
前言
线程池最大的作用就是复用线程。在线程池中,经过同一个线程去执行不一样的任务,减少反复地创建线程带来的系统开销,就是线程的复用。那么线程池线程复用的原理是什么呢?
之前面试被问到线程池复用的原理时,由于对源码不甚了解,回答的不好。因此这篇文章将深入源码,理解线程复用到底时如何实现的。
一、线程池核心属性
首先我们看看线程池的核心属性,这也是面试中经常被问到的问题。
public class ThreadPoolExecutor extends AbstractExecutorService {
//线程状态,高3为表示线程池状态,低29位表示线程数量
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
//Lock锁
private final ReentrantLock mainLock = new ReentrantLock();
//条件变量
private final Condition termination = mainLock.newCondition();
//线程集合
private final HashSet workers = new HashSet<>();
//核心线程数
private volatile int corePoolSize;
//最大线程数
private volatile int maximumPoolSize;
//阻塞队列
private final BlockingQueue workQueue;
//非核心线程存活时间
private volatile long keepAliveTime;
//线程工厂,所有线程使用线程工厂创建
private volatile ThreadFactory threadFactory;
//拒绝策略,是一个函数式接口
private volatile RejectedExecutionHandler handler;
}
二、execute源码
我们可以从execute() 方法开始,查看线程复用的原理
private static final int COUNT_BITS = Integer.SIZE - 3; //32-3
private static final int COUNT_MASK = (1 << COUNT_BITS) - 1; 2^29-1
//c & COUNT_MASK; 返回低29位,也就是线程树
private static int workerCountOf(int c) { return c & COUNT_MASK; }
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
//得到线程数,判断
以上的步骤可以以流程图来表示
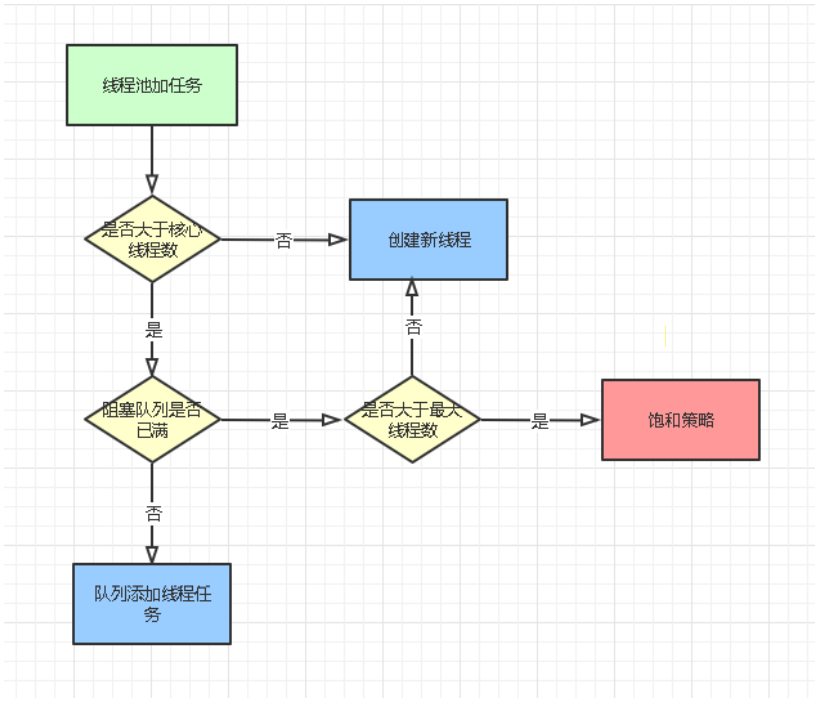

三、addWorker源码
addWorker 方法的主要做用是在线程池中建立一个线程并执行传入的任务,若是返回 true 表明添加成功,若是返回 false 表明添加失败。
- firstTask:表示传入的任务
- core:布尔值,
- true :表明增长线程时判断当前线程是否少于 corePoolSize,小于则cas将ctl加1,大于等于则不增长;
- false :表明增长线程时判断当前线程是否少于 maximumPoolSize,小于则则cas将ctl加1,大于等于则不增长
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (int c = ctl.get();;) {
// Check if queue empty only if necessary.
