

7 Predicting Dynamic Embedding Trajectory in Temporal Interaction Networks
link:https://arxiv.org/abs/1908.01207
Abstract
本文提出了一种在嵌入空间中显示建模用户/项目的未来轨迹的模型JODIE。该模型基于RNN模型,用于学习用户和项目的嵌入轨迹。JODIE可以进行未来轨迹的预测。本文还提出了 t-Batch算法,利用该方法可以创建时间相同的batch,并使训练速度提高9倍。
Conclusion
在本文中,提出了一个称为JODIE的rnn模型,该模型从一系列时间交互中学习用户和项目的动态嵌入。JODIE学习预测用户和项目的未来嵌入,这使得它能够更好地预测未来用户项目交互和用户状态的变化。还提出了一种训练数据批处理方法,使JODIE比类似基线快一个数量级
未来的工作有几个方向。学习单个用户和项目的嵌入是昂贵的,可以学习用户或项目组的轨迹,以减少参数的数量。另一个方向是描述相似实体的轨迹。最后,一个创新的方向是根据许多用户可能与之交互的缺失预测项目设计新项目。
Figure and table
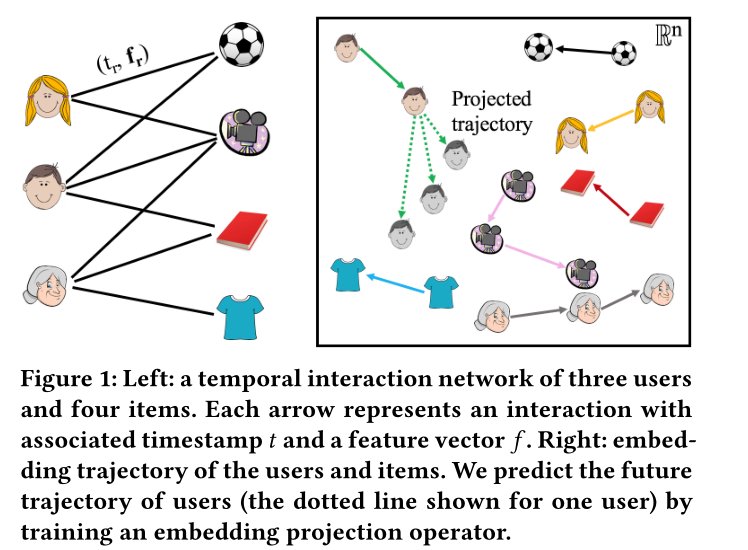

图1 左边是一个时序交互网络(二部图),包含三个用户和四个物品。连线表示在时间t和特征向量f下的交互。右边是用户和物品的嵌入轨迹图,通过训练一个嵌入预测操作(可训练参数矩阵)预测用户的特征轨迹。图中虚线就是用户的估计预测。
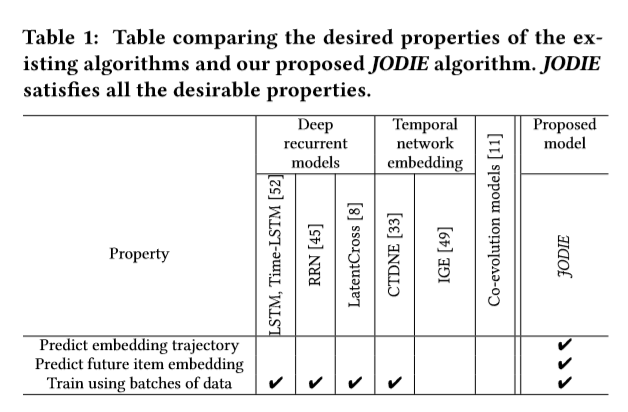
表1 对比了已存在的各种算法和JODIE的用途,JODIE全部满足(自己论文肯定全部满足啊。。。)
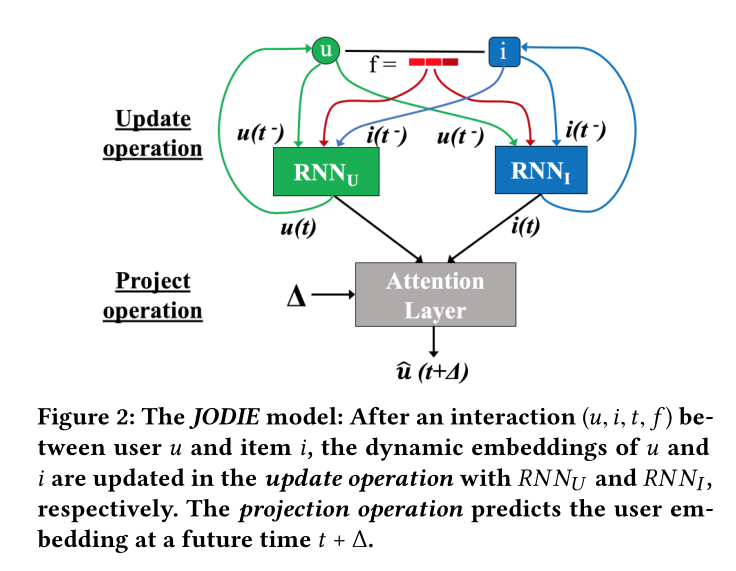
图2 JODIE模型:JODIE在一次交互((u,i,t,f))后,通过(RNN_U)和(RNN_I)两个模块更新(u)和(i)的动态嵌入,接着预测操作去预测(t+∆)时间的用户嵌入

表2 符号的含义
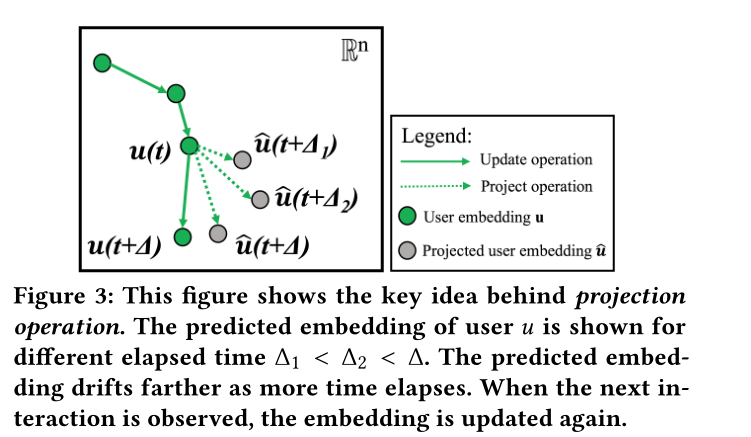
图3 展示了预测操作。这里预测了用户在三个间隔时间的嵌入位置,其中(∆_1 < ∆_2 < ∆)。随着时间的推移,预测的嵌入会漂移得更远。当观察到下一次交互时,嵌入将再次更新。
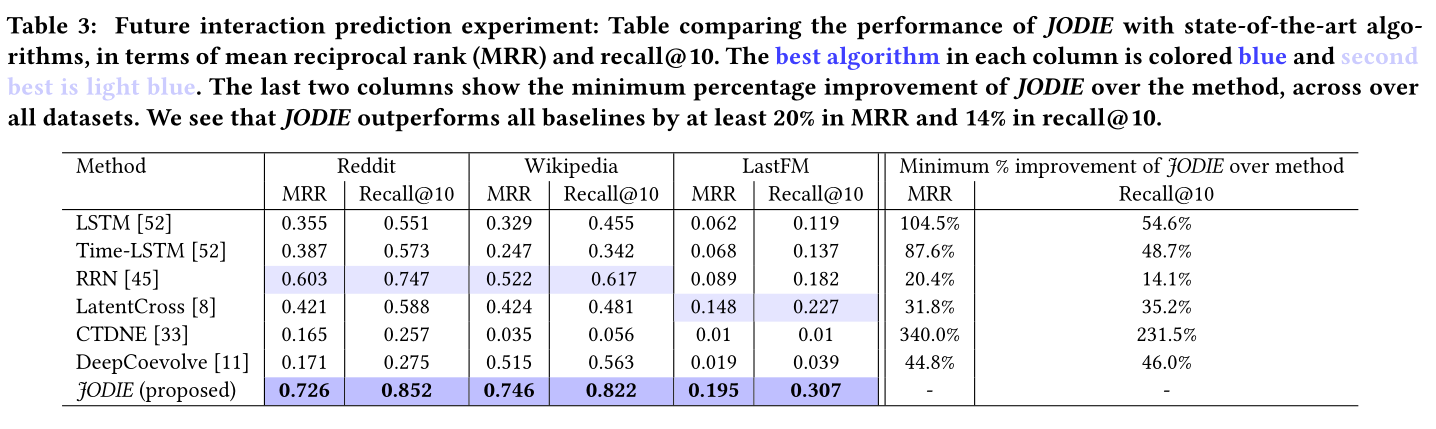
