

知识融合一般分为两步,本体对齐和实体匹配两种的基本流程相似,如下:


一、实体对齐常见的步骤:
1.1 数据预处理
1) 语法正规化 2) 数据正规化
1.2 记录链接
把实体通过相似度进行连接
1.3 相似度计算
分成属性相似度和实体相似度。其中,属性相似度可以通过编辑距离(Levenstein,Wagner and Fisher, edit distance with Afine Gaps)集合相似度(Jaccard, Dice)基于向量的相似度(Cosine,TFIDF)。实体相似度可通过聚合,聚类(Canoy+K-means此法不用指定K,可分为层次聚类,相关性聚类)
1.4 分块(blocking)
从所有三元组中找到潜在的匹配并分到一块中,减少运算量。
1.5 负载均衡
保证所有的分块中实体书目相当,做Map-reduce。
1.6 结果评估
二、知识图谱对齐的常见方法
2.1 传统的基于概率模型的方法
考虑各个实体的属性,不考虑实体间的关系,通过评估各种相似度来对齐实体,本质上为分类问题。
2.2 机器学习方法
- 通过属性,比较实体或属性向量,进而判断实体匹配与否
- 聚类方法
- 主动学习:通过机器与人的交互学习(类似的有ActiveAtlas系统)
三、解决不同规模知识图谱方面的方法
3.1 小规模知识图谱的融合
一般来讲,小规模的知识图谱融合由人工完成为主,多以WordNet为参照做相似度计算求得对齐
- First-world-first-sence策略:把未见到的词连接到与其词性相同,同一集合的词上。但是这种方法对于 _领域图谱_并不适用。
- VCU:使用相似度计算如果相似度大于阈值,认为相同,可以对齐。这种方法简单有效。但是未考虑到去除噪声,也未使用KG的结构。
- TALN:使用BabelNet更多的假如句法,词性,短语等信息
- MSeirku:加入了消歧机制。
所有这些方法都离不开简单的相似度排序方法
参考论文:
1. VCU at Semeval-2016 Task 14: Evaluating similarity measures for semantic taxonomy enrichment
2. TALN at SemEval-2016 Task 14: Semantic Taxonomy Enrichment Via Sense-Based Embeddings
3. MSejrKu at SemEval-2016 Task 14: Taxonomy Enrichment by Evidence Ranking
3.2 中等规模的KG Alignment
当知识图谱规模小的时候,多使用词法句法信息,规模变大后可以使用图谱的结构特征信息
- Enriching Taxonomies with Functional Domain Knowledge: 使用了图语义特征,图中心度特征。在语义理解上提升许多
- Improvement on 1:使用了模糊聚类算法,发现并概念化新的实体,找到实体在图中的位置。
参考论文:
1. Enriching Taxonomies With Functional Domain Knowledge
2. Using Taxonomy Tree to Generalize a Fuzzy Thematic Cluster
3.3 大规模的KG Alignment
本质上是不同的领域的实体对齐,形成与以上的链接。使用了基于知识表示的实体对齐。可以使用上下级的结构特征,和语义特征。
- Entity Alignment Between KGs using attribute embedding: 不同于TransE,PTransE等KGE模型关注的是学习实体和路径。本论文关注的是实体属性。可分为三个部分:谓词对齐,知识表示(embedding)和实体对齐。这类对齐要求把两个KG映射到一个向量空间中。使用谓词对齐模块查找相似的谓词。并使用统一命名。相当于使用谓词匹配反推实体对齐
- Iterative entity Alignment via joint KE: Background(大多知识图谱对齐依赖的是外部信息如Wikipedia) 本文提出一种基于联合知识图谱嵌入的方法。分为三部分:1)知识表示-TransE,2)联合表示-将多个KG映射到同一空间,使用机器翻译模型Seq2Seq,线性变换函数,参数共享,3)知识对齐迭代。
参考论文:(前三个基于字符相似度,后三个基于知识图嵌入)
1. RDF-AI: an Architecture for RDF Datasets Matching, Fusion and Interlink
2. Limes: a time-efficient approach for large-scale link discovery on the web of data
3. Holistic Entity Matching Across Knowledge Graphs
4. Entity Alignment between Knowledge Graphs Using Attribute Embeddings
5. Iterative Entity Alignment via Joint Knowledge Embeddings
