

其实对seq2seq如何解码一直不明确。现在整理一下苏神博客里关于seq2seq的知识 。文章太多 只放一个网址吧https://spaces.ac.cn/archives/5861
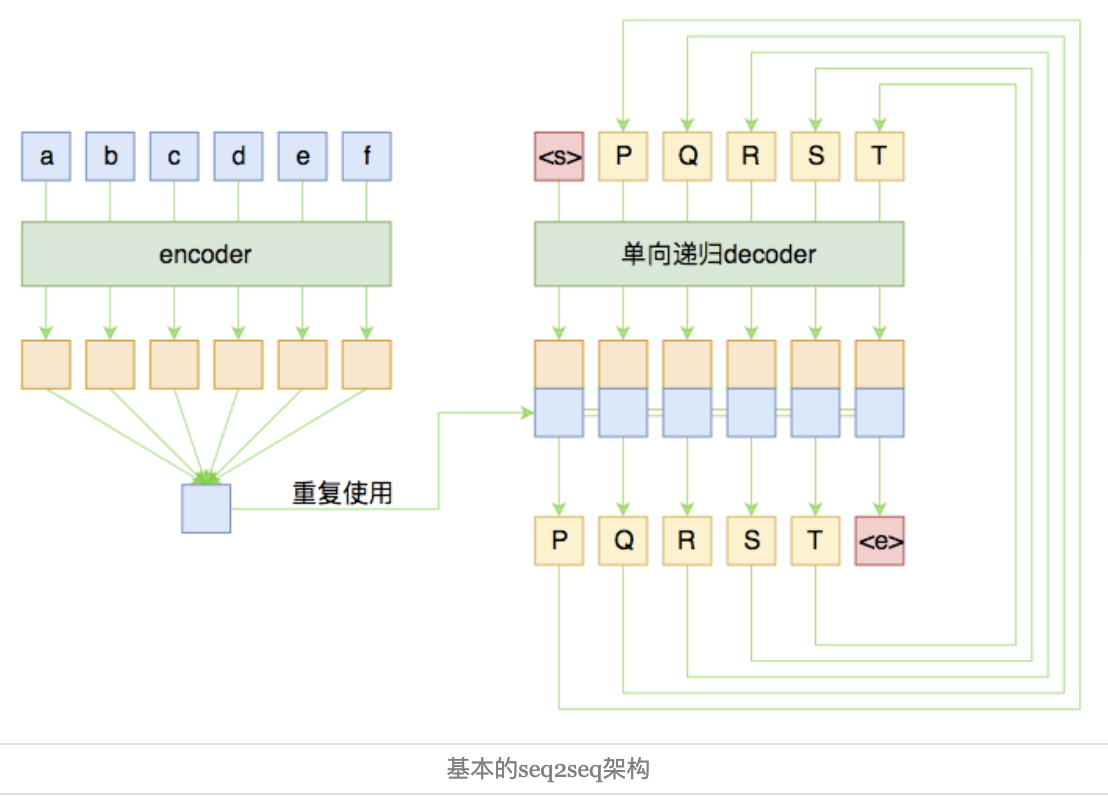

尽管整个图的线条比较多,可能有点眼花,但其实结构很简单。左边是对输入的encoder,它负责把输入(可能是变长的)编码为一个固定大小的向量,这个可选择的模型就很多了,用GRU、LSTM等RNN结构或者CNN+Pooling、Google的纯Attention等都可以,这个固定大小的向量,理论上就包含了输入句子的全部信息。
而decoder负责将刚才我们编码出来的向量解码为我们期望的输出。与encoder不同,我们在图上强调decoder是”单向递归”的,因为解码过程是递归进行的,具体流程为:

这就是一个基本的seq2seq模型的解码过程,在解码的过程中,将每步的解码结果送入到下一步中去,直到输出
训练过程
事实上,上图也表明了一般的seq2seq的训练过程。由于训练的时候我们有标注数据对,因此我们能提前预知decoder每一步的输入和输出,因此整个结果实际上是”输入X 和Y[:-1],预测Y [1:],即将目标Y错开一位来训练。这种训练方式,称之为Teacher-Forcing。
而decoder同样可以用GRU、LSTM或CNN等结构,但注意再次强调这种”预知未来”的特性仅仅在训练中才有可能,在预测阶段是不存在的,因此decoder在执行每一步时,不能提前使用后面步的输入。所以,如果用RNN结构,一般都只使用单向RNN;如果使用CNN或者纯Attention,那么需要把后面的部分给mask掉(对于卷积来说,就是在卷积核上乘上一个0/1矩阵,使得卷积只能读取当前位置及其”左边”的输入,对于Attention来说也类似,不过是对query的序列进行mask处理)。
「自注:这里有个问题,是解码进行了mask 而不是编码对吗。自己在实验中为啥是编码过程有了mask。要想清楚这个过程就需要明白在transformer实验中的对谁用了mask。我记得是对编码进行了mask
有关将bert作为编码器和解码器可以搜索Bert如何既当作编码器又当解码器。还要看这里https://baijiahao.baidu.com/s?id=1736572335920886109&wfr=spider&for=pc transformers中bert作编码器解码器的包 」