表3 交互预测实验:这张表展示了各类算法在不同的数据集上表现,用MRR和recall作为指标
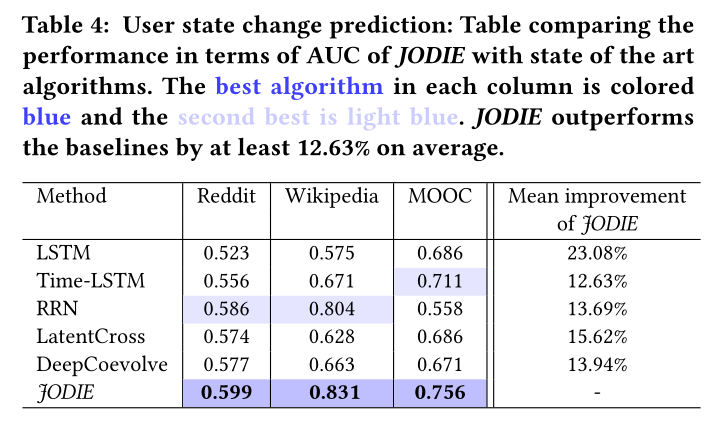
表4 用户状态更改预测:用auc做指标
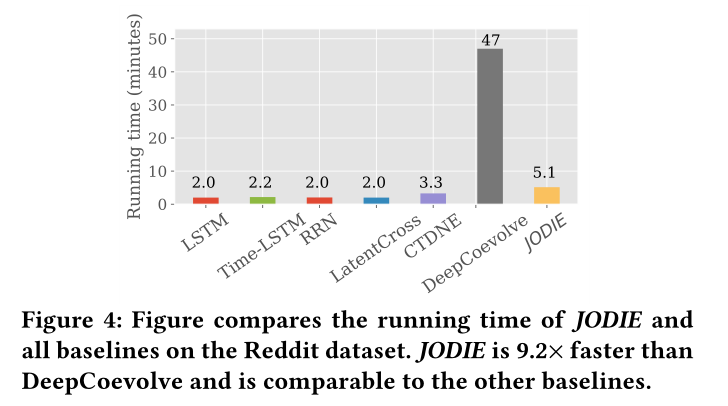
图4 运行时间对比
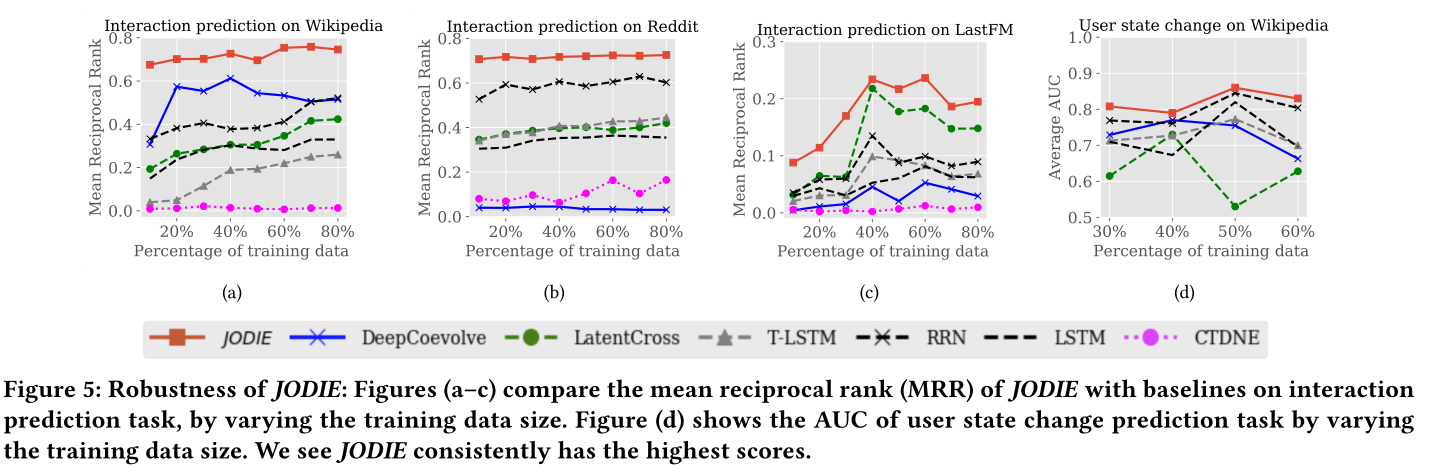
图5 鲁棒性对比
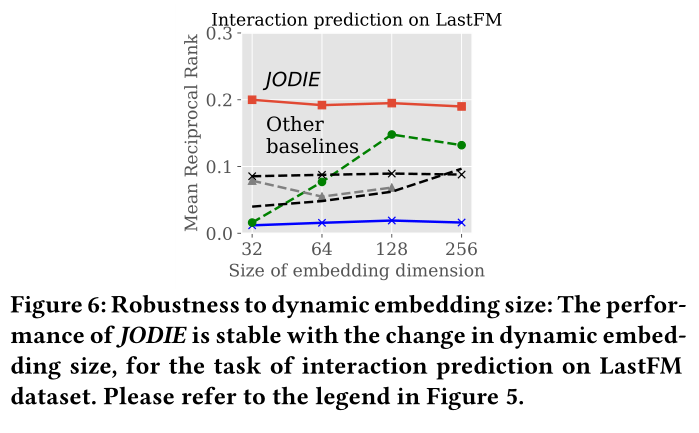
图6 动态嵌入尺寸的鲁棒性对比
Introduction
本文提出了一个工业场景中实际的四个问题
先前的方法都是等到用户有交互才会去更新他的嵌入。比如一个今天购买的用户,其嵌入已更新。如果在第二天、一周后甚至一个月后返回平台,嵌入将保持不变。因此,无论她什么时候回来,都会对她做出同样的预测和建议。然而,用户的意图会随着时间的推移而改变,因此她的嵌入需要更新(预测)到查询时间。这里的挑战是如何随着时间的推移准确预测用户/项目的嵌入轨迹。
实体有随时间改变的属性,也有不随时间改变的属性。现有的方法一般只会考虑二者其一
许多现有方法通过为每个用户的所有项目打分来预测用户项目交互。复杂性过高,推荐相关场景需要较低的时间复杂度(原文近乎恒定时间:near-constant time)
现在的大多数模型都是通过将交互串行化依次处理,以保证时间顺序信息。同样时间代价较大。
本文模型JODIE学习从时间交互中生成所有用户和项目的嵌入轨迹。在使用用户的嵌入进行交互预测时,并不会直接使用上一次的用户嵌入,而是先通过一个预测,预测用户在所需时间的嵌入位置,通过通过预测预测的嵌入进行下一步的操作。(解决了第一个问题)
本文提出的模型JODIE学习从时间交互中生成所有用户和项目的嵌入轨迹。每个用户和项目都有两个嵌入属性:静态嵌入和动态嵌入。静态嵌入表示实体的长期平稳特性,而动态嵌入表示时变特性,并使用JODIE算法进行学习。(解决了第二个问题)
JODIE模型由两个主要组件组成:更新操作和预测操作。JODIE的更新操作有两个RNN来生成用户和项目嵌入。至关重要的是,这两个RNN被耦合起来,以合并用户和项目之间的相互依赖性。耦合的含义是:再一次交互后,用户RNN根据交互项目的嵌入去更新用户嵌入。同样的,项目RNN使用用户嵌入去更新项目嵌入。(这就带来了特征交叉)
