据库的样板代码再也没有了,事情一下子变得简单起来。
5.引入Spring MVC之后,视图被解耦出来,不再与应用程序捆绑在一起,从而提高了应用程序的可扩展性,降低了软件开发的复杂度。
至此,关于Spring MVC的基础知识介绍完了。可是静下心来仔细一想,又开始觉得事情不对。试想一下,这里响应给请求的是HTML。可是,如果用户使用的前台终端不是浏览器,而是鸿蒙应用程序,IOS应用程序,安卓应用程序,微信小程序,等等;这些前台终端难道也能像浏览器那样解析HTML吗?显然不能,毕竟不同的前台终端其用户界面的实现方式是不同的。由此可见,后台服务器仅向前台终端响应HTML是远远不够的,是不合时宜的。我们将在下章开始讨论如何使用REST这种编程思想解决这个问题。欢迎大家继续阅读,谢谢大家!
Original: https://www.cnblogs.com/evanlin/p/15487292.html
Author: 林雪波
Title: Spring MVC
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/571406/
转载文章受原作者版权保护。转载请注明原作者出处!