if (runStateAtLeast(c, SHUTDOWN)
&& (runStateAtLeast(c, STOP)
|| firstTask != null
|| workQueue.isEmpty()))
return false;
for (;;) {
if (workerCountOf(c)
>= ((core ? corePoolSize : maximumPoolSize) & COUNT_MASK))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateAtLeast(c, SHUTDOWN))
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//创建新线程w
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock(); //加锁
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int c = ctl.get();
if (isRunning(c) ||
(runStateLessThan(c, STOP) && firstTask == null)) {
if (t.getState() != Thread.State.NEW)
throw new IllegalThreadStateException();
//将新建线程w加入集合
workers.add(w);
workerAdded = true;
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
//运行线程t
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
现在,我们已经创建了一个线程来执行任务,我们发现,当线程数小于核心线程数或者当队列已经满时且线程数小于最大线程数时,addWorker会创建一个新线程来执行新任务,那么当阻塞队列未满时,怎么复用核心线程呢?答案就在29行,Worker类中。
四、Worker类源码
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
/**
* This class will never be serialized, but we provide a
* serialVersionUID to suppress a javac warning.
*/
private static final long serialVersionUID = 6138294804551838833L;
/** Thread this worker is running in. Null if factory fails. */
@SuppressWarnings("serial") // Unlikely to be serializable
final Thread thread;
/** Initial task to run. Possibly null. */
@SuppressWarnings("serial") // Not statically typed as Serializable
Runnable firstTask;
/** Per-thread task counter */
volatile long completedTasks;
// TODO: switch to AbstractQueuedLongSynchronizer and move
// completedTasks into the lock word.
/**
* Creates with given first task and thread from ThreadFactory.
* @param firstTask the first task (null if none)
*/
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this); //使用线程工厂创建线程
}
/** Delegates main run loop to outer runWorker. */
public void run() {
runWorker(this);
}
// Lock methods
//
// The value 0 represents the unlocked state.
// The value 1 represents the locked state.
protected boolean isHeldExclusively() {
return getState() != 0;
}
......
}
Worker实现了 Runnable接口,并且有一个 final属性 thread,当 addWorker()方法执行 new Worker(firstTask)时,构造器通过 ThreadFactory创建新线程,并将当前 Runnable传入 newThread()。因此, addWorker() 方法执行 t.start后,当该线程抢到cpu执行权时,将执行 runWorker(this);
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
//取出w的firstTask
Runnable task = w.firstTask;
//将w的firstTask置为null
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
//线程第一次创建后,task不为null;当执行完之后的线程之后,该线程会从阻塞队列中去取任务
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
//该方法的方法体为null,留给我们自己扩展
beforeExecute(wt, task);
try {
//直接调用task的run方法
task.run();
//该方法的方法体为null,留给我们自己扩展
afterExecute(task, null);
} catch (Throwable ex) {
afterExecute(task, ex);
throw ex;
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
在这里,我们终于找到了线程复用的最终实现,当调用 execute方法或者 submit方法时,会判断当前线程数是不是小于核心线程数,或者当线程数大于核心线程数且小于最大线程数且阻塞队列未满,线程池会在 addWorker方法中新建一个Worker线程,并将该线程添加进线程集合中,线程状态ctl加1,然后运行该线程。
在 Worker的 run方法中会调用 runWorker方法,该方法通过一个循环进行线程的复用, while (task != null || (task = getTask()) != null)。当 task≠null(当线程执行创建线程时的任务时)或者 (task = getTask()) != null(从阻塞队列中取任务赋值给task)时,直接运行 task.run方法而不是新建线程。也就是说,每一个线程都始终在一个大循环中,反复获取任务,而后执行任务,从而实现了线程的复用。
Original: https://www.cnblogs.com/ruigedada/p/16258645.html
Author: 睿哥Dada
Title: 线程池线程复用的原理
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/569573/
转载文章受原作者版权保护。转载请注明原作者出处!