在以往的工作中如果想预测用户下一步的交互项目,通常会对所有项目进行打分,这样将会带来线形时间的复杂度。本文提出的方案是利用模型预测的嵌入,在嵌入空间找尽可能接近的嵌入,使用位置敏感哈希(LSH)技术在固定时间内高效完成。(解决了第三个问题)
作者还提出了t-batch的操作。大多数现有模型通过依次处理每个交互来学习嵌入,以保持交互之间的时间依赖性。在本文中,通过创建独立交互的训练batch来训练JODIE,这样每个batch中的交互都可以并行处理。操作为迭代地从交互网络中选择独立的边集,在每个批次中,每个用户和项目最多出现一次,用每个用户(和项目)的交互时序排序递增增作为顺序。(解决了第四个问题)
Method
3 JODIE: JOINT DYNAMIC USER-ITEM EMBEDDING MODEL
在本节,将提出JODIE其具体模型。该模型学习用户的嵌入(\boldsymbol{u}(t) \in \mathbb{R}^{n},\forall u \in \mathcal{U})和项目嵌入(\boldsymbol{i}(t) \in \mathbb{R}^{n},\forall i \in \mathcal{I}),其中(\forall t \in[0, T])来自时序用户项交互的有序序列(S_{r}=\left(u_{r}, i_{r}, t_{r}, f_{r}\right))。该交互由用户(u_r \in \mathcal{U})和项目(i_r \in \mathcal{I})在时间(t_r \in \mathbb{R}^+,0
JODIE由用户和物品的交互去训练更新操作。JODIE训练一个预测操作,该操作使用以前观察到的状态和经过的时间来预测用户未来的嵌入。当观察到用户和项目的下一次交互时,它们的嵌入会再次更新。
为每个用户和项目分配了两个嵌入:静态嵌入和动态嵌入。我们使用这两种嵌入来编码实体的长期静态特性和动态特性。
静态嵌入:(\overline{\boldsymbol{u}} \in \mathbb{R}^{d} \forall u \in \mathcal{U} \text { , } \overline{\boldsymbol{i}} \in \mathbb{R}^{d} \forall i \in \mathcal{I})不会随时间变化。这些用于表示固定属性,例如用户的长期兴趣。本文使用独热码作为用户和项目的静态嵌入。
动态嵌入:为每个用户(u)和项目(i)分配一个动态嵌入,表示为(u(t) \in \mathbb{R}^{n} \text { , } i(t) \in \mathbb{R}^{n})分别位于时间(t)的嵌入。这些嵌入会随着时间的推移而变化,以模拟其随时间变化的行为和属性。用户/项目的动态嵌入顺序是指其轨迹。