6. Collective Embedding-based Entity Alignment via Adaptive Features
步骤补充说明:
1.数据预处理:
数据预处理阶段,原始数据的质量会直接影响到最终链接的结果,不同的数据集对同一实体的描述方式往往是不相同的,对这些数据进行归一化是提高后续链接精确度的重要步骤。常用的数据预处理有:
语法正规化:
语法匹配:如联系电话的表示方法
综合属性:如家庭地址的表达方式
数据正规化:
移除空格、《》、””、-等符号
输入错误类的拓扑错误
用正式名字替换昵称和缩写等
2.记录连接
假设两个实体的记录x 和y, x和y在第i个属性上的值是, 那么通过如下两步进行记录连接:
属性相似度: 综合单个属性相似度得到属性相似度向量:
实体相似度: 根据属性相似度向量得到一个实体的相似度。
2.1属性相似度的计算
属性相似度的计算有多种方法,常用的有编辑距离、集合相似度计算、基于向量的相似度计算等。
(1)编辑距离: Levenstein、 Wagner and Fisher、 Edit Distance with Afine Gaps
(2)集合相似度计算: Jaccard系数, Dice
(3)基于向量的相似度计算: Cosine相似度、TFIDF相似度
2.2实体相似度的计算
实体关系发现框架Limes 教程网址:http://openkg1.oss-cn-beijing.aliyuncs.com/d9780259-7e4f-456f-88fa-8274a3def82b/tutorial-limes.pdf
2.2.1聚合:
(1)加权平均:对相似度得分向量的各个分量进行加权求和,得到最终的实体相似度
(2)手动制定规则:给每一个相似度向量的分量设置一个阈值,若超过该阈值则将两实体相连
(3)分类器:采用无监督/半监督训练生成训练集合分类
2.2.2聚类:
(1)层次聚类:通过计算不同类别数据点之间的相似度对在不同的层次的数据进行划分,最终形成树状的聚类结构。
(2)相关性聚类:使用最小的代价找到一个聚类方案。
(3)Canopy + K-means:不需提前指定K值进行聚类
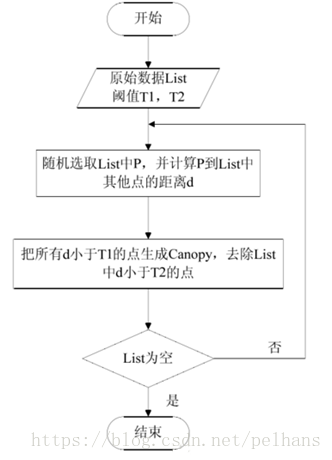
2.2.3知识表示学习:(嵌入式表示)
将知识图谱中的实体和关系都映射低维空间向量,直接用数学表达式来计算各个实体之间相似度。这类方法不依赖任何的文本信息,获取到的都是数据的深度特征。
3 分块
分块 (Blocking)是从给定的知识库中的所有实体对中,选出潜在匹配的记录对作为候选项,并将候选项的大小尽可能的缩小。常用的分块方法有基于Hash函数的分块、邻近分块等。常见的Hash函数有:字符串的前n个字,n-grams,结合多个简单的hash函数等。邻近分块算法包含Canopy聚类、排序邻居算法、Red-Blue Set Cover等。
4 负载均衡
负载均衡 (Load Balance)来保证所有块中的实体数目相当,从而保证分块对性能的提升程度。最简单的方法是多次Map-Reduce操作。
实体对齐工具调研:
Falcon-AO是一个自动的本体匹配系统,已经成为RDF(S)和OWL所表达的Web本体相匹配的一种实用和流行的选择。编程语言为Java。匹配算法库包含V-Doc、I-sub、GMO、PBM四个算法。其中V-Doc即基于虚拟文档的语言学匹配,它是将实体及其周围的实体、名词、文本等信息作一个集合形成虚拟文档的形式。可以用TD-IDF等算法进行操作。I-Sub是基于编辑距离的字符串匹配。I-Sub和V-Doc都是基于字符串或文本级别的处理。更进一步的就有了GMO,它是对RDF本体的图结构上做的匹配。PBM则基于分而治之的思想做。首先经由PBM进行分而治之,后进入到V-Doc和 I-Sub ,GMO接收两者的输出做进一步处理,GMO的输出连同V-Doc和I-Sub的输出经由最终的贪心算法进行选取。

2.Limes 实体匹配
Limes是一个基于度量空间的实体匹配发现框架,适合于大规模数据链接,编程语言是Java。其整体框架如下图所示:

3.Sematch(开源2017)
用于知识图谱的语义相似性的开发、评价和应用的集成框架。 Sematch支持对概念、词和实体的语义相似度的计算,并给出得分。 Sematch专注于基于特定知识的语义相似度量,它依赖于分类( 比如 ) 中的结构化知识。 深度、路径长度 ) 和统计信息内容( 语料库与语义图谱) 。—-基于wordNet。
4 .基于 Neo4j 图数据库 的知识图谱的实体对齐 (目前最常用)
计算相关性的基本步骤分为三步:
1,链接neo4j数据库,并且读取出里面的数据
2,对齐算法运算
3,拿到运算结果设定一个阀值,来判断大于阀值的就是相关。
基于Neo4j 图数据库的知识图谱的关联对齐-最小编辑距离-jacard 算法
Original: https://blog.csdn.net/xs1997/article/details/109257678
Author: 春末的南方城市
Title: 知识图谱之实体对齐一
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/568763/
转载文章受原作者版权保护。转载请注明原作者出处!