



Kaldi(http://kaldi-asr.org/doc/)是一个语音识别工具。使用 C++ 开发,基于 Apache 许可证。目的是为语音识别研究者提供。
Kaldi 的目标和受众范围与 HTK 相似。目标是用 C++ 编写的现代灵活的代码,易于修改和扩展。重要功能包括:
- 与有限状态传感器(FST)的代码级集成
- 根据 OpenFst 工具包进行编译(将其用作库)。
- 广泛的线性代数支持
- 包括一个矩阵库,它封装了标准的 BLAS 和 LAPACK 例程。
- 可扩展设计。
kaldi是一个对新手极其不友好的工具,首先表现在它的官方文档很硬核,全英文。网上关于它的使用资料很少,对学习者是一个很大的挑战;其次,kaldi是用C++编写,在windows下支持的不是很全面,所以需要在linux机器上使用它,这就要求学习者对linux系统及其shell命令比较熟悉。综合两方面,该工具使用需要一定的门槛,为了方便学习Kaldi工具,特此记录,欢迎学习kaldi工具的小伙伴,关注我的公众号”每日猿码”,一起学习~
Kaldi搭建语音识别系统实践——数据准备
本文以AISHELL数据为例,做实践演示
获取源码
git clone https://github.com/kaldi-asr/kaldi.git
编译源码
该部分参见我的另外一篇文章,关于centos下编译Kaldi。
创建工程
kaldi的实例都放在kaldi/egs的目录下,我们来看yesno实例的工程目录结构,为了保持与kaldi一致,我们需要创建类似kaldi/name/version模板的工程,文件列表如下图所示。
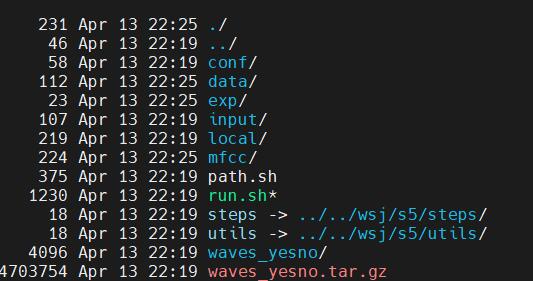
- data : 存放相关数据的文件夹,比如训练集,测试集,语言模型,发音字典等文件。
- steps: kaldi官方工具, 封装了am训练/解码等脚本。
- utils: kaldi 官方工具, 封装了数据处理, lm处理等常用脚本。
- local: 用户自定义的一些处理脚本一般放在这, 比如计算词错率脚本啥的。
- conf: 存放配置文件的目录, 这里面一般有提取特征/解码需要的配置。
- cmd.sh: 该文件定义了训练/构图/解码需要的硬件支持配置。
- path.sh: 该文件需要声明kaldi根目录所在位置, 这样可以可以使用kaldi一些二进制命令
相关代码
#1.建立文件夹
cd kaldi/egs
mkdir -p aispeech0/s5
#2.做符号链接
ln -s ./../../wsj/s5/utils/ utils
ln -s ./../../wsj/s5/steps/ steps
#3.复制环境变量文件path.sh以及并行配置文件cmd.sh
cp ./../../wsj/s5/path.sh ./
cp ./../../wsj/s5/cmd.sh ./
修改path.sh,如下图所示,修改KALDI_ROOT即可

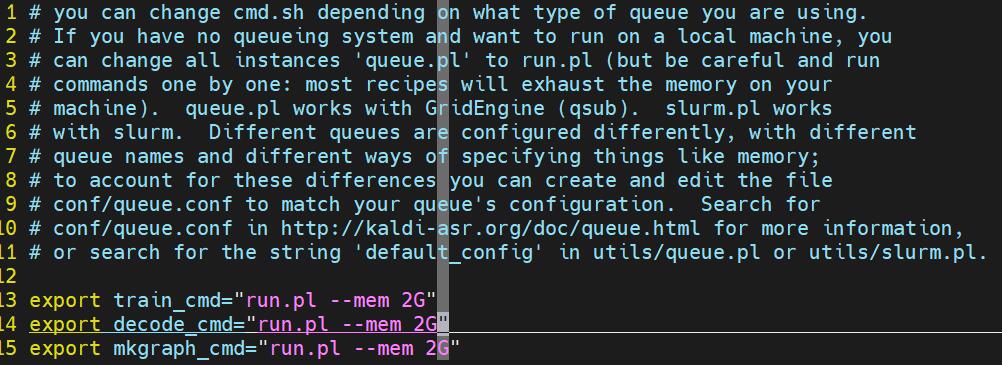
修改cmd.sh,如下图所示,修改queue.pl为run.pl(单机)
下载数据集
aishell-1(http://www.aishelltech.com/kysjcp)提供了178小时的中文含标注的语音数据(aishell-1开源中文语音数据库),下载该完数据集后,解压会得到如下图所示两个文件夹