接下来介绍更新和预测操作
*3.1 Embedding update operation
在更新操作中,用户(u)和项目(i)在时间t之间的交互(S=(u,i,t,f))用于生成它们的动态嵌入(u(t))和(i(t))。图2示出了更新操作。
我们的模型使用两个递归神经网络进行更新,所有用户共享(RNN_U)来更新用户嵌入,所有项目共享(RNN_I)来更新项目嵌入。用户RNN和项目RNN的隐藏状态分别表示用户和项目嵌入。
这两个RNN是相互递归(mutually-recursive)的。当用户(u)与项目(i)交互时,(RNN_U)在时间(t)将嵌入(i(t))作为输入项目,更新嵌入(u(t^−)) 。$i(t^−) $表示为上一个时刻的项目嵌入。
作者提到了原来普遍用的使用项目独热码来训练的缺点
a) 独热码只包含关于项的id的信息,而不包含项的当前状态
b)当实际数据集有数百万项时,独热码的维度变得非常大,不利于训练
本文使用项目的动态嵌入,因为它反映了项目的当前状态,从而导致更有意义的动态用户嵌入和更容易的训练。出于同样的原因,(RNN_I)使用动态用户嵌入(u(t))更新项目(i)的动态嵌入$i(t^−) ((这是时间)t (之前)u$的嵌入)。这会导致嵌入之间的相互递归依赖关系。见下式
[\begin{array}{c} \boldsymbol{u}(\boldsymbol{t})=\sigma\left(W_{1}^{u} \boldsymbol{u}\left(\boldsymbol{t}^{-}\right)+W_{2}^{u} \boldsymbol{i}\left(\boldsymbol{t}^{-}\right)+W_{3}^{u} f+W_{4}^{u} \Delta_{u}\right) \ \boldsymbol{i}(\boldsymbol{t})=\sigma\left(W_{1}^{i} \boldsymbol{i}\left(\boldsymbol{t}^{-}\right)+W_{2}^{i} \boldsymbol{u}\left(\boldsymbol{t}^{-}\right)+W_{3}^{i} f+W_{4}^{i} \Delta_{i}\right) \end{array} ]
其中