beam search [
;](https://spaces.ac.cn/archives/5861#beam%20search)
前面已经多次提到了解码过程,但还不完整。事实上,对于seq2seq来说,我们是在建模
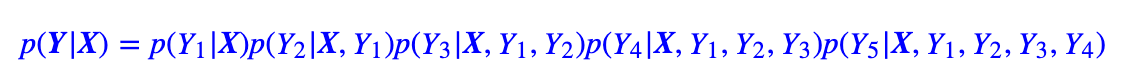
显然在解码时,我们希望能找到最大概率的Y,那要怎么做呢?
如果在第一步p(Y1|X)时,直接选择最大概率的那个(我们期望是目标P ),然后代入第二步p(Y2|X,Y1),再次选择最大概率的Y 2 ,依此类推,每一步都选择当前最大概率的输出,那么就称为贪心搜索,是一种最低成本的解码方案。但是要注意,这种方案得到的结果未必是最优的,假如第一步我们选择了概率不是最大的Y1,代入第二步时也许会得到非常大的条件概率p(Y2|X,Y1),从而两者的乘积会超过逐位取最大的算法。
然而,如果真的要枚举所有路径取最优,那计算量是大到难以接受的(这不是一个马尔可夫过程,动态规划也用不了)。因此,seq2seq使用了一种折中的方法:beam search。
这种算法类似动态规划,但即使在能用动态规划的问题下,它还比动态规划要简单,它的思想是:在每步计算时,只保留当前最优的topk个候选结果。比如取t pk=3,那么第一步时,我们只保留使得p(Y1|X)最大的前3个Y1,然后分别代入p(Y2|X,Y1),然后各取前三个Y2,这样一来我们就有3 2 =9 32=9个组合了,这时我们计算每一种组合的总概率,
然后还是只保留前三个,依次递归,直到出现了第一个
seq2seq提升 #
前面所示的seq2seq模型是标准的,但它把整个输入编码为一个固定大小的向量,然后用这个向量解码,这意味着这个向量理论上能包含原来输入的所有信息,会对encoder和decoder有更高的要求,尤其在机器翻译等信息不变的任务上。因为这种模型相当于让我们”看了一遍中文后就直接写出对应的英文翻译”那样,要求有强大的记忆能力和解码能力,事实上普通人完全不必这样,我们还会反复翻看对比原文,这就导致了下面的两个技巧。
Attention #
Attention目前基本上已经是seq2seq模型的”标配”模块了,它的思想就是:每一步解码时,不仅仅要结合encoder编码出来的固定大小的向量(通读全文),还要往回查阅原来的每一个字词(精读局部),两者配合来决定当前步的输出。
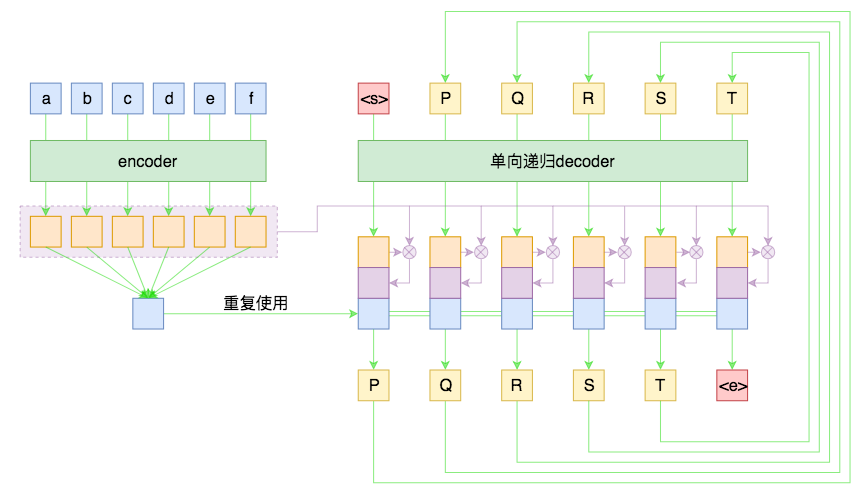
带Attention的seq2seq
至于Attention的具体做法,笔者之前已经撰文介绍过了,请参考《Attention is All You Need》浅读(简介+代码)。Attention一般分为乘性和加性两种,笔者介绍的是Google系统介绍的乘性的Attention,加性的Attention读者可以自行查阅,只要抓住query、key、value三个要素,Attention就都不难理解了。
mask #
在seq2seq中,做好mask是非常重要的,所谓mask,就是要遮掩掉不应该读取到的信息、或者是无用的信息,一般是用0/1向量来乘掉它。keras自带的mask机制十分不友好,有些层不支持mask,而普通的LSTM开启了mask后速度几乎下降了一半。所以现在我都是直接以0作为mask的标记,然后自己写个Lambda层进行转化的,这样速度基本无损,而且支持嵌入到任意层,具体可以参考上面的代码。
要注意我们以往一般是不区分mask和unk(未登录词)的,但如果采用我这种方案,还是把未登录词区分一下比较好,因为未登录词尽管我们不清楚具体含义,它还是一个真正的词,至少有占位作用,而mask是我们希望完全抹掉的信息。
Original: https://www.cnblogs.com/nlpers/p/16435474.html
Author: nlp如此迷人
Title: seq2seq总结【转载以学习、回忆】
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/568108/
转载文章受原作者版权保护。转载请注明原作者出处!