其中data_aishell/wav存放wav的压缩文件,解压后会得到 train,dev,test 数据用于训练/开发/测试:

另外的文件夹存放说话人信息及汉字与音素的对应关系。
标准的kaldi数据格式
text文件
该文件表示语音与说话内容的关系,如下图所示

scp文件
该文件表示语音与存放路径的对应关系,如下图所示

utt2spk
该文件表示语音与说书人的对应关系,如下图所示

spk2utt
该文件表示说话人与语音的对应关系,如下图所示

数据处理
该代码为kaldi中源码自带数据处理脚本,全为shell,若有不懂,可私聊小编
#!/usr/bin/env bash
Copyright 2017 Xingyu Na
Apache 2.0
. ./path.sh || exit 1;
if [ $# != 2 ]; then
echo "Usage: $0 <audio-path> <text-path>"
echo " $0 /export/a05/xna/data/data_aishell/wav /export/a05/xna/data/data_aishell/transcript"
exit 1;
fi
aishell_audio_dir=$1
aishell_text=$2/aishell_transcript_v0.8.txt
train_dir=data/local/train
dev_dir=data/local/dev
test_dir=data/local/test
tmp_dir=data/local/tmp
mkdir -p $train_dir
mkdir -p $dev_dir
mkdir -p $test_dir
mkdir -p $tmp_dir
data directory check
if [ ! -d $aishell_audio_dir ] || [ ! -f $aishell_text ]; then
echo "Error: $0 requires two directory arguments"
exit 1;
fi
find wav audio file for train, dev and test resp.
find $aishell_audio_dir -iname "*.wav" > $tmp_dir/wav.flist
n=cat $tmp_dir/wav.flist | wc -l
[ $n -ne 141925 ] && \
echo Warning: expected 141925 data data files, found $n
grep -i "wav/train" $tmp_dir/wav.flist > $train_dir/wav.flist || exit 1;
grep -i "wav/dev" $tmp_dir/wav.flist > $dev_dir/wav.flist || exit 1;
grep -i "wav/test" $tmp_dir/wav.flist > $test_dir/wav.flist || exit 1;
rm -r $tmp_dir
Transcriptions preparation
for dir in $train_dir $dev_dir $test_dir; do
echo Preparing $dir transcriptions
sed -e 's/\.wav//' $dir/wav.flist | awk -F '/' '{print $NF}' > $dir/utt.list
sed -e 's/\.wav//' $dir/wav.flist | awk -F '/' '{i=NF-1;printf("%s %s\n",$NF,$i)}' > $dir/utt2spk_all
paste -d' ' $dir/utt.list $dir/wav.flist > $dir/wav.scp_all
utils/filter_scp.pl -f 1 $dir/utt.list $aishell_text > $dir/transcripts.txt
awk '{print $1}' $dir/transcripts.txt > $dir/utt.list
utils/filter_scp.pl -f 1 $dir/utt.list $dir/utt2spk_all | sort -u > $dir/utt2spk
utils/filter_scp.pl -f 1 $dir/utt.list $dir/wav.scp_all | sort -u > $dir/wav.scp
sort -u $dir/transcripts.txt > $dir/text
utils/utt2spk_to_spk2utt.pl $dir/utt2spk > $dir/spk2utt
done
mkdir -p data/train data/dev data/test
for f in spk2utt utt2spk wav.scp text; do
cp $train_dir/$f data/train/$f || exit 1;
cp $dev_dir/$f data/dev/$f || exit 1;
cp $test_dir/$f data/test/$f || exit 1;
done
echo "$0: AISHELL data preparation succeeded"
exit 0;
</text-path></audio-path>
总结
今天的数据处理就讲到这里,大家有什么不懂的地方,可关注公众号”每日猿码”,私聊小编,保证知无不言~

Original: https://www.cnblogs.com/saltape/p/16205194.html
Author: 牙牙学语的猿
Title: kaldi工具搭建语音识别系统——数据处理
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/567617/
转载文章受原作者版权保护。转载请注明原作者出处!