(∆_u)表示自u上次交互(与任何项目)以来的时间,(∆_i)表示自i上次交互(与任何用户)以来的时间。(引入了时间间隔信息)。
$ f$是交互特征向量
(W^u_1 , . . .W^u_4)和(W^i_1 , . . .W^i_4)是可训练矩阵
$ σ $是激活函数sigmoid
RNN的变体,如LSTM、GRU和T-LSTM,在实验上表现出类似的性能,有时甚至更差,因此在模型中使用RNN来减少可训练参数的数量。(所以不是模型越新越好,不能单纯迷恋新技术)
*3.2 Embedding projection operation
在本节 作者介绍了自己模型的另外一个核心工作,预测操作。通过这个操,模型预测了用户未来的嵌入轨迹。该操作可以用于下游任务,例如链接预测等。
图3展示了预测操作的想法。在t时刻,(u(t))表示用户的嵌入,假设有三个时间间隔(∆_1 < ∆_2 < ∆),对于每个时间间隔,预测他们的嵌入轨迹(\hat{u}(t+∆_1),\hat{u}(t+∆_2),\hat{u}(t+∆)),由图3可以看到作者认为时间间隔和嵌入平移距离成正比。
接着通过({u}(t+∆))的真实位置和(\hat{u}(t+∆))的预测位置去训练预测操作里的可训练矩阵。
该操作需要两个输入,(u(t))和(∆),但是这里并不是简单的将嵌入和时间间隔拼接起来,而是通过哈达玛积的操作将时间和嵌入结合,因为先前的研究表明,神经网络对处理拼接特征的效果不是很好。
本文首先将(∆)通过线性层(W_p)计算,输出时间上下文向量(\boldsymbol{w}:w = W_p∆)。(W_p)初始化为0均值的高斯分布。然后,将预测嵌入作为时间上下文向量与先前嵌入的元素乘积,如下所示
[\widehat{\boldsymbol{u}}(t+\Delta)=(1+w) * \boldsymbol{u}(t) ]
向量(1+w)作为时间注意向量来缩放过去的用户嵌入。若(∆ = 0),则(w=0),投影嵌入与输入嵌入向量相同。(∆)值越大,预测嵌入向量与输入嵌入向量的差异越大。
作者发现,线性层最适合预测嵌入,因为它等效于嵌入空间中的线性变换。将非线性添加到变换中会使投影操作非线性,在实验中发现这会降低预测性能。因此,我们使用如上所述的线性变换。(本来我打算说是不是非线性的会更好的一点,结果在这就解释了为什么不用非线性层)
3.3 Training to predict next item embedding
本节作者将会介绍如何去预测下一个项目嵌入
在之前说过,本文的模型和之前大多数模型的区别并不是去计算两个嵌入之间的连接概率的(类似CTR),而是输出一个嵌入。这样做的优点是可以将计算量从线性(每个项目数一个概率)减少到接近常数。JODIE只需要对预测层进行一次前向传递,并输出一个预测项嵌入。然后,通过使用位置敏感哈希(LSH)技术,可以在近乎恒定的时间内返回嵌入最接近的项。为了维护LSH数据结构,会在项目的嵌入更新时对其进行更新。
因此JODIE通过训练模型,最小化预测嵌入(\tilde{j}(t+\Delta))和真实嵌入(\left[\bar{j}, j\left(t+\Delta^{-}\right)\right])的L2距离 写作(\left\|\tilde{j}(t+\Delta)-\left[\bar{j}, j\left(t+\Delta^{-}\right)\right]\right\|_{2})。此处$ [x, y](代表拼接操作。上标”-“表示时间)t$之前的嵌入.(符号定义见表2)
在时间(t + ∆)之前使用用户预测嵌入(\widehat{\boldsymbol{u}}(t+\Delta))和项目嵌入(i(t+\Delta^{-}))进行预测。
使用项目嵌入(i(t+\Delta^{-}))有两点原因
(a)项目i可能在t到t+∆时间之间和其他用户进行交互,因此,嵌入包含了更多的最新信息
(b)用户经常连续地与同一项目交互,包含项目嵌入有助于简化预测。
我们使用静态和动态嵌入来预测预测项j的静态和动态嵌入。
使用完全连接的线性层进行预测,如下所示
[\tilde{\boldsymbol{j}}(\boldsymbol{t}+\Delta)=W_{1} \widehat{\boldsymbol{u}}(\boldsymbol{t}+\Delta)+W_{2} \overline{\boldsymbol{u}}+W_{3} \boldsymbol{i}\left(\boldsymbol{t}+\Delta^{-}\right)+W_{4} \overline{\boldsymbol{i}}+B ]
其中(W1…W4)和偏置向量(B)构成线性层。
综上 损失如下
[\begin{aligned} \text { Loss }=& \sum_{(u, j, t, f) \in S}\left\|\tilde{j}(t)-\left[\overline{\boldsymbol{j}}, \boldsymbol{j}\left(\boldsymbol{t}^{-}\right)\right]\right\|{2} \ &+\lambda{U}\left\|u(t)-\boldsymbol{u}\left(t^{-}\right)\right\|{2}+\lambda{I}\left\|\boldsymbol{j}(t)-\boldsymbol{j}\left(t^{-}\right)\right\|_{2} \end{aligned} ]
第一个损失项使预测的嵌入误差最小化。添加最后两个术语是为了规范损失,并防止用户和项目的连续动态嵌入分别变化过大。(λ_U)和(λ_I)是缩放参数,以确保损耗在相同范围内。值得注意的是,在训练期间不使用负采样,因为JODIE直接输出预测项的嵌入。
如何将损失扩展到分类预测
可以训练另一个预测函数:(Θ :\mathbb{R}^{n+d}→ C)(静态嵌入是d维,动态嵌入是n维)在交互后使用用户的嵌入来预测标签。其中还是会加入缩放参数将损失来防止过拟合,不只是训练最小化交叉熵损失。
*3.4 t-Batch: Training data batching
这个方法将使模型并行化训练,且保持原有的时间依赖性。即对于交互(S_r),需要在(S_k)的前面 ,其中(∀_r < k)。
现有的并行方法都是利用用户用户分成不同的批次然后并行处理。但是JODIE由于两个RNN模型是相互递归(mutually-recursive)的,所以这会在与同一项目交互的两个用户之间创建相互依赖关系,从而防止将用户拆分为单独的批并并行处理它们。
所以提出了在构建批次时应该满足的两个条件
1:可并行训练
2:若按照索引的递增顺序处理,应保持交互的时间顺序
t-batch提出了通过选择交互网络的独立边缘集来创建每个批次,即同一批次中的两个交互不共享任何公共用户或项目。
具体说一下这个算法的流程,分两步
1 选择:这一步将会从边集中选择互无公共节点的边出来,并且保证每个边((u,i))的时间戳都是最小的。
2 减少:在一次的batch训练后,这一步将吧上一步选出来的边从图中删除。接着回到1。
Experiment
4 EXPERIMENTS
静态向量和动态嵌入维度为128,eopch选择50
选择三个种类的算法baseline:
(1) Deep recurrent recommender models
RRN:C.-Y. Wu, A. Ahmed, A. Beutel, A. J. Smola, and H. Jing.Recurrent recommender networks. In WSDM, 2017.
LatentCross :A. Beutel, P. Covington, S. Jain, C. Xu, J. Li, V. Gatto, and E. H. Chi. Latent cross: Making use of context in recurrent recommender systems. In WSDM, 2018.
Time-LSTM:Y. Zhu, H. Li, Y. Liao, B. Wang, Z. Guan, H. Liu, and D. Cai. What to do next:modeling user behaviors by time-lstm. In IJCAI, 2017.
(2) Dynamic co-evolution models
DeepCoevolve:H. Dai, Y. Wang, R. Trivedi, and L. Song. Deep coevolutionary network: Embedding user and item features for recommendation. arXiv:1609.03675, 2016.
(3) Temporal network embedding models
CTDNE:G. H. Nguyen, J. B. Lee, R. A. Rossi, N. K. Ahmed, E. Koh, and S. Kim. Continuous-time dynamic network embeddings. In WWW BigNet workshop, 2018.
数据集:
Reddit post dataset:这个公共数据集由用户在subreddits上发布的一个月的帖子组成。我们选择了1000个最活跃的子站点作为项目,选择了10000个最活跃的用户。这导致672447次交互。我们将每篇文章的文本转换为表示其LIWC类别的特征向量。
Wikipedia edits:他的公共数据集是维基百科页面编辑一个月的编辑数据。选择编辑次数最多的1000个页面作为项目和编辑,这些编辑至少以用户身份进行了5次编辑(总共8227个用户)。这产生了157474个交互。与Reddit数据集类似,我们将编辑文本转换为LIWC特征向量。
LastFM song listens:这个公共数据集有一个月的WhoListen(谁听哪首歌)信息。我们选择了所有1000名用户和1000首收听最多的歌曲,产生了1293103次互动。在此数据集中,交互没有功能。
4.1 Experiment 1: Future interaction prediction
sota见表三
4.2 Experiment 2: User state change prediction
sota见表4
4.3 Experiment 3: Runtime experiment
运行时间见图4
4.4 Experiment 4: Robustness to the proportion of training data
sota见图5
4.5 Experiment 5: Embedding size
sota见图6
Summary
这篇文章的重点是在做用户和项目之间的预测时,不是直接用用户的嵌入来做,而是经过一个预测操作后先预测用户的动态嵌入随时间的移动结果,在利用这个结果去和项目做预测(项目亦然)。整个论文simple but effective,结构明确,而且适当解释了为什么,例如为什么要用rnn,为什么要用线性变化的∆,读下来赏心悦目!
Original: https://www.cnblogs.com/luoyoucode/p/16303499.html
Author: 落悠
Title: 论文阅读 Predicting Dynamic Embedding Trajectory in Temporal Interaction Networks
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/568062/
转载文章受原作者版权保护。转载请注明原作